中国AI已进入迷茫阶段!从技术到科学,AI该何去何从?


作者:金榕,阿里巴巴达摩院副院长、原密歇根州立大学终身教授

引言
如果从达特茅斯会议起算,AI已经走过65年历程,尤其是近些年深度学习兴起后,AI迎来了空前未有的繁荣。不过,最近两年中国AI热潮似乎有所回落,在理论突破和落地应用上都遇到了挑战,外界不乏批评质疑的声音,甚至连一些AI从业者也有些沮丧。
从90年代到美国卡耐基梅隆大学读博开始,我有幸成为一名AI研究者,见证了这个领域的一些起伏。通过这篇文章,我将试图通过个人视角回顾AI的发展,审视我们当下所处的历史阶段,以及探索AI的未来究竟在哪里。
AI的历史阶段:手工作坊
虽然有人把当下归为第三波甚至是第四波AI浪潮,乐观地认为AI时代已经到来,但我的看法要谨慎一些:AI无疑具有巨大潜力,但就目前我们的能力,AI尚处于比较初级的阶段,是技术而非科学。这不仅是中国AI的问题,也是全球AI共同面临的难题。
这几年深度学习的快速发展,极大改变了AI行业的面貌,让AI成为公众日常使用的技术,甚至还出现了一些令公众惊奇的AI应用案例,让人误以为科幻电影即将变成现实。但实际上,技术发展需要长期积累,目前只是AI的初级阶段,AI时代才刚开始。
如果将AI时代和电气时代类比,今天我们的AI技术还是法拉第时代的电。法拉第通过发现电磁感应现象,从而研制出人类第一台交流电发电机原型,不可谓不伟大。法拉第这批先行者,实践经验丰富,通过大量观察和反复实验,手工做出了各种新产品,但他们只是拉开了电气时代的序幕。电气时代的真正大发展,很大程度上受益于电磁场理论的提出。麦克斯维尔把实践的经验变成科学的理论,提出和证明了具有跨时代意义的麦克斯维尔方程。
如果人们对电磁的理解停留在法拉第的层次,电气革命是不可能发生的。试想一下,如果刮风下雨打雷甚至连温度变化都会导致断电,电怎么可能变成一个普惠性的产品,怎么可能变成社会基础设施?又怎么可能出现各种各样的电气产品、电子产品、通讯产品,彻底改变我们的生活方式?
这也是AI目前面临的问题,局限于特定的场景、特定的数据。AI模型一旦走出实验室,受到现实世界的干扰和挑战就时常失效,鲁棒性不够;一旦换一个场景,我们就需要重新深度定制算法进行适配,费时费力,难以规模化推广,泛化能力较为有限。
这是因为今天的AI很大程度上是基于经验。AI工程师就像当年的法拉第,能够做出一些AI产品,但都是知其然,不知其所以然,还未能掌握其中的核心原理。
那为何AI迄今未能成为一门科学?
答案是,技术发展之缓慢远超我们的想象。回顾90年代至今这二十多年来,我们看到的更多是AI应用工程上的快速进步,核心技术和核心问题的突破相对有限。一些技术看起来是这几年兴起的,实际上早已存在。
以自动驾驶为例,美国卡耐基梅隆大学的研究人员进行的Alvinn项目,在80年代末已经开始用神经网络来实现自动驾驶,1995年成功自东向西穿越美国,历时7天,行驶近3000英里。在下棋方面,1992年IBM研究人员开发的TD-Gammon,和AlphaZero相似,能够自我学习和强化,达到了双陆棋领域的大师水平。

(1995年穿越美国项目开始之前的团队合照)
不过,由于数据和算力的限制,这些研究只是点状发生,没有形成规模,自然也没有引起大众的广泛讨论。今天由于商业的普及、算力的增强、数据的方便获取、应用门槛的降低,AI开始触手可及。
但核心思想并没有根本性的变化。我们都是试图用有限样本来实现函数近似从而描述这个世界,有一个input,再有一个output,我们把AI的学习过程想象成一个函数的近似过程,包括我们的整个算法及训练过程,如梯度下降、梯度回传等。
同样的,核心问题也没有得到有效解决。90年代学界就在问的核心问题,迄今都未得到回答,他们都和神经网络、深度学习密切相关。比如非凸函数的优化问题,它得到的解很可能是局部最优解,并非全局最优,训练时可能都无法收敛,有限数据还会带来泛化不足的问题。我们会不会被这个解带偏了,忽视了更多的可能性?
深度学习:大繁荣后遭遇发展瓶颈
毋庸讳言,以深度学习为代表的AI研究这几年取得了诸多令人赞叹的进步,比如在复杂网络的训练方面,产生了两个特别成功的网络结构,CNN和transformer。基于深度学习,AI研究者在语音、语义、视觉等各个领域都实现了快速的发展,解决了诸多现实难题,实现了巨大的社会价值。
但回过头来看深度学习的发展,不得不感慨AI从业者非常幸运。
首先是随机梯度下降(SGD),极大推动了深度学习的发展。随机梯度下降其实是一个很简单的方法,具有较大局限性,在优化里面属于收敛较慢的方法,但它偏偏在深度网络中表现很好,而且还是出奇的好。为什么会这么好?迄今研究者都没有完美的答案。类似这样难以理解的好运气还包括残差网络、知识蒸馏、Batch Normalization、Warmup、Label Smoothing、Gradient Clip、Layer Scaling…尤其是有些还具有超强的泛化能力,能用在多个场景中。
再者,在机器学习里,研究者一直在警惕过拟合(overfitting)的问题。当参数特别多时,一条曲线能够把所有的点都拟合得特别好,它大概率存在问题,但在深度学习里面这似乎不再成为一个问题…虽然有很多研究者对此进行了探讨,但目前还有没有明确答案。更加令人惊讶的是,我们即使给数据一个随机的标签,它也可以完美拟合(请见下图红色曲线),最后得出拟合误差为0。如果按照标准理论来说,这意味着这个模型没有任何偏差(bias),能帮我们解释任何结果。请想想看,任何东西都能解释的模型,真的可靠吗,包治百病的良药可信吗?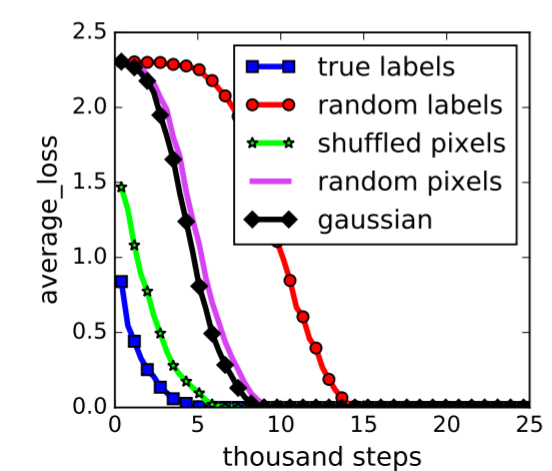
(Understanding deep learning requires rethinking generalization. ICLR, 2017.)
说到这里,让我们整体回顾下机器学习的发展历程,才能更好理解当下的深度学习。
机器学习有几波发展浪潮,在上世纪80年代到90年代,首先是基于规则(rule based)。从90年代到2000年代,以神经网络为主,大家发现神经网络可以做一些不错的事情,但是它有许多基础的问题没回答。所以2000年代以后,有一批人尝试去解决这些基础问题,最有名的叫SVM(support vector machine),一批数学背景出身的研究者集中去理解机器学习的过程,学习最基础的数学问题,如何更好实现函数的近似,如何保证快速收敛,如何保证它的泛化性?
那时候,研究者非常强调理解,好的结果应该是来自于我们对它的深刻理解。研究者会非常在乎有没有好的理论基础,因为要对算法做好的分析,需要先对泛函分析、优化理论有深刻的理解,接着还要再做泛化理论…大概这几项都得非常好了,才可能在机器学习领域有发言权,否则连文章都看不懂。如果研究者自己要做一个大规模实验系统,特别是分布式的,还需要有工程的丰富经验,否则根本做不了,那时候没有太多现成的东西,更多只是理论,多数工程实现需要靠自己去跑。
但是深度学习时代,有人做出了非常好的框架,便利了所有的研究者,降低了门槛,这真是非常了不起的事情,促进了行业的快速发展。今天去做深度学习,有个好想法就可以干,只要写上几十行、甚至十几行代码就可以跑起来。成千上万人在实验各种各样的新项目,验证各种各样新想法,经常会冒出来非常让人惊喜的结果。
但我们可能需要意识到,时至今日,深度学习已遇到了很大的瓶颈。那些曾经帮助深度学习成功的好运气,那些无法理解的黑盒效应,今天已成为它进一步发展的桎梏。
下一代AI的三个可能方向
AI的未来究竟在哪里?下一代AI将是什么?目前很难给出明确答案,但我认为,至少有三个方向值得重点探索和突破。
第一个方向:寻求对深度学习的根本理解
破除目前的黑盒状态,只有这样AI才有可能成为一门科学。具体来说,应该包括对以下关键问题的突破:
对基于DNN函数空间的更全面刻画;
对SGD(或更广义的一阶优化算法)的理解;
重新考虑泛化理论的基础。
第二个方向:知识和数据的有机融合
人类在做大量决定时,不仅使用数据,而且大量使用知识。如果我们的AI能够把知识结构有机融入,成为重要组成部分,AI势必有突破性的发展。研究者已经在做知识图谱等工作,但需要进一步解决知识和数据的有机结合,探索出可用的框架。之前曾有些创新性的尝试,比如Markov Logic,就是把逻辑和基础理论结合起来,形成了一些有趣的结构。
第三个方向:自监督学习和小样本学习
我虽然列将这个列在第三,但却是目前值得重点推进的方向,它可以弥补AI和人类智能之间的差距。
今天我们经常听说AI在一些能力上可以超越人类,比如语音识别、图像识别,最近达摩院AliceMind在视觉问答上的得分也首次超过人类,但这并不意味着AI比人类更智能。谷歌2019年有篇论文on the Measure of intelligence非常有洞察力,核心观点是说,真正的智能不仅要具有高超的技能,更重要的是能否快速学习、快速适应或者快速通用?
按照这个观点,目前AI是远不如人类的,虽然它可能在一些方面的精度超越人类,但可用范围非常有限。这里的根本原因在于:人类只需要很小的学习成本就能快速达到结果,聪明的人更是如此——这也是我认为目前AI和人类的主要区别之一。
有一个很简单的事实证明AI不如人类智能,以翻译为例,现在好的翻译模型至少要亿级的数据。如果一本书大概是十几万字,AI大概要读上万本书。我们很难想象一个人为了学习一门语言需要读上万本书。
另外有意思的对比是神经网络结构和人脑。目前AI非常强调深度,神经网络经常几十层甚至上百层,但我们看人类,以视觉为例,视觉神经网络总共就四层,非常高效。而且人脑还非常低功耗,只有20瓦左右,但今天GPU基本都是数百瓦,差了一个数量级。著名的GPT-3跑一次,碳排放相当于一架747飞机从美国东海岸到西海岸往返三次。再看信息编码,人脑是以时间序列来编,AI是用张量和向量来表达。
也许有人说,AI发展不必一定向人脑智能的方向发展。我也认为这个观点不无道理,但在AI遇到瓶颈,也找不到其他参照物时,参考人脑智能可能会给我们一些启发。比如,拿人脑智能来做对比,今天的深度神经网络是不是最合理的方向?今天的编码方式是不是最合理的?这些都是我们今天AI的基础,但它们是好的基础吗?
应该说,以GPT-3为代表的大模型,可能也是深度学习的一个突破方向,能够在一定程度上实现自学习。大模型有些像之前恶补了所有能看到的东西,碰到一个新场景,就不需要太多新数据。但这是一个最好的解决办法吗?我们目前还不知道。还是以翻译为例,很难想象一个人需要装这么多东西才能掌握一门外语。大模型现在都是百亿、千亿参数规模起步,没有一个人类会带着这么多数据。
所以,也许我们还需要继续探索。
AI的机会:AI for Science
说到这里,也许有些人会失望。既然我们AI还未解决上面的三个难题,AI还未成为科学,那AI还有什么价值?
技术本身就拥有巨大价值,像互联网就彻底重塑了我们的工作和生活。AI作为一门技术,当下一个巨大的机会就是帮助解决科学重点难题(AI for Science)。AlphaFold已经给了我们一个很好的示范,AI解决了生物学里困扰半个世纪的蛋白质折叠难题。
我们要学习AlphaFold,但没必要崇拜。AlphaFold的示范意义在于,DeepMind在选题上真是非常厉害,他们选择了一些今天已经有足够的基础和数据积累、有可能突破的难题,然后建设一个当下最好的团队,下决心去攻克。
我们有可能创造比AlphaFold更重要的成果,因为在自然科学领域,有着很多重要的open questions,AI还有更大的机会,可以去发掘新材料、发现晶体结构,甚至去证明或发现定理…AI可颠覆传统的研究方法,甚至改写历史。
比如现在一些物理学家正在思考,能否用AI重新发现物理定律?过去数百年来,物理学定律的发现都是依赖天才,爱因斯坦发现了广义相对论和狭义相对论,海森堡、薛定谔等人开创了量子力学,这些都是个人行为。如果没有这些天才,很多领域的发展会推迟几十年甚至上百年。但今天,随着数据越来越多,科学规律越来越复杂,我们是不是可以依靠AI来推导出物理定律,而不再依赖一两个天才?
以量子力学为例,最核心的是薛定谔方程,它是由天才物理学家推导出来的。但现在,已有物理学家通过收集到的大量数据,用AI自动推导出其中规律,甚至还发现了薛定谔方程的另外一个写法。这真的是一件非常了不起、有可能改变物理学甚至人类未来的事情。
我们正在推进的AI EARTH项目,是将AI引入气象领域。天气预报已有上百年历史,是一个非常重大和复杂的科学问题,需要超级计算机才能完成复杂计算,不仅消耗大量资源而且还不是特别准确。我们今天是不是可以用AI来解决这个问题,让天气预报变得既高效又准确?如果能成功,将是一件非常振奋人心的事情。当然,这注定是一个非常艰难的过程,需要时间和决心。
AI从业者:多一点兴趣,少一点功利
AI的当下局面,是对我们所有AI研究者的考验。不管是AI的基础理论突破,还是AI去解决科学问题,都不是一蹴而就的事情,需要研究者们既聪明又坚定。如果不聪明,不可能在不确定的未来抓住机会;如果不坚定,很可能就被吓倒了。
但更关键的是兴趣驱动,而不是利益驱动,不能急功近利,这些年深度学习的繁荣,使得中国大量人才和资金涌入AI领域,快速推动了行业发展,但也催生了一些不切实际的期待。像DeepMind做了AlphaGo之后,中国一些人跟进复制,但对于核心基础创新进步来说意义相对有限。
既然AI还不是一门科学,我们要去探索没人做过的事情,很有可能失败。这意味着我们必须有真正的兴趣,靠兴趣和好奇心去驱动自己前行,才能扛过无数的失败。我们也许看到了DeepMind做成了AlphaGo和AlphaFold两个项目,但可能还有更多失败的、无人听闻的项目。
在兴趣驱动方面,国外研究人员值得我们学习。像一些获得图灵奖的顶级科学家,天天还在一线做研究,亲自推导理论。还记得在CMU读书的时候,当时学校有多个图灵奖得主,他们平常基本都穿梭在各种seminar(研讨班)。我认识其中一个叫Manuel Blum,因为密码学研究获得图灵奖,有一次我参加一个seminar,发现Manuel Blum没有座位,就坐在教室的台阶上。他自己也不介意坐哪里,感兴趣就来了,没有座位就挤一挤。我曾有幸遇到过诺贝尔经济学奖得主托马斯·萨金特,作为经济学者,他早已功成名就,但他60岁开始学习广义相对论,70岁开始学习深度学习,76岁还和我们这些晚辈讨论深度学习的进展…也许这就是对研究的真正热爱吧。
说回国内,我们也不必妄自菲薄,中国AI在工程方面拥有全球领先的实力,承认AI还比较初级并非否定从业者的努力,而是提醒我们需要更坚定地长期努力,不必急于一时。电气时代如果没有法拉第这些先行者,没有一个又一个的点状发现,不可能总结出理论,让人类迈入电气时代。
同样,AI发展有赖于我们以重大创新为憧憬,一天天努力,不断尝试新想法,然后才会有一些小突破。当一些聪明的脑袋,能够将这些点状的突破联结起来,总结出来理论,AI才会产生重大突破,最终上升为一门科学。
我们已经半只脚踏入AI时代的大门,这注定是一个比电气时代更加辉煌、激动人心的时代,但这一切的前提,都有赖于所有研究者的坚定不移的努力。


往
期
回
顾
新闻
苹果新算法已混进 iOS14.3!
技术
谁说女孩子就不适合做编程?
送书
图数据库实践与创新浅析
采访
25年汽车技术老兵亲述自动驾驶新驶向

分享

点收藏

点点赞

点在看
相关文章:

Libgdx学习笔记:Simple text input
2019独角兽企业重金招聘Python工程师标准>>> 官方Wiki:https://github.com/libgdx/libgdx/wiki/Simple-text-input 实现接口TextInputListener public class MyTextInputListener implements TextInputListener { Overridepublic void input (String …

CentOS7系统下修改网卡为eth0
一、编辑网卡信息 123456789101112131415[rootlinux-node2~]# cd /etc/sysconfig/network-scripts/ #进入网卡目录 [rootlinux-node2network-scripts]# mv ifcfg-eno16777728 ifcfg-eth0 #重命名网卡名称 [rootlinux-node2network-scripts]# cat ifcfg-eth0 #编辑网卡信息 T…
squid,nginx,lighttpd反向代理的区别
反向代理从传输上分可以分为2种: 1:同步模式(apache-mod_proxy和squid) 2:异步模式(lighttpd 和 nginx) 在nginx的文档说明中,提到了异步传输模式并提到它可以减少后端连接数和压力,这是为何? 下面就来讲…
Unix_Linux系统定时器的应用(案例)
2014-05-05 Created By BaoXinjian 一、摘要 关于任务定时的命令crontab,在Linux中应用还算常见,这次为了配合开发完成一些辅助功能,以及一些备份更新等脚本,就需要crontab来完成,在windows下也就是一个批处理…

SDN 网络技术创新探索 | 移动云 TeaTalk 线上直播 倒计时启动中
在企业数字化转型、云服务和国家政策等多种因素驱动下,越来越多的企业、行业和政府机关将业务迁移到云上,随着移动云的快速发展,在“多系统、多场景、多业务”需求下,对网络提供差异化的服务能力提出了更高的要求。大规模数据中心…
学习Spring中遇到关于BeanFactory及测试类的问题
最近在学习Spring,使用的是Spring 5.0.1 学习书本中使用的是4.0 学习书本中使用以下来加载配置文件及设置 Resource resource new ClassPathResource("applicationContext.xml"); //加载配置文件 BeanFactory factory new XmlBeanFactory(resource); St…
[Java基础] Java如何实现条件编译
条件编译绝对是一个好东西。如在C或CPP中,可以通过预处理语句来实现条件编译。但是在JAVA中却没有预处理,宏定义这些东西,而有时在一些项目中,我们又需要条件编译。那么,在JAVA中,该如何实现条件编译呢&…

深度学习上的又一重点发现——利用MSCNN实现人群密度监测
作者|李秋键 出品|AI科技大本营(ID:rgznai100) 人群密度计数是指估计图像或视频中人群的数量、密度或分布,它是智能视频监控分析领域的关键问题和研究热点,也是后续行为分析、拥塞分析、异常检测和事件检测等高级视频处理任务的基础。随着城市化进程的…
nginx和squid配合搭建的web服务器前端系统
两种前端架构: lvs -> nginx前端代理 -> squid缓存lvs -> squid前端缓存 -> nginx中层代理squid在前面的优点: Squid作纯代理比较稳当前端少一级代理,响应速度会快,出问题的可能性要小功能有限,不会常被调…
聊聊jesque的几个dao
为什么80%的码农都做不了架构师?>>> 序 本文主要聊一下jesque的几个dao dao列表 FailureDAOKeysDAOQueueInfoDAOWorkerInfoDAOFailureDAO jesque-2.1.0-sources.jar!/net/greghaines/jesque/meta/dao/FailureDAO.java /*** FailureDAO provides access …
Proxy与NAT有什么区别
在internet共享上网技术上,一般有两种方式,一种是proxy代理型,一种是NAT网关型,关于两者的区别与原理,身边很多人都不是很明白,下面我来讲讲我的理解,如有不对的,欢迎指正.1.先说应用例子:服务器端,用wingate就是Proxy,用sygate就是NAT客户端,需要在IE中设置代理服务器的就是用…

【转】ubuntu 12.04 下 Vim 插件 YouCompleteMe 的安装
原文网址:http://www.cnblogs.com/jostree/p/4137402.html 作者:jostree 转载请注明出处 http://www.cnblogs.com/jostree/p/4137402.html 1.需要保证vim的版本大于7.3.584,否则的话需要更新vim 可以通过第三方源更新: 在终端输入…

「倒计时」2021年移动云 API 应用创新开发大赛,你居然还没报名?!
移动云API应用创新开发大赛自成立举办以来,因赛事覆盖广、规模大、奖励高等、吸引了移动、企业、高校各赛道选手踊跃报名。目前活动火爆呈现白热化状态,截至目前为止,累计报名600人。现距离大赛报名截止仅剩5天!!&…

snort源码的详细分析
前段时间由于工作关系,对snort入侵检测系统进行了仔细的研究,起初基本都是通过网上找的资料,对于snort系统的应用,原理,架构,配置,源码机构网上都可以找到比较详细的资料,我自己用vs…

TCP/IP四层模型和OSI七层模型
TCP/IP四层模型和OSI七层模型对应表。我们把OSI七层网络模型和Linux TCP/IP四层概念模型对应,然后将各种网络协议归类。 表1-1 TCP/IP四层模型和OSI七层模型对应表 OSI七层网络模型 Linux TCP/IP四层概念模型 对应网络协议 应用层(Application&am…

强化学习环境库 Gym 发布首个社区发布版,全面兼容 Python 3.9
作者:肖智清 来源:AI科技大本营 强化学习环境库Gym于2021年8月中旬迎来了首个社区志愿者维护的发布版Gym 0.19。该版本全面兼容Python 3.9,增加了多个新特性。 强化学习环境库的事实标准Gym迎来首个社区发布版 Gym库在强化学习领域可以说是…
SCOM电子书
SCOM电子书介绍转载于:https://blog.51cto.com/286722/1599625
京东二面的几个问题
1. tcp 连接的最大数量,tcp 用什么来标识 2. 多线程时如何避免互斥 3. protected 关键字 4. 动态库和静态库 5. 线程池 6.多继承时的虚表 网络编程需要加强转载于:https://www.cnblogs.com/simplepaul/p/7865777.html

服务器集群负载均衡(F5,LVS,DNS,CDN)区别以及选型
服务器集群负载均衡(F5,LVS,DNS,CDN)区别以及选型 下面是“黑夜路人”的《大型网站架构优化(PHP)与相关开源软件使用建议》 F5全称: F5-BIG-IP-GTM 全球流量管理器. 是一家叫F5 Networks的公司开发的四~七层交换机,软硬件捆绑. 据说最初用BSD系统,现在是…
linux下SVN不允许空白日志提交
在svn服务端通过hooks在提交时强制要求写日志。1. 在hooks目录里,复制文件pre-commit.tmpl到pre-commit2. 修改pre-commit文件,如下。#!/bin/shREPOS"$1"TXN"$2"SVNLOOK/usr/bin/svnlook #根据你的SVN目录而定LOGMSG$SVNLOOK log -t…

没有熙熙攘攘,百度VR在世界大会的一场奇妙之旅
你可听过玄奘西行的故事?没有猴子和女儿国,也没有鬼怪和妖魔,在那个故事里有的只是人心的善恶和风雨的折磨。相传,在玄奘走到楼兰时,曾被官兵追捕,他机缘巧合才悄悄逃出大狱。那茫茫大漠里,为避…
Ubuntu下搭建postgresql主从服务器(方法1)
Ubuntu下搭建postgresql主从服务器(方法1) 安装略 postgresql主服务器: $ vi /etc/postgresql/9.1/main/postgresql.conf 按a或i进入编辑模式 listen_addresses ‘*’ (默认为注释的,此处不改从postgresql同步时会报…
利用集群技术实现Web服务器的负载均衡
集群(Cluster)所谓集群是指一组独立的计算机系统构成的一个松耦合的多处理器系统,它们之间通过网络实现进程间的通信。应用程序可以通过网络共享内存进行消息传送,实现分布式计算机。 负载均衡(Load Balance)网络的负载均衡是一种动态均衡技术…

AI EARTH再立功,达摩院包揽遥感AI领域三项冠军
人类赖以生存的地球表面积大约为5.1亿平方公里,而陆地面积仅占29.2%,这些土地历经数十亿年的演变及人类生活的改造,又被分割成耕地、森林、草地、水域及建筑等等,现在,AI正在成为管理陆地资源的新途径。 8月27日&#…
node.js写一个json服务
待续转载于:https://www.cnblogs.com/progfun/p/4212099.html

试过不用循环语句撸代码吗?
译者按: 通过使用数组的reduce、filter以及map方法来避免循环语句。 原文: Coding Tip: Try to Code Without Loops 译者: Fundebug 为了保证可读性,本文采用意译而非直译。另外,本文版权归原作者所有,翻译仅用于学习。 在前一篇博…
Linux 命令 top 学习总结
本文简介 概要: 学习总结 Linux 下的 top 命令 版本: Debian 5(Lenny), top: procps version 3.2.7 日期: 2010-11-17 永久链接: http://sleepycat.org/linux/linuxcommand/top.html I. 概述 学习总结 top 命令。主要学习自 man 手册。 Linux 下 top 命令:# toptop…
android 中改变按钮按下时的颜色
原文出处:http://blog.csdn.net/nmsoftklb/article/details/9087233 a、在开发中大家都会遇到这样情况,在一个xxx.xml文件中如果有两个以上的组件有一样的属性功能时,可以把它们共同的内容抽取出来 放在styles.xml文件来声明。 然后在相应的组…

实战:使用 Mask-RCNN 的停车位检测
作者:小白来源:小白学视觉Q如何使用Mask-RCNN检测停车位可用性?我最近做了一个项目,根据安全摄像头的照片来检测停车位是否可用或被占用。我的工作有局限性,我将进一步详细介绍这些局限性,但一旦这些问题得到解决&…

Microsoft Office Communications Server 2007 R2 RTM 简体中文企业版部署速成篇之二
写文章真是件累人的事情.\(^o^)/~.OCS2007R2中的CWA有很多新特性.今天我们来看看,接着昨天的开始.本篇基于速成篇之一.Go!在一中的环境中多了,一台WIN2008的服务器,并加入域.首先在DNS里面建两条别名,指向CWA服务器!完成后,记得重新启动DNS.然后,子啊功能和角色里面添加必要的组…