一文速览机器学习的类别(Python代码)


作者:泳鱼
来源:算法进阶
机器学习按照学习数据经验的不同,即训练数据的标签信息的差异,可以分为:
*监督学习(supervised learning)
*非监督学习(unsupervised learning)
*半监督学习(semi- supervised learning)
*强化学习(reinforcement learning)。
机器学习类别
监督学习
监督学习是机器学习中应用最广泛及成熟的,它是从有标签的数据样本(x,y)中,学习如何关联x到正确的y。这过程就像是模型在给定题目的已知条件(特征x),参考着答案(标签y)学习,借助标签y的监督纠正,模型通过算法不断调整自身参数以达到学习目标。
监督学习常用的模型有:线性回归、朴素贝叶斯、K最近邻、逻辑回归、支持向量机、神经网络、决策树、集成学习(如LightGBM)等。按照应用场景,以模型预测结果Y的取值有限或者无限的,可再进一步分为分类或者回归模型。
分类模型:
分类模型是处理预测结果取值有限的分类任务。如下示例通过逻辑回归分类模型,根据温湿度、风速等情况去预测是否会下雨。
逻辑回归简介
逻辑回归虽然名字有带“回归”,但其实它是一种广义线性的分类模型,由于模型简单和高效,在实际中应用非常广泛。
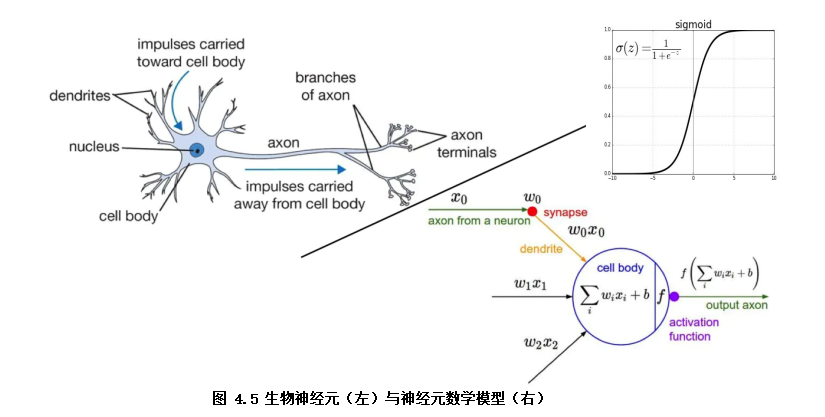
逻辑回归模型结构可以视为双层的神经网络(如图4.5)。模型输入x,通过神经元激活函数f(f为sigmoid函数)将输入非线性转换至0~1的取值输出,最终学习的模型决策函数为Y=sigmoid(wx + b)。其中模型参数w即对应各特征(x1, x2, x3...)的权重(w1,w2,w3...),b模型参数代表着偏置项,Y为预测结果(0~1范围)。
模型的学习目标为极小化交叉熵损失函数。模型的优化算法常用梯度下降算法去迭代求解损失函数的极小值,得到较优的模型参数。
代码示例
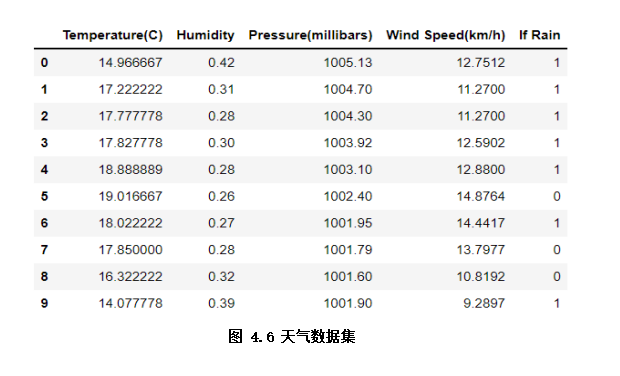
示例所用天气数据集是简单的天气情况记录数据,包括室外温湿度、风速、是否下雨等,在分类任务中,我们以是否下雨作为标签,其他为特征(如图4.6)
import pandas as pd # 导入pandas库
weather_df = pd.read_csv('./data/weather.csv') # 加载天气数据集
weather_df.head(10) # 显示数据的前10行from sklearn.linear_model import LogisticRegression # 导入逻辑回归模型
x = weather_df.drop('If Rain', axis=1) # 特征x
y = weather_df['If Rain'] # 标签y
lr = LogisticRegression()
lr.fit(x, y) # 模型训练
print("前10个样本预测结果:", lr.predict(x[0:10]) ) # 模型预测前10个样本并输出结果以训练的模型输出前10个样本预测结果为:[1 1 1 1 1 1 0 1 1 1],对比实际前10个样本的标签:[1 1 1 1 1 0 1 0 0 1],预测准确率并不高。在后面章节我们会具体介绍如何评估模型的预测效果,以及进一步优化模型效果。
回归模型
回归模型是处理预测结果取值无限的回归任务。如下代码示例通过线性回归模型,以室外湿度为标签,根据温度、风力、下雨等情况预测室外湿度。
线性回归简介
线性回归模型前提假设是y和x呈线性关系,输入x,模型决策函数为Y=wx+b。模型的学习目标为极小化均方误差损失函数。模型的优化算法常用最小二乘法求解最优的模型参数。
代码示例
from sklearn.linear_model import LinearRegression #导入线性回归模型
x = weather_df.drop('Humidity', axis=1) # 特征x
y = weather_df['Humidity'] # 标签y
linear = LinearRegression()linear.fit(x, y) # 模型训练
print("前10个样本预测结果:", linear.predict(x[0:10]) ) # 模型预测前10个样本并输出结果
非监督学习
非监督学习也是机器学习中应用较广泛的,是从无标注的数据(x)中,学习数据的内在规律。这个过程就像模型在没有人提供参考答案(y),完全通过自己琢磨题目的知识点,对知识点进行归纳、总结。按照应用场景,非监督学习可以分为聚类,特征降维和关联分析等方法。如下示例通过Kmeans聚类划分出不同品种的iris鸢尾花样本。
Kmeans聚类简介
代码示例
from sklearn.datasets import load_iris # 数据集
from sklearn.cluster import KMeans # Kmeans模型
import matplotlib.pyplot as plt # plt画图
lris_df = datasets.load_iris() # 加载iris鸢尾花数据集,数据集有150条样本,分三类的iris品种
x = lris_df.data
k = 3 # 聚类出k个簇类, 已知数据集有三类品种, 设定为3
model = KMeans(n_clusters=k)
model.fit(x) # 训练模型
print("前10个样本聚类结果:",model.predict(x[0:10]) ) # 模型预测前10个样本并输出聚类结果:[1 1 1 1 1 1 1 1 1 1]
# 样本的聚类效果以散点图展示
x_axis = lris_df.data[:,0] # 以iris花的sepal length (cm)特征作为x轴
y_axis = lris_df.data[:,1] # 以iris花的sepal width (cm)特征作为y轴
plt.scatter(x_axis, y_axis, c=model.predict(x)) # 分标签颜色展示聚类效果
plt.xlabel('Sepal length (cm)')#设定x轴注释
plt.ylabel('Sepal width (cm)')#设定y轴注释
plt.title('Iris KMeans Scatter')
plt.show() # 如图4.7聚类效果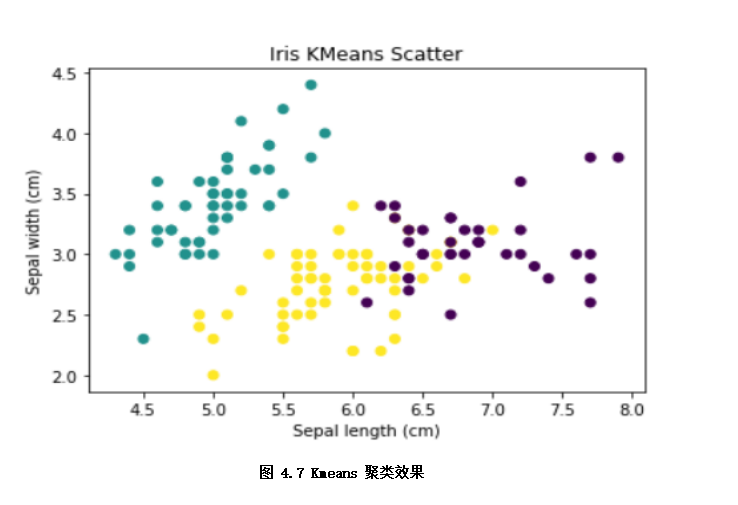
半监督学习
半监督学习是介于传统监督学习和无监督学习之间(如图4.8),其思想是在有标签样本数量较少的情况下,以一定的假设前提在模型训练中引入无标签样本,以充分捕捉数据整体潜在分布,改善如传统无监督学习过程盲目性、监督学习在训练样本不足导致的学习效果不佳的问题。按照应用场景,半监督学习可以分为聚类,分类及回归等方法。如下示例通过基于图的半监督算法——标签传播算法分类俱乐部成员。

标签传播算法简介
标签传播算法(LPA)是基于图的半监督学习分类算法,基本思路是在所有样本组成的图网络中,从已标记的节点标签信息来预测未标记的节点标签。
首先利用样本间的关系(可以是样本客观关系,或者利用相似度函数计算样本间的关系)建立完全图模型。
接着向图中加入已标记的标签信息(或无),无标签节点是用一个随机的唯一的标签初始化。
将一个节点的标签设置为该节点的相邻节点中出现频率最高的标签,重复迭代,直到标签不变即算法收敛。
代码示例
该示例的数据集空手道俱乐部是一个被广泛使用的社交网络,其中的节点代表空手道俱乐部的成员,边代表成员之间的相互关系。
import networkx as nx # 导入networkx图网络库
import matplotlib.pyplot as plt
from networkx.algorithms import community # 图社区算法
G=nx.karate_club_graph() # 加载美国空手道俱乐部图数据
#注: 本例未使用已标记信息, 严格来说是半监督算法的无监督应用案例
lpa = community.label_propagation_communities(G) # 运行标签传播算法
community_index = {n: i for i, com in enumerate(lpa) for n in com} # 各标签对应的节点
node_color = [community_index[n] for n in G] # 以标签作为节点颜色
pos = nx.spring_layout(G) # 节点的布局为spring型
nx.draw_networkx_labels(G, pos) # 节点序号
nx.draw(G, pos, node_color=node_color) # 分标签颜色展示图网络
plt.title(' Karate_club network LPA')
plt.show() #展示分类效果,不同颜色为不同类别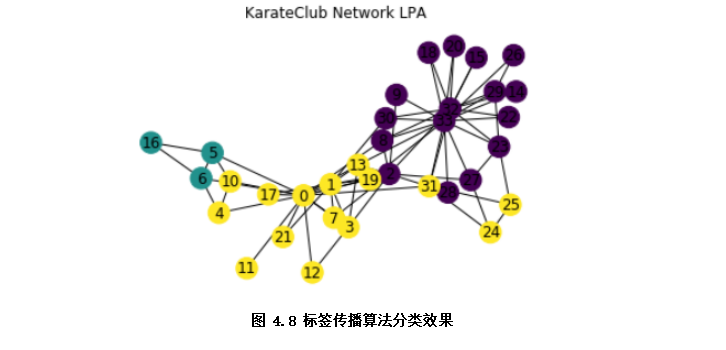
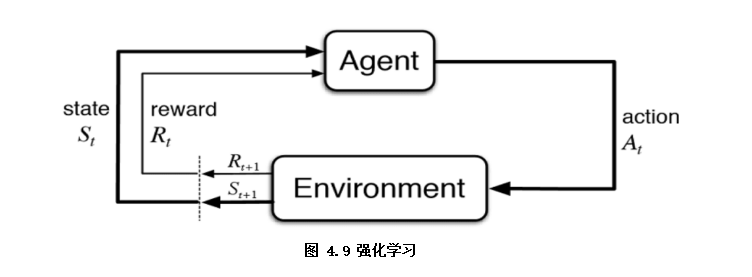
强化学习
强化学习从某种程度可以看作是有延迟标签信息的监督学习(如图4.9),是指智能体Agent在环境Environment中采取一种行为action,环境将其转换为一次回报reward和一种状态表示state,随后反馈给智能体的学习过程。本书中对强化学习仅做简单介绍,有兴趣可以自行扩展。


9月11日,面基技术大佬,相约腾讯北京总部,立即扫码报名
往
期
回
顾
技术
懂外语、会创作,机器高质量学习
福利
如何在众多简历中脱颖而出?
技术
YOLO 实现吸烟行为监测
资讯
史上最大规模 DDoS 攻击

分享

点收藏

点点赞

点在看
相关文章:

Linux下分割与合并文件的方法
Linux下分割与合并文件的方法 切割合并文件在linux下用split和cat就可以完成。下面举些实例进行说明。1.文件切割文件切割模式分为两种: 文本文件 二进制模式。 1.1文本模式 文本模式只适用于文本文件,用这种模式切割后的每个文件都是可读的。文本模式又…
将网站程序放在tmpfs下
将网站程序放在tmpfs下然后用nginx直接做对外服务呢varnish或者squid都是利用内存和它的连接数来做到加速服务.但是如果是squid->nginx->fastcgi->mysql这样当中很多连接是开销在内部的连接之中而且如果客户端请求php.squid还需要将请求再转发至nginx,然后nginx再转发…
docker 连接容器
1.通过端口映射 sudo docker run -d -P training/webapp python app.py 容器有一个内部网络和IP地址(在使用Docker部分我们使用docker inspect命令显示容器的IP地址) -P 标记创建一个容器,将容器的内部端口随机映射到主机的高端口49000到4990…

新进展!英伟达用 AI 给纪录片配音,情绪语调拿捏得稳稳地
编译 | 禾木木 出品 | AI科技大本营(ID:rgznai100) AI 已经将合成语音从单调的机器人电话和传统 GPS 导航系统转变为智能手机和智能扬声器中动听的虚拟助手。 虽然日常和Siri、小爱或小度等对话时声音还是很机械,但最新的技术进展显示&#x…
揭开Annotation的面纱
Annotation是Java5、6只后的新特征(中文称之为注解),并且越来越多的得到了应用,比如Spring、Hibernate3、Struts2、iBatis3、JPA、JUnit等等都得到了广泛应用,通过使用注解,代码的灵活性大大提高。这些都是…

使用Nginx的proxy_cache缓存功能取代Squid
[文章作者:张宴 本文版本:v1.2 最后修改:2009.01.12 转载请注明原文链接:http://blog.s135.com/nginx_cache/] Nginx从0.7.48版本开始,支持了类似Squid的缓存功能。这个缓存是把URL及相关组合当作Key,用…
oracle grant 权限
grant connect,resource,dba to user;CONNECT角色: --是授予最终用户的典型权利,最基本的 CREATE SESSION --建立会话 RESOURCE角色: --是授予开发人员的 CREATE CLUSTER --建立聚簇 CREATE …

技术沙龙 | TeaTalk 带你深度探索 SDN 网络技术再创新
越来越多的企业、行业和政府机关顺应企业数字化转型、云服务和国家政策等趋势将业务迁移上云。随着移动云的快速发展,对网络提供差异化的服务能力也提出了很多新的考验。大规模数据中心、虚拟化 SDN 网络技术及超融合软硬一体可编程设备在云网络的应用已成为行业发展…

利用windows 2003实现服务器群集的搭建与架设(一) NLB群集的创建与架设
实验场景:西安凌云系统高科技有限公司利用IIS搭建了一个WEB站点,域名为nlb.angeldevil.com。由于业务的逐渐增加,网站速度也越来越慢,而且经常出现故障,为公司的利益带来了很多的不便;公司决定使用两台WEB站…
nginx 反向代理,动静态请求分离,proxy_cache缓存及缓存清除
一,nginx反向代理配置 #tomcat 显然就是用户访问www.wolfdream.com(需要设置本地localhost,将www.wolfdream.com指向nginx所在IP)的时候(或将www.wolfdream.com直接写在nginx所在的IP地址),将请求转到到后台的tomcat服务器,即127.…

深度强化学习的前景:帮助机器掌控复杂性
作者:数据实战派 来源:数据实战派深度强化学习,即机器通过测试其行为后果来学习的方法,是人工智能最有前途和影响力的领域之一。它将深度神经网络与强化学习结合在一起,可以通过训练实现多个步骤的目标。它是自动驾驶汽…
成绩转换(15)
#include<stdio.h> int main() {int n;char ch;while(scanf("%d",&n)!EOF){if(n>100||n<0) continue;if(n>90) chA;else if(n>80) chB;else if(n>70) chC;else if(n>60) chD;else chE;printf("%c\n",ch);} }转载于:https://ww…
pangolin最新版 v2.5.2.975
Pangolin是一款帮助渗透测试人员进行Sql注入测试的安全工具。 所谓的SQL注入测试就是通过利用目标网站的某个页面缺少对用户传递参数控制或者控制的不够好的情况下出现的漏洞,从而达到获取、修改、删除数据,甚至控制数据库服务器、Web服务器的目的的测试…
nginx 的proxy_cache才是王道
nginx 的proxy_cache才是性价比最高的缓存,我目前的配置是LiteSpeednginx,可以参考apachenginx将动态内容交给LiteSpeed或apache来处理,然后利用proxy_cache反向代理全部缓存在硬盘,变成静态内容,大家都知道nginx跑静态内容是有多厉害了吧,所以这样就可以小内存跑大PV.但是这样…
Android 占位符 %1$s %1$d
1、整型,比如“我今年23岁了”,这个23是整型的。在string.xml中可以这样写,<string name"old">我今年%1$d岁了</string> 在程序中,使用 [java] view plaincopy String sAgeFormat getResources().getStrin…

谁说技术男不适合养猫!90后程序员2天做出猫咪情绪识别软件
整理 | 王晓曼出品 | CSDN(ID:CSDNnews)9月1日,一则关于#程序员2天做出猫咪情绪识别软件#的话题登上微博热搜,参与阅读的人数达到了8218.1万,讨论次数1.3万,引发网友们的热议。高手在民间&#…
符合RESTful的接口规范
把api放在专属域名下,要带版本号 api的url中应该只有名词,和数据库的表或文档资源相对应;对资源(collection)的具体操作类型则由http方法动词表示 (安全性:不改变资源状态,类似只读&…
Nginx proxy_cache 使用示例
原文出处:http://blog.chenlb.com/2010/04/nginx-proxy-cache.html 动态网站使用缓存是很有必要的。前段时间使用了 nginx proxy_stroe 来保存静态页面,以达到缓存的目的。当然 proxy stroe 用来做缓存是不够好的方案。 缓存这一块当然还有 squid 之类的…
Lync 小技巧-49-Lync 自动备份-批量管理-用户(免费视频)
自从2010年开始,自从Lync Server 2010开始,我都在研究Lync 自动备份和批量管理用户,当年都做成功,做标准过.不过都是图片,未写博客,为什么呢?有可能你有这样那样的假设,但是今天可以…

数学很差的人能当程序员吗?
【CSDN 编者按】作者在大学时代受《程序员》杂志的启发,从数学专业投身计算机编程,毕业后进入软件开发行业。过去9年,他去过大厂敲代码,也曾在创业公司带过团队,一直从事“下一代”软件技术的研发,对于网上…
Nginx 学习笔记(六)引入线程池 性能提升9倍
原文地址:https://www.cnblogs.com/shitoufengkuang/p/4910333.html 一、前言 1、Nignx版本:1.7.11 以上 2、NGINX采用了异步、事件驱动的方法来处理连接。这种处理方式无需(像使用传统架构的服务器一样)为每个请求创建额外的专用…
Nginx源代码分析 - 日志处理
我看Nginx源代码的时候,感觉整个系统都在传递log指针。log在nginx里是比较关键的。日志和内存分配是最基础的两个起点代码,最好是在自己写的程序框架中早点完善并实现。以免未来要用大量的精力调整。1. 日志的源代码位置日志的源代码在src/code/ngx_log.…

strom.yaml配置
2019独角兽企业重金招聘Python工程师标准>>> 配置storm.yaml storm发行版在conf/storm.yaml包含了一些配置信息。你可以在这里看到默认配置。storm.yaml里面的配置比default.xml的优先级要高, 下面是要运行storm集群所必须的配置: 1. storm.zookeeper.se…

用 Python 快速制作海报级地图
作者:费弗里 来源:Python大数据分析 1 简介 基于Python中诸如matplotlib等功能丰富、自由度极高的绘图库,我们可以完成各种极富艺术感的可视化作品,关于这一点我在系列文章在模仿中精进数据可视化中已经带大家学习过很多案例了。 …

关于VS2012如何安装Windows Phone Toolkit
最近也是碰到很多问题,在编程的时候。这个问题是我遇到的比较棘手的一个,问了一堆人都说得很是模糊,最后还是琢磨出来了,深感欣慰。写下来以防以后忘记了怎么操作的,也期望能帮助到遇到同样问题的你。 首先让我先说了几…
论Oracle 11g数据库备份与恢复策略
11G中有个新特性,当表无数据时,不分配segment,以节省空间解决方案:1、insert一行,再roolback就会产生segment了该方法是在空表中插入一行数据,再删除,就会产生segment。则在数据库导出时可以导出…
使Apache实现gzip压缩
众所周知,在HTTP1.1中支持gzip压缩,这样可以缩小页面的容量从而加快页面的显示速度。可以使用常用HTTP抓包工具来检测一下你的站点是否开始了gzip压缩。 Apache默认的http.conf配置文件中没有开启gzip压缩,apache1.3.x可以用mod_gzip进行优化…
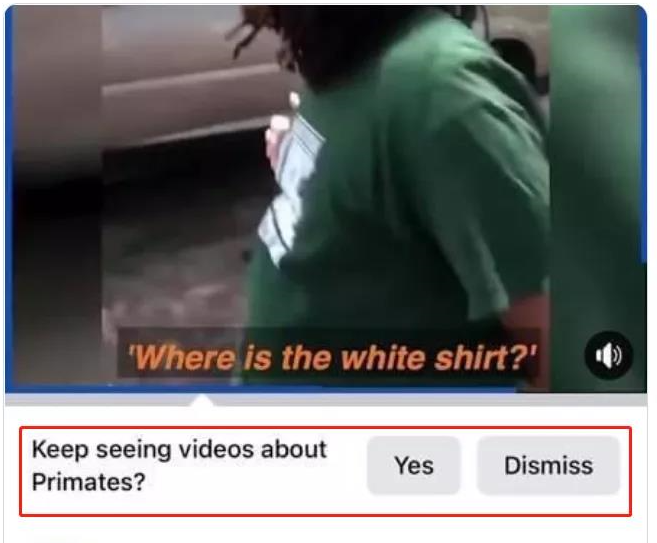
脸书 AI 识别误将黑人标记为「灵长类动物」
整理 | 禾木木 出品 | AI科技大本营(ID:rgznai100) 最近,Facebook用户在观看一段以黑人为主角的视频时,会看到一个自动生成的提示,询问他们是否愿意“继续观看灵长类动物的视频”。 视频的内容其实是几个黑人和警察发…
Forefront for OCS2007之部署
1. 前提准备①OCS服务器②创建一个域账户,用于Forefront IM通告。帐户还将用于运行 ForefrontRTCProxy 服务用来截取来自 Office Communications Server SIP 通信进行扫描。此帐户必须满足以下要求:该帐户必须被为ForefrontRTCProxy服务授予 “ 运行为服…
Memcached在大型网站中应用
memcached是一个高性能的分布式的内存对象缓存系统,通过在内存里维护一个统一的巨大的hash表,它能够用来存储各种格式的数据,包括图像、视频、文件以及数据库检索的结果等。最初为了加速 LiveJournal 访问速度而开发的,后来被很多大型的网站采…