20个经典函数细说 Pandas 中的数据读取与存储,强烈建议收藏

作者 | 俊欣
来源 | 关于数据分析与可视化
大家好,今天小编来为大家介绍几个Pandas读取数据以及保存数据的方法,毕竟我们很多时候需要读取各种形式的数据,以及将我们需要将所做的统计分析保存成特定的格式。
我们大致会说到的方法有:
read_sql()to_sql()read_clipboard()from_dict()to_dict()to_clipboard()read_json()to_json()read_html()to_html()read_table()read_csv()to_csv()read_excel()to_excel()read_xml()to_xml()read_pickle()to_pickle()
read_sql()与to_sql()
我们一般读取数据都是从数据库中来读取的,因此可以在read_sql()方法中填入对应的sql语句然后来读取我们想要的数据,
pd.read_sql(sql, con, index_col=None,coerce_float=True, params=None,parse_dates=None,columns=None, chunksize=None)参数详解如下:
sql: SQL命令字符串
con: 连接SQL数据库的Engine,一般用SQLAlchemy或者是PyMysql之类的模块来建立
index_col:选择某一列作为Index
coerce_float:将数字形式的字符串直接以float型读入
parse_dates: 将某一列日期型字符串传唤为datatime型数据,可以直接提供需要转换的列名以默认的日期形式转换,或者也可以提供字典形式的列名和转换日期的格式,
我们用PyMysql这个模块来连接数据库,并且读取数据库当中的数据,首先我们导入所需要的模块,并且建立起与数据库的连接
import pandas as pd
from pymysql import *conn = connect(host='localhost', port=3306, database='database_name',user='', password='', charset='utf8')我们简单地写一条SQL命令来读取数据库当中的数据,并且用read_sql()方法来读取数据
sql_cmd = "SELECT * FROM table_name"
df = pd.read_sql(sql_cmd, conn)
df.head()上面提到read_sql()方法当中parse_dates参数可以对日期格式的数据进行处理,那我们来试一下其作用
sql_cmd_2 = "SELECT * FROM test_date"
df_1 = pd.read_sql(sql_cmd_2, conn)
df_1.head()output
number date_columns
0 1 2021-11-11
1 2 2021-10-01
2 3 2021-11-10我们来看一个各个列的数据类型
df_1.info()output
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3 entries, 0 to 2
Data columns (total 2 columns):# Column Non-Null Count Dtype
--- ------ -------------- ----- 0 number 3 non-null int64 1 date_columns 3 non-null object
dtypes: int64(1), object(1)
memory usage: 176.0+ bytes正常默认情况下,date_columns这一列也是被当做是String类型的数据,要是我们通过parse_dates参数将日期解析应用与该列
df_2 = pd.read_sql(sql_cmd_2, conn, parse_dates="date_columns")
df_2.info()output
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3 entries, 0 to 2
Data columns (total 2 columns):# Column Non-Null Count Dtype
--- ------ -------------- ----- 0 number 3 non-null int64 1 date_columns 3 non-null datetime64[ns]
dtypes: datetime64[ns](1), int64(1)
memory usage: 176.0 bytes就转换成了相对应的日期格式,当然我们还可以采用上面提到的另外一种格式
parse_dates={"date_column": {"format": "%d/%m/%y"}})to_sql()方法
我们来看一下to_sql()方法,作用是将DataFrame当中的数据存放到数据库当中,请看下面的示例代码,我们创建一个基于内存的SQLite数据库
from sqlalchemy import create_engine
engine = create_engine('sqlite://', echo=False)然后我们创建一个用于测试的数据集,并且存放到该数据库当中,
df = pd.DataFrame({'num': [1, 3, 5]})
df.to_sql('nums', con=engine)查看一下是否存取成功了
engine.execute("SELECT * FROM nums").fetchall()output
[(0, 1), (1, 3), (2, 5)]我们可以尝试着往里面添加数据
df2 = pd.DataFrame({'num': [7, 9, 11]})
df2.to_sql('nums', con=engine, if_exists='append')
engine.execute("SELECT * FROM nums").fetchall()output
[(0, 1), (1, 3), (2, 5), (0, 7), (1, 9), (2, 11)]注意到上面的if_exists参数上面填的是append,意味着添加新数据进去,当然我们也可以将原有的数据替换掉,将append替换成replace
df2.to_sql('nums', con=engine, if_exists='replace')
engine.execute("SELECT * FROM nums").fetchall()output
[(0, 7), (1, 9), (2, 11)]from_dict()方法和to_dict()方法
有时候我们的数据是以字典的形式存储的,有对应的键值对,我们如何根据字典当中的数据来创立DataFrame,假设
a_dict = {'学校': '清华大学','地理位置': '北京','排名': 1
}一种方法是调用json_normalize()方法,代码如下
df = pd.json_normalize(a_dict)output
学校 地理位置 排名
0 清华大学 北京 1当然我们直接调用pd.DataFrame()方法也是可以的
df = pd.DataFrame(json_list, index = [0])output
学校 地理位置 排名
0 清华大学 北京 1当然我们还可以用from_dict()方法,代码如下
df = pd.DataFrame.from_dict(a_dict,orient='index').Toutput
学校 地理位置 排名
0 清华大学 北京 1这里最值得注意的是orient参数,用来指定字典当中的键是用来做行索引还是列索引,请看下面两个例子
data = {'col_1': [1, 2, 3, 4],'col_2': ['A', 'B', 'C', 'D']}我们将orient参数设置为columns,将当中的键当做是列名
df = pd.DataFrame.from_dict(data, orient='columns')output
col_1 col_2
0 1 A
1 2 B
2 3 C
3 4 D当然我们也可以将其作为是行索引,将orient设置为是index
df = pd.DataFrame.from_dict(data, orient='index')output
0 1 2 3
col_1 1 2 3 4
col_2 A B C Dto_dict()方法
语法如下:
df.to_dict(orient='dict')针对orient参数,一般可以填这几种形式
一种是默认的dict,代码如下
df = pd.DataFrame({'shape': ['square', 'circle', 'triangle'],'degrees': [360, 360, 180],'sides': [4, 5, 3]})
df.to_dict(orient='dict')output
{'shape': {0: 'square', 1: 'circle', 2: 'triangle'}, 'degrees': {0: 360, 1: 360, 2: 180}, 'sides': {0: 4, 1: 5, 2: 3}}也可以是list,代码如下
df.to_dict(orient='list')output
{'shape': ['square', 'circle', 'triangle'], 'degrees': [360, 360, 180], 'sides': [4, 5, 3]}除此之外,还有split,代码如下
df.to_dict(orient='split')output
{'index': [0, 1, 2], 'columns': ['shape', 'degrees', 'sides'], 'data': [['square', 360, 4], ['circle', 360, 5], ['triangle', 180, 3]]}还有records,代码如下
df.to_dict(orient='records')output
[{'shape': 'square', 'degrees': 360, 'sides': 4}, {'shape': 'circle', 'degrees': 360, 'sides': 5}, {'shape': 'triangle', 'degrees': 180, 'sides': 3}]最后一种是index,代码如下
df.to_dict(orient='index')output
{0: {'shape': 'square', 'degrees': 360, 'sides': 4}, 1: {'shape': 'circle', 'degrees': 360, 'sides': 5}, 2: {'shape': 'triangle', 'degrees': 180, 'sides': 3}}read_json()方法和to_json()方法
我们经常也会在实际工作与学习当中遇到需要去处理JSON格式数据的情况,我们用Pandas模块当中的read_json()方法来进行处理,我们来看一下该方法中常用到的参数
orient:对应JSON字符串的格式主要有
split: 格式类似于:{index: [index], columns: [columns], data: [values]}
例如我们的JSON字符串长这样
a = '{"index":[1,2,3],"columns":["a","b"],"data":[[1,3],[2,8],[3,9]]}'
df = pd.read_json(a, orient='split')output
a b
1 1 3
2 2 8
3 3 9records: 格式类似于:[{column: value}, ... , {column: value}]
例如我们的JSON字符串长这样
a = '[{"name":"Tom","age":"18"},{"name":"Amy","age":"20"},{"name":"John","age":"17"}]'
df_1 = pd.read_json(a, orient='records')output
name age
0 Tom 18
1 Amy 20
2 John 17index: 格式类似于:{index: {column: value}}
例如我们的JSON字符串长这样
a = '{"index_1":{"name":"John","age":20},"index_2":{"name":"Tom","age":30},"index_3":{"name":"Jason","age":50}}'
df_1 = pd.read_json(a, orient='index')output
name age
index_1 John 20
index_2 Tom 30
index_3 Jason 50columns: 格式类似于:{column: {index: value}}
我们要是将上面的index变成columns,就变成
df_1 = pd.read_json(a, orient='columns')output
index_1 index_2 index_3
name John Tom Jason
age 20 30 50values: 数组
例如我们的JSON字符串长这样
v='[["a",1],["b",2],["c", 3]]'
df_1 = pd.read_json(v, orient="values")output
0 1
0 a 1
1 b 2
2 c 3to_json()方法
将DataFrame数据对象输出成JSON字符串,可以使用to_json()方法来实现,其中orient参数可以输出不同格式的字符串,用法和上面的大致相同,这里就不做过多的赘述
read_html()方法和to_html()方法
有时候我们需要抓取网页上面的一个表格信息,相比较使用Xpath或者是Beautifulsoup,我们可以使用pandas当中已经封装好的函数read_html来快速地进行获取,例如我们通过它来抓取菜鸟教程Python网站上面的一部分内容
url = "https://www.runoob.com/python/python-exceptions.html"
dfs = pd.read_html(url, header=None, encoding='utf-8')返回的是一个list的DataFrame对象
df = dfs[0]
df.head()output
异常名称 描述
0 NaN NaN
1 BaseException 所有异常的基类
2 SystemExit 解释器请求退出
3 KeyboardInterrupt 用户中断执行(通常是输入^C)
4 Exception 常规错误的基类当然read_html()方法也支持读取HTML形式的表格,我们先来生成一个类似这样的表格,通过to_html()方法
df = pd.DataFrame(np.random.randn(3, 3))
df.to_html("test_1.html")当然这个HTML形式的表格长这个样子
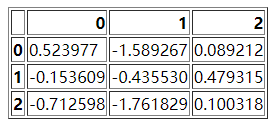
然后我们再通过read_html方法读取该文件,
dfs = pd.read_html("test_1.html")
dfs[0]read_csv()方法和to_csv()方法
read_csv()方法
read_csv()方法是最常被用到的pandas读取数据的方法之一,其中我们经常用到的参数有
filepath_or_buffer: 数据输入的路径,可以是文件的路径的形式,例如
pd.read_csv('data.csv')output
num1 num2 num3 num4
0 1 2 3 4
1 6 12 7 9
2 11 13 15 18
3 12 10 16 18也可以是URL,如果访问该URL会返回一个文件的话
pd.read_csv("http://...../..../data.csv")sep: 读取
csv文件时指定的分隔符,默认为逗号,需要注意的是:“csv文件的分隔符”要和“我们读取csv文件时指定的分隔符”保持一致
假设我们的数据集,csv文件当中的分隔符从逗号改成了"\t",需要将sep参数也做相应的设定
pd.read_csv('data.csv', sep='\t')index_col: 我们在读取文件之后,可以指定某一列作为
DataFrame的索引
pd.read_csv('data.csv', index_col="num1")output
num2 num3 num4
num1
1 2 3 4
6 12 7 9
11 13 15 18
12 10 16 18除了指定单个列,我们还可以指定多个列,例如
df = pd.read_csv("data.csv", index_col=["num1", "num2"])output
num3 num4
num1 num2
1 2 3 4
6 12 7 9
11 13 15 18
12 10 16 18usecols:如果数据集当中的列很多,而我们并不想要全部的列、而是只要指定的列就可以,就可以使用这个参数
pd.read_csv('data.csv', usecols=["列名1", "列名2", ....])output
num1 num2
0 1 2
1 6 12
2 11 13
3 12 10除了指定列名之外,也可以通过索引来选择想要的列,示例代码如下
df = pd.read_csv("data.csv", usecols = [0, 1, 2])output
num1 num2 num3
0 1 2 3
1 6 12 7
2 11 13 15
3 12 10 16另外usecols参数还有一个比较好玩的地方在于它能够接收一个函数,将列名作为参数传递到该函数中调用,要是满足条件的,就选中该列,反之则不选择该列
# 选择列名的长度大于 4 的列
pd.read_csv('girl.csv', usecols=lambda x: len(x) > 4)prefix: 当导入的数据没有header的时候,可以用来给列名添加前缀
df = pd.read_csv("data.csv", header = None)output
0 1 2 3
0 num1 num2 num3 num4
1 1 2 3 4
2 6 12 7 9
3 11 13 15 18
4 12 10 16 18如果我们将header设为None,pandas则会自动生成表头0, 1, 2, 3..., 然后我们设置prefix参数为表头添加前缀
df = pd.read_csv("data.csv", prefix="test_", header = None)output
test_0 test_1 test_2 test_3
0 num1 num2 num3 num4
1 1 2 3 4
2 6 12 7 9
3 11 13 15 18
4 12 10 16 18skiprows: 过滤掉哪些行,参数当中填行的索引
代码如下:
df = pd.read_csv("data.csv", skiprows=[0, 1])output
6 12 7 9
0 11 13 15 18
1 12 10 16 18上面的代码过滤掉了前两行的数据,直接将第三行与第四行的数据输出,当然我们也可以看到第二行的数据被当成是了表头
nrows: 该参数设置一次性读入的文件行数,对于读取大文件时非常有用,比如 16G 内存的PC无法容纳几百G的大文件
代码如下:
df = pd.read_csv("data.csv", nrows=2)output
num1 num2 num3 num4
0 1 2 3 4
1 6 12 7 9to_csv()方法
该方法主要是用于将DataFrame写入csv文件当中,示例代码如下
df.to_csv("文件名.csv", index = False)我们还能够输出到zip文件的格式,代码如下
df = pd.read_csv("data.csv")
compression_opts = dict(method='zip',archive_name='output.csv')
df.to_csv('output.zip', index=False,compression=compression_opts)read_excel()方法和to_excel()方法
read_excel()方法
要是我们的数据是存放在excel当中就可以使用read_excel()方法,该方法中的参数和上面提到的read_csv()方法相差不多,这里就不做过多的赘述,我们直接来看代码
df = pd.read_excel("test.xlsx")dtype: 该参数能够对指定某一列的数据类型加以设定
df = pd.read_excel("test.xlsx", dtype={'Name': str, 'Value': float})output
Name Value
0 name1 1.0
1 name2 2.0
2 name3 3.0
3 name4 4.0sheet_name: 对于读取
excel当中的哪一个sheet当中的数据加以设定
df = pd.read_excel("test.xlsx", sheet_name="Sheet3")output
Name Value
0 name1 10
1 name2 10
2 name3 20
3 name4 30当然我们要是想一次性读取多个Sheet当中的数据也是可以的,最后返回的数据是以dict形式返回的
df = pd.read_excel("test.xlsx", sheet_name=["Sheet1", "Sheet3"])output
{'Sheet1': Name Value
0 name1 1
1 name2 2
2 name3 3
3 name4 4, 'Sheet3': Name Value
0 name1 10
1 name2 10
2 name3 20
3 name4 30}例如我们只想要Sheet1的数据,可以这么来做
df1.get("Sheet1")output
Name Value
0 name1 1
1 name2 2
2 name3 3
3 name4 4to_excel()方法
将DataFrame对象写入Excel表格,除此之外还有ExcelWriter()方法也有着异曲同工的作用,代码如下
df1 = pd.DataFrame([['A', 'B'], ['C', 'D']],index=['Row 1', 'Row 2'],columns=['Col 1', 'Col 2'])
df1.to_excel("output.xlsx")当然我们还可以指定Sheet的名称
df1.to_excel("output.xlsx", sheet_name='Sheet_Name_1_1_1')有时候我们需要将多个DataFrame数据集输出到一个Excel当中的不同的Sheet当中
df2 = df1.copy()
with pd.ExcelWriter('output.xlsx') as writer:df1.to_excel(writer, sheet_name='Sheet_name_1_1_1')df2.to_excel(writer, sheet_name='Sheet_name_2_2_2')我们还可以在现有的Sheet的基础之上,再添加一个Sheet
df3 = df1.copy()
with pd.ExcelWriter('output.xlsx', mode="a", engine="openpyxl") as writer:df3.to_excel(writer, sheet_name='Sheet_name_3_3_3')我们可以生成至Excel文件并且进行压缩包处理
with zipfile.ZipFile("output_excel.zip", "w") as zf:with zf.open("output_excel.xlsx", "w") as buffer:with pd.ExcelWriter(buffer) as writer:df1.to_excel(writer)对于日期格式或者是日期时间格式的数据,也能够进行相应的处理
from datetime import date, datetime
df = pd.DataFrame([[date(2019, 1, 10), date(2021, 11, 24)],[datetime(2019, 1, 10, 23, 33, 4), datetime(2021, 10, 20, 13, 5, 13)],],index=["Date", "Datetime"],columns=["X", "Y"],
)
with pd.ExcelWriter("output_excel_date.xlsx",date_format="YYYY-MM-DD",datetime_format="YYYY-MM-DD HH:MM:SS"
) as writer:df.to_excel(writer)read_table()方法
对于txt文件,既可以用read_csv()方法来读取,也可以用read_table()方法来读取,其中的参数和read_csv()当中的参数大致相同,这里也就不做过多的赘述
df = pd.read_table("test.txt", names = ["col1", "col2"], sep=' ')output
col1 col2
0 1 2
1 3 4
2 5 6
3 7 8
4 9 10
5 11 12我们要读取的txt文件当中的数据是以空格隔开的,因此再sep参数上面需要设置成空格
read_pickle()方法和to_pickle()方法
Python当中的Pickle模块实现了对一个Python对象结构的二进制序列和反序列化,序列化过程是将文本信息转变为二进制数据流,同时保存数据类型。例如数据处理过程中,突然有事儿要离开,可以直接将数据序列化到本地,这时候处理中的数据是什么类型,保存到本地也是同样的类型,反序列化之后同样也是该数据类型,而不是从头开始处理
to_pickle()方法
我们先将DataFrame数据集生成pickle文件,对数据进行永久储存,代码如下
df1.to_pickle("test.pkl")read_pickle()方法
代码如下
df2 = pd.read_pickle("test.pkl")read_xml()方法和to_xml()方法
XML指的是可扩展标记语言,和JSON类似也是用来存储和传输数据的,还可以用作配置文件
XML和HTML之间的差异
XML和HTML为不同的目的而设计的
XML被设计用来传输和存储数据,其重点是数据的内容
HTML被设计用来显示数据,其焦点是数据的外观
XML不会替代HTML,是对HTML的补充
对XML最好的理解是独立于软件和硬件的信息传输工具,我们先通过to_xml()方法生成XML数据
df = pd.DataFrame({'shape': ['square', 'circle', 'triangle'],'degrees': [360, 360, 180],'sides': [4, np.nan, 3]})
df.to_xml("test.xml")我们用pandas中的read_xml()方法来读取数据
df = pd.read_xml("test.xml")output
shape degrees sides
0 square 360 4.0
1 circle 360 NaN
2 triangle 180 3.0read_clipboard()方法
有时候数据获取不太方便,我们可以通过复制的方式,通过Pandas当中的read_clipboard()方法来读取复制成功的数据,例如我们选中一部分数据,然后复制,运行下面的代码
df_1 = pd.read_clipboard()output
num1 num2 num3 num4
0 1 2 3 4
1 6 12 7 9
2 11 13 15 18
3 12 10 16 18to_clipboard()方法
有复制就会有粘贴,我们可以将DataFrame数据集输出至剪贴板中,粘贴到例如Excel表格中
df.to_clipboard()

往
期
回
顾
技术
6种常用的绘制地图的方法,码住!
资讯
DeepMind 打造AI游戏系统
资讯
全球首个活体机器人,能生娃
资讯
机器人Ameca苏醒瞬间逼真到令人...

分享

点收藏

点点赞

点在看
相关文章:

fastlane自动打包--详细介绍
fastlane--Packaging 自动化打包,通过fastlane自动发布Fastlane安装不在这里详细罗列,参照一下链接流程 https://www.jianshu.com/p/0a113f754c09操作步骤 1.检查Fastlane是否正确安装。输入以下命令: fastlane --version 复制代码可以看到Fa…

【Big Data】HADOOP集群的配置(一)
Hadoop集群的配置(一) 摘要: hadoop集群配置系列文档,是笔者在实验室真机环境实验后整理而得。以便随后工作所需,做以知识整理,另则与博客园朋友分享实验成果,因为笔者在学习初期,也遇到不少问题…
C语言 条件编译详解
预处理过程扫描源代码,对其进行初步的转换,产生新的源代码提供给编译器。可见预处理过程先于编译器对源代码进行处理。在C 语言中,并没有任何内在的机制来完成如下一些功能:在编译时包含其他源文件、定义宏、根据条件决定编译时是…

凝聚406万开发者 飞桨十大发布提速产业智能化
12月12日,由深度学习技术及应用国家工程实验室主办的WAVE SUMMIT2021深度学习开发者峰会在上海召开。百度首席技术官、深度学习技术及应用国家工程实验室主任王海峰公布飞桨最新成绩单:凝聚406万开发者、创建47.6万模型、服务15.7万企事业单位࿰…

环境变量,cp,mv,查看文档命令
2019独角兽企业重金招聘Python工程师标准>>> 一、环境变量PATH echo $PATH 打印当前的环境变量 PATH$PATH:路径 自定义环境变量 which查找某个命令的绝对路径,也可以查看某个命令的别名,which查找的范围就在PATH下的几个目录下查找࿱…
Linux中errno使用
当linux中的C api函数发生异常时,一般会将errno变量(需include errno.h)赋一个整数值,不同的值表示不同的含义,可以通过查看该值推测出错的原因,在实际编程中用这一招解决了不少原本看来莫名其妙的问题。但是errno是一个数字,代表的具体含义还要到errno.…

工程师文化:BAT 为什么不喊老板
BAT员工之间不喊老板,也不喊真名,而是用同学、花名,这是虚情假意?还是弘扬武侠文化?还是另有隐情?为什么欧美公司不这么做?本文将带大家走进科学,探索真相。 BAT 的称呼方式 腾讯&am…
SVN常见问题
2019独角兽企业重金招聘Python工程师标准>>> 目录[隐藏] 1. 提示SVN证书过期? 2. 用户名密码校验失败? 3. SVN提交文件时提示文件冲突怎么办? 4. SVN提交文件时提示失败? 1. 提示SVN证书过期? 问题描述&…

2017海克斯康拉斯维加斯美国大会 精彩即将开始
海克斯康集团与遍及全球行业用户的故事已经证明,海克斯康先进的解决方案影响着世界各行各业的发展,并为他们带来了颠覆性的科技变革...... 通过海克斯康集团与遍及全球行业用户的故事,已经证明海克斯康先进的解决方案影响着世界各行各业的发展…
Linux环境编程--waitpid与fork与execlp
waitpidwaitpid(等待子进程中断或结束)表头文件#include<sys/types.h>#include<sys/wait.h>定义函数 pid_t waitpid(pid_t pid,int * status,int options);函数说明waitpid()会暂时停止目前进程的执行,直到有信号来到或子进程结束。如果在调用 wait()时子进程已经结…
C# 批处理制作静默安装程序包
使用批处理WinRAR制作静默安装程序包 echo 安装完窗口会自动关闭!!! echo off start /wait Lync.exe /Install /Silent start /wait vcredist_x86/vcredist_x86.exe /q /norestart start /wait DotNetFx40/dotNetFx40_Full_x86_x64.exe /q /…

程序员是复制粘贴的工具人?还是掌握“谜底”的魔术师?
作者 | David Heinemeier Hansson译者 | 弯月出品 | CSDN(ID:CSDNnews)编程世界在经历了“Imposter Syndrome(冒充者症候群/负担症候群)”和“gatekeeping(守门人理论)”两方的激战之后,最终以“…
Josephus Problem的详细算法及其Python, Java语言的实现
笔者昨天看电视,偶尔看到一集讲述古罗马人与犹太人的战争——马萨达战争,深为震撼,有兴趣的同学可以移步:http://finance.ifeng.com/a/20170627/15491157_0.shtml . 这不仅让笔者想起以前在学数据结构时碰到的Josephus问题&a…
SlightPHP
SlightPHP是一个轻量级的php框架,支持php5,和php模块方式使用,和apc使用性能更高!项目地址:http://code.google.com/p/slightphp/源码地址:http://slightphp.googlecode.com/svn/trunk/你有两种方法使用Sli…

bzoj1178
题目:http://www.lydsy.com/JudgeOnline/problem.php?id1178 看ppthttp://wenku.baidu.com/link?urldJv6LNme7syiLGM-TzbEEKXwx36JWEnI5HFrIlzfmzUXXg4HG8FDggj5WQS3EKL3k3p-sUYeJ268jCvN4t_kq2YPo3I4GXvaGulQjXrO3d7#include<cstdio> #include<cstdlib&…

编程能力差,学不好Python、AI、Java等技术,90%是输在了这点上!
据了解,超90%的人在学习Python、Java、AI等技术时,都是在网上随便找个入门的教程就开始学起来。然而多数人在看了不少教程后,还是很难独立完成项目,甚至反思自己为什么学了这么久编程能力还是这么差!因为你在刚刚开始学…
cglib代理的使用
一、什么是CGLIB? 总的来说,无论是cglib、jdk动态代理又或者是aop面向切面编程,都运用到了一个最重要的设计模式--代理模式!万变不离其终,学好代理模式,打遍天下无敌手! cglib就是一个字节码生成和转换的库…
使用PHP+Sphinx建立高效的站内搜索引擎
1. 为什么要使用Sphinx假设你现在运营着一个论坛,论坛数据已经超过100W,很多用户都反映论坛搜索的速度非常慢,那么这时你就可以考虑使用Sphinx了(当然其他的全文检索程序或方法也行)。2. Sphinx是什么Sphinx由俄…

9个必知的 Python 操作文件/文件夹方法
作者 | 欣一来源 | Python爱好者集中营近几年随着Python的热度不断上涨,人们渐渐使用这门编程语言来进行一些自动化操作,以节省重复劳动带来的效率低下,那么必定会涉及到对文件系统的操作,包括文件的增、删、改、查等等࿰…
Get/POST方法提交的长度限制
1. Get方法长度限制 Http Get方法提交的数据大小长度并没有限制,HTTP协议规范没有对URL长度进行限制。这个限制是特定的浏览器及服务器对它的限制。 如:IE对URL长度的限制是2083字节(2K35)。 下面就是对各种浏览器和服务器的…
Bitmap上下合成图片
合成两张图片,上下叠加的效果: /*** 把两个位图覆盖合成为一个位图,以底层位图的长宽为基准** param backBitmap 在底部的位图* param frontBitmap 盖在上面的位图* return*/public static Bitmap mergeBitmap(Bitmap backBitmap, Bitmap fr…
PHP 符号大全
注解符号: // 单行注解 /* */ 多行注解引号的使用’ ’ 单引号,没有任何意义,不经任何处理直接拿过来;" "双引号,php动态处理然后输出,一般用于变量.变量形态: 一种是True 即 真的;另一种是False 即假的常见变量形态: string 字串(数字\汉…
添加Net4CollectionTypeFactory的原因
.NET4.0已经实现了该功能 http://jahav.com/blog/nhibernate-using-net-4-iset/ NHibernate using .NET 4 ISet 0 CommentsNHibernate 4.0 (released in 2014-08-17) has brought us support for .NET 4 ISet<> collections, thus freeing us from the tyranny of the Ie…
LTSM 实现多元素时序数据植物健康预测
作者 | 李秋键 出品 | AI科技大本营(ID:rgznai100) 引言: 近些年来,“预测”一词在各个领域被频繁提及,所谓预测,实际上就是根据历史规律,推测未来结果。在科学技术发展有限的过去࿰…
如何扩大以太坊的规模:分片简介(How to Scale Ethereum: Sharding Explained)
2019独角兽企业重金招聘Python工程师标准>>> 分片是提高区块链效率的一个主要流派。下面简单通俗的解释一下分片算法。 以太猫(Cryptokitties)堵塞了以太坊网络好几天,以太坊--世界上最大的,公开的区块链目前是无法扩容的,也众所周…

Xdebug的安装-(无错可执行版)
xdebug是一个开源的php调试器,以php模块的形式加载并被使用。可以用来跟踪,调试和分析PHP程序的运行状况. 这里以PHP5.2.13为例, 1.下载php_xdebug-2.1.0-5.2.dll文件, http://www.xdebug.org/download.php 选择:PHP 5.2 VC6 TS (32 bit) 选择…

云游戏、VR、AI,云计算给元宇宙提供了哪些想象力?
2021 最火的新概念,莫过于元宇宙。2021 年 10 月 29 日,Facebook 宣布改名 Meta;2021 年 11 月 1 日,“元宇宙第一股” Roblox 经过短暂调整,宣布重新上线。接下来关于元宇宙的线下 / 线上讨论如火如荼,…
sys.check_constraints
每个用作 CHECK 约束(sys.objects.type C)的对象都在表中占一行。 SELECT name FROM sys.check_constraints-- equal to SELECT o.name FROM sys.sysobjects oJOIN sys.sysconstraints s ON o.parent_obj s.id WHERE o.xtype C GROUP BY o.…
什么是Bootstrap Aggregating
简介 Bootstrap Aggregating也叫作bagging,是一种机器学习领域用来做模型合并的一种算法。这种算法可以提高统计分类器和回归器的稳定性和准确度。同时也可以帮助模型避免过拟合。历史Bootstrap Aggregating最早在1994年由Leo Breiman提出,当时用来通过随…
柯南君:看大数据时代下的IT架构(5)消息队列之RabbitMQ--案例(Work Queues起航)...
二、Work Queues(using the Java Client) 走起 在第上一个教程中我们写程序从一个命名队列发送和接收消息。在这一次我们将创建一个工作队列,将用于分发耗时的任务在多个工作者(worker)之间。 背后的主要思想工作队列(又名:任务队列)是为了避…