如何训练2457亿参数量的中文巨量模型“源1.0”
如何训练2457亿参数量的中文巨量模型“源1.0”
浪潮人工智能研究院
从2018年的BERT到2020年的GPT-3,NLP语言模型经历了爆发式的发展过程,其中BERT模型的参数量为3.4亿,而GPT-3的模型参数量达到了1750亿。2021年9月,浪潮人工智能研究院发布了“源1.0”,它是目前规模最大的中文AI单体模型,参数规模高达2457亿,训练采用的中文数据集达5TB。“源1.0”在语言智能方面表现优异,获得中文语言理解评测基准CLUE榜单的零样本学习和小样本学习两类总榜冠军。测试结果显示,人群能够准确分辨人与“源1.0”作品差别的成功率低于50%。
海量的参数带来了模型训练和部署上的巨大挑战。本文将聚焦“源1.0”背后的计算挑战以及我们采取的训练方法。
1.“源1.0”的模型结构
“源1.0”是一个典型的语言模型。语言模型通俗来讲就是能够完成自然语言理解或者生成文本的神经网络模型。对于“源1.0”,我们考虑语言模型(Language Model,LM)和前缀语言模型(Prefix Language Model,PLM)两种模型结构。如下图所示:
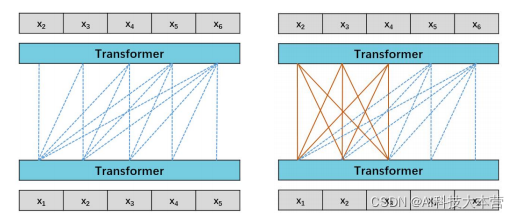
图1 模型结构示意图(左图为LM,右图为PLM)
我们比较了130亿参数的LM和PLM在不同下游任务上的结果,注意到LM在Zero-Shot和Few-Shot上表现更好,而PLM在微调方面表现出色。微调通常会在大多数任务中带来更好的准确性,然而微调会消耗大量的计算资源,这是不经济的。所以我们选择LM作为“源 1.0”模型的基础模型结构。
2. 如何训练“源1.0”
2.1.源1.0训练面对的挑战
“源1.0”的训练需要面对的第一个挑战就是数据和计算量的挑战。
数据方面,如果把训练一个巨量模型的训练过程比作上异常战役的话,那么数据就是我们的弹药。数据量的多少,决定了我们可以训练模型的规模,以及最后的效果。针对这一方面,我们构建了一个全新的中文语料库,清洗后的高质量数据规模达到了5TB,是目前规模最大的中文语料库。
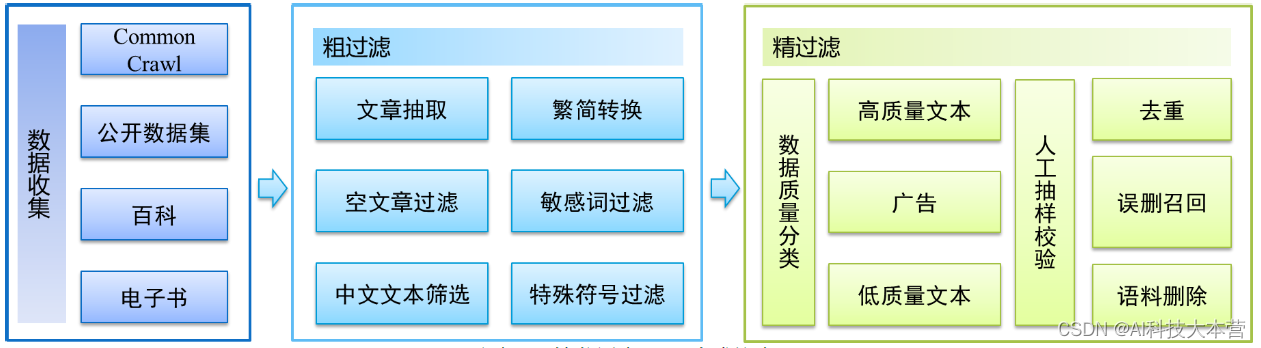
图2 数据预处理流程图
算力方面,根据OpenAI提出的PetaFlop/s-day衡量标准,我们可以估算“源1.0”训练的计算需求情况。根据Wikipedia提供的数据(https://en.wikipedia.org/wiki/OpenAI),GPT-3的计算需求约为3640 PetaFlop/s-day, 约等于64个A100 GPU训练1年时间。而“源1.0”的计算需求达到了4095 PetaFlop/s-day。
计算资源的巨大开销是限制研究人员研发具有数以千万计参数的NLP大模型的瓶颈。例如GPT-3是在由10000个GPU所组成的集群上训练得到的。我们在设计“源1.0”的模型结构时,考虑到了影响大规模分布式训练的关键因素,采用了专门的分布式训练策略,从而加速了模型的训练过程。
在模型训练时一般最常用的是采用数据并行分布式计算策略,但这只能满足小模型的训练需求。对于巨量模型来说,由于其模型参数量过大,远远超过常用计算设备比如GPU卡的显存容量,因此需要专门的算法设计来解决巨量模型训练的显存占用问题,同时还需要兼顾训练过程中的GPU计算性能的利用率。
2.2“源1.0”的训练策略
为了解决显存不足的问题,我们采用了张量并行、流水并行、数据并行相结合的并行策略,实现了在2128个GPU上部署“源1.0”,并完成了1800亿tokens的训练。
一、张量并行
针对单个GPU设备不能完整的承载模型训练,一个解决方案就是张量并行+数据并行的2D并行策略。具体来说,使用多个GPU设备为1组,比如单个服务器内的8个GPU为1组,组内使用张量并行策略对模型进行拆分,组间(服务器间)采用数据并行。
对于张量并行部分,NVIDIA在Megatron-LM中提出了针对Transformer结构的张量并行解决方案。其思路是把每一个block的参数和计算都均匀的拆分到N个GPU设备上,从而实现每个GPU设备都承担这一block的参数量和计算量的1/N效果。图3展示了对Transformer结构中的MLP层和self-attention层进行张量并行拆分计算的过程示意图。
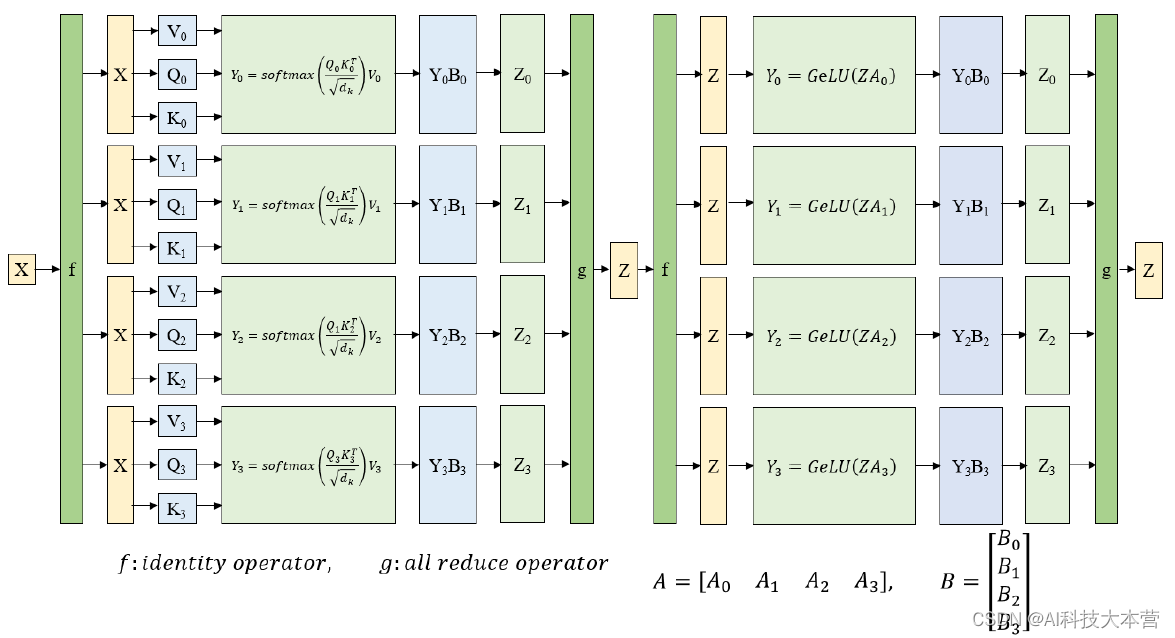
图3 张量并行示意图
在训练过程中,tensor经过每一层的时候,计算量与通信数据量之比![]() 如下:
如下:
![]()
其中,S为输入序列的长度,h为隐藏层的大小(hidden size)。
二、流水并行

图4 流水线并行示意图
对于具有数千亿参数的语言模型,这些参数很难被存放在单个节点中。流水线并行将LM的层序列在多个节点之间进行分割,以解决存储空间不足的问题,如图5所示。每个节点都是流水线中的一个阶段,它接受前一阶段的输出并将结果过发送到下一阶段。如果前一个相邻节点的输出尚未就绪,则当前节点将处于空闲状态。节点的空闲时间被称为流水线气泡(pipline bubble)。为了提高流水行并行的性能,我们必须尽可能减少在气泡上花费的时间。定义流水线中气泡的理想时间占比![]() 为如下形式:
为如下形式:
![]()
根据这一公式,流水线气泡的耗时随着层数L的增加而增加,随着微批次大小(micro-batch-size)的增加而减小。当m≫L/l 的时候,流水并行过程中的流水线气泡对训练性能的影响几乎可以忽略。
与此同时,在流水并行过程中,节点间的计算量与通信数据量之比![]() 为:
为:
![]()
根据上面的公式,流水线中节点的计算效率与h和S呈线性关系,这与张量并行类似。
三、数据并行
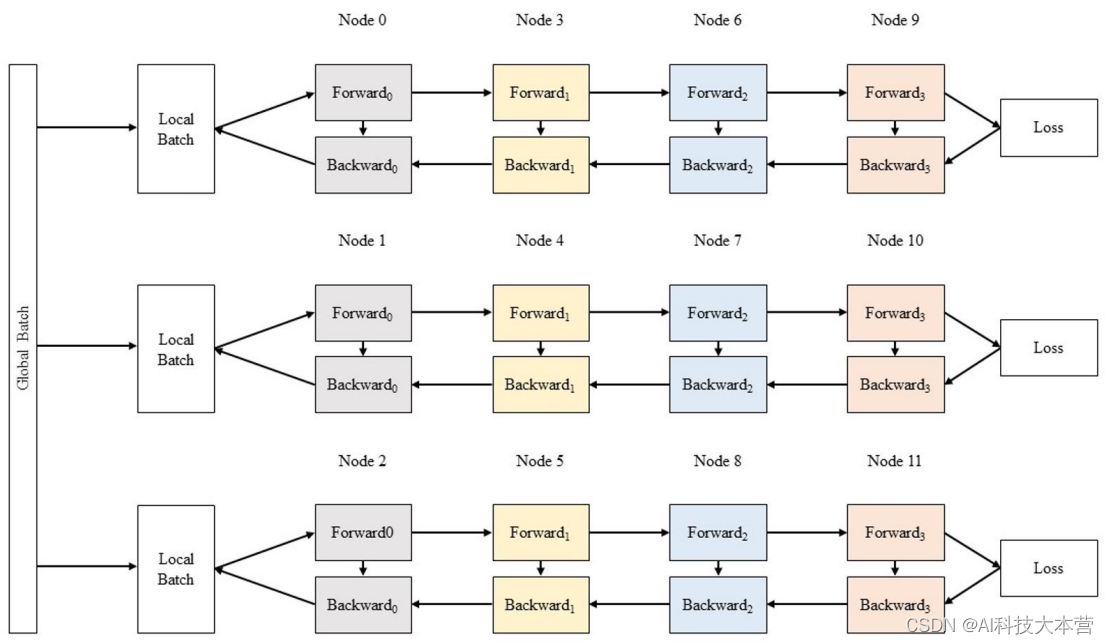
图5 数据并行示意图
采用数据并行时,全局批次大小(global batch size)按照流水线分组进行分割。每个流水线组都包含模型的一个副本,数据在组内按照局部批次规模送入模型副本。数据并行时的计算量与通信数据量的比值![]() 可用如下公式近似:
可用如下公式近似:
![]()
当d≫1 时,上面公式可以进一步简化成:
![]()
根据这一公式,我们可以看出数据并行的计算效率与全局批次大小B和序列长度S呈正比关系。由于模型对内存的需求与S的平方成正比,与B成线性关系,因此增加全局批次大小可以更有效的提升数据并行的效率。
当全局批次大小过大的时候,模型很容易出现不收敛的问题,为了保证模型训练过程的稳定性,我们将全局批次大小限制在了![]() 个token内。
个token内。
根据以上的理论分析,我们确定了设计“源1.0”巨量模型结构的基本原则:
- 尽可能增加序列长度,因为它有利于张量并行、流水线并行和数据并行。由于内存占用与序列长度的平方成正比,因此有必要在反向传播时重新计算激活函数,以节省内存开销。
- 语言模型中层数太多会对性能产生负面影响,因为这会增加在流水线气泡上的时间消耗。
- 增加隐藏层大小可以提高张量并行和流水线并行的性能。
- 增加节点中的微批次大小可以提高流水线并行效率,增加全局批次大小可以提升数据并行的效率。
在这一设计原则的基础上,我们设计的“源1.0”的模型结构以及分布式策略的设置如下表所示:
Model | Layers | Hidden size | Global BS | Micro BS | Sequence Length | t | p | d | GPUs |
Yuan 1.0 | 76 | 16384 | 3360 | 1 | 2048 | 8 | 38 | 7 | 2128 |
结合模型结构的特性以及我们使用集群的硬件特性,我们如下的节点配置和分布式策略选择:
- “源1.0”模型在训练过程中共使用了2128个GPU
- 模型分成了7组,每组38台AI服务器,里面放置一个完整的“源1.0”模型,7组之间采用数据并行
- 每组的38个服务器,采用流水并行每个服务器放置1/38的模型(2个Transformer Layer),一共76层
- 在每台服务器内采用张量并行,按照Transformer结构的每一层进行均匀切分
模型收敛曲线如下图:
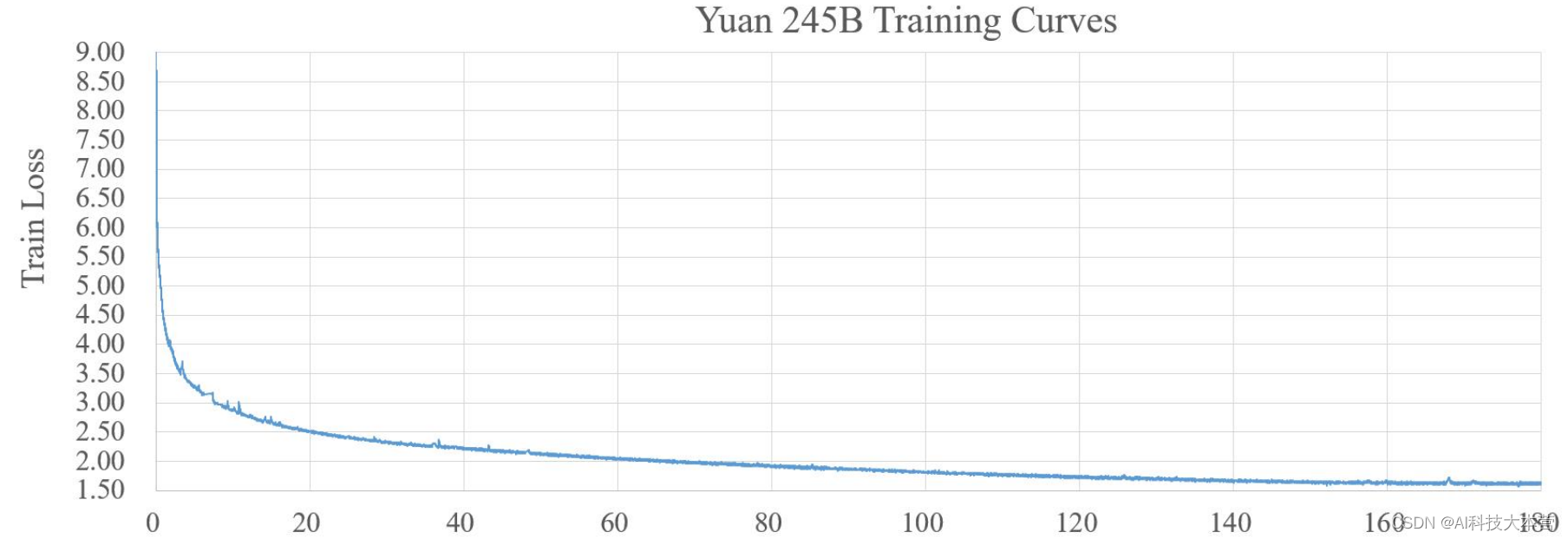
关于“源1.0”的更多信息,大家可以参照浪潮人工智能研究院发布在arxiv上的论文:https://arxiv.org/abs/2110.04725。
相关文章:

Linux驱动程序编写
工作需要写了我们公司一块网卡的Linux驱动程序。经历一个从无到有的过程,深感技术交流的重要。Linux作为挑战微 软垄断的强有力武器,日益受到大家的喜爱。真希望她能在中国迅速成长。把程序文档贴出来,希望和大家探讨Linux技术和应用…
PHP+socket+SMTP、POP3协议发送、接收邮件
1、实现SMTP协议的类dsmtp.cls.php:<?php//通过socket实现SMTP协议的功能//version: 1.1//author : DCC//create : 2014-01-17 23:38:24//modify : 2014-01-18 16:59:04//more : http://www.thinkful.cn/archives/389.htmlclass Dmail_smtp{var $socket;var $…
JavaScript学习记录 (三) 函数和对象
1.函数使用 function 关键字来声明函数函数的命名规则和变量一样JS没有函数签名,所以没有函数重载JS函数中的所有参数都是值传递;不能通过引用传递// 定义函数 function test(arg) {return arg 10; } // 定义一个同名函数 function test(arg, arg1) {re…

基于jQuery图片自适应排列显示代码
基于jQuery图片自适应排列显示代码。这是一款基于jquery.flex-images插件实现的类似谷歌图片流效果。效果图如下: 在线预览 源码下载 实现的代码。 html代码: <div style"max-width:900px;margin:auto;padding:0 10px"><h3>演示…

计算机史最疯狂一幕:豪赌50亿美元,“蓝色巨人”奋身一跃
作者 | OneFlow社区来源 | OneFlow社区“Go big or go home. ”是美国人的一句习语,经常会在赛场上听到,NBA球迷应该很熟悉,翻译过来就是“要不变强大,要不滚回家”。在1960年初期的计算机行业,IBM正站在这样一个十字路…
CentOS Linux内核升级全过程
首先说明,下面带#号的行都是要输入的命令行,且本文提到的所有命令行都在终端里输入。接下来,让我们一起开始精彩的Linux内核升级之旅吧!一、准备工作启动Linux系统,并用根用户登录,进入终端模式下。1、查看…
Windows程序设计------字体不等宽引出的问题及其细节知识
在写Windows程序设计的Typer程序时,我并不是在每一个使用HDC的地方都重新创建选中字体,而是在一开始选中之后,就没有再删除它,代码如图: 结果我的字体不是等宽字体! 起先我以为是没有设置WM_INPUTLANGCHANG…
看闯关东原来知道古代已经十六进制了
闯关东第四集中夏掌柜说黄县口诀什么意思 1625 2125 31875 425 53125 6375 74375 85 95625 1625 116875 1275 138125 14875 159375 161 这个问题实际上是过去商品流通中的一种算法。过去的衡器十六两为一斤,也就是十六进制。为了计算方便,先人便选用了这…

手机客户端和web端开发的异同
2019独角兽企业重金招聘Python工程师标准>>> 版本升级。用户角度上看,客户端升级必须让用户手动下载整个新的安装包覆盖安装,而web的升级无需用户做任何事情。开发角度上看,如果客户端有个小bug需要紧急修复,需要修复完…

AI 监视打工人,这个国家明确说:保护我方“摸鱼权”!
撰文 | 刘芳来源 | 学术头条近日,国美控股集团对员工“摸鱼” 的处罚引起了关于职场中隐私权的巨大争议。事实上,这一事件并非个例。如今人工智能(AI)算法在职场中的使用,已经涉及到包含隐私权在内的诸多问题。随着…

Hibernate复习之Hibernate基本介绍
众所周知。眼下流行的面向对象的对象关系映射的Java持久层框架有MyBatis和Hibernate。他们都是对象关系映射ORM。 解决的主要问题就是对象-关系的映射。域模型和关系模型都分别建立在概念模型的基础上。域模型是面向对象的,关系模型是面向关系的,普通情况…
Linux常用命令手册
核心: cat定位,sed时间搜索,grep关键字查询,tail行数,|管道结合 最前N行 这个主要看文件最开始是什么时候记录了什么 #head -1 XXX.log 最后N行 #cat XXX.log | tail -n 10 时间区间搜索 #sed -n /2010-05-20…

程序员敲诈老板,或面临 37 年监禁
作者 | 祝涛 出品 | CSDN(ID:CSDNnews)12月1日,网络设备制造商优比快(Ubiquiti)的前雇员尼古拉斯夏普(nicholas Sharp)被捕,他被控窃取数据,并试图…
使用modernizr.js检测浏览器对html5以及css3的支持情况
使用modernizr.js检测浏览器对html5和css3的支持情况 详情请看主页:modernizr主页 1. modernizr 是什么? modernize 是一个js库————一个用于检测当前浏览器对html5&css3 的支持情况,其中包括对 css3 的 font-face、border-radius、…

SharePoint运行状况分析器有关磁盘空间不足的警告
对于负责管理SharePoint内部部署安装的SharePoint管理员,SharePoint Health Analyzer是一款出色的工具。此功能不仅有助于解决服务器故障和服务失败的问题,还提供了有关如何解决问题的提示。总的来说,我觉得这个功能非常有帮助。但是…
百度PHP高级顾问惠新宸:PHP在百度的发展历程
惠新宸,百度PHP高级顾问,年二十有八,好追根究底,有不良嗜好, 幸性本善。乙酉年识互联网,丁亥年入雅虎,翌年入百度。虽性好安稳,然经变无数,唯常叹"人生,菠菜汤尔"。大家好…

Python 远程连接服务器用它就够了
作者 | 费弗里来源 | Python大数据分析❝本文示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes❞1 简介日常工作中经常需要通过SSH连接到多台远程服务器来完成各种任务,当需要操作的服务器众多,且要执行的任务涉…
如何在centos安装python-mysql
在python中使用mysql,需要安装mysql-python依赖包,可以通过pip来安装:pip install MySQL-python如果发生错误,需要先安装一个开发包:yum install python-devel如果还是报错,运行:yum install my…

DNS 到底怎么工作的? (How does dns work?)
其实这个问题每次看的时候都觉得很明白,但是很久之后就忘记了,所以这次准备记录下来。深入到这个过程的各个细节之中,以后多看看。 Step 1 请求缓存信息: 当你在开始访问一个 www.baidu.com 开始,第一件事情就是去访问…
#pragma pack(n) 的作用
在C语言中,结构是一种复合数据类型,其构成元素既可以是基本数据类型(如int、long、float等)的变量,也可以是一些复合数据类型(如数组、结构、联合等)的数据单元。在结构中,编译器为结…
LoadRunner设置检查点的几种方法介绍
LoadRunner设置检查点的几种方法介绍 发布时间: 2011-5-03 11:53 作者: 一米阳光做测试 来源: 51Testing软件测试网采编 字体: 小 中 大 | 上一篇 下一篇 | 打印 | 我要投稿 3、将脚本切换回代码界面, 在光标闪烁的上行,添加如下的代码&…

Python 爬虫利器 Selenium 从入门到进阶
作者 | 俊欣来源 | 关于数据分析与可视化今天小编就来讲讲selenium,我们大致会讲这些内容selenium简介与安装页面元素的定位浏览器的控制鼠标的控制键盘的控制设置元素的等待获取cookies调用JavaScriptselenium进阶selenium的简介与安装selenium是最广泛使用的开源W…
获取下个月的今天
/* 获取下个月的今天如果 $date 2018-1-31 二月没有31号 则获取二月份的最后一天 返回值为2018-2-28如果 $date 2018-1-15 返回值为2018-2-15 -- psw-- */function getNextMonthDays($date){$firstday date(Y-m-01, strtotime($date));$lastday strtotime("$firstday …
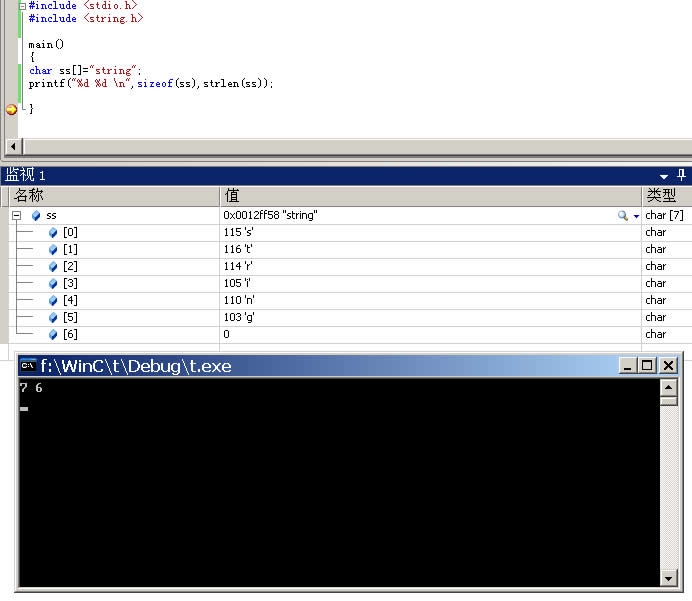
C语言的sizeof和strlen
strlen是函数,而sizeof是算符。strlen需要进行一次函数调用,而对于sizeof而言,因为缓冲区已经用已知字符串进行了初始化,起长度是固定的,所以sizeof在编译时计算缓冲区的长度。因为sizeof()测试的是数组的长度。而strl…

机器人 Ameca「苏醒」瞬间逼真到令人恐惧,网友纷纷惊叹……
整理 | 禾木木 出品 | AI科技大本营(ID:rgznai100) 近日,国内外网友都被一段机器人「苏醒」的视频惊讶到。 视频开始时,机器人似乎已经睡着,眼睛闭着,头部略微向下倾斜。随着肩膀的伸展,机器…
linux源码包卸载方式
linux源码包软件的安装与卸载3人收藏此文章,我要收藏 发表于1年前 , 已有593次阅读 共0个评论Linux软件安装与卸载(源码包形式):一般情况下linux程序的发布不能像windows那样,直接打包成一个setup.exe文件,然用户安装 …

在实践中我遇到stompjs, websocket和nginx的问题与总结
阅读原文:https://wdd.js.org/stomp-over... 1. AWS EC2 不支持WebSocket 直达解决方案 英文版 简单说一下思路:WebSocket底层基于TCP协议的,如果你的服务器基于HTTP协议暴露80端口,那WebSocket肯定无法连接。你只要将HTTP协议修改…
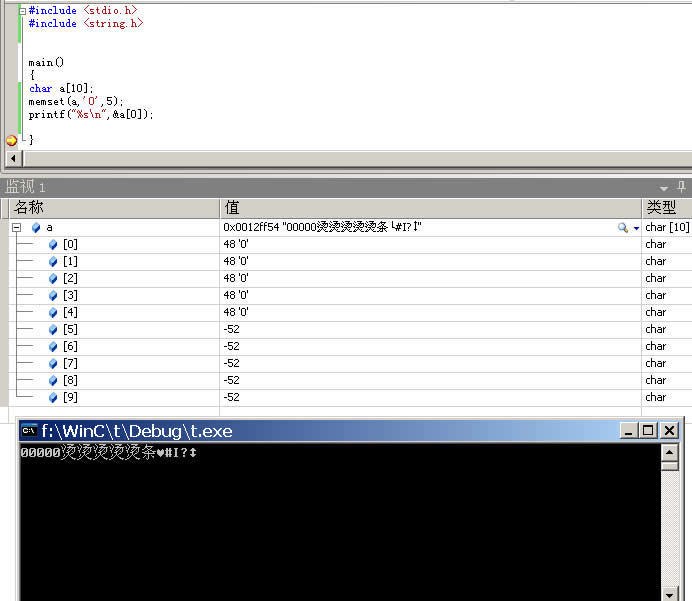
C语言memset函数详解(Linux下和windows下的差异)
memest原型 (please type "man memset" in your shell) void *memset(void *s, int c, size_t n); memset:作用是在一段内存块中填充某个给定的值,它对较大的结构体或数组进行清零操作的一种最快方法。 #include <stdio.h>#include <string.…

Oracle 工程师离职并回踩:MySQL 糟糕透顶,强烈推荐 PostgreSQL
整理 | 祝涛 出品 | CSDN(ID:CSDNnews)如果你即将离职,你会做什么?抨击自己付出了五年心血的技术——这是Oracle公司前首席软件工程师、MySQL优化器团队成员Steinar Gunderson的选择。这位工程师现已在Chrome团队…
ORA-01109:数据库未打开(解决)
SQL> startup mountORA-01081: 无法启动已在运行的 ORACLE - 请首先关闭它SQL> shutdown immediateORA-01109: 数据库未打开 已经卸载数据库。ORACLE 例程已经关闭。SQL> startup mountORACLE 例程已经启动。 Total System Global Area 612368384 bytesFixed Size 125…