深入浅出,机器学习该怎么入门?


来源 | 算法进阶
责编 | 寇雪芹
头图 | 下载于视觉中国
前言:
机器学习作为人工智能领域的核心组成,是计算机程序学习数据经验以优化自身算法,并产生相应的“智能化的”建议与决策的过程。
一个经典的机器学习的定义是:
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.

机器学习概论
机器学习是关于计算机基于数据分布构建出概率统计模型,并运用模型对数据进行分析与预测的方法。按照学习数据分布的方式的不同,主要可以分为监督学习和非监督学习:
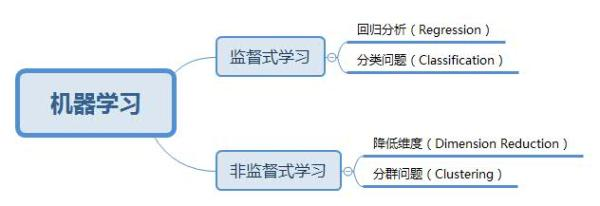
1.1 监督学习
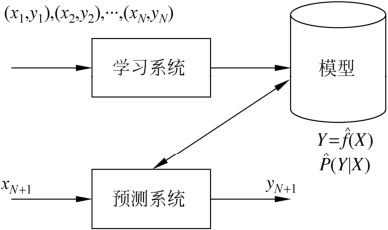
从有标注的数据(x为变量特征空间, y为标签)中,通过选择的模型及确定的学习策略,再用合适算法计算后学习到最优模型,并用模型预测的过程。模型预测结果Y的取值有限的或者无限的,可分为分类模型或者回归模型;
1.2 非监督学习
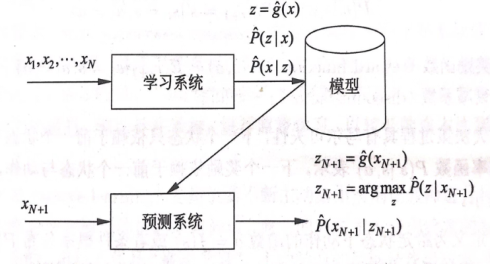
从无标注的数据(x为变量特征空间),通过选择的模型及确定的学习策略,再用合适算法计算后学习到最优模型,并用模型发现数据的统计规律或者内在结构。按照应用场景,可以分为聚类,降维和关联分析等模型;

机器学习建模流程
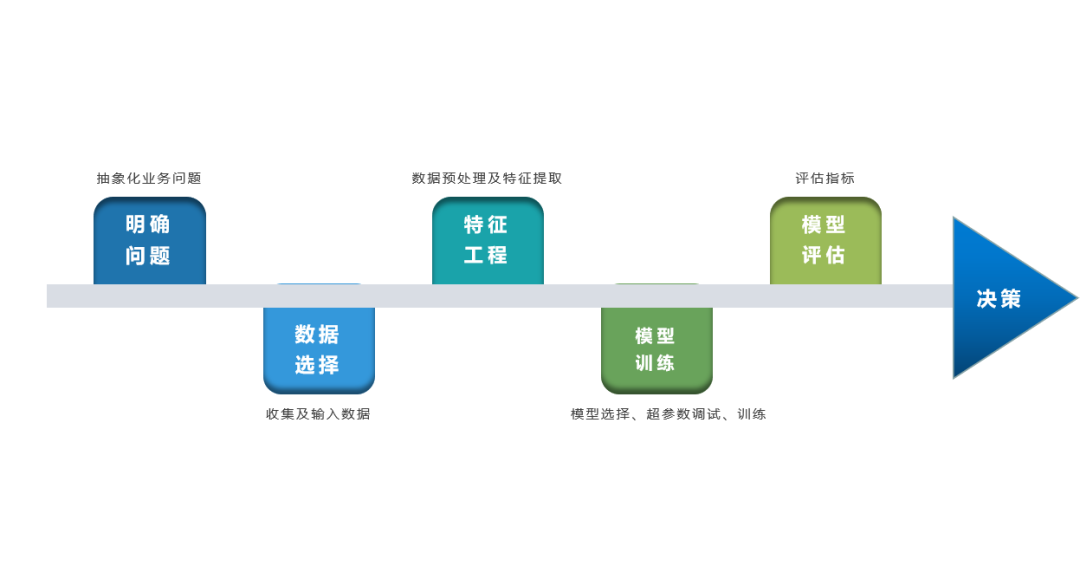
2.1 明确业务问题
明确业务问题是机器学习的先决条件,这里需要抽象出现实业务问题的解决方案:需要学习什么样的数据作为输入,目标是得到什么样的模型做决策作为输出。
(如一个简单的新闻分类场景就是学习已有的新闻及其类别标签数据,得到一个分类模型,通过模型对每天新的新闻做类别预测,以归类到每个新闻频道。)
2.2 数据选择:收集及输入数据
数据决定了机器学习结果的上限,而算法只是尽可能逼近这个上限。意味着数据的质量决定了模型的最终效果,在实际的工业应用中,算法通常占了很小的一部分,大部分工程师的工作都是在找数据、提炼数据、分析数据。数据选择需要关注的是:
① 数据的代表性:无代表性的数据可能会导致模型的过拟合,对训练数据之外的新数据无识别能力;
② 数据时间范围:监督学习的特征变量X及标签Y如与时间先后有关,则需要明确数据时间窗口,否则可能会导致数据泄漏,即存在和利用因果颠倒的特征变量的现象。(如预测明天会不会下雨,但是训练数据引入明天温湿度情况);
③ 数据业务范围:明确与任务相关的数据表范围,避免缺失代表性数据或引入大量无关数据作为噪音;
2.3 特征工程:数据预处理及特征提取
特征工程就是将原始数据加工转化为模型有用的特征,技术手段一般可分为:
数据预处理:特征表示,缺失值/异常值处理,数据离散化,数据标准化等;特征提取:特征衍生,特征选择,特征降维等;
特征表示
数据需要转换为计算机能够处理的数值形式。如果数据是图片数据需要转换为RGB三维矩阵的表示。
字符类的数据可以用多维数组表示,有Onehot独热编码表示、word2vetor分布式表示及bert动态编码等;

异常值处理
收集的数据由于人为或者自然因素可能引入了异常值(噪音),这会对模型学习进行干扰。
通常需要对人为引起的异常值进行处理,通过业务判断和技术手段(python、正则式匹配、pandas数据处理及matplotlib可视化等数据分析处理技术)筛选异常的信息,并结合业务情况删除或者替换数值。
缺失值处理
数据缺失的部分,通过结合业务进行填充数值、不做处理或者删除。根据缺失率情况及处理方式分为以下情况:
① 缺失率较高,并结合业务可以直接删除该特征变量。经验上可以新增一个bool类型的变量特征记录该字段的缺失情况,缺失记为1,非缺失记为0;
② 缺失率较低,结合业务可使用一些缺失值填充手段,如pandas的fillna方法、训练随机森林模型预测缺失值填充;
③ 不做处理:部分模型如随机森林、xgboost、lightgbm能够处理数据缺失的情况,不需要对缺失数据做任何的处理。
数据离散化
数据离散化能减小算法的时间和空间开销(不同算法情况不一),并可以使特征更有业务解释性。
离散化是将连续的数据进行分段,使其变为一段段离散化的区间,分段的原则有等距离、等频率等方法。
数据标准化
数据各个特征变量的量纲差异很大,可以使用数据标准化消除不同分量量纲差异的影响,加速模型收敛的效率。常用的方法有:
① min-max 标准化:
将数值范围缩放到(0,1),但没有改变数据分布。max为样本最大值,min为样本最小值。
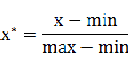
② z-score 标准化:
将数值范围缩放到0附近, 经过处理的数据符合标准正态分布。u是平均值,σ是标准差。
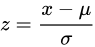
特征衍生
基础特征对样本信息的表述有限,可通过特征衍生出新含义的特征进行补充。特征衍生是对现有基础特征的含义进行某种处理(组合/转换之类),常用方法如:
① 结合业务的理解做衍生,比如通过12个月工资可以加工出:平均月工资,薪资变化值,是否发工资 等等;
② 使用特征衍生工具:如feature tools等技术;
特征选择
特征选择筛选出显著特征、摒弃非显著特征。特征选择方法一般分为三类:
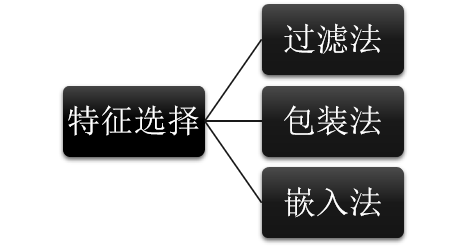
① 过滤法:按照特征的发散性或者相关性指标对各个特征进行评分后选择,如方差验证、相关系数、IV值、卡方检验及信息增益等方法。
② 包装法:每次选择部分特征迭代训练模型,根据模型预测效果评分选择特征的去留。
③ 嵌入法:使用某些模型进行训练,得到各个特征的权值系数,根据权值系数从大到小来选择特征,如XGBOOST特征重要性选择特征。
特征降维
如果特征选择后的特征数目仍太多,这种情形下经常会有数据样本稀疏、距离计算困难的问题(称为 “维数灾难”),可以通过特征降维解决。常用的降维方法有:主成分分析法(PCA), 线性判别分析法(LDA)等。
2.4 模型训练
模型训练是选择模型学习数据分布的过程。这过程还需要依据训练结果调整算法的(超)参数,使得结果变得更加优良。
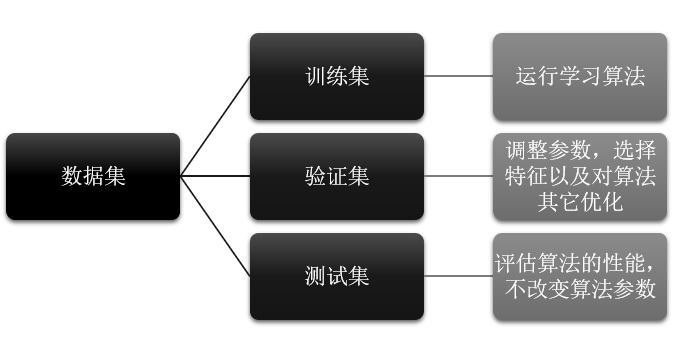
2.4.1 数据集划分
训练模型前,一般会把数据集分为训练集和测试集,并可再对训练集再细分为训练集和验证集,从而对模型的泛化能力进行评估。
① 训练集(training set):用于运行学习算法。
② 开发验证集(development set)用于调整参数,选择特征以及对算法其它优化。常用的验证方式有交叉验证Cross-validation,留一法等;
③ 测试集(test set)用于评估算法的性能,但不会据此改变学习算法或参数。
2.4.2 模型选择
常见的机器学习算法如下:
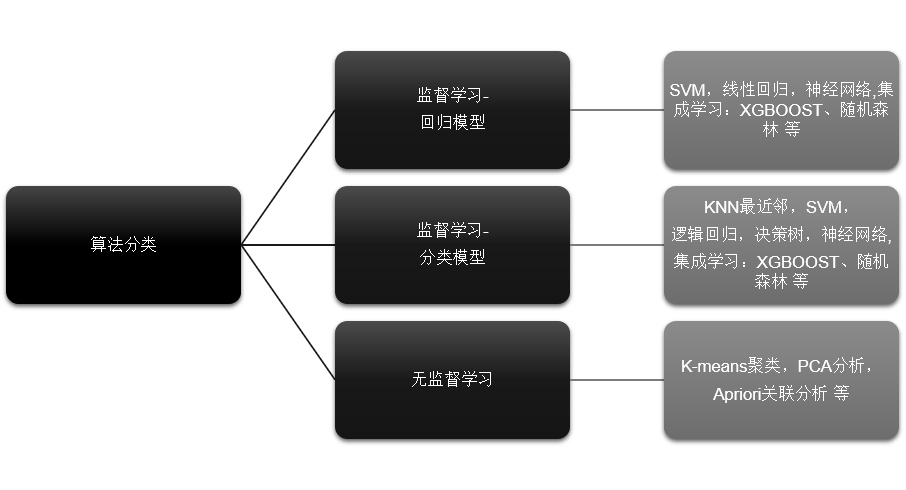
模型选择取决于数据情况和预测目标。可以训练多个模型,根据实际的效果选择表现较好的模型或者模型融合。
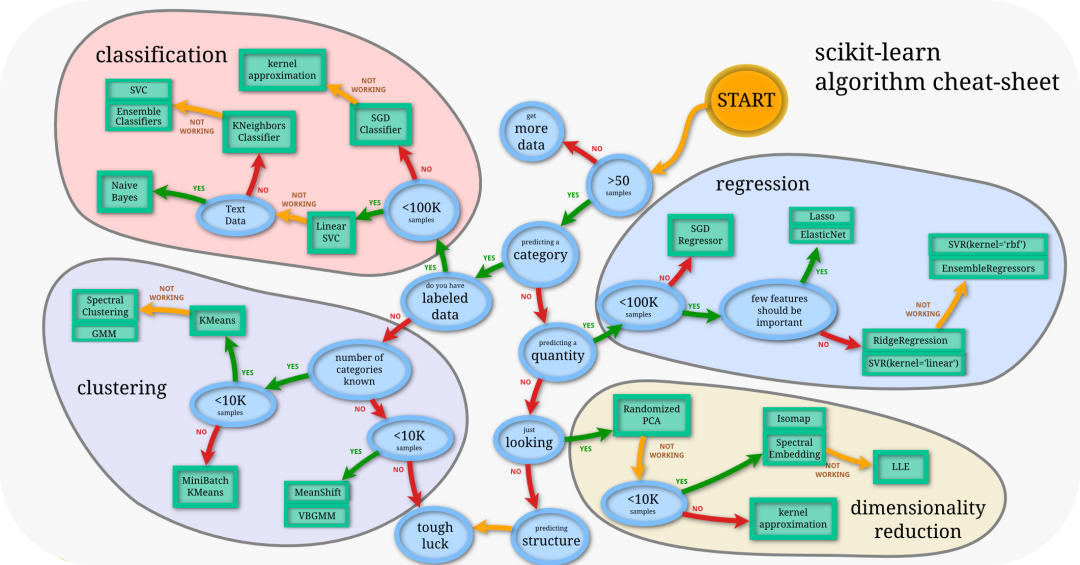
模型选择
2.4.3 模型训练
训练过程可以通过调参进行优化,调参的过程是一种基于数据集、模型和训练过程细节的实证过程。超参数优化需要基于对算法的原理的理解和经验,此外还有自动调参技术:网格搜索、随机搜索及贝叶斯优化等。
2.5 模型评估
模型评估的标准:模型学习的目的使学到的模型对新数据能有很好的预测能力(泛化能力)。现实中通常由训练误差及测试误差评估模型的训练数据学习程度及泛化能力。
2.5.1 评估指标
① 评估分类模型:常用的评估标准有查准率P、查全率R、两者调和平均F1-score 等,并由混淆矩阵的统计相应的个数计算出数值:
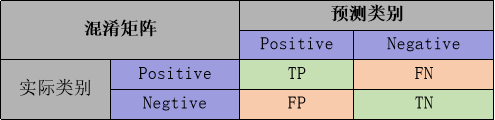
混淆矩阵
查准率是指分类器分类正确的正样本(TP)的个数占该分类器所有预测为正样本个数(TP+FP)的比例;
查全率是指分类器分类正确的正样本个数(TP)占所有的正样本个数(TP+FN)的比例。
F1-score是查准率P、查全率R的调和平均:
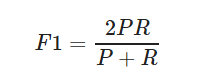
② 评估回归模型:常用的评估指标有RMSE均方根误差 等。反馈的是预测数值与实际值的拟合情况。
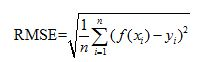
③ 评估聚类模型:可分为两类方式,一类将聚类结果与某个“参考模型”的结果进行比较,称为“外部指标”(external index):如兰德指数,FM指数 等;另一类是直接考察聚类结果而不利用任何参考模型,称为“内部指标”(internal index):如紧凑度、分离度 等。
2.5.2 模型评估及优化
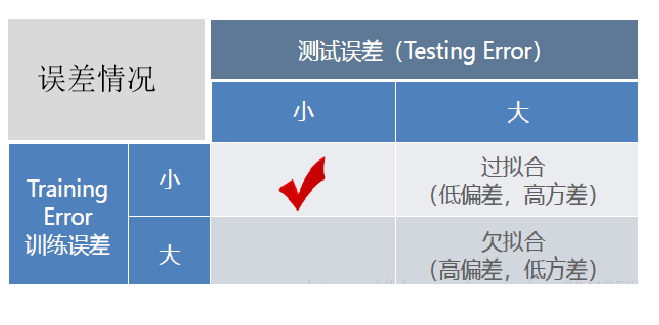
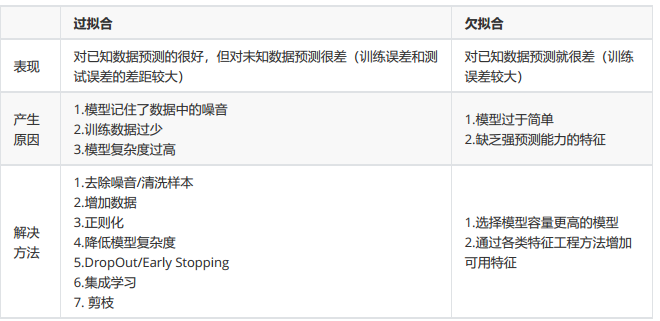
根据训练集及测试集的指标表现,分析原因并对模型进行优化,常用的方法有:
2.6 模型决策
决策是机器学习最终目的,对模型预测信息加以分析解释,并应用于实际的工作领域。
需要注意的是工程上是结果导向,模型在线上运行的效果直接决定模型的成败,不仅仅包括其准确程度、误差等情况,还包括其运行的速度(时间复杂度)、资源消耗程度(空间复杂度)、稳定性的综合考虑。
参考文献:
《机器学习》周志华
《统计学习方法》李航
Google machine-learning
更多精彩推荐
☞谈“云”色变?近80%企业曾遭受数据泄露☞换脸火了,我用 python 快速入门生成模型☞大佬新番:吴恩达送出深度学习新手大礼包☞提气!清华成立集成电路学院,专研“卡脖子”技术点分享点收藏点点赞点在看
相关文章:

防止SQL注入式攻击
1将sql中使用的一些特殊符号,如 -- /* ; %等用Replace()过滤;2限制文本框输入字符的长度;3检查用户输入的合法性;客户端与服务器端都要执行,可以使用正则。4使用带参数的SQL语句形式。 尽量用存储过程
js中document.write的那点事
document.write()方法可以用在两个方面:页面载入过程中用实时脚本创建页面内容,以及用延时脚本创建本窗口或新窗口的内容。该方法需要一个字符串参数,它是写到窗口或框架中的HTML内容。这些字符串参数可以是变量或值为字符串的表达式…
SVN提示被锁定的解决方法(转)
1、(常用)出现这个问题后使用“清理”即"Clean up"功能,如果还不行,就直接到上一级目录,再执行“清理”,然后再“更新”。 2、(没试过)有时候如果看到某个包里面的文件夹没…
征集佳句-精妙SQL语句收集
征集佳句-精妙SQL语句收集 SQL语句先前写的时候,很容易把一些特殊的用法忘记,我特此整理了一下SQL语句操作,方便自己写SQL时方便一点,想贴上来,一起看看,同时希望大家能共同多多提意见,也给我…

【WP8】ResourceDictionary
WP8中引用资源字典 当我们定义的样式太多的时候,我们可以把样式分别定义在不同的文件中,然后通过 MergedDictionaries 应用到其他资源字典中,看下面Demo 我们可以把样式定义在多个文件中,然后再App.xaml中引用 我们先定义三个文件…

拿来就能用! CTO 创业技术栈指南!
作者 | Nitin Aggarwal译者 | 弯月出品 | CSDN(ID:CSDNnews)随着开发运维概念的诞生,以及“You build it, you run it.”(谁构建,谁运维)理念的盛行,现代创业公司的技术栈也发生了许…

Go处理百万每分钟的请求
2019独角兽企业重金招聘Python工程师标准>>> I have been working in the anti-spam, anti-virus and anti-malware industry for over 15 years at a few different companies, and now I know how complex these systems could end up being due to the massive a…
data pump工具
expdp和impdp的用法ORCALE10G提供了新的导入导出工具,数据泵。Oracle官方对此的形容是:OracleDataPump technology enables Very High-Speed movement of data and metadata from one database to another.其中Very High-Speed是亮点。先说数据泵提供的主…
游标对于分页存储过程
1。我个人认为最好的分页方法是: Select top 10 * from table where id>200写成存储过程,上面的语句要拼一下sql语句,要获得最后大于的哪一个ID号 2。那个用游标的方式,只适合于小数据量的表,如果表在一万行以上,就差劲了 你的存储过程还比不上NOT IN分页,示例: SELECT …

混沌、无序、变局?探索之中,《拟合》开启
从无序中寻找踪迹,从眼前事探索未来在东方的神话里,喜鹊会搭桥,银河是条河,两端闪耀的牵牛星和织女星,则是一年一相会的佳偶,他们彼此间的惦念,会牵引彼此在七夕那天实现双星聚首。在西方的世界…
linxu 下安装mysql5.7.19
2019独角兽企业重金招聘Python工程师标准>>> 1、首先检查是否已经安装过mysql,查找mysql相关软件rpm包 # rpm -qa | grep mysql 2、将所有与mysql相关的东西删除 #yum -y remove mysql-libs-5.1.66-2.el6_3.x86_64 3、安装依赖包 #yum -y install make gcc-c cmake …
C#技术内幕 学习笔记
引用类型是类型安全的指针,它们的内存是分配在堆(保存指针地址)上的。String、数组、类、接口和委托都是引用类型。 强制类型转换与as类型转换的区别:当类型转换非法时,强制类型转换将抛出一个System.InvalidCastExce…

java的深度克隆
原文:http://blog.csdn.net/randyjiawenjie/article/details/7563323javaobjectinterfacestringclassexception先做个标记 http://www.iteye.com/topic/182772 http://www.blogjava.net/jerry-zhaoj/archive/2009/10/14/298141.html 关于super.clone的理解 http://h…

持续推进预估时间问题研究,滴滴盖亚计划开放ETA数据集
4月29日消息,为持续推进行程时长预估问题研究,滴滴联合GIS(地理信息系统)领域国际顶会ACM SIGSPATIAL发布ACM SIGSPATIAL GISCUP 2021比赛,鼓励研究者们基于滴滴新开放的行程时长数据集,进一步提升时间预估准确性。 预估到达时间…
3.Java集合-HashSet实现原理及源码分析
一、HashSet概述: HashSet实现Set接口,由哈希表(实际上是一个HashMap实例)支持,它不保证set的迭代顺序很久不变。此类允许使用null元素 二、HashSet的实现: 对于HashSet而言,它是基于HashMap实现…
一个函数返回多个值
有两种方法:1.使用指针变量声明函数(或者使用数组变量)2.使用传出参数 第一种方法:函数返回的是一个指针地址(数组地址),这个内存地址有多个变量寄存在里面。这个方法我不太会用,传…

4月30日或为上半年“最难打车日”
滴滴出行昨日发布预测,称由于周五通勤晚高峰及假期启程高峰叠加,4月30日下午或将成为今年上半年“最难打车日”,用户将遇到叫车排队甚至打不到车的情况。滴滴呼吁,请提前规划行程,预留充足时间,大家五一快乐…

exchange 2003配置ASSP 反垃圾邮件
Exchange上第三方反垃圾邮件用得比较多的是ORF,它直接运行在虚拟SMTP服务上,配置非常的方便。ASSP(https://sourceforge.net/projects/assp/) 是一个开源的反垃圾邮件代理,反垃圾效果也非常好,这里不讲如何…
中国人工智能学会通讯——人工智能在各医学亚专科的发展现状及趋势 1.3 人工智能在各医学亚专科的发展态势...
1.3 人工智能在各医学亚专科的发展态势 1. 人工智能在眼科领域的应用 2016年11月,Google的研究者Gulshan博士等人在美国医学协会杂志“Journal of the American Medical Association”上发表的一篇文章,运用deep learning算法(卷积神经网络&a…
在ASP.NET中如何用C#.NET实现基于表单的验证
这篇文章引用到了Microsoft .NET类库中的以下名空间: System.Data.SqlClient System.Web.Security ------------ÿ…
PHP学习笔记 第八讲 Mysql.简介和创建新的数据库
八、Mysql.简介和创建新的数据库1、mysql简介与概要mysql是一个小型关系型数据管理系统,开发者为瑞典mysqlab公司现在已经被sun公司收购1.可以处理拥有上千万条记录的大型数据2.支持常见SQL语句规范3.可移植高,安装简单小巧4.良好的运行效率,…

摆脱 FM!这些推荐系统模型真香
作者 | 梁唐来源 | TechFlow之前我们介绍了推荐当中应用得非常广泛的FM大家族,从FM这个模型衍生出了一系列的模型,从纯FM,到AFM、FFM、DeepFM等等一系列的FM模型,最后的终极版本是xDeepFM。这个模型非常复杂,可以说…

新技术、新思维开创公共安全管理新模式
智慧城市的建设在国内外许多地区正如火如荼的进行中,在为期六天的第十七届中国国际高新技术成果交易会(高交会)上,智慧城市这一话题再次引发观众及城市建设者们的热议。 尤其是高交会期间召开的“2015亚太智慧城市发展高峰论坛”&…

.Net 中字符串性能
Introduction 你在代码中处理字符串的方法可能会对性能产生令人吃惊的影响。在本文中,我需要考虑两个由于使用字符串而产生的问题:临时字符串变量的使用和字符串连接。 Background 每个项目都有需要你为其考虑编码标准的时候。使用 FxCop 是一个好的开…

Lambda表达式可以被转换为委托类型
void Main() { //向Users类中增加两人; List<Users> usernew List<Users>{ new Users{ID1,Name"Jalen",Age23}, new Users{ID12,Name"Administrator",Age32}, }; //接下来就是利用Linq提供的新的方法来进行相关操作; var userslistuser.Wher…

人工干预如何提高模型性能?看这文就够了!
作者 | Preetam Joshi译者 | 吴家帆出品 | AI科技大本营(ID:rgznai100)有一些行业对误报非常敏感,如金融行业,在对信用卡欺诈检测时,如果检测系统将用户的行为错误地分类为欺诈,这将对该金融机构的声誉产生…

一种无需留坑为页面动态添加View方案
在Activity或Fragment页面动态添加View,有其应用场景,比如配合运营在首页动态插入H5活动页(如下图手淘的雪花例示[1]),在页面头部插入通知View等。本文结合ActivityLifecycleCallbacks[2]及DecorView使用,为类似需求提…

边缘加速创新和AI应用,Xilinx推出Kria自适应系统模块产品组合
为了帮助开发者更容易使用FPGA和SoC的功能,赛灵思在开发工具上做了不少的投入,自适应系统模块(SOM)产品组合就是其中之一。 近日,赛灵思宣布推出Kria™自适应系统模块( SOM )产品组合ÿ…
windows计算器
using System; using System.Drawing; using System.Windows; using System.Windows.Forms; using System.Collections; using System.ComponentModel; using System.Data; namespace comput{ /// <summary> /// 这是一个计算器的简单实现。 /// </summary&…

哈夫曼树的构造
[转载于网易博客,具体地址不详] 构造哈夫曼树的过程是这样的 一、构成初始集合 对给定的n个权值{W1,W2,W3,...,Wi,...,Wn}构成n棵二叉树的初始集合F{T1,T2,T3,...,Ti,...,Tn},其中每棵二叉树Ti中只有一个权值为Wi的根结点,它的左右子树均为空…