真香!精心整理了 100+Python 字符串常用操作

来源丨萝卜大杂烩
作者丨周萝卜
字符串作为平时使用最多的数据类型,其常用的操作我们还是很有必要熟记于心的,本文整理了多种字符串的操作的案例,还是非常用心,记得点赞收藏~
字符串切片操作
test = "Python Programming"
print("String: ", test)# First one character
first_character = test[:1]
print("First Character: ", first_character)# Last one character
last_character = test[-1:]
print("Last Character: ", last_character)# Everything except the first one character
except_first = test[1:]
print("Except First Char.: ", except_first)# Everything except the last one character
except_last = test[:-1]
print("Except First Char.: ", except_last)# Everything between first and last two character
between_two = test[2:-2]
print("Between two character: ", between_two)# Skip one character
skip_one = test[0:18:2] # [start:stop:step]
print("Skip one character: ", skip_one)# Reverse String
reverse_str = test[::-1]
print("Reverse String: ", reverse_str)Output:
String: Python ProgrammingFirst Character: PLast Character: gExcept First Char.: ython ProgrammingExcept First Char.: Python ProgramminBetween two character: thon ProgrammiSkip one character: Pto rgamnReverse String: gnimmargorP nohtyP检查字符串是否为空
import re
from collections import Countersentence = 'Canada is located in the northern part of North America'
# Example I
counter = len(re.findall("a", sentence))
print(counter)# Example II
counter = sentence.count('a')
print(counter)# Example III
counter = Counter(sentence)
print(counter['a'])Output:
EmptyEmptyEmpty计算字符串中字符出现次数的多种方法
import re
from collections import Countersentence = 'Canada is located in the northern part of North America'
# Example I
counter = len(re.findall("a", sentence))
print(counter)# Example II
counter = sentence.count('a')
print(counter)# Example III
counter = Counter(sentence)
print(counter['a'])Output:
6
6
6将 String 变量转换为 float、int 或 boolean
# String to Float
float_string = "254.2511"
print(type(float_string))string_to_float = float(float_string)
print(type(string_to_float))# String to Integer
int_string = "254"
print(type(int_string))string_to_int = int(int_string)
print(type(string_to_int))# String to Boolean
bool_string = "True"
print(type(bool_string))string_to_bool = bool(bool_string)
print(type(string_to_bool))Output:
class 'str'class 'float>class 'str'class 'int'class 'str'class 'bool'向字符串填充或添加零的不同方法
num = 7print('{0:0>5d}'.format(num)) # left
print('{0:0<5d}'.format(num)) # rightprint('{:05d}'.format(num))print("%0*d" % (5, num))
print(format(num, "05d"))temp = 'test'
print(temp.rjust(10, '0'))
print(temp.ljust(10, '0'))Output:
0000770000000070000700007000000testtest000000去掉字符串中的 space 字符
string_var = " \t a string example\n\t\r "
print(string_var)string_var = string_var.lstrip() # trim white space from left
print(string_var)string_var = " \t a string example\t "
string_var = string_var.rstrip() # trim white space from right
print(string_var)string_var = " \t a string example\t "
string_var = string_var.strip() # trim white space from both side
print(string_var)Output:
a string examplea string examplea string examplea string example生成N个字符的随机字符串
import string
import randomdef string_generator(size):chars = string.ascii_uppercase + string.ascii_lowercasereturn ''.join(random.choice(chars) for _ in range(size))def string_num_generator(size):chars = string.ascii_lowercase + string.digitsreturn ''.join(random.choice(chars) for _ in range(size))# Random String
test = string_generator(10)
print(test)# Random String and Number
test = string_num_generator(15)
print(test)Output:
acpPTojXetqmpah72cjb83eqd以不同的方式反转字符串
test_string = 'Python Programming'string_reversed = test_string[-1::-1]
print(string_reversed)string_reversed = test_string[::-1]
print(string_reversed)# String reverse logically
def string_reverse(text):r_text = ''index = len(text) - 1while index >= 0:r_text += text[index]index -= 1return r_textprint(string_reverse(test_string))Output:
gnimmargorP nohtyPgnimmargorP nohtyPgnimmargorP nohtyP将 Camel Case 转换为 Snake Case 并更改给定字符串中特定字符的大小写
import redef convert(oldstring):s1 = re.sub('(.)([A-Z][a-z]+)', r'\1_\2', oldstring)return re.sub('([a-z0-9])([A-Z])', r'\1_\2', s1).lower()# Camel Case to Snake Case
print(convert('CamelCase'))
print(convert('CamelCamelCase'))
print(convert('getHTTPResponseCode'))
print(convert('get2HTTPResponseCode'))# Change Case of a particular character
text = "python programming"
result = text[:1].upper() + text[1:7].lower() \+ text[7:8].upper() + text[8:].lower()
print(result)text = "Kilometer"
print(text.lower())old_string = "hello python"
new_string = old_string.capitalize()
print(new_string)old_string = "Hello Python"
new_string = old_string.swapcase()
print(new_string)Output:
camel_casecamel_camel_caseget_http_response_codeget2_http_response_codePython ProgrammingkilometerHello pythonhELLO pYTHON检查给定的字符串是否是 Python 中的回文字符串
import reContinue = 1
Quit = 2def main():choice = 0while choice != Quit:# Display the menu.display_menu()# Constant to assume string is Palindromeis_palindrome = True# Get the user's choice.choice = int(input('\nEnter your choice: '))# Perform the selected action.if choice == Continue:line = input("\nEnter a string: ")str_lower = re.sub("[^a-z0-9]", "", line.lower())for i in range(0, len(str_lower)//2):if str_lower[i] != str_lower[len(str_lower) - i - 1]:is_palindrome = Falseif is_palindrome:print(line, "is a palindrome")else:print(line, "is not a palindrome")else:print('Thank You.')def display_menu():print('\n*******MENU*******')print('1) Continue')print('2) Quit')main()Output:
*******MENU*******1) Continue2) QuitEnter your choice: 1Enter a string: A dog! A panic in a pagoda!A dog! A panic in a pagoda! is a palindrome*******MENU*******1) Continue2) QuitEnter your choice: 1Enter a string: CivicCivic is a palindrome*******MENU*******1) Continue2) QuitEnter your choice: 1Enter a string: Python vs JavaPython vs Java is not a palindrome*******MENU*******1) Continue2) QuitEnter your choice: 2Thank You.检查字符串是否以列表中的一个字符串结尾
str_list = ['aaa', 'bbb', 'ccc', 'ddd'] # list of items
str_test = 'testccc' # string need to testfor str_item in str_list:if str_test.endswith(str_item):print("found")break # loop ends when result foundelse:print("not found")Output:
not foundnot foundfound在字符串中应用查找模式
import res1 = 'abccba'
s2 = 'abcabc'
s3 = 'canadajapanuaeuaejapancanada'
p = '123321'def match(s, p):nr = {}regex = []for c in p:if c not in nr:regex.append('(.+)')nr[c] = len(nr) + 1else:regex.append('\\%d' % nr[c])return bool(re.match(''.join(regex) + '$', s))print(match(s1, p))
print(match(s2, p))
print(match(s3, p))Output:
True
False
True如果是 Python 中的反斜杠,则删除最后一个字符
x = 'Canada\\'
print(x.rstrip('\\'))Output:
Canada在Python中拆分字符串而不丢失拆分字符
import re
string = 'canada-japan-india'print(re.split(r'(\-)', string))Output:
['canada', '-', 'japan', '-', 'india']从字符串 Python 中提取大写和小写字符
string = "asdfHRbySFss"uppers = [l for l in string if l.isupper()]
print (''.join(uppers))lowers = [l for l in string if l.islower()]
print (''.join(lowers))Output:
HRSF
asdfbyss如何在 Python 中比较字符串的索引是否相等
myString = 'AAABBB'
for idx, char in enumerate(myString, ):if idx + 1 == len(myString):breakif char == myString[idx + 1]:print(idx, char, myString[idx + 1])Output:
0 A A
1 A A
3 B B
4 B B在每个第 4 个字符上添加空格
string = 'Test5412Test8745Test'
print([string[i:i + 4] for i in range(0, len(string), 4)])Output:
['Test', '5412', 'Test', '8745', 'Test']在 Python 中以多行方式连接字符串
str1 = "This is a demo string"
str2 = "This is another demo string"
strz = ("This is a line\n" +str1 + "\n" +"This is line 2\n" +str2 + "\n" +"This is line 3\n")print(strz)Output:
This is a line
This is a demo string
This is line 2
This is another demo string
This is line 3在 Python 中将多个变量附加到列表中
volumeA = 100
volumeB = 20
volumeC = 10vol1 = []
vol2 = []vol1.extend((volumeA, volumeB, volumeC))
vol2 += [val for name, val in globals().items() if name.startswith('volume')]print(vol1)
print(vol2)Output:
[100, 20, 10]
[100, 20, 10]将字符串拆分为 Python 中的字符列表
s = 'canada'
l = list(s)
print(l)Output:
['c', 'a', 'n', 'a', 'd', 'a']如何在 Python 中小写字符串
text = ['Canada', 'JAPAN']text = [txt.lower() for txt in text]
print(text)Output:
['canada', 'japan']通过多个标点符号分割字符串
import re
s = 'a,b,c d!e.f\ncanada\tjapan&germany'l = re.split('[?.,\n\t&! ]', s)for i in l:print(i)Output:
a
b
c
d
e
f
canada
japan
germanyPython 字符串填充
lines_of_text = [(123, 5487, 'Testing', 'Billy', 'Jones'),(12345, 100, 'Test', 'John M', 'Smith')
]for mytuple in lines_of_text:name = '{}, {}'.format(mytuple[4], mytuple[3])value = '$' + str(mytuple[1])print('{name:<20} {id:>8} {test:<12} {value:>8}'.format(name=name, id=mytuple[0], test=mytuple[2], value=value))Output:
Jones, Billy 123 Testing $5487
Smith, John M 12345 Test $100在 Python 中检查两个字符串是否包含相同的字符
str1 = 'caars'
str2 = 'rats'
str3 = 'racs'print(set(str1)==set(str2))
print(set(str1)==set(str3))Output:
False
True在 Python 中查找给定字符串中的整个单词
def contains_word(s, w):return (' ' + w + ' ') in (' ' + s + ' ')result = contains_word('those who seek shall find', 'find')
print(result)
result = contains_word('those who seek shall find', 'finds')
print(result)Output:
True
False查找所有出现的子字符串
import reaString = 'this is a string where the substring "is" is repeated several times'
print([(a.start(), a.end()) for a in list(re.finditer('is', aString))])Output:
[(2, 4), (5, 7), (38, 40), (42, 44)]在 Python 中去除所有开头在Python中的正斜杠上拆分字符串和结尾标点符号
from string import punctuation
s = '.$958-5-Canada,#'print(s.strip(punctuation))Output:
958-5-Canada用 Python 中的正斜杠上拆分字符串
s = 'canada/japan/australia'
l = s.split('/')print(l)Output:
['canada', 'japan', 'australia']根据 Python 中的索引位置将字符串大写
def capitalize(s, ind):split_s = list(s)for i in ind:try:split_s[i] = split_s[i].upper()except IndexError:print('Index out of range : ', i)return "".join(split_s)print(capitalize("abracadabra", [2, 6, 9, 10, 50]))Output:
Index out of range : 50
abRacaDabRA检查字符串中的所有字符是否都是Python中的数字
a = "1000"
x = a.isdigit()
print(x)b = "A1000"
x = b.isdigit()
print(x)Output:
True
False为什么使用'=='或'is'比较字符串有时会产生不同的结果
a = 'canada'
b = ''.join(['ca', 'na', 'da'])
print(a == b)
print(a is b)a = [1, 2, 3]
b = [1, 2, 3]
print(a == b)
print(a is b)c = b
print(c is b)Output:
True
False
True
False
True如何在 Python 中为字符串添加 X 个空格
print('canada'.ljust(10) + 'india'.ljust(20) + 'japan')Output:
canada india japan如何在Python中替换字符串中的特定字符串实例
def nth_replace(str,search,repl,index):split = str.split(search,index+1)if len(split)<=index+1:return strreturn search.join(split[:-1])+repl+split[-1]str1 = "caars caars caars"
str2 = nth_replace(str1, 'aa', 'a', 1)print(str2)Output:
caars cars caars如何连接两个变量,一个是字符串,另一个是 Python 中的 int
int1 = 10
str1 = 'test'print(str(int1) + str1)Output:
10test在 Python 中的反斜杠上拆分字符串
s = r'canada\japan\australia'
l = s.split('\\')print(l)Output:
['canada', 'japan', 'australia']在Python中随机大写字符串中的字母
from random import choicex = "canada japan australia"
print(''.join(choice((str.upper, str.lower))(c) for c in x))Output:
CANaDA JaPan auStRALIa在单词处拆分字符串并且或不保留分隔符
import restring = "Canada AND Japan NOT Audi OR BMW"l = re.split(r'(AND|OR|NOT)', string)
print(l)Output:
['Canada ', 'AND', ' Japan ', 'NOT', ' Audi ', 'OR', ' BMW']在 Python 中填充 n 个字符
def header(txt: str, width=30, filler='*', align='c'):assert align in 'lcr'return {'l': txt.ljust, 'c': txt.center, 'r': txt.rjust}[align](width, filler)print(header("Canada"))
print(header("Canada", align='l'))
print(header("Canada", align='r'))Output:
************Canada************
Canada************************
************************Canada检查变量是否等于一个字符串或另一个字符串
x = 'canada'if x in ['canada', 'japan', 'germany', 'australia']:print("Yes")Output:
truePython字符串格式化固定宽度
num1 = 0.04154721841
num2 = 10.04154721841
num3 = 1002.04154721841print "{0:<12.11g}".format(num1)[:12]
print "{0:<12.11g}".format(num2)[:12]
print "{0:<12.11g}".format(num3)[:12]Output:
100.041549
0.04159874
12.8878877在Python中查找字符串中字符的所有位置
test = 'canada#japan#uae'
c = '#'
print([pos for pos, char in enumerate(test) if char == c])Output:
[6, 12]在Python中从左右修剪指定数量的空格
def trim(text, num_of_leading, num_of_trailing):text = list(text)for i in range(num_of_leading):if text[i] == " ":text[i] = ""else:breakfor i in range(1, num_of_trailing+1):if text[-i] == " ":text[-i] = ""else:breakreturn ''.join(text)txt1 = " Candada "
print(trim(txt1, 1, 1))
print(trim(txt1, 2, 3))
print(trim(txt1, 6, 8))Output:
Candada Candada
Candada在Python中按字符串中字符的位置拆分字符串
str = 'canadajapan'
splitat = 6
l, r = str[:splitat], str[splitat:]
print(l)
print(r)Output:
canada
japan将Python字符串中的第一个和最后一个字母大写
string = "canada"result = string[0:1].upper() + string[1:-1].lower() + string[-1:].upper()
print(result)Output:
CanadA检查字符串是否以Python中的给定字符串或字符结尾
txt = "Canada is a great country"x = txt.endswith("country")print(x)Output:
True如何在 Python 中比较两个字符串
str1 = "Canada"
str2 = "Canada"
print(str1 is str2) # True
print(str1 == str2) # Truestring1 = ''.join(['Ca', 'na', 'da'])
string2 = ''.join(['Can', 'ada'])
print(string1 is string2) # False
print(string1 == string2) # TrueOutput:
True
True
False
True在Python中将整数格式化为带有前导零的字符串
x = 4
x = str(x).zfill(5)
print(x)Output:
00004在Python中替换字符串的多个子字符串
s = "The quick brown fox jumps over the lazy dog"
for r in (("brown", "red"), ("lazy", "quick")):s = s.replace(*r)print(s)Output:
The quick red fox jumps over the quick dogPython字符串替换字符
s = "The quick brown fox jumps over the lazy dog"
for r in (("brown", "red"), ("lazy", "quick")):s = s.replace(*r)print(s)Output:
The quick red fox jumps over the quick dog在Python中查找字符串中所有出现的单词的所有索引
import resentence = 'this is a sentence this this'
word = 'this'for match in re.finditer(word, sentence):print(match.start(), match.end())Output:
0 4
19 23
24 28在 Python 中将字符串中每个单词的首字母大写
import stringx = "they're bill's friends from the UK"
x = string.capwords(x)
print(x)x = x.title()
print(x)Output:
They're Bill's Friends From The Uk
They'Re Bill'S Friends From The Uk仅在 Python 中的双引号后拆分字符串
s = '"Canada", "Japan", "Germany", "Russia"'
l = ['"{}"'.format(s) for s in s.split('"') if s not in ('', ', ')]for item in l:print(item)Output:
"Canada"
"Japan"
"Germany"
"Russia"在 Python 中以字节为单位获取字符串的大小
string1 = "Canada"
print(len(string1.encode('utf-16')))Output:
10在 Python 中比较字符串中的字符
myString = 'AAABBB'
for idx, char in enumerate(myString, ):if idx + 1 == len(myString):breakif char == myString[idx + 1]:print(idx, char, myString[idx + 1])Output:
0 A A
1 A A
3 B B
4 B B在 Python 中的括号和字符串之间添加空格
import retest = "example(test)"
test2 = "example(test)example"
test3 = "(test)example"
test4 = "example (test) example"for i in [test, test2, test3, test4]:print(re.sub(r"[^\S]?(\(.*?\))[^\S]?", r" \1 ", i).strip())Output:
example (test)
example (test) example
(test) example
example (test) example在 Python 中删除开头和结尾空格
s = ' canada '
print(s.strip())Output:
canada在 Python 中拆分字符串以获得第一个值
s = 'canada-japan-australia'
l = s.split('-')[0]
print(l)string = 'canada-japan-australia'
print(string[:string.index('-')])Output:
canada
canada在 Python 中检查字符串是大写、小写还是混合大小写
words = ['The', 'quick', 'BROWN', 'Fox','jumped', 'OVER', 'the', 'Lazy', 'DOG']print([word for word in words if word.islower()])print([word for word in words if word.isupper()])print([word for word in words if not word.islower() and not word.isupper()])Output:
['quick', 'jumped', 'the']
['BROWN', 'OVER', 'DOG']
['The', 'Fox', 'Lazy']Python计数字符串出现在给定字符串中
txt = "I love Canada, Canada is one of the most impressive countries in the world. Canada is a great country."x = txt.count("Canada")print(x)Output:
3在 Python3 中用前导零填充字符串
hour = 4
minute = 3print("{:0>2}:{:0>2}".format(hour, minute))
print("{:0>3}:{:0>5}".format(hour, minute))
print("{:0<3}:{:0<5}".format(hour, minute))
print("{:$<3}:{:#<5}".format(hour, minute))Output:
04:03
004:00003
400:30000
4$$:3####在 Python 中检查两个字符串是否包含相同的字母和数字
from string import ascii_letters, digitsdef compare_alphanumeric(first, second):for character in first:if character in ascii_letters + digits and character not in second:return Falsereturn Truestr1 = 'ABCD'
str2 = 'ACDB'
print(compare_alphanumeric(str1, str2))str1 = 'A45BCD'
str2 = 'ACD59894B'
print(compare_alphanumeric(str1, str2))str1 = 'A45BCD'
str2 = 'XYZ9887'
print(compare_alphanumeric(str1, str2))Output:
True
True
False在Python中的字符串中的字符之间添加空格的有效方法
s = "CANADA"print(" ".join(s))
print("-".join(s))
print(s.replace("", " ")[1: -1])Output:
C A N A D A
C-A-N-A-D-A
C A N A D A在Python中查找字符串中最后一次出现的子字符串的索引
s = 'What is Canada famous for?'print(s.find('f'))
print(s.index('f'))
print(s.rindex('f'))
print(s.rfind('f'))Output:
15
15
22
22在 Python 中将字符串大写
x = 'canada'
x = x.capitalize()print(x)Output:
Canada拆分非字母数字并在 Python 中保留分隔符
import res = "65&Can-Jap#Ind^UK"
l = re.split('([^a-zA-Z0-9])', s)
print(l)Output:
['65', '&', 'Can', '-', 'Jap', '#', 'Ind', '^', 'UK']计算Python中字符串中大写和小写字符的数量
string = "asdfHRbySFss"uppers = [l for l in string if l.isupper()]
print(len(uppers))lowers = [l for l in string if l.islower()]
print(len(lowers))Output:
4
8在 Python 中将字符串与枚举进行比较
from enum import Enum, autoclass Signal(Enum):red = auto()green = auto()orange = auto()def equals(self, string):return self.name == stringbrain_detected_colour = "red"
print(Signal.red.equals(brain_detected_colour))brain_detected_colour = "pink"
print(Signal.red.equals(brain_detected_colour))Output:
True
FalsePython中的段落格式
import textwraphamlet = '''\
Lorum ipsum is the traditional Latin placeholder text, used when a designer needs a chunk of text for dummying up a layout.
Journo Ipsum is like that, only using some of the most common catchphrases, buzzwords, and bon mots of the future-of-news crowd.
Hit reload for a new batch. For entertainment purposes only.'''wrapper = textwrap.TextWrapper(initial_indent='\t' * 1,subsequent_indent='\t' * 2,width=40)for para in hamlet.splitlines():print(wrapper.fill(para))Output:
Lorum ipsum is the traditional Latinplaceholder text, used when a designerneeds a chunk of text for dummying upa layout.Journo Ipsum is like that, only usingsome of the most common catchphrases,buzzwords, and bon mots of the future-of-news crowd.Hit reload for a new batch. Forentertainment purposes only.从 Python 中的某个索引替换字符
def nth_replace(str,search,repl,index):split = str.split(search,index+1)if len(split)<=index+1:return strreturn search.join(split[:-1])+repl+split[-1]str1 = "caars caars caars"
str2 = nth_replace(str1, 'aa', 'a', 1)print(str2)Output:
caars cars caars如何连接 str 和 int 对象
i = 123
a = "foobar"
s = a + str(i)
print(s)Output:
foobar123仅在 Python 中将字符串拆分为两部分
s = 'canada japan australia'
l = s.split(' ', 1)
print(l)Output:
['canada', 'japan australia']将大写字符串转换为句子大小写
text = ['CANADA', 'JAPAN']text = [txt.capitalize() for txt in text]
print(text)Output:
['Canada', 'Japan']在标点符号上拆分字符串
string = 'a,b,c d!e.f\ncanada\tjapan&germany'
identifiers = '!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~\n\t 'listitems = "".join((' ' if c in identifiers else c for c in string)).split()for item in listitems:print(item)Output:
a
b
c
d
e
f
canada
japan
germany在 Python 中比较字符串
str1 = "Canada"
str2 = "Canada"
print(str1 is str2) # True
print(str1 == str2) # Truestring1 = ''.join(['Ca', 'na', 'da'])
string2 = ''.join(['Can', 'ada'])
print(string1 is string2) # False
print(string1 == string2) # TrueOutput:
True
True
False
True用零填充数字字符串
num = 123
print('{:<08d}'.format(num))
print('{:>08d}'.format(num))string = '123'
print(string.ljust(8, '0'))
print(string.rjust(8, '0'))print(string[::-1].zfill(8)[::-1])Output:
12300000
00000123
12300000
00000123
12300000找到两个字符串之间的差异位置
def dif(a, b):return [i for i in range(len(a)) if a[i] != b[i]]print(dif('stackoverflow', 'stacklavaflow'))Output:
[5, 6, 7, 8]Python填充字符串到固定长度
number = 4print(f'{number:05d}') # (since Python 3.6), or
print('{:05d}'.format(number)) # orprint('{0:05d}'.format(number))
print('{n:05d}'.format(n=number)) # or (explicit `n` keyword arg. selection)
print(format(number, '05d'))Output:
00004
00004
00004
00004
00004
00004Python中的字符串查找示例
import retext = 'This is sample text to test if this pythonic '\'program can serve as an indexing platform for '\'finding words in a paragraph. It can give '\'values as to where the word is located with the '\'different examples as stated'find_the_word = re.finditer('as', text)for match in find_the_word:print('start {}, end {}, search string \'{}\''.format(match.start(), match.end(), match.group()))Output:
start 63, end 65, search string 'as'
start 140, end 142, search string 'as'
start 200, end 202, search string 'as'删除字符串中的开头零和结尾零
list_num = ['000231512-n', '1209123100000-n00000','alphanumeric0000', '000alphanumeric']print([item.strip('0') for item in list_num]) # Remove leading + trailing '0'
print([item.lstrip('0') for item in list_num]) # Remove leading '0'
print([item.rstrip('0') for item in list_num]) # Remove trailing '0'Output:
['231512-n', '1209123100000-n', 'alphanumeric', 'alphanumeric']
['231512-n', '1209123100000-n00000', 'alphanumeric0000', 'alphanumeric']
['000231512-n', '1209123100000-n', 'alphanumeric', '000alphanumeric']Python在换行符上拆分
s = 'line 1\nline 2\nline without newline'
l = s.splitlines(True)print(l)Output:
['line 1\n', 'line 2\n', 'line without newline']将字符串中的每个第二个字母大写
s = 'canada'
s = "".join([x.upper() if i % 2 != 0 else x for i, x in enumerate(s)])print(s)Output:
cAnAdA在 Python 中查找一个月的最后一个营业日或工作日
import calendardef last_business_day_in_month(year: int, month: int) -> int:return max(calendar.monthcalendar(year, month)[-1:][0][:5])print(last_business_day_in_month(2021, 1))
print(last_business_day_in_month(2021, 2))
print(last_business_day_in_month(2021, 3))
print(last_business_day_in_month(2021, 4))
print(last_business_day_in_month(2021, 5))Output:
29
26
31
30
31比较两个字符串中的单个字符
def compare_strings(a, b):result = Trueif len(a) != len(b):print('string lengths do not match!')for i, (x, y) in enumerate(zip(a, b)):if x != y:print(f'char miss-match {x, y} in element {i}')result = Falseif result:print('strings match!')return resultprint(compare_strings("canada", "japan"))Output:
string lengths do not match!
char miss-match ('c', 'j') in element 0
char miss-match ('n', 'p') in element 2
char miss-match ('d', 'n') in element 4
False在 Python 中多次显示字符串
print('canada' * 3)
print(*3 * ('canada',), sep='-')Output:
canadacanadacanada
canada-canada-canadaPython从头开始替换字符串
def nth_replace(s, old, new, occurrence):li = s.rsplit(old, occurrence)return new.join(li)str1 = "caars caars caars caars caars"
str2 = nth_replace(str1, 'aa', 'a', 1)
print(str2)str2 = nth_replace(str1, 'aa', 'a', 2)
print(str2)str2 = nth_replace(str1, 'aa', 'a', 3)
print(str2)Output:
caars caars caars caars cars
caars caars caars cars cars
caars caars cars cars cars在 Python 中连接字符串和变量值
year = '2020'print('test' + str(year))
print('test' + year.__str__())Output:
test2020
test2020在每个下划线处拆分字符串并在第 N 个位置后停止
s = 'canada_japan_australia_us_uk'
l = s.split('_', 0)
print(l)l = s.split('_', 1)
print(l)l = s.split('_', 2)
print(l)Output:
['canada_japan_australia_us_uk']
['canada', 'japan_australia_us_uk']
['canada', 'japan', 'australia_us_uk']Python中列表中第一个单词的首字母大写
text = ['johnny rotten', 'eddie vedder', 'kurt kobain','chris cornell', 'micheal phillip jagger']text = [txt.capitalize() for txt in text]
print(text)Output:
['Johnny rotten', 'Eddie vedder', 'Kurt kobain', 'Chris cornell', 'Micheal phillip jagger']如何在 Python 字符串中找到第一次出现的子字符串
test = 'Position of a character'
print(test.find('of'))
print(test.find('a'))Output:
9
12不同长度的Python填充字符串
data = [1148, 39, 365, 6, 56524]for element in data:print("{:>5}".format(element))Output:
1148393656
56524Python比较两个字符串保留一端的差异
def after(s1, s2):index = s1.find(s2)if index != -1 and index + len(s2) < len(s1):return s1[index + len(s2):]else:return Nones1 = "canada"
s2 = "can"print(after(s1, s2))Output:
ada如何用Python中的一个字符替换字符串中的所有字符
test = 'canada'
print('$' * len(test))Output:
$$$$$$在字符串中查找子字符串并在 Python 中返回子字符串的索引
def find_str(s, char):index = 0if char in s:c = char[0]for ch in s:if ch == c:if s[index:index + len(char)] == char:return indexindex += 1return -1print(find_str("India Canada Japan", "Canada"))
print(find_str("India Canada Japan", "cana"))
print(find_str("India Canada Japan", "Uae"))Output:
6
-1
-1从 Python 中的字符串中修剪特定的开头和结尾字符
number = '+91 874854778'print(number.strip('+'))
print(number.lstrip('+91'))Output:
91 874854778874854778在 Python 中按长度将字符串拆分为字符串
string = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"x = 3
res = [string[y - x:y] for y in range(x, len(string) + x, x)]
print(res)Output:
['ABC', 'DEF', 'GHI', 'JKL', 'MNO', 'PQR', 'STU', 'VWX', 'YZ']如何在 Python 中将字符串的第三个字母大写
s = "xxxyyyzzz"# convert to list
a = list(s)# change every third letter in place with a list comprehension
a[2::3] = [x.upper() for x in a[2::3]]# back to a string
s = ''.join(a)print(s)Output:
xxXyyYzzZ将制表符大小设置为指定的空格数
txt = "Canada\tis\ta\tgreat\tcountry"print(txt)
print(txt.expandtabs())
print(txt.expandtabs(2))
print(txt.expandtabs(4))
print(txt.expandtabs(10))Output:
Canada is a great country
Canada is a great country
Canada is a great country
Canada is a great country
Canada is a great country将两个字符串与某些字符进行比较
str1 = "Can"
str2 = "Canada"
print(str1 in str2)
print(str1.startswith(str2))
print(str2.startswith(str1))print(str1.endswith(str2))str3 = "CAN"
print(str3 in str2)Output:
True
False
True
False
False字符串格式化填充负数
n = [-2, -8, 1, -10, 40]num = ["{1:0{0}d}".format(2 if x >= 0 else 3, x) for x in n]
print(num)Output:
n = [-2, -8, 1, -10, 40]num = ["{1:0{0}d}".format(2 if x >= 0 else 3, x) for x in n]
print(num)单独替换字符串中的第一个字符
str1 = "caars caars caars"
str2 = str1.replace('aa', 'a', 1)print(str2)Output:
cars caars caars连接固定字符串和变量
variable = 'Hello'
print('This is the Test File ' + variable)variable = '10'
print('This is the Test File ' + str(variable))Output:
This is the Test File Hello
This is the Test File 10将字符串拆分为多个字符串
s = 'str1, str2, str3, str4'
l = s.split(', ')print(l)Output:
['str1', 'str2', 'str3', 'str4']在 Python 中将字符串大写
x = "canada japan australia"x = x[:1].upper() + x[1:]
print(x)x= x.capitalize()
print(x)x= x.title()
print(x)Output:
Canada japan australia
Canada japan australia
Canada Japan Australia将字节字符串拆分为单独的字节
data = b'\x00\x00\x00\x00\x00\x00'info = [data[i:i + 2] for i in range(0, len(data), 2)]
print(info)Output:
[b'\x00\x00', b'\x00\x00', b'\x00\x00']用空格填写 Python 字符串
string = 'Hi'.ljust(10)
print(string)string = 'Hi'.rjust(10)
print(string)string = '{0: ^20}'.format('Hi')
print(string)string = '{message: >16}'.format(message='Hi')
print(string)string = '{message: <16}'.format(message='Hi')
print(string)string = '{message: <{width}}'.format(message='Hi', width=20)
print(string)Output:
Hi HiHi Hi
Hi
Hi比较两个字符串并检查它们共有多少个字符
from collections import Counterdef shared_chars(s1, s2):return sum((Counter(s1) & Counter(s2)).values())print(shared_chars('car', 'carts'))Output:
3在 Python 中的数字和字符串之间添加空格
import res = "ABC24.00XYZ58.28PQR"
s = re.sub("[A-Za-z]+", lambda group: " " + group[0] + " ", s)
print(s.strip())Output:
ABC 24.00 XYZ 58.28 PQR如何在 Python 中去除空格
s = ' canada '
print(s.rstrip()) # For whitespace on the right side use rstrip.
print(s.lstrip()) # For whitespace on the left side lstrip.
print(s.strip()) # For whitespace from both side.s = ' \t canada '
print(s.strip('\t')) # This will strip any space, \t, \n, or \r characters from the left-hand side, right-hand side, or both sides of the string.Output:
canada
canada
canadacanada字符串中最后一次出现的分隔符处拆分字符串
s = 'canada-japan-australia-uae-india'
l = s.rsplit('-', 1)[1]
print(l)Output:
india在Python中将字符串的最后一个字母大写
string = "canada"result = string[:-1] + string[-1].upper()
print(result)result = string[::-1].title()[::-1]
print(result)Output:
canadA
canadA使用指定字符居中对齐字符串
txt = "canada"x = txt.center(20)print(x)Output:
canada格式字符串中动态计算的零填充
x = 4
w = 5
print('{number:0{width}d}'.format(width=w, number=x))Output:
00004在 Python 中使用 string.replace()
a = "This is the island of istanbul"
print (a.replace("is" , "was", 1))
print (a.replace("is" , "was", 2))
print (a.replace("is" , "was"))Output:
Thwas is the island of istanbul
Thwas was the island of istanbul
Thwas was the wasland of wastanbul在 Python 中获取字符的位置
test = 'Position of a character'
print(test.find('of'))
print(test.find('a'))Output:
9
12Python字符串替换多次出现
s = "The quick brown fox jumps over the lazy dog"
for r in (("brown", "red"), ("lazy", "quick")):s = s.replace(*r)print(s)Output:
The quick red fox jumps over the quick dog在索引后找到第一次出现的字符
string = 'This + is + a + string'
x = string.find('+', 4)
print(x)x = string.find('+', 10)
print(x)Output:
5
10在 Python 中将字符串更改为大写
x = 'canada'
x = x.upper()print(x)Output:
CANADA在 Python 中拆分具有多个分隔符的字符串
import rel = re.split(r'[$-]+', 'canada$-india$-japan$-uae')
print(l)Output:
['canada', 'india', 'japan', 'uae']在 Python 中获取字符串的大小
string1 = "Canada"
print(len(string1))string2 = " Canada"
print(len(string2))string3 = "Canada "
print(len(string3))Output:
6
8
8Python中的字符串比较 is vs ==
x = 'canada'
y = ''.join(['ca', 'na', 'da'])
print(x == y)
print(x is y)x = [1, 2, 3]
y = [1, 2, 3]
print(x == y)
print(x is y)z = y
print(z is y)Output:
True
False
True
False
True每当数字与非数字相邻时,Python 正则表达式都会添加空格
import retext = ['123', 'abc', '4x5x6', '7.2volt', '60BTU','20v', '4*5', '24in', 'google.com-1.2', '1.2.3']pattern = r'(-?[0-9]+\.?[0-9]*)'
for data in text:print(repr(data), repr(' '.join(segment for segment in re.split(pattern, data) if segment)))Output:
'123' '123'
'abc' 'abc'
'4x5x6' '4 x 5 x 6'
'7.2volt' '7.2 volt'
'60BTU' '60 BTU'
'20v' '20 v'
'4*5' '4 * 5'
'24in' '24 in'
'google.com-1.2' 'google.com -1.2'
'1.2.3' '1.2 . 3'在 Python 中仅按第一个空格拆分字符串
s = 'canada japan australia'
l = s.split(' ', 1)
print(l)Output:
['canada', 'japan australia']在Python中将字符串中的一些小写字母更改为大写
indices = set([0, 7, 14, 18])s = "i love canada and japan"
print("".join(c.upper() if i in indices else c for i, c in enumerate(s)))Output:
I love Canada And Japan将字符串拆分为具有多个单词边界分隔符的单词
import rethestring = "a,b,c d!e.f\ncanada\tjapan&germany"
listitems = re.findall('\w+', thestring)for item in listitems:print(item)Output:
a
b
c
d
e
f
canada
japan
germany检查一个字符串在 Python 中是否具有相同的字符
str1 = 'caars'
str2 = 'rats'
str3 = 'racs'print(set(str1)==set(str2))
print(set(str1)==set(str3))Output:
False
True在多个分隔符或指定字符上拆分字符串
import restring_test = "Ethnic (279), Responses (3), 2016 Census - 25% Sample"
print(re.findall(r"[\w']+", string_test))def split_by_char(s, seps):res = [s]for sep in seps:s, res = res, []for seq in s:res += seq.split(sep)return resprint(split_by_char(string_test, [' ', '(', ')', ',']))Output:
['Ethnic', '279', 'Responses', '3', '2016', 'Census', '25', 'Sample']['Ethnic', '', '279', '', '', 'Responses', '', '3', '', '', '2016', 'Census', '-', '25%', 'Sample']将一个字符串附加到另一个字符串
# Example 1
str1 = "Can"
str2 = "ada"
str3 = str1 + str2
print(str3)# Example 2
str4 = 'Ca'
str4 += 'na'
str4 += 'da'
print(str4)# Example 3
join_str = "".join((str1, str2))
print(join_str)# Example 4
str_add = str1.__add__(str2)
print(str_add)Output:
CanadaCanadaCanadaCanada在 Python 中遍历字符串
# Example 1
test_str = "Canada"
for i, c in enumerate(test_str):print(i, c)print("------------------------")# Example 2
indx = 0
while indx < len(test_str):print(indx, test_str[indx])indx += 1print("------------------------")
# Example 3
for char in test_str:print(char)Output:
0 C1 a2 n.......da从 Python 中的字符串中去除标点符号
import string
import re# Example 1
s = "Ethnic (279), Responses (3), 2016 Census - 25% Sample"
out = re.sub(r'[^\w\s]', '', s)
print(out)# Example 2
s = "Ethnic (279), Responses (3), 2016 Census - 25% Sample"
for p in string.punctuation:s = s.replace(p, "")
print(s)# Example 3
s = "Ethnic (279), Responses (3), 2016 Census - 25% Sample"
out = re.sub('[%s]' % re.escape(string.punctuation), '', s)
print(out)Output:
Ethnic 279 Responses 3 2016 Census 25 SampleEthnic 279 Responses 3 2016 Census 25 SampleEthnic 279 Responses 3 2016 Census 25 Sample将列表转换为字符串
list_exp = ['Ca', 'na', 'da']
print(type(list_exp))# Example 1
str_exp1 = ''.join(list_exp)
print(type(str_exp1))
print(str_exp1)# Example 2
str_exp2 = ''.join(str(e) for e in list_exp)
print(type(str_exp2))
print(str_exp2)# Example 3
str_exp3 = ''.join(map(str, list_exp))
print(type(str_exp2))
print(str_exp2)Output:
class 'list'class 'str'Canadaclass 'str'Canadaclass 'str'Canada将 JSON 转换为字符串
import json# list with dict a simple Json format
json_exp = \[{"id": "12", "name": "Mark"}, {"id": "13", "name": "Rock", "date": None}]
print(type(json_exp))str_conv = json.dumps(json_exp) # string
print(type(str_conv))
print(str_conv)Output:
class 'list'class 'str'[{"id": "12", "name": "Mark"}, {"id": "13", "name": "Rock", "date": null}]对字符串列表进行排序
# Example 1
str_list = ["Japan", "Canada", "Australia"]
print(str_list)
str_list.sort()
print(str_list)# Example 2
str_list = ["Japan", "Canada", "Australia"]
for x in sorted(str_list):print(x)# Example 3
str_var = "Canada"
strlist = sorted(str_var)
print(strlist)Output:
['Japan', 'Canada', 'Australia']['Australia', 'Canada', 'Japan']AustraliaCanadaJapan['C', 'a', 'a', 'a', 'd', 'n']在 Python 中检查字符串是否以 XXXX 开头
import reexp_str = "Python Programming"# Example 1
if re.match(r'^Python', exp_str):print(True)
else:print(False)# Example 2
result = exp_str.startswith("Python")
print(result)Output:
TrueTrue在 Python 中将两个字符串网格或交错在一起的不同方法
str1 = "AAAA"
str2 = "BBBBBBBBB"# Example 1
mesh = "".join(i + j for i, j in zip(str1, str2))
print("Example 1:", mesh)# Example 2
min_len = min(len(str1), len(str2))
mesh = [''] * min_len * 2
mesh[::2] = str1[:min_len]
mesh[1::2] = str2[:min_len]
print("Example 2:", ''.join(mesh))# Example 3
mesh = ''.join(''.join(item) for item in zip(str1, str2))
print("Example 3:", mesh)# Example 4
min_len = min(len(str1), len(str2))
mesh = [''] * min_len * 2
mesh[::2] = str1[:min_len]
mesh[1::2] = str2[:min_len]
mesh += str1[min_len:] + str2[min_len:]
print("Example 4:", ''.join(mesh))Output:
Example 1: ABABABABExample 2: ABABABABExample 3: ABABABABExample 4: ABABABABBBBBB
往
期
回
顾
技术
Python多层级索引的数据分析
资讯
红帽、Docker、SUSE在俄停服
技术
太强了!Python开发桌面小工具
技术
一行Python代码能干嘛?来看!

分享

点收藏

点点赞

点在看
相关文章:

IOS版添加phonegap-视频播放插件教程
2019独角兽企业重金招聘Python工程师标准>>> 插件集成过程:1.配置Target链接参数选择 Build Settings | Linking | Other Linker Flags, 将该选项的 Debug/Release 键都配置为-ObjC。2.Vitamio SDK 依赖的系统框架和系统库如下:– AVFoundation.framwork…

C#线程同步的几种方法
在网上也看过一些关于线程同步的文章,其实线程同步有好几种方法,下面我就简单的做一下归纳。 一、volatile关键字 volatile是最简单的一种同步方法,当然简单是要付出代价的。它只能在变量一级做同步,volatile的含义就是告诉处理器…

ecshop模板的原理分析
模板的原理 类似Smarty/ECShop这类模板的原理如下图所示。1.首先是编译模板ECShop/Smart是利用PHP引擎,所以编译的结果是一个PHP文件,其编译过程就是将分隔符{}替换成PHP的标准分隔符<?PHP ?>,将$var替换成 echo $var; 或者print $va…

Python 快速生成 web 动态展示机器学习项目!
来源丨网络作者丨wedo实验君1. Streamlit一句话,Streamlit是一个可以用python编写web app的库,可以方便的动态展示你的机器学习的项目。优点你不需要懂html, css, js等,纯python语言编写web app包括web常用组件&#x…
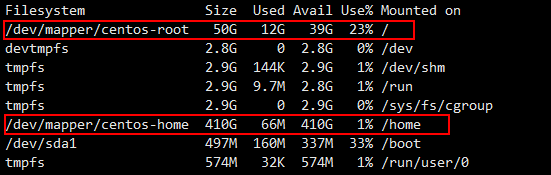
Linux-CentOS 7 增加root分区容量
今天搭建了一台CentOS 7 的机器,搭建完成后通过【df -lh】看了一下分区大小,root分区太小了。 分区.png打算把home分区的容量分一部分给root,具体操作步骤如下: 备份home分区cp -r /home/ homebak卸载【home】目录umount /home/现…

PHP数组实际占用内存大小的分析
http://blog.csdn.net/hguisu/article/details/7376705我们在前面的php高效写法提到,尽量不要复制变量,特别是数组。一般来说,PHP数组的内存利用率只有 1/10, 也就是说,一个在C语言里面100M 内存的数组,在PHP里面就要1…

肝货,详解 tkinter 图形化界面制作流程!
作者 | 黄伟呢来源 | 数据分析与统计学之美本期案例是带着大家制作一个属于自己的GUI图形化界面—>用于设计签名的哦(效果如下图),是不是感觉很好玩,是不是很想学习呢?限于篇幅,今天我们首先详细讲述一下Tkinter的使用方法。tk…
迁移碰到数据库 Unknown collation: 'utf8mb4_unicode_ci'
数据库从香港服务器迁移到阿里云的虚拟主机,不得不吐槽一下。阿里云的ftp好慢,db导入面板也不够友好。 还得靠中断命令行链接,结果版本太低不支持 utf8mb4_unicode_ci,尼玛,现在都mysql5.7了,您还在 5.1时代…
15-shell 输入/输出重定向
大多数 UNIX 系统命令从你的终端接受输入并将所产生的输出发送回到您的终端。一个命令通常从一个叫标准输入的地方读取输入,默认情况下,这恰好是你的终端。同样,一个命令通常将其输出写入到标准输出,默认情况下,这也是…
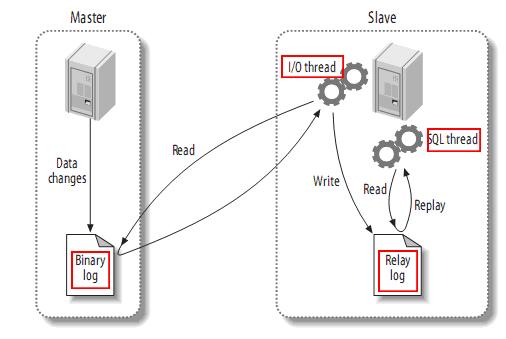
高性能Mysql主从架构的复制原理及配置详解
1 复制概述Mysql内建的复制功能是构建大型,高性能应用程序的基础。将Mysql的数据分布到多个系统上去,这种分布的机制,是通过将Mysql的某一台主机的数据复制到其它主机(slaves)上,并重新执行一遍来实现的。复…
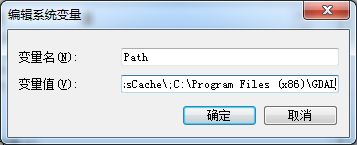
gdal 1.9+python 2.7开发环境配置
最近项目使用Cesium平台基于WegGl做web地球,其中关于地形数据有一种支持格式为terrain的地形数据。这种格式可以通过一个python工具切dem来得到。 下面记录下配置gdalpython开发环境,系统是win7 64位,不过gdal和python是32位的,没…

破纪录了!用 Python 实现自动扫雷!
用PythonOpenCV实现了自动扫雷,突破世界记录,我们先来看一下效果吧。中级 - 0.74秒 3BV/S60.81相信许多人很早就知道有扫雷这么一款经典的游(显卡测试)戏(软件),更是有不少人曾听说过中国雷圣&a…
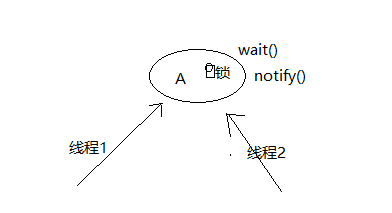
java高并发编程(二)
马士兵java并发编程的代码,照抄过来,做个记录。 一、分析下面面试题 /*** 曾经的面试题:(淘宝?)* 实现一个容器,提供两个方法,add,size* 写两个线程,线程1添加…
LAMP 关键数据集锦技术选项参考
LAMP 关键数据集锦技术选项参考 源自日积月累自己的其他人的经验总结负载均衡 LVS工作在四层,内核态,性能极高,有VIP功能,配合 keepalived 做有效的 心跳检查和负载均衡安装配置麻烦,HAProxy工作在四层到七层&am…
centos7 设置中文
查看系统版本[rootwebtest76 ~]# cat /etc/redhat-releaseCentOS Linux release 7.0.1406 (Core) [rootlocalhost ~]# cat /etc/locale.conf LANGen_US.UTF-8[rootlocalhost ~]# cp /etc/locale.conf /etc/locale.conf_bak[rootlocalhost ~]# vim /etc/locale.conf # 修改后原英…

Python最常用的函数、基础语句有哪些?
作者 | 朱卫军来源 | Python大数据分析Python有很多好用的函数和模块,这里给大家整理下我常用的一些方法及语句。一、内置函数内置函数是python自带的函数方法,拿来就可以用,比方说zip、filter、isinstance等。下面是Python官档给出的内置函数…

1.5s~0.02s,期间我们可以做些什么?
原文是在我自己博客中,小伙伴也可以点阅读原文进行跳转查看,还有好听的背景音乐噢背景音乐已取消~ 2333333大爷我就算功能重做,模块重构,我也不做优化!!!运行真快! 前言 本文主要探讨…

Python 自动化办公之 Excel 拆分并自动发邮件
作者 | 周萝卜来源 | 萝卜大杂烩今天我们来分享一个真实的自动化办公案例,希望各位 Python 爱好者能够从中得到些许启发,在自己的工作生活中更多的应用 Python,使得工作事半功倍!需求需要向大约 500 名用户发送带有 Excel 附件的电…
In Gradle projects, always use http://schemas.andr
2019独角兽企业重金招聘Python工程师标准>>> 版权声明:本文为博主原创文章,未经博主允许不得转载。 在做项目自定义时候遇到这个错误 In Gradle projects, always use http://schemas.android.com/apk/res-auto for custom attributes 解决办…
HTTP POST慢速DOS攻击初探
1. 关于HTTP POST慢速DOS攻击 HTTP Post慢速DOS攻击第一次在技术社区被正式披露是今年的OWASP大会上,由Wong Onn Chee 和 Tom Brennan共同演示了使用这一技术攻击的威力。他们的slides在这里: http://www.darkreading.com/galleries/security/applicatio…
Java 学习(20)--异常 / IO 流
异常(Exception) (1)程序出现的不正常的情况。 (2)异常的体系 Throwable(接口,将异常类对象交给 JVM 来处理) |--Error 严重问题,我们不处理。(jvm 错误,程序无法处理) |--Exception 异常 …

runtime自动归档/解档
原文出自:标哥的技术博客 前言 善用runtime,可以解决自动归档解档。想想以前归档是手动写的,确实太麻烦了。现在有了runtime,我们可以做到自动化了。本篇文章旨在学习如何通过runtime实现自动归档和解档,因此不会对所有…
Ivanti 洞察职场新趋势:71% 的员工宁愿放弃升职也要选择随处工作
近日,为从云端到边缘的 IT 资产提供检测、管理、保护和服务的自动化平台供应商 Ivanti 公布了其年度无处不在的办公空间( Everywhere Workplace) 调查结果。这项调查是Ivanti与全球“未来工作”专家共同完成的,调查范围涵盖 6100 …
Shippable和Packet合作提供原生ARM CI/CD
DevOps自动化平台Shippable和裸金属云服务提供商Packet联合发布了一种新的持续集成和交付(CI/CD)托管服务,适用于在Armv8-A架构上开发软件应用的开发人员。该解决方案支持开源和商业软件项目,用于在Packet提供的基于ARM的云服务上…
阿里云ECS架设***过程总结
原文地址:最近开发移动项目,数据库服务是架设在电信服务器上,可怜我的联通网络本地调试直接x碎了一地!!度娘相关资料后,最终决定在阿里云ECS上架设作为跳板来访问电信服务器!一.原理1.阿里云ECS上架设.2.本地连接使用拨号到阿里云ECS.3.使用阿里云ECS网络访问电信服务器.使用前…
MYSQL的MERGE存储引擎
MYSQL的引擎不是一般的多,这次说到的是MERGE,这个引擎有很多特殊的地方: MERGE引擎类型允许你把许多结构相同的表合并为一个表。然后,你可以执行查询,从多个表返回的结果就像从一个表返回的结果一样。每一个合并的表必…

Pandas SQL 语法归纳总结,真的太全了
作者 | 俊欣来源 | 关于数据分析与可视化对于数据分析师而言,Pandas与SQL可能是大家用的比较多的两个工具,两者都可以对数据集进行深度的分析,挖掘出有价值的信息,但是二者的语法有着诸多的不同,今天小编就来总结归纳一…
分布式RPC实践--Dubbo基础篇
2019独角兽企业重金招聘Python工程师标准>>> 简介 Dubbo是阿里巴巴开源的一个高性能的分布式RPC框架,整个框架的核心原理来源于生产者与消费者的运作模型;框架的核心分4大部分: 1. 服务注册中心 注册中心主要用于保存生产者消费者…

又居家办公了,要签合同怎么办?
本篇文章暨 CSDN《中国 101 计划》系列数字化转型场景之一。 《中国 101 计划——探索企业数字化发展新生态》为 CSDN 联合《新程序员》、GitCode.net 开源代码仓共同策划推出的系列活动,寻访一百零一个数字化转型场景,聚合呈现并开通评选通道࿰…

lombox的用法(省去了set/get/NoArgsConstructor/AllArgsConstructor)
1、环境的搭建,在eclipse下的eclipse.ini中添加以下参数,-Xbootclasspath/a:C:\repository\org\projectlombok\lombok\1.16.6\lombok-1.16.6.jar-javaagent:C:\repository\org\projectlombok\lombok\1.16.6\lombok-1.16.6.jar重启你的eclipse.2、将lombo…