一文全览机器学习建模流程(Python代码)


作者:泳鱼
来源:算法进阶
引言
随着人工智能时代的到来,机器学习已成为解决问题的关键工具,如识别交易是否欺诈、预测降雨量、新闻分类、产品营销推荐。我们接下来会详细介绍机器学习如何应用到实际问题,并概括机器学习应用的一般流程。
1
基本内容
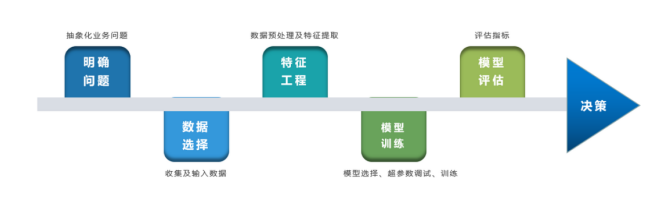
1.1明确问题
明确业务问题是机器学习的先决条件,即抽象出该问题为机器学习的预测问题:需要学习什么样的数据作为输入,目标是得到什么样的模型做决策作为输出。
一个简单的新闻分类的场景,就是学习已有的新闻及其类别标签数据,得到一个文本分类模型,通过模型对每天新的新闻做类别预测,以归类到每个新闻频道。
1.2数据选择
机器学习广泛流传一句话:“数据和特征决定了机器学习结果的上限,而模型算法只是尽可能逼近这个上限”,意味着数据及其特征表示的质量决定了模型的最终效果,且在实际的工业应用中,算法通常占了很小的一部分,大部分的工作都是在找数据、提炼数据、分析数据及特征工程。
数据选择是准备机器学习原料的关键,需要关注的是:① 数据的代表性:数据质量差或无代表性,会导致模型拟合效果差;② 数据时间范围:对于监督学习的特征变量X及标签Y,如与时间先后有关,则需要划定好数据时间窗口,否则可能会导致数据泄漏,即存在和利用因果颠倒的特征变量的现象。(如预测明天会不会下雨,但是训练数据引入明天温湿度情况);③ 数据业务范围:明确与任务相关的数据表范围,避免缺失代表性数据或引入大量无关数据作为噪音。
2
特征工程
特征工程就是对原始数据分析处理转化为模型可用的特征,这些特征可以更好地向预测模型描述潜在规律,从而提高模型对未见数据的准确性。特征工程按技术上可分为如下几步:① 探索性数据分析:数据分布、缺失、异常及相关性等情况;② 数据预处理:缺失值/异常值处理,数据离散化,数据标准化等;③ 特征提取:特征表示,特征衍生,特征选择,特征降维等;
2.1探索性数据分析
拿到数据后,可以先做探索性数据分析(EDA)去理解数据本身的内部结构及规律,如果你对数据情况不了解也没有相关的业务背景知识,不做相关的分析及预处理,直接将数据喂给传统模型往往效果不太好。通过探索性数据分析,可以了解数据分布、缺失、异常及相关性等情况,利用这些基本信息做数据的处理及特征加工,可以进一步提高特征质量,灵活选择合适的模型方法。
2.2数据预处理
异常值处理
收集的数据由于人为或者自然因素可能引入了异常值(噪音),这会对模型学习进行干扰。 通常需要处理人为引起的异常值,通过业务或技术手段(如3σ准则)判定异常值,再由(正则式匹配)等方式筛选异常的信息,并结合业务情况删除或者替换数值。
缺失值处理
数据缺失值可以通过结合业务进行填充数值、不做处理或者删除。根据特征缺失率情况及处理方式分为以下情况:① 缺失率较高,并结合业务可以直接删除该特征变量。经验上可以新增一个bool类型的变量特征记录该字段的缺失情况,缺失记为1,非缺失记为0;② 缺失率较低,结合业务可使用一些缺失值填充手段,如pandas的fillna方法、训练回归模型预测缺失值并填充;③ 不做处理:部分模型如随机森林、xgboost、lightgbm能够处理数据缺失的情况,不需要对缺失数据再做处理。
数据离散化
离散化是将连续的数据进行分段,使其变为一段段离散化的区间,分段的原则有等宽、等频等方法。通过离散化一般可以增加抗噪能力、使特征更有业务解释性、减小算法的时间及空间开销(不同算法情况不一)。
数据标准化
数据各个特征变量的量纲差异很大,可以使用数据标准化消除不同分量量纲差异的影响,加速模型收敛的效率。常用的方法有:① min-max 标准化:可将数值范围缩放到(0, 1)且无改变数据分布。max为样本最大值,min为样本最小值。
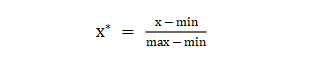
② z-score 标准化:可将数值范围缩放到0附近, 经过处理的数据符合标准正态分布。是平均值,σ是标准差。
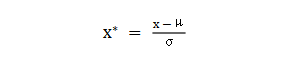
2.3特征提取
特征表示
数据需要转换为计算机能够处理的数值形式,图片类的数据需要转换为RGB三维矩阵的表示。
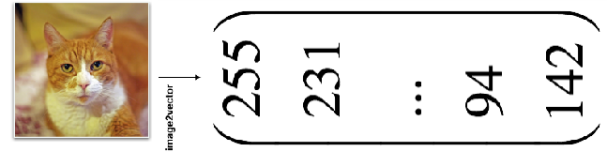
字符类的数据可以用多维数组表示,有Onehot独热编码表示(用单独一个位置的1来表示)、word2vetor分布式表示等;

特征衍生
基础特征对样本信息的表达有限,可通过特征衍生可以增加特征的非线性表达能力,提升模型效果。另外,在业务上的理解设计特征,还可以增加模型的可解释性。(如体重除以身高就是表达健康情况的重要特征。) 特征衍生是对现有基础特征的含义进行某种处理(聚合/转换之类),常用方法人工设计、自动化特征衍生(图4.15):① 结合业务的理解做人工衍生设计:聚合的方式是指对字段聚合后求平均值、计数、最大值等。比如通过12个月工资可以加工出:平均月工资,薪资最大值 等等;转换的方式是指对字段间做加减乘除之类。比如通过12个月工资可以加工出:当月工资收入与支出的比值、差值等等;
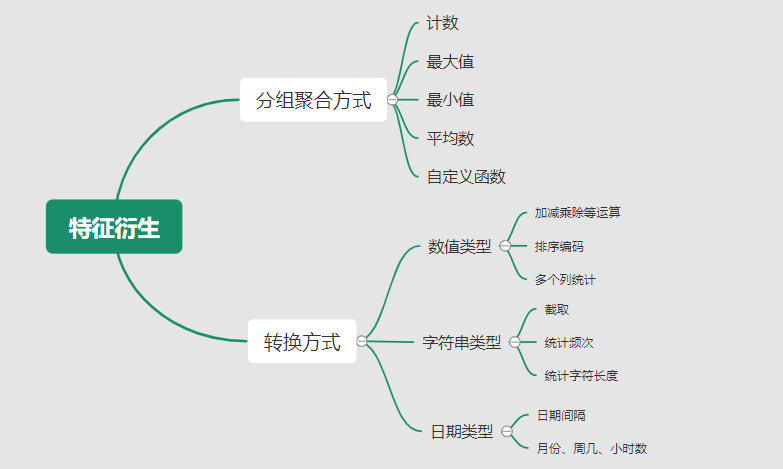
② 使用自动化特征衍生工具:如Featuretools等,可以使用聚合(agg_primitives)、转换(trans_primitives)或则自定义方式暴力生成特征;
特征选择
特征选择的目标是寻找最优特征子集,通过筛选出显著特征、摒弃冗余特征,减少模型的过拟合风险并提高运行效率。特征选择方法一般分为三类:① 过滤法:计算特征的缺失情况、发散性、相关性、信息量、稳定性等类型的指标对各个特征进行评估选择,常用如缺失率、单值率、方差验证、pearson相关系数、chi2卡方检验、IV值、信息增益及PSI等方法。② 包装法:通过每次选择部分特征迭代训练模型,根据模型预测效果评分选择特征的去留,如sklearn的RFE递归特征消除。③ 嵌入法:直接使用某些模型训练的到特征重要性,在模型训练同时进行特征选择。通过模型得到各个特征的权值系数,根据权值系数从大到小来选择特征。常用如基于L1正则项的逻辑回归、XGBOOST特征重要性选择特征。
特征降维
如果特征选择后的特征数目仍太多,这种情形下常会有数据样本稀疏、距离计算困难的问题(称为 “维数灾难”),可以通过特征降维解决。常用的降维方法有:主成分分析法(PCA)等。
3
模型训练
模型训练是利用既定的模型方法去学习数据经验的过程,这过程还需要结合模型评估以调整算法的超参数,最终选择表现较优的模型。
3.1数据集划分
训练模型前,常用的HoldOut验证法(此外还有留一法、k折交叉验证等方法),把数据集分为训练集和测试集,并可再对训练集进一步细分为训练集和验证集,以方便评估模型的性能。① 训练集(training set):用于运行学习算法,训练模型。② 开发验证集(development set)用于调整超参数、选择特征等,以选择合适模型。③ 测试集(test set)只用于评估已选择模型的性能,但不会据此改变学习算法或参数。###3.2 模型方法选择 结合当前任务及数据情况选择合适的模型方法,常用的方法如下图 ,scikit-learn模型方法的选择。此外还可以结合多个模型做模型融合。
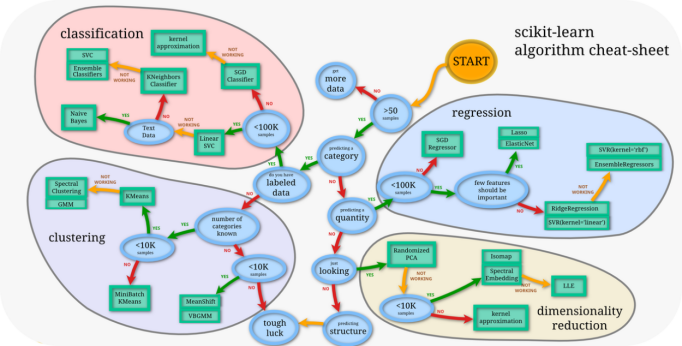
3.2训练过程
模型的训练过程即学习数据经验得到较优模型及对应参数(如神经网络最终学习到较优的权重值)。整个训练过程还需要通过调节超参数(如神经网络层数、梯度下降的学习率)进行控制优化的。调节超参数是一个基于数据集、模型和训练过程细节的实证过程,需要基于对算法的原理理解和经验,借助模型在验证集的评估进行参数调优,此外还有自动调参技术:网格搜索、随机搜索及贝叶斯优化等。
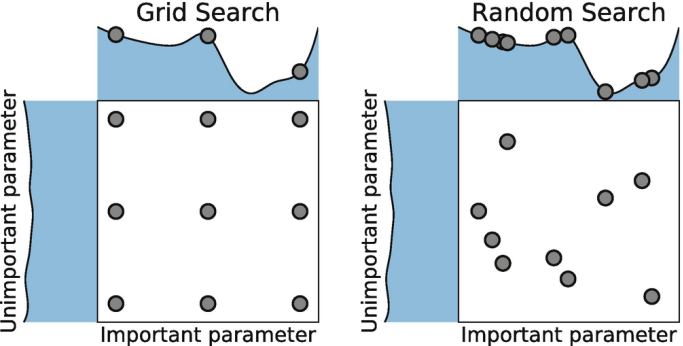
4
模型评估
机器学习的直接目的是学(拟合)到“好”的模型,不仅仅是学习过程中对训练数据的良好的学习预测能力,根本上在于要对新数据能有很好的预测能力(泛化能力),所以客观地评估模型性能至关重要。技术上常根据训练集及测试集的指标表现,评估模型的性能。
4.1评估指标
评估分类模型
常用的评估标准有查准率P、查全率R及两者调和平均F1-score 等,并由混淆矩阵的统计相应的个数计算出数值:
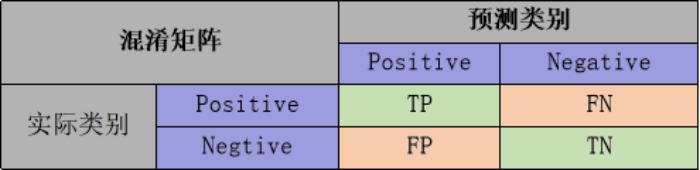
查准率是指分类器分类正确的正样本(TP)的个数占该分类器所有预测为正样本个数(TP+FP)的比例;查全率是指分类器分类正确的正样本个数(TP)占所有的正样本个数(TP+FN)的比例。F1-score是查准率P、查全率R的调和平均:
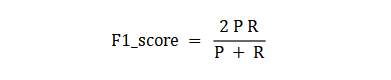
评估回归模型
常用的评估指标有MSE均方误差等。反馈的是预测数值与实际值的拟合情况。

评估聚类模型
可分为两类方式,一类将聚类结果与某个“参考模型”的结果进行比较,称为“外部指标”(external index):如兰德指数,FM指数等。另一类是直接考察聚类结果而不利用任何参考模型,称为“内部指标”(internal index):如紧凑度、分离度等。
4.2模型评估及优化
训练机器学习模型所使用的数据样本集称之为训练集(training set), 在训练数据的误差称之为训练误差(training error),在测试数据上的误差,称之为测试误差(test error)或泛化误差 (generalization error)。
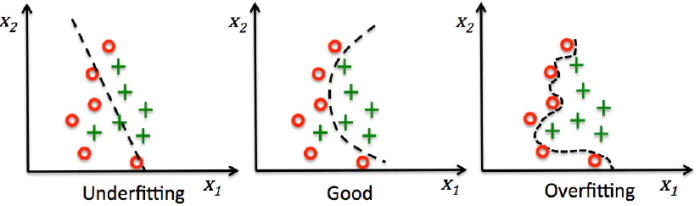
描述模型拟合(学习)程度常用欠拟合、拟合良好、过拟合,我们可以通过训练误差及测试误差评估模型的拟合程度。从整体训练过程来看,欠拟合时训练误差和测试误差均较高,随着训练时间及模型复杂度的增加而下降。在到达一个拟合最优的临界点之后,训练误差下降,测试误差上升,这个时候就进入了过拟合区域。
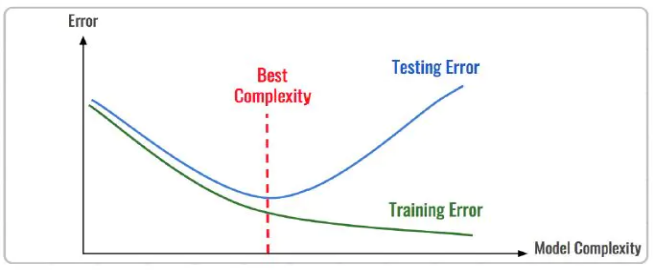
欠拟合是指相较于数据而言模型结构过于简单,以至于无法学习到数据中的规律。过拟合是指模型只过分地匹配训练数据集,以至于对新数据无良好地拟合及预测。其本质是较复杂模型从训练数据中学习到了统计噪声导致的。分析模型拟合效果并对模型进行优化,常用的方法有:

5
模型决策
决策应用是机器学习最终目的,对模型预测信息加以分析解释,并应用于实际的工作领域。需要注意的是,工程上是结果导向,模型在线上运行的效果直接决定模型的成败,不仅仅包括其准确程度、误差等情况,还包括其运行的速度(时间复杂度)、资源消耗程度(空间复杂度)、稳定性的综合考虑。
6
机器学习项目实战(数据挖掘)
6.1项目介绍
项目的实验数据来源著名的UCI机器学习数据库,该数据库有大量的人工智能数据挖掘数据。本例选用的是sklearn上的数据集版本:Breast Cancer Wisconsin DataSet(威斯康星州乳腺癌数据集),这些数据来源美国威斯康星大学医院的临床病例报告,每条样本有30个特征属性,标签为是否良性肿瘤,即有监督分类预测的问题。 项目的建模思路是通过分析乳腺癌数据集数据,特征工程,构建逻辑回归模型学习数据,预测样本的类别是否为良性肿瘤。
6.2代码实现
导入相关的Python库,加载cancer数据集,查看数据介绍, 并转为DataFrame格式。
import numpy as np
import pandas as pd
import matplotlib.pyplot as pltfrom keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.utils import plot_model
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import precision_score, recall_score, f1_score
dataset_cancer = datasets.load_breast_cancer() # 加载癌细胞数据集print(dataset_cancer['DESCR'])df = pd.DataFrame(dataset_cancer.data, columns=dataset_cancer.feature_names) df['label'] = dataset_cancer.targetprint(df.shape)df.head()
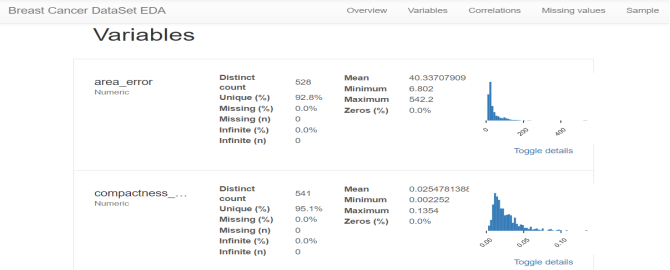
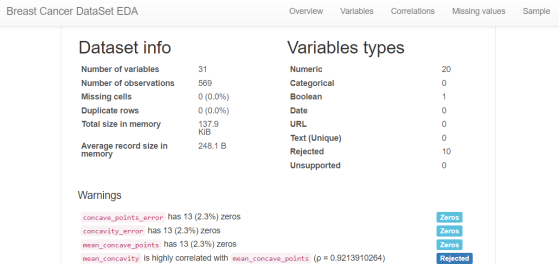
探索性数据分析EDA:使用pandas_profiling库分析数据数值情况,缺失率及相关性等。
import pandas_profilingpandas_profiling.ProfileReport(df, title='Breast Cancer DataSet EDA')
特征工程方面主要的分析及处理有:
● 分析特征无明显异常值及缺失的情况,无需处理;
● 已有mean/standard error等衍生特征,无需特征衍生;
● 结合相关性等指标做特征选择(过滤法);
● 对特征进行标准化以加速模型学习过程;
# 筛选相关性>0.99的特征清单列表及标签
drop_feas = ['label','worst_radius','mean_radius']# 选择标签y及特征x
y = df.label
x = df.drop(drop_feas,axis=1) # 删除相关性强特征及标签列# holdout验证法: 按3:7划分测试集 训练集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3)# 特征z-score 标准化
sc = StandardScaler()x_train = sc.fit_transform(x_train) # 注:训练集测试集要分别标准化,以免测试集信息泄露到模型训练
x_test = sc.transform(x_test)
模型训练:使用keras搭建逻辑回归模型,训练模型,观察模型训练集及验证集的loss损失
_dim = x_train.shape[1] # 输入模型的特征数# LR逻辑回归模型
model = Sequential() model.add(Dense(1, input_dim=_dim, activation='sigmoid',bias_initializer='uniform')) # 添加网络层,激活函数sigmoidmodel.summary()plot_model(model,show_shapes=True)
model.compile(optimizer='adam', loss='binary_crossentropy') #模型编译:选择交叉熵损失函数及adam梯度下降法优化算法model.fit(x, y, validation_split=0.3, epochs=200) # 模型迭代训练: validation_split比例0.3, 迭代epochs200次# 模型训练集及验证集的损失plt.figure()plt.plot(model.history.history['loss'],'b',label='Training loss')plt.plot(model.history.history['val_loss'],'r',label='Validation val_loss')plt.title('Traing and Validation loss')plt.legend()
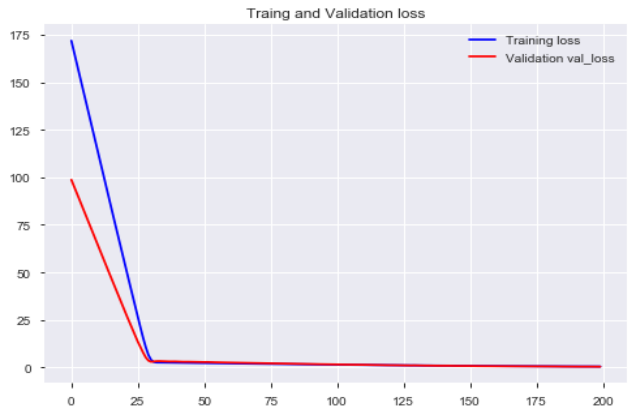
以测试集F1-score等指标的表现,评估模型的泛化能力。最终测试集的f1-score有88%,有较好的模型表现。

def model_metrics(model, x, y):"""评估指标"""yhat = model.predict(x).round() # 模型预测yhat,预测阈值按默认0.5划分result = {'f1_score': f1_score(y, yhat),'precision':precision_score(y, yhat),'recall':recall_score(y, yhat)}return result# 模型评估结果print("TRAIN")print(model_metrics(model, x_train, y_train))print("TEST")print(model_metrics(model, x_test, y_test))

往
期
回
顾
新闻
波士顿动力机器人解锁跑酷技能
大赛
移动云 API 应用创新开发大赛
技术
强化学习环境库 Gym 首个社区发布版
采访
驭势科技的无人驾驶野心

分享

点收藏

点点赞

点在看
相关文章:

CSS Selector 3
转载于:https://www.cnblogs.com/dmdj/p/4213159.html

GSM中时隙、信道、突发序列、帧的解释
刚从论坛中看到有人问GSM中时隙、信道、突发序列、帧知识。今天我们数字通信正好上到这一块,我就根据我知道的和网上搜索的回答! 1、时分多路复用技术 FDMA:频分多址 TDMA:时分多址 CDMA:码分多址 为了提高通信道的利用率,使若干彼此独立信号…

网页效率之DNS查找和并行下载
首先,一个页面所需要访问的域名数量为n,那么就需要n次DNS查找,而DNS查找通常是blocking call,就是说在得到结果之后才能继续,所以越多的DNS查找,反应速度就越慢; 雅虎的YSlow插件的规则之一&…
赛门铁克开启“容灾即服务”时代
从本地备份到异地复制再到云容灾,随着云计算技术的快速发展,以及云服务这种模式逐渐被广大企业用户所接受,将数据备份到云已经是一种可行的数据保护解决方案。12 月 16日,赛门铁克公司推出了一款全新的灾难恢复解决方案Symantec D…

再谈“去虚拟化”对深度学习系统的必要性
作者 | 袁进辉上周写了一篇《浅谈GPU虚拟化与分布式深度学习框架的异同》,想不到引起很多关注和讨论。和朋友们讨论之后,觉得这个话题值得再发散一下:首先,文章只讨论了GPU“一分多”这种“狭义”的虚拟化,还存在另外的…
Enable PowerShell script execution policy
Open Windows PowerShell with administrator Run “Set-ExecutionPolicy UnRestricted –Force” 本文转自学海无涯博客51CTO博客,原文链接http://blog.51cto.com/549687/1918870如需转载请自行联系原作者520feng2007
Linux下DNS轮询与Squid反向代理结合
一、安装反向代理服务器 1.下载反向代理服务器软件采用squid,下载地址: http://www.squid-cache.org/Versions/v2/2.2/squid-2.2.STABLE5-src.tar.gz 下载后存放在/usr/local/squid/src目录里,文件名是 squid-2.2.STABLE5 ... 一…

从iOS证书申请到签名文件生成
2019独角兽企业重金招聘Python工程师标准>>> 苹果的应用在发布时(无论是Adhoc发布还是AppStore正式发布)都需要一个签名文件。这个签名文件是由苹果后台生成的,它把用户生成的证书,注册设备,AppID等统统连在…

GitHub 热榜:来膜拜这个流弊的 AI 框架!
近年来,人工智能正在进入一个蓬勃发展的新时期,这主要得益于深度学习和CV领域近年来的发展和成就。在这其中,卷积神经网络的成功也带动了更多学术和商业应用的发展和进步。为了避免“内卷”,更多人选择学习进阶,但是仍…

ASP.net:添加.net(2.0C#)FCKeditor在线编辑器步骤
1.下载本版本的编辑器压缩包。源码下载地址 2.解压缩打开文件夹拥有如下文件:3.在VS中添加“选择项”加载在此文件夹的Bin下FredCK.FCKeditorV2.dll。4.在你的网站的web.config的 <appSettings>枝节中加入:<appSettings><add key"FC…
安装varish作为缓存和代理
1,Varish的使用有两种模式:第1种 Nginx(负载)varish(缓存)WEB第2种 Varish(缓存和负载)web2,varish是以内存作为共享容器的:内存的大小决定了它的缓存容量。相对于主要以硬盘为存储的squid来说要高效的多…

英伟达 400 亿美元收购 ARM 受阻,不妨考虑 VMware?
作者 | 马超 出品 | CSDN(ID:CSDNnews)目前半导体行业的发展可以用冰火两重天来形容,传统的桌面及移动SOC(System on a Chip,系统级芯片)市场已经基本停止增长,而云计算成了各…
单目和双目模式识别---游戏控制
http://v.youku.com/v_show/id_XMzQwMjUwNTY.html http://blog.csdn.net/anthonywanted/article/details/3024535转载于:https://www.cnblogs.com/pengkunfan/p/4220144.html
vsftpd企业应用快速部署文档
系统环境:centos 5.6 vsftpd:2.3.5 vsftpd是UNIX/Linux中非常安全且快速的FTP服务器,目前已经被许多大型站点所采用。vsftpd支持将用户名和口令保存在数据库文件或数据库服务器中。登录FTP有三种方式,匿名登录、本地用户登录和虚拟…

华为持续引领,开辟5G Massive MIMO绿色新赛道
今日,在华为举办的无线首届媒体沙龙暨MBBF2021预沟通会上,华为无线产品线首席营销官甘斌发表了“华为持续引领,开辟5G Massive MIMO绿色新赛道”的主题发言,分享了Massive MIMO的下一个突破性创新方向,引领绿色5G网络建…

MRTG—网络监控工具
最近一段时间在研究后台服务器测试技术,需要对后台服务器的各项性能指标进行实时监控和统计,也由此让我回想起之前公司曾经接触过的一个服务SNMP,SNMP是一种称之为简单网络管理协议的服务,主要是用于获取系统的流量、I/O、CPU、Me…
IBM会话设置和覆盖规则
为什么80%的码农都做不了架构师?>>> 中文版地址:http://www-01.ibm.com/support/docview.wss?uidswg21659740 Technote (troubleshooting) Problem(Abstract) It is possible to set the HTTP Session time-out in various places on th…
FOSCommentBundle功能包:设置Doctrine ODM映射
Step 2b: Setup MongoDB mapping The MongoDB implementation does not provide a concrete Comment class for your use,you must create one: MongoDB实现并不提供为您所用的具体评论类,您必须要创建一个。 1234567891011121314151617181920212223<?php// src…
lighttpd 负载均衡-反向代理+cache浅谈
Lighttpd有硬盘级别的cache-(mod_cache)和内存级别的cache(mod_mem_cache),内存级别的cache是国人的产品,我喜欢用lighttpd就是因为它具有2种选择的cache,像我的实际需求,由于系统存在很多图片,但是容量不大…

设置网页标题图标
网页图标如图上位置 设置语句如下: link rel:"SHORTCUT ICON", href:"/images/logo.ico"

DeepMind 的新强化学习系统,是迈向通用人工智能的一步吗?
作者:Ben Dickson来源:数据实战派前言尽管已经掌握围棋、星际争霸 2 和其他游戏,深度强化学习模型的主要挑战之一是,它们无法将其能力泛化到训练领域之外。这种限制使得将这些系统在现实世界中的应用变得非常困难,因为…
无法访问D盘,执行页内操作时的错误
打开D盘后出现“无法访问D:/,执行页内操作时的错误”怎么办?既便D盘有病毒也不会出现这种状况,初步判断是D: 分区表错误,用系统安装光盘开机进入纯DOS下的修复模式中用 CHKDSK /R 或 /F来修复一下试试看。在cmd下输入chkdsk空格d:空格/f本文转…

怎样修改Ubuntu的root帐户密码并使用root登录
Ubuntu版本11.04 Ubuntu是一套基于Debian的Linux系统,它追求的是“Just Work”,最新的7.10版本发布于2007年10月,不同于其他Linux发行版本,Ubuntu的所有版本都是免费的,包括企业版。第一次安装Ubuntu,发现比…

CSDN 开学见面礼!限时免费申请,手慢无!
暑假即将结束,金秋开学季来袭。别让年轻的自己虚度光阴,现在扫码申请学习资格,10+场考前辅导,600+分钟大咖讲解与答疑直播免费看!大厂CTO级别导师陪你加buff!3周带你掌握大厂工程师基…

【No.1_sizeof与strlen】
【注意】 程序语言只是我们与计算机交流并让计算机实现我们创造性思想的工具,可以并鼓励深入掌握一门语言,但千万别沉迷于钻某种语言的牛角尖,一定要把握好二者间的度 本帖属不定时连载贴,以试卷的形式提出一个比较基础的问题供大…

Linux: CentOS 7下搭建高可用集群
转载: http://linux.cn/article-3963-1.html本文以两台机器实现双集热备高可用集群,主机名node1的IP为192.168.122.168 ,主机名node2的IP为192.168.122.169 。一、安装集群软件必须软件pcs,pacemaker,corosync…
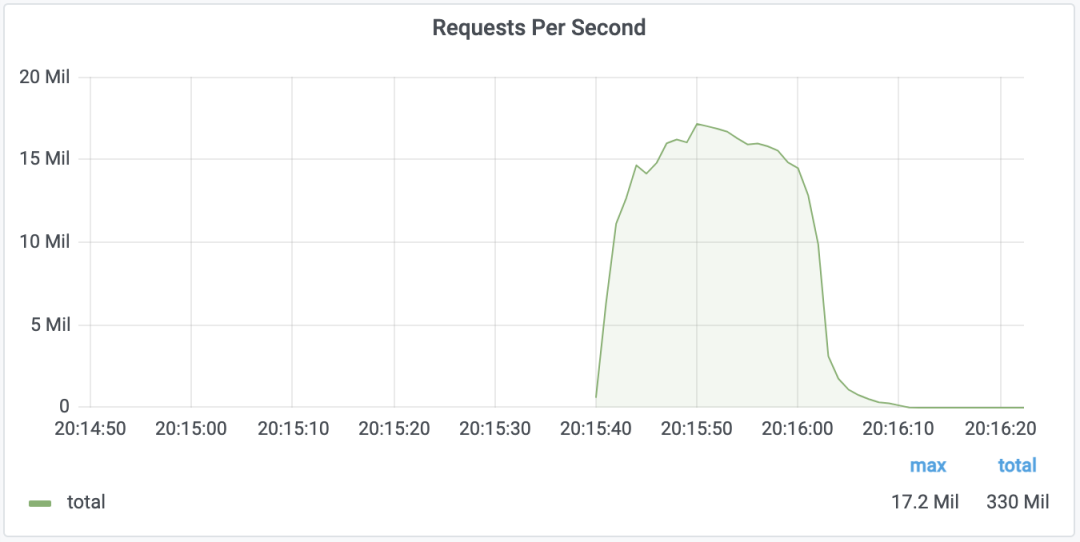
史上最大规模 DDoS 攻击,每秒 1720 万次 HTTP 请求
整理 | 禾木木 出品 | AI科技大本营(ID:rgznai100) 互联网基础设施公司 Cloudflare 表示,已化解了迄今为止所记录的最大规模的容量耗尽分布式拒绝服务(DDoS)攻击。 近日,互联网基础设施服务提供商 Cloudfl…
如何查看当前Linux的版本
查看linux的版本主要有三种方法:1) 登录到服务器执行 lsb_release -a ,即可列出所有版本信息,例如:[root3.5.5Biz-46 ~]# lsb_release -a LSB Version: 1.3Distributor ID: RedHatEnterpriseASDescription: Red Hat Enterprise Li…
AIX5.3安装bash shell
一、下载bash shell,地址是:ftp://ftp.software.ibm.com/aix/freeSoftware/aixtoolbox/RPMS/ppc/bash/ 二、安装bash shell,rpm -ivh bash-3.2-1.aix5.2.ppc.rpm三、你现在就可以用了,赶紧bash试试!----你可能会有疑问我的系统的是…
经典算法题每日演练——第六题 协同推荐SlopeOne 算法
原文:经典算法题每日演练——第六题 协同推荐SlopeOne 算法相信大家对如下的Category都很熟悉,很多网站都有类似如下的功能,“商品推荐”,"猜你喜欢“,在实体店中我们有导购来为我们服务,在网络上 我们需要同样的一种替代物&…