Memcached深度分析
CODE: #include <fcntl.h> #include <stdlib.h> #include <unistd.h> int daemon(nochdir, noclose) int nochdir, noclose; { int fd; switch (fork()) { case -1: return (-1); case 0: break; default: _exit(0); } if (setsid() == -1) return (-1); if (!nochdir) (void)chdir("/"); if (!noclose && (fd = open("/dev/null", O_RDWR, 0)) != -1) { (void)dup2(fd, STDIN_FILENO); (void)dup2(fd, STDOUT_FILENO); (void)dup2(fd, STDERR_FILENO); if (fd > STDERR_FILENO) (void)close(fd); } return (0); } |
CODE: void slabs_init(size_t limit) { int i; int size=1; mem_limit = limit; for(i=0; i<=POWER_LARGEST; i++, size*=2) { slabclass[i].size = size; slabclass[i].perslab = POWER_BLOCK / size; slabclass[i].slots = 0; slabclass[i].sl_curr = slabclass[i].sl_total = slabclass[i].slabs = 0; slabclass[i].end_page_ptr = 0; slabclass[i].end_page_free = 0; slabclass[i].slab_list = 0; slabclass[i].list_size = 0; slabclass[i].killing = 0; } /* for the test suite: faking of how much we've already malloc'd */ { char *t_initial_malloc = getenv("T_MEMD_INITIAL_MALLOC"); if (t_initial_malloc) { mem_malloced = atol(getenv("T_MEMD_INITIAL_MALLOC")); } } /* pre-allocate slabs by default, unless the environment variable for testing is set to something non-zero */ { char *pre_alloc = getenv("T_MEMD_SLABS_ALLOC"); if (!pre_alloc || atoi(pre_alloc)) { slabs_preallocate(limit / POWER_BLOCK); } } } |
CODE: void slabs_init(size_t limit, double factor) { int i = POWER_SMALLEST - 1; unsigned int size = sizeof(item) + settings.chunk_size; /* Factor of 2.0 means use the default memcached behavior */ if (factor == 2.0 && size < 128) size = 128; mem_limit = limit; memset(slabclass, 0, sizeof(slabclass)); while (++i < POWER_LARGEST && size <= POWER_BLOCK / 2) { /* Make sure items are always n-byte aligned */ if (size % CHUNK_ALIGN_BYTES) size += CHUNK_ALIGN_BYTES - (size % CHUNK_ALIGN_BYTES); slabclass[i].size = size; slabclass[i].perslab = POWER_BLOCK / slabclass[i].size; size *= factor; if (settings.verbose > 1) { fprintf(stderr, "slab class %3d: chunk size %6d perslab %5d/n", i, slabclass[i].size, slabclass[i].perslab); } } power_largest = i; slabclass[power_largest].size = POWER_BLOCK; slabclass[power_largest].perslab = 1; /* for the test suite: faking of how much we've already malloc'd */ { char *t_initial_malloc = getenv("T_MEMD_INITIAL_MALLOC"); if (t_initial_malloc) { mem_malloced = atol(getenv("T_MEMD_INITIAL_MALLOC")); } } #ifndef DONT_PREALLOC_SLABS { char *pre_alloc = getenv("T_MEMD_SLABS_ALLOC"); if (!pre_alloc || atoi(pre_alloc)) { slabs_preallocate(limit / POWER_BLOCK); } } #endif } |
CODE: static int grow_slab_list (unsigned int id) { slabclass_t *p = &slabclass[id]; if (p->slabs == p->list_size) { size_t new_size = p->list_size ? p->list_size * 2 : 16; void *new_list = realloc(p->slab_list, new_size*sizeof(void*)); if (new_list == 0) return 0; p->list_size = new_size; p->slab_list = new_list; } return 1; } |
CODE: typedef unsigned long int ub4; /* unsigned 4-byte quantities */ typedef unsigned char ub1; /* unsigned 1-byte quantities */ #define hashsize(n) ((ub4)1<<(n)) #define hashmask(n) (hashsize(n)-1) |
CODE: /* expires items that are more recent than the oldest_live setting. */ void item_flush_expired() { int i; item *iter, *next; if (! settings.oldest_live) return; for (i = 0; i < LARGEST_ID; i++) { /* The LRU is sorted in decreasing time order, and an item's timestamp * is never newer than its last access time, so we only need to walk * back until we hit an item older than the oldest_live time. * The oldest_live checking will auto-expire the remaining items. */ for (iter = heads[i]; iter != NULL; iter = next) { if (iter->time >= settings.oldest_live) { next = iter->next; if ((iter->it_flags & ITEM_SLABBED) == 0) { item_unlink(iter); } } else { /* We've hit the first old item. Continue to the next queue. */ break; } } } } |
CODE: /* wrapper around assoc_find which does the lazy expiration/deletion logic */ item *get_item_notedeleted(char *key, size_t nkey, int *delete_locked) { item *it = assoc_find(key, nkey); if (delete_locked) *delete_locked = 0; if (it && (it->it_flags & ITEM_DELETED)) { /* it's flagged as delete-locked. let's see if that condition is past due, and the 5-second delete_timer just hasn't gotten to it yet... */ if (! item_delete_lock_over(it)) { if (delete_locked) *delete_locked = 1; it = 0; } } if (it && settings.oldest_live && settings.oldest_live <= current_time && it->time <= settings.oldest_live) { item_unlink(it); it = 0; } if (it && it->exptime && it->exptime <= current_time) { item_unlink(it); it = 0; } return it; } |
相关文章:

【分享】 IT囧事
导读:企业的业务发展离不开信息化建设,信息系统的稳定运行更离不开IT运维的支持,许多生命期短暂或者使用效果不太好的IT系统,都是因为后期的维护和支持不到位,才导致前期投入的资金和人力付之东流,让人扼腕…

为什么掌握Linux对程序员这么重要……
人工智能、物联网、大数据时代,Linux正有着一统天下的趋势,几乎每个软件工程师岗位,都要求掌握Linux。可以说,打开 Linux 操作系统这扇门,你才是合格的软件工程师。如果不能熟练地操作 Linux,你基本上等于少…
Java并发编程有多难?这几个核心技术你掌握了吗?
本文主要内容索引 1、Java线程 2、线程模型 3、Java线程池 4、Future(各种Future) 5、Fork/Join框架 6、volatile 7、CAS(原子操作) 8、AQS(并发同步框架) 9、synchronized(同步锁) 10、并发队列࿰…

这届 AI 预测欧洲杯冠军,通通被打脸
持续了一个月的欧洲杯,终于落下帷幕。北京时间 7 月 12 日(周一)凌晨,本届欧洲杯决赛中,意大利对阵英格兰。两队在 120 分钟时间里 1-1 战平,意大利在欧洲杯中通过点球大战以 3:2击败英格兰夺冠。意大利上次…
资源的正确引用
对资源的引用应该发生在对资源的保护期间。 比如在所保护内hold住资源、local_bh_disable内hold住资源; 否则对资源的使用可能发生不一致的情况。 PS: 代码逻辑应该符合真实世界的合理逻辑。转载于:https://www.cnblogs.com/kernel521/p/4045976.html

给网站管理员的建议:创建可利用的、可抓取的网站
转载自 谷歌中文网站管理员博客 发表者 T.V. Raman,研究学者 原文: Webmaster tips for creating accessible, crawlable sites 发表于:2008年4月14日 上午10:47 Hubbell和我正在我们位于加州的家中度假。欢迎您随时 阅读在此之前我为网站管…
iptables如何开放被动模式的FTP服务
如何开放被动模式的FTP服务? 1.装载FTP追踪时的专用的模块; # modprobe nf_conntrack_ftp # lsmod | grep ftp 2.放行请求报文 命令连接: NEW,ESTABLISHED 数据连接: RELATED,ESTABLISHED #iptables -I INPUT -d 192.168.141.10 …

KNN 分类算法原理代码解析
作者 | Charmve来源 | 迈微AI研习社k-最近邻算法是基于实例的学习方法中最基本的,先介绍基x于实例学习的相关概念。基于实例的学习已知一系列的训练样例,很多学习方法为目标函数建立起明确的一般化描述;但与此不同,基于实例的学习…
Roadsend PHP-开源的PHP代码编译器
Roadsend PHP 是一个开源的php compiler, 可以将你的PHP代码编译成原生的二进制代码, 无需分发php源码. Roadsend 可以将你的PHP web项目编译成FastCGI的可执行文件,这样apache,nginx可以通过fastcgi方式和编译后的 程序进行通讯. 看起来,PHP 编写的程序可以和C编写的程序有同…
Android安卓开发中图片缩放讲解
安卓开发中应用到图片的处理时候,我们通常会怎么缩放操作呢,来看下面的两种做法: 方法1:按固定比例进行缩放 在开发一些软件,如新闻客户端,很多时候要显示图片的缩略图,由于手机屏幕限制&#x…
a标签是什么意思 怎么使用?
转自:https://www.imooc.com/qadetail/190881 (1) a标签的作用:超链接,用于跳转到别的网页。 (2) a标签的用法:<a href"网址" target"_blank" >到百度首页</a> 其中target是a标签的一个属性&…

【Java】Lucene检索引擎详解
基于Java的全文索引/检索引擎——Lucene Lucene不是一个完整的全文索引应用,而是是一个用Java写的全文索引引擎工具包,它可以方便的嵌入到各种应用中实现针对应用的全文索引/检索功能。 Lucene的作者:Lucene的贡献者Doug Cutting是一位资深全…

大手笔 !Julia Computing 获 2400 万美元融资,前 Snowflake CEO 加入董事会
整理 | 梦依丹出品 | CSDN(ID:CSDNnews)2021 年 7 月 19 日,由 Julia 高性能编程语言创始人成立的 Julia Computing 公司完成了 2400 万美元的 A 轮融资,这笔融资由 Dorilton Ventures 领投,Menlo Ventures…
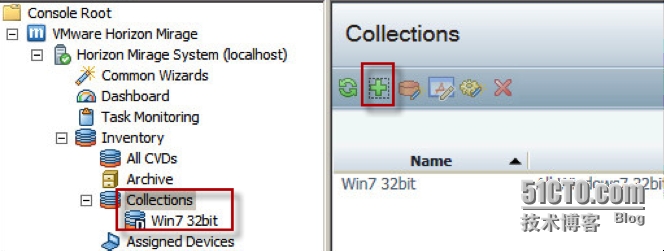
(Mirage系列之六)在Mirage里使用Collection
在Mirage中,Collection是包含一个或多个CVD的集合。 Collection的主要作用是简化操作。比如我有一百个终端设备需要分配基础层,如果没有Collection,那么管理员需要逐个点击。这是无趣的重复劳动。有了Collection,只要选择一个Coll…
WAS服务器负载测试软件导读
转帖:出处未知 你的Web服务器和应用到底能够支持多少并发用户访问?在出现大量并发请求的情况下,软件会出现问题吗?这些问题靠通常的测试手段是无法解答的。本文介绍了Microsoft为这个目的而提供的免费工具WAS及其用法。另外&#…

深度学习实现场景字符识别模型|代码干货
作者|李秋键出品|AI科技大本营(ID:rgznai100)# 前言 #文字是人从日常交流中语音中演化出来,用来记录信息的重要工具。文字对于人类意义非凡,以中国为例,中国地大物博,各个地方的口音都不统一,但是人们使用同一套书写体…
SQL Server 一些重要视图3
1、 sys.dm_tran_locks; 为每一把锁返回一行、request_session_id 可以与sys.dm_tran_session_transactions \sys.dm_exec_connections相关联。 request_status 查看锁的分配情况 2、 sys.dm_os_waiting_tasks; 为每一个等待的任务返回一行、blocking_session_id标记是因为谁而…
Linux下将Mysql和Apache加入到系统服务里的方法
Apache加入到系统服务里面: cp /安装目录下/apache/bin/apachectl /etc/rc.d/init.d/httpd 修改httpd 在文件头部加入如下内容: ### # Comments to support chkconfig on RedHat Linux # chkconfig: 2345 90 90 # description:http server ### 保存 在打入 #chkconf…
int、bigint、smallint 和 tinyint
int、bigint、smallint 和 tinyint使用整数数据的精确数字数据类型。 bigint 从 -2^63 (-9223372036854775808) 到 2^63-1 (9223372036854775807) 的整型数据(所有数字)。存储大小为 8 个字节。 int 从 -2^31 (-2,147,483,648) 到 2^31 - 1 (2,147,483,6…
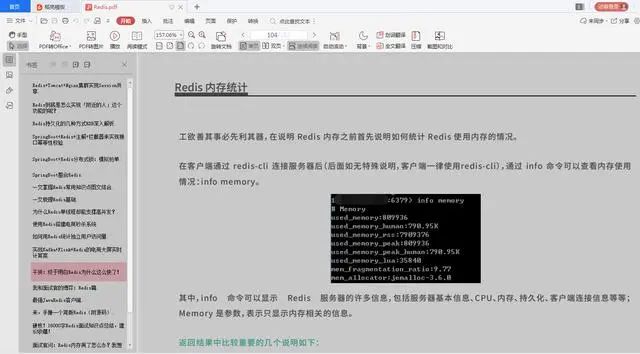
阿里技术文档:Redis+Spring全家桶+Dubbo精选+高性能+高并发
最近花了很长的时间去搜罗整理Java核心技术好文,我把每个Java核心技术的优选文章都整理成了一个又一个的文档。今天就把这些东西分享给老铁们,也能为老铁们省去不少麻烦,想学什么技能了,遇到哪方面的问题了 直接打开文档学一学就好…
SDN:软件定义网络
近期高级网络课的小组任务是在老师给定的范围内自选方向主题研究并做展示报告。我们组选了sdn。原以为这东西会是工业界无人问津的概念化产品,Google了一下却发现事实上sdn挺火的,因为它可能带来的可扩展性,一些大互联网企业也在開始涉足相关…
Linux之文本处理
1 cut:按某种方式对文件进行分割然后输出 选项:-b 按字节选取 -d 自定义分隔符 -f 和-d一起使用,指定哪个区域或字段 [rootlocalhost ~]# cat /etc/passwd | cut -d : -f 1 #以:为分隔符,打印第一个字段 […

Yahoo javascript 开源界面库YUI 和EXT
清清月儿整理 [yui][译]Yahoo!User Interface Libray 介绍 Yahoo! User Interface Library(简称yui) 是一个使用JavaScript编写的工具和控件库。它利用DOM脚本,DHTML和AJAX来构造具有丰富交互功能的Web程序。yui也包含几个核心的CSS文件。yui中的所有组件已经以开源的形式发布…

芯片开发语言:Verilog 在左,Chisel 在右
来源 | 老石谈芯在最近召开的RISC-V中国峰会上,中科院计算所的包云岗研究员团队正式发布了名为“香山”的开源高性能处RISC-V处理器。前不久我有幸和包老师就这个事情做了一次深度的交流,我们聊了关于RISC-V、还有“香山”处理器的前世今生。包老师也分享…

1.1GTK+ 的简单程序HelloWorld
1.1GTK 的简单程序HelloWorld 编译执行如图所看到的:
struts2 validate验证
转自:https://blog.csdn.net/houpengfei111/article/details/9038233 自定义拦截器 要自定义拦截器需要实现com.opensymphony.xwork2.interceptor.Interceptor接口: [java] view plaincopypublic class PermissionInterceptor implements Interceptor { …
PHP中文乱码
页面顶端加 <?php header("content-Type: text/html; charsetgbk"); ?>

收藏 | 提高数据处理效率的 Pandas 函数方法
作者:俊欣来源:关于数据分析与可视化前言大家好,这里是俊欣,今天和大家来分享几个Pandas方法可以有效地帮助我们在数据分析与数据清洗过程当中提高效率,加快工作的进程,希望大家看了之后会有收获。首先导入…
如何让两个div在同一行显示?一个float搞定
最近在学习div和css,遇到了一些问题也解决了很多以前以为很难搞定的问题。比如:如何让两个div显示在同一行呢?(不是用table表格,table对SE不太友好)其实,<div> 是一个块级元素,…
使用sudo进入root权限,以及防止root密码被恶意篡改
一、前言 sudo是允许系统管理员让普通用户执行一些或者全部的root命令的一个工具,减少了root用户的登陆和管理时间,提高了安全性。Sudo不是对shell的一个代替,它是面向每个命令的。 而防止root用户密码被恶意更改,主要是用户基本上…