模型神器组合,yyds!

作者 | 东哥起飞
来源 | Python数据科学
最近在kaggle上有一个调参神器非常热门,在top方案中频频出现,它就是OPTUNA。知道很多小伙伴苦恼于漫长的调参时间里,这次结合一些自己的经验,给大家带来一个LGBM模型+OPTUNA调参的使用教程,这对可谓是非常实用且容易上分的神器组合了,实际工作中也可使用。

关于LightGBM不多说了,之前分享过很多文章,它是在XGBoost基础上对效率提升的优化版本,由微软发布的,运行效率极高,且准确度不降。目前是公认比较好,且广泛使用的机器学习模型了,分类回归均可满足。
关于调参,也就是模型的超参数调优,可能你会想到GridSearch。确实最开始我也在用GridSearch,暴力美学虽然好,但它的缺点很明显,运行太耗时,时间成本太高。相比之下,基于贝叶斯框架下的调参工具就舒服多了。这类开源工具也很多,常见的比如HyperOPT。当然今天主角不是它,而是另外一个更香的OPTUNA,轻量级且功能更强大,速度也是快到起飞!
因为需要用 LGBM 配合举例讲解,下面先从 LGBM 的几个主要超参数开始介绍,然后再根据这些超参设置 Optuna 进行调参。
LightGBM参数概述
通常,基于树的模型的超参数可以分为 4 类:
影响决策树结构和学习的参数
影响训练速度的参数
提高精度的参数
防止过拟合的参数
大多数时候,这些类别有很多重叠,提高一个类别的效率可能会降低另一个类别的效率。如果完全靠手动调参,那会比较痛苦。所以前期我们可以利用一些自动化调参工具给出一个大致的结果,而自动调参工具的核心在于如何给定适合的参数区间范围。 如果能给定合适的参数网格,Optuna 就可以自动找到这些类别之间最平衡的参数组合。
下面对LGBM的4类超参进行介绍。
1、控制树结构的超参数
max_depth 和 num_leaves
在 LGBM 中,控制树结构的最先要调的参数是max_depth(树深度) 和 num_leaves(叶子节点数)。这两个参数对于树结构的控制最直接了断,因为 LGBM 是 leaf-wise 的,如果不控制树深度,会非常容易过拟合。max_depth一般设置可以尝试设置为3到8。
这两个参数也存在一定的关系。由于是二叉树,num_leaves最大值应该是2^(max_depth)。所以,确定了max_depth也就意味着确定了num_leaves的取值范围。
min_data_in_leaf
树的另一个重要结构参数是min_data_in_leaf,它的大小也与是否过拟合有关。它指定了叶子节点向下分裂的的最小样本数,比如设置100,那么如果节点样本数量不够100就停止生长。当然,min_data_in_leaf的设定也取决于训练样本的数量和num_leaves。对于大数据集,一般会设置千级以上。
提高准确性的超参数
learning_rate 和 n_estimators
实现更高准确率的常见方法是使用更多棵子树并降低学习率。换句话说,就是要找到LGBM中n_estimators和learning_rate的最佳组合。
n_estimators控制决策树的数量,而learning_rate是梯度下降的步长参数。经验来说,LGBM 比较容易过拟合,learning_rate可以用来控制梯度提升学习的速度,一般值可设在 0.01 和 0.3 之间。一般做法是先用稍多一些的子树比如1000,并设一个较低的learning_rate,然后通过early_stopping找到最优迭代次数。
max_bin
除此外,也可以增加max_bin(默认值为255)来提高准确率。因为变量分箱的数量越多,信息保留越详细,相反,变量分箱数量越低,信息越损失,但更容易泛化。这个和特征工程的分箱是一个道理,只不过是通过内部的hist直方图算法处理了。如果max_bin过高,同样也存在过度拟合的风险。
更多超参数来控制过拟合
lambda_l1 和 lambda_l2
lambda_l1 和 lambda_l2 对应着 L1 和 L2 正则化,和 XGBoost 的 reg_lambda 和 reg_alpha 是一样的,对叶子节点数和叶子节点权重的惩罚,值越高惩罚越大。这些参数的最佳值更难调整,因为它们的大小与过拟合没有直接关系,但会有影响。一般的搜索范围可以在 (0, 100)。
min_gain_to_split
这个参数定义着分裂的最小增益。这个参数也看出数据的质量如何,计算的增益不高,就无法向下分裂。如果你设置的深度很深,但又无法向下分裂,LGBM就会提示warning,无法找到可以分裂的了。参数含义和 XGBoost 的 gamma 是一样,说明数据质量已经达到了极限了。比较保守的搜索范围是 (0, 20),它可以用作大型参数网格中的额外正则化。
bagging_fraction 和 feature_fraction
这两个参数取值范围都在(0,1)之间。
feature_fraction指定训练每棵树时要采样的特征百分比,它存在的意义也是为了避免过拟合。因为有些特征增益很高,可能造成每棵子树分裂的时候都会用到同一个特征,这样每个子树就同质化了。而如果通过较低概率的特征采样,可以避免每次都遇到一样的强特征,从而让子树的特征变得差异化,即泛化。
bagging_fraction指定用于训练每棵树的训练样本百分比。要使用这个参数,还需要设置 bagging_freq,道理和feature_fraction一样,也是让没棵子树都变得好而不同。
在 Optuna 中创建搜索网格
Optuna 中的优化过程首先需要一个目标函数,该函数里面包括:
字典形式的参数网格
创建一个模型(可以配合交叉验证
kfold)来尝试超参数组合集用于模型训练的数据集
使用此模型生成预测
根据用户定义的指标对预测进行评分并返回
下面给出一个常用的框架,模型是5折的Kfold,这样可以保证模型的稳定性。最后一行返回了需要优化的 CV 分数的平均值。目标函数可以自己设定,比如指标logloss最小,auc最大,ks最大,训练集和测试集的auc差距最小等等。
import optuna # pip install optuna
from sklearn.metrics import log_loss
from sklearn.model_selection import StratifiedKFolddef objective(trial, X, y):# 后面填充param_grid = {}cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=1121218)cv_scores = np.empty(5)for idx, (train_idx, test_idx) in enumerate(cv.split(X, y)):X_train, X_test = X.iloc[train_idx], X.iloc[test_idx]y_train, y_test = y[train_idx], y[test_idx]model = lgbm.LGBMClassifier(objective="binary", **param_grid)model.fit(X_train,y_train,eval_set=[(X_test, y_test)],eval_metric="binary_logloss",early_stopping_rounds=100,)preds = model.predict_proba(X_test)cv_scores[idx] = predsreturn np.mean(cv_scores)下面是参数的设置,Optuna比较常见的参数设置方式有suggest_categorical,suggest_int,suggest_float。其中,suggest_int和suggest_float的设置方式为(参数,最小值,最大值,step=步长)。
def objective(trial, X, y):# 字典形式的参数网格param_grid = {"n_estimators": trial.suggest_categorical("n_estimators", [10000]),"learning_rate": trial.suggest_float("learning_rate", 0.01, 0.3),"num_leaves": trial.suggest_int("num_leaves", 20, 3000, step=20),"max_depth": trial.suggest_int("max_depth", 3, 12),"min_data_in_leaf": trial.suggest_int("min_data_in_leaf", 200, 10000, step=100),"max_bin": trial.suggest_int("max_bin", 200, 300),"lambda_l1": trial.suggest_int("lambda_l1", 0, 100, step=5),"lambda_l2": trial.suggest_int("lambda_l2", 0, 100, step=5),"min_gain_to_split": trial.suggest_float("min_gain_to_split", 0, 15),"bagging_fraction": trial.suggest_float("bagging_fraction", 0.2, 0.95, step=0.1),"bagging_freq": trial.suggest_categorical("bagging_freq", [1]),"feature_fraction": trial.suggest_float("feature_fraction", 0.2, 0.95, step=0.1),}创建 Optuna 自动调起来
下面是完整的目标函数框架,供参考:
from optuna.integration import LightGBMPruningCallbackdef objective(trial, X, y):# 参数网格param_grid = {"n_estimators": trial.suggest_categorical("n_estimators", [10000]),"learning_rate": trial.suggest_float("learning_rate", 0.01, 0.3),"num_leaves": trial.suggest_int("num_leaves", 20, 3000, step=20),"max_depth": trial.suggest_int("max_depth", 3, 12),"min_data_in_leaf": trial.suggest_int("min_data_in_leaf", 200, 10000, step=100),"lambda_l1": trial.suggest_int("lambda_l1", 0, 100, step=5),"lambda_l2": trial.suggest_int("lambda_l2", 0, 100, step=5),"min_gain_to_split": trial.suggest_float("min_gain_to_split", 0, 15),"bagging_fraction": trial.suggest_float("bagging_fraction", 0.2, 0.95, step=0.1),"bagging_freq": trial.suggest_categorical("bagging_freq", [1]),"feature_fraction": trial.suggest_float("feature_fraction", 0.2, 0.95, step=0.1),"random_state": 2021,}# 5折交叉验证cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=1121218)cv_scores = np.empty(5)for idx, (train_idx, test_idx) in enumerate(cv.split(X, y)):X_train, X_test = X.iloc[train_idx], X.iloc[test_idx]y_train, y_test = y[train_idx], y[test_idx]# LGBM建模model = lgbm.LGBMClassifier(objective="binary", **param_grid)model.fit(X_train,y_train,eval_set=[(X_test, y_test)],eval_metric="binary_logloss",early_stopping_rounds=100,callbacks=[LightGBMPruningCallback(trial, "binary_logloss")],)# 模型预测preds = model.predict_proba(X_test)# 优化指标logloss最小cv_scores[idx] = log_loss(y_test, preds)return np.mean(cv_scores)上面这个网格里,还添加了LightGBMPruningCallback,这个callback类很方便,它可以在对数据进行训练之前检测出不太好的超参数集,从而显着减少搜索时间。
设置完目标函数,现在让参数调起来!
study = optuna.create_study(direction="minimize", study_name="LGBM Classifier")
func = lambda trial: objective(trial, X, y)
study.optimize(func, n_trials=20)direction可以是minimize,也可以是maximize,比如让auc最大化。然后可以设置trials来控制尝试的次数,理论上次数越多结果越优,但也要考虑下运行时间。
搜索完成后,调用best_value和bast_params属性,调参就出来了。
print(f"\tBest value (rmse): {study.best_value:.5f}")
print(f"\tBest params:")for key, value in study.best_params.items():print(f"\t\t{key}: {value}")-----------------------------------------------------
Best value (binary_logloss): 0.35738Best params:device: gpulambda_l1: 7.71800699380605e-05lambda_l2: 4.17890272377219e-06bagging_fraction: 0.7000000000000001feature_fraction: 0.4bagging_freq: 5max_depth: 5num_leaves: 1007min_data_in_leaf: 45min_split_gain: 15.703519227860273learning_rate: 0.010784015325759629n_estimators: 10000得到这个参数组合后,我们就可以拿去跑模型了,看结果再手动微调,这样就可以省很多时间了。
结语
本文给出了一个通过Optuna调参LGBM的代码框架,使用及其方便,参数区间范围需要根据数据情况自行调整,优化目标可以自定定义,不限于以上代码的logloss。
关于Optuna的强大之处,后面会对比同类的调参工具介绍,敬请期待 。
。


往
期
回
顾
资讯
GitHub的AI编程代码漏洞40%
技术
谷歌新深度学习系统促进放射科
资讯
英伟达用 AI 给自家纪录片配音
资讯
Tidio AI 趋势报告!超精彩

分享

点收藏

点点赞

点在看
相关文章:

理解http响应头中的Date和Age
Date:Date头域表示消息发送的时间,时间的描述格式由rfc822定义。例如,Date: Mon, 04 Jul 2011 05:53:36 GMT。 Age:当代理服务器用自己缓存的实体去响应请求时,用该头部表明该实体从产生到现在经过多长时间了。 比如访…

linux 保留内核中sas驱动的加载导致crash问题
[rootlocalhost ~]# uname -a Linux localhost.localdomain 3.10.0-693.5.2.el7.x86_64 问题描述,在crash的时候,小内核因为分配中断号失败而触发panic,打印如下:(备注:本文大内核就是指正常运行的内核&am…
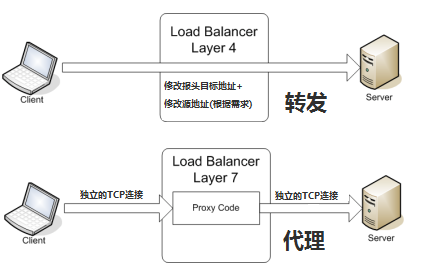
四层和七层负载均衡的区别
负载均衡设备也常被称为"四到七层交换机",那补充:所谓四层就是基于IP端口的负载均衡;七层就是基于URL等应用层信息的负载均衡;同理,还有基于MAC地址的二层负载均衡和基于IP地址的三层负载均衡。换句换说&…

关于数据库,你可能最想知道的几件事
【CSDN 编者按】随着技术不断更新,数据库的发展可谓全面开花,也吸引了越来越多人的关注,但大家真的都足够了解数据库吗?作者 | 易璜珵 责编 | 侯淼淼出品 | 《新程序员》互联网飞速发展的时代里,数据库、中间件和…
Visual C++ 2012/2013的内存溢出检測工具
在过去,每次编写C/C程序的时候,VLD差点儿是我的标配。有了它,就能够放心地敲代码,随时发现内存溢出。 VLD最高可支持到Visual Studio 2012。不知道以后会不会支持Visual Studio 2013,但反正眼下是不支持的。 相关的讨论…

.NetCore Docker
转载于:https://blog.51cto.com/linhongquan/2047736

集生态之力跨城市数字化之难题,英特尔交上了一份完美答卷
随着数字孪生、人工智能、大数据、云计算、区块链等新兴技术的发展成熟,社会正加大步伐向数字化时代迈进。城市,作为社会民生与经济发展的重要载体,自然站在了数字化建设历程的第一线。当然,数字化城市建设并不是搭建“空中楼阁”…
设置Squid Cache_mem大小
squid代理服务器一般的Unix,Linux都自带。我使用的是CentOS 5.3,Squid是自已编译的。 Squid 默认 cache_mem 100 16 256 打开/etc/squid/squid.conf 配置 $vi /etc/squid/squid.conf #http_port ,是代理的端口,如果没有其他的http服务占用80端口或8080…
centos iptables关于ping
配置iptables策略后,一般来说INPUT都是DROP然后配置需要通过的 当执行: iptables -P INPUT DROP 后,机器就不能被ping通了! 因为icmp没有添加到规则中! 于是我执行如下代码: iptables -A INPUT -p icmp -j …
禁止蒙层底部页面跟随滚动
场景概述 弹窗是一种常见的交互方式,而蒙层是弹窗必不可少的元素,用于隔断页面与弹窗区块,暂时阻断页面的交互。但是,在蒙层元素中滑动的时候,滑到内容的尽头时,再继续滑动,蒙层底部的页面会开始…
squid日志文件太大,怎样处理?
Squid 默认的5天会压缩一次, 在 /etc/logrotate.d/squid中有设置。如果你修改了日志的位置, 请修改 /etc/logrotate.d/squid /home/log/squid/access.log { weekly rotate 5 copytruncate compress notifempty missingok } /home…

安卓系列七(广播机制)
2019独角兽企业重金招聘Python工程师标准>>> 一、什么是广播接收者 广播接收者(BroadcastReceiver)用于接收广播Intent,广播Intent的发送是通过调用Context.sendBroadcast()、Context.sendOrderedBroadcast()来实现的。通常一个广…

第九代小冰惊喜登场,多端融合且琴棋书画样样精通
谈及智能助手,相信大家都不会漏过小冰这款具有划时代意义的产品。从最初的微软小冰到现在的第九代小冰,AI的技术在不断的演进,而小冰也从最初的贴心助手变成了如今琴棋书画样样精通的人工智能前沿技术载体。 北京时间2021年9月22日ÿ…
C++对象赋值的四种方式
1. 引用作为参数的方式传递. 1 GetObject(Object& obj) 2 { 3 obj.value value1; 4 } 特点: 在外部构造一个对象. 把该对象以引用的方式传递到函数中. 从而实现对该对象的改变, 该参数实质是一个[out]类型的参数, 而非[in]类型的参数. 这里的引用可以称为别名. 点评: …

金九银十,不要跳槽!
前言:又到了求职的金九银十的黄金月份,我相信有不少小伙伴已经摩拳擦掌的准备寻找下一份工作。就目前国内的面试模式来讲,在面试前积极的准备面试,复习整个 Java 知识体系将变得非常重要,可以很负责任地说一句,复习准备…
FreeMarker标签介绍
FreeMarker标签使用 一、FreeMarker模板文件主要有4个部分组成 1、文本,直接输出的部分 2、注释,即<#--...-->格式不会输出 3、插值(Interpolation):即${..}或者#{..}格式的部分,将使用数据模型中的部分替代输…
让Squid 显示本地时间
Squid的Error messages 默认的时间显示的GMT时间,而非本地时间,这个有时候看着很别扭。 下面是修改方法,找到Squid的源文件src/errorpage.c 大概在60多行, { ERR_SQUID_SIGNATURE, "\n<BR clear\"all\">\n&…
linux mysql 命令 大全
linux mysql 命令 大全 1.linux下启动mysql的命令: mysqladmin start /ect/init.d/mysql start (前面为mysql的安装路径) 2.linux下重启mysql的命令: mysqladmin restart /ect/init.d/mysql restart (前面为mysql的安装路径) 3.linux下关闭mysql的…

助力5G行业应用扬帆启航,第二届5G毫米波产业高峰论坛圆满召开
当前,5G发展如火如荼,成为引领我国高质量发展的新引擎。5G要想进一步实现向千行百业拓展,离不开全频段的支持,推动5G毫米波发展成为各国共识。为进一步推进5G毫米波产业发展,释放5G全部潜能,助力5G行业应用…
Bootstrap3.x - 源代码分析
参照http://v3.bootcss.com/css/ 文档与源代码colors 比较全面定义总结有意义的颜色。所有uI要用的颜色,都先从已定义的读,这样保证样式的同一性,而且方便以后开发主题库。(建议想自己写css模块的,可以参考一下bootstrap里颜色定义…
清除Squid缓存的小工具
[ 2007-11-2 17:49 | by 张宴 ] 以前我写过一篇《清除指定squid缓存文件的脚本》,但在取URL时存在10%的错误率。如今找到一款老外的程序,可以批量清除某类URL的Squid缓存,支持正则表达式。下载网址:http://www.wa.apana.org.au/~d…

谷歌 AI 编舞师,连张艺兴最喜欢的 Krump 都不在话下
编译 | 禾木木 出品 | AI科技大本营(ID:rgznai100) 舞蹈一直是文化、仪式和庆祝活动的重要组成部分,也是一种自我表达的方式。今天,存在多种形式的舞蹈,从舞厅到迪斯科。然而,舞蹈是一种需要练习的艺术形…
Python 字典(Dictionary)
Python 字典(Dictionary)字典是另一种可变容器模型,且可存储任意类型对象。字典的每个键值(key>value)对用冒号(:)分割,每个对之间用逗号(,)分割,整个字典包括在花括号({})中 ,格式如下所示:d {key1 : value1, key2 : value2 …
Varnish Cache 3.0.0安装
https://www.varnish-cache.org/installation/redhat Installation on RedHat 先按需要的模块 在安装软件包之前首先看看主机上的 automake autoconf libtool ncurses-devel libxslt groff pcre-devel pkgconfig软件包是否已经安装 如果没有那么就要首先安装ÿ…
three.js绘制过程(二)
2019独角兽企业重金招聘Python工程师标准>>> 同一个场景中可以有多个摄像机,同一个屏幕缓冲区可以分块绘制不同的物体。 WeblGLRender 中autoClear 设定为false之后, 每次绘制不会清空缓冲区; setSize 设定canvas的大小 setViewpo…
AI 不可以作为专利认证发明人,“因为它不是人”
编译 | 禾木木 出品 | AI科技大本营(ID:rgznai100) 英格兰和威尔士上诉法院本周驳回了一名男子的请求,该男子要求法院承认他的人工智能系统为两项专利的发明者。 总部位于美国的 Imagination Engines 的创始人 Stephen Thaler 想要给智能机器…
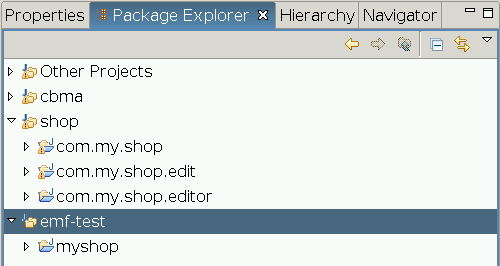
使用工作集(Working Set)整理项目
Eclipse鼓励将不同的功能模块划分为独立的项目存在,这样不但结构清晰,组织起来还非常灵活,因为我们可以用feature对这些项目进行不同的组合,输出后得到具有不同功能的产品。 不过这样一来Package Explorer里的项目会以更快的速度增…
深入探讨Varnish缓存命中率
也许你还在为刚才动态内容获得7336.76 reqs/s的吞吐率感到振奋,等等,理想和现实是有差距的,你要忍受现实的残酷,别忘了,我们压力测试中的动态内容都处于全缓存情况下,也就是每次请求都命中缓存,…

网易有道词典笔 —— 73 岁“人类高质量”奶奶梅耶马斯克的中文学习之选
继埃隆马斯克发微博称7000年后英语将不复存在后,他的忠实粉丝,同时也是他的母亲——梅耶马斯克也正式开启了学习新语言行动,值得注意的是,梅耶的语种选择是中文。近日,埃隆马斯克的母亲——梅耶马斯克使用有道词典笔学…
Android类库打包方法探究
为什么80%的码农都做不了架构师?>>> 开发Android应用的时候,对于可用于多个应用的公用的部分,或是打算发布给第三方进行应用集成的部分,要把这部分打包成类库怎么做呢? 众所周知,Android应用使用ADT打包成…