keras训练完以后怎么预测_使用Keras建立Wide Deep神经网络,通过描述预测葡萄酒价格...
你能通过“优雅的单宁香”、“成熟的黑醋栗香气”或“浓郁的酒香”这样的描述,预测葡萄酒的价格吗?事实证明,机器学习模型可以。
在这篇文章中,我将解释我是如何利用Keras(tf.keras)建立一个Wide & Deep神经网络,并基于产品描述来预测葡萄酒的价格。对于那些刚接触Keras的人来说,这个用于构建ML模型的TensorFlow API,已经是更高级别的方法了。如果你想直接获取代码,可以去GitHub上查找。你也可以在浏览器中直接运行这个模型,用Colab无需进行设置。
GitHub:https://github.com/sararob/keras-wine-model
colab:https://colab.research.google.com/github/sararob/keras-wine-model/blob/master/keras-wide-deep.ipynb
利用Keras建立Wide & Deep神经网络
我最近一直在用Sequential模型API构建很多Keras模型,但这次我想尝试一下Functional API。Sequential API是Keras的最佳入门方法,它可以让你轻松地将模型定义为层堆栈。而Functional API允许更多灵活性,最适合应用于多重输入模型或组合模型。Functional API的一个实例,就是在Keras中实现一个Wide & Deep网络。因为已经有很多关于Wide & Deep方面的资源,所以我不会描述太多细节。
Wide & Deep Learning:https://research.googleblog.com/2016/06/wide-deep-learning-better-together-with.html
在你用Wide & Deep网络来解决你的ML问题之前,最好确保它非常适合你想要预测的问题。如果你有一个预测任务,输入和输出之间有相对直接的关系,那么一个wide模型可能就足够了。Wide模型是具有稀少特征向量的模型,或者说是大多为零值向量的模型。另一方面,多层深度网络在图像或语音识别等任务中表现良好,在这样的情况下,输入和输出之间可能存在意想不到的关系。如果你的预测任务可以从这两种模型中获益(推荐模型或带有文本输入的模型都是很好的例子),wide & deep可能就会非常适合你的问题。在这种情况下,我分别尝试了wide模型和deep模型,又将它们结合起来,结果发现wide & deep组合精确度最高。
数据集:预测葡萄酒的价格
我们将使用Kaggle的葡萄酒数据集来测试:能否通过描述和种类预测一瓶葡萄酒的价格?
这个问题很适合wide & deep learning,因为它涉及到文本输入,而且葡萄酒的描述和价格之间并没有显著的相关性。我们不能肯定地说,在描述中有“果味浓”的葡萄酒更贵,或者有“单宁柔和”的葡萄酒更便宜。此外,当我们将文本输入到我们的模型中时,有多种方法来表示文本,并且上述两者都可以导致不同类型的见解。而且两者皆包含wide(词袋)和deep(embedding)特征,结合两者可以使我们从文本中获得更多的意义。这个数据集有很多不同的潜在特征,但是我们只使用描述和种类这两种特征,这样结构相对简单。
下面是这个数据集的输入样本和预测:
输入
描述:酒瓶里冒出浓郁的香草味,即使是在这个不佳葡萄酒酿造期,果香也毫不逊色。这样强烈的水果酸中,含有草本成分,水果、酸、药草和香草以相同的比例迅速作用,生成美味的酒。密封的瓶体,这款酒年份不长,需要过酒换瓶或继续贮存,以完美地出现在世人面前。
种类:Pinot Noir(黑皮诺)
预测
价格:45美元
首先,我们要构建这个模型,需要导入:
由于我们的模型的输出(预测)是具体的价格(数字),我们就直接把价格数值输入到模型中进行训练和评估。这个模型的完整代码可以在GitHub上找到。这里我只列出重点。
首先,下载数据并将其转换为Pandas数据帧:
之后,我们将它分为训练集和测试集并提取特征和标签:
第一部分:wide模型
特征1:葡萄酒描述
为了创建我们的文本描述的wide代表,我们将使用bag of words model。简单解释下bag of words model:它可以在模型的每个输入中寻找单词。你可以把每一个输入想象成一个拼字块游戏,每一块都是一个单词而不是一个分解的字母。用这个模型无需考虑到描述中单词的顺序,只需查找一个单词是否存在。
我们不会去查看数据集中每个描述中存在的每个词,而是将我们的词袋限制在数据集中的12 000个单词中(内置的Keras工具可以创建这个词汇表)。这就可以代表wide,因为对于每个描述,模型的输入都是12000元素宽的向量,其中1 s和0s分别表示在特定的描述中,来自我们的词汇表的词是否存在。
Keras中有一些用于文本预处理的便利工具,我们用这种工具将文本描述转换成词袋。用bag of words model,我们通常只希望在词汇表中,找到数据集中所有词的子集。在本例中,我使用了12000个单词,但这是一个超参数,所以你可以进行调整(尝试一些数值,看看哪些在数据集上的效果最好)。我们可以使用Keras Tokenizer class来创建词袋:
然后用texts_to_matrix函数将每个描述转换为词袋向量:
特征2:葡萄酒种类
最初的Kaggle数据集中,葡萄酒分为632种。为了让模型更容易提取模式,我做了一些预处理,只保留了前40个种类(大约占原始数据集的65%,或者说共有96000个例子)。我们将使用Keras实用工具将每一个种类转换成整数表示,然后我们为每个表示种类的输入,创建了40个元素wide独热向量。
目前为止,我们已做好建立wide模型的准备了。
用Keras functional API创建wide模型
Keras有两种用于构建模型的API:Sequential API和Functional API。Functional API给我们提供了更多的灵活性,让我们可以对层进行定义,并将多重特征输入合并到一个层中。当我们做好准备,它也能够很容易地将我们的wide和deep模型结合到一起。使用Functional API,我们就可以在短短几行代码中定义我们的wide模型。首先,我们将输入层定义为12000个元素向量(对应词汇表中的每个单词)。然后我们将它连接到Dense输出层,以得出价格预测。
然后我们编译这个模型,这样就可以使用了:
如果我们对其本身使用wide模型,那么这里我们就要调用fit()函数进行训练,调用evaluate()函数进行评估。因为我们以后会把它和deep模型结合起来,所以我们可以在两个模型结合后在进行训练。现在,是时候建立deep模型了。
第二部分:deep模型
为了用deep代表葡萄酒描述,我们将把它作为一种embedding来表示。有很多关于word embeddings的资源,但简单来说就是它们提供了一种将词映射到向量的方法,这样类似的词在向量空间中将会更紧密地结合。
代表描述作为word embedding
为了将我们的文本描述转换为embedding层,我们首先需要将每个描述进行转换,使其成为对应于词汇表中的每个单词的整数向量。我们可以用Keras texts to sequence方法来实现这一点。
现在我们已经有了完整的描述向量,我们需要确保它们长度相同,才能把它们输入到我们的模型中。Keras也有可以作此处理的实用工具。我们用pad_sequences函数在每个描述向量中加入零点,以便它们长度相同(我将170设为最大长度,这样就无需缩短描述)。
描述被转换成长度相同的向量,我们已经准备好创建embedding层并将其输入到deep模型中。
建立deep模型
有两种方法可以创建一个embedding层:其一,我们可以用预训练得到的embedding权重(有很多开源的embedding词);其二,我们可以从词汇表中学习embedding。最好是对两者进行试验,看看哪一个在数据集上的表现更好。这里我们将使用第二种,即习得的embedding。
首先,我们将定义添加到deep模型的输入的形状。然后我们再将输入添加到embedding层。这里我使用了维度为8的embedding层(你可以尝试对embedding层的维度稍作调整)。embedding层的输出将是一个具有形状的三维向量:批处理大小,序列长度(本例中是170),embedding维度(本例中是8)。为了将我们的embedding层连接到Dense,并充分连接到输出层,我们需要先调用flatten()函数:
一旦用flatten()函数对embedding层进行了调整,就可以将它添加至模型并编译了:
第三部分:wide & deep
一旦我们成功定义了两个模型,将它们结合起来就很容易了。我们只需要创建一个层,将每个模型的输出连接起来,然后将它们合并到可以充分连接的Dense层中,将每个模型的输入和输出结合在一起,最后定义这一组合模型。显然,由于每个模型都在预测相同的事物(价格),所以每个模型的输出或标签都是相同的。还要注意的是,由于我们的模型输出是一个数值,我们不需要做任何预处理,它早已以正确的形式显示出来了:
这样我们就可以开始进行训练和评估了。你可以尝试找到最适合数据集的训练周期和批处理大小:
# Training
combined_model.fit([description_bow_train, variety_train] + [train_embed], labels_train, epochs=10, batch_size=128)
# Evaluation
combined_model.evaluate([description_bow_test, variety_test] + [test_embed], labels_test, batch_size=128)
通过受过训练的模型得出预测
终于到了最激动人心的时刻,现在让我们看看基于数据的模型性能,这样的表现是前所未有的。我们可以为受过训练的模型调用predict()函数,将其传递我们的测试数据集:
然后我们将比较测试数据集的前15种葡萄酒的实际价格与预测价格:
模型是如何进行比较的?让我们看看测试集中的三个例子:
1.酒瓶里冒出浓郁的香草味,即使是在这个不佳葡萄酒酿造期,果香也毫不逊色。这样强烈的水果酸中,含有草本成分,水果、酸、药草和香草以相同的比例迅速作用,生成美味的酒。密封的瓶体,这款酒年份不长,需要过酒换瓶或继续贮存,以完美地出现在世人面前。
预测价格:46.233624 实际价格: 45.0
2.日常酒品,干且浓郁,浆果樱桃口味,组织细腻均匀。
预测价格:9.694958实际价格:10.0
3.时尚圆瓶装,醇和的Barolo葡萄酒(产自Monforte d’Alba),喜欢浓稠多汁口感的人绝不会错过。薰衣草,甜胡椒,肉桂,白巧克力和香草混合的香气让人难忘。清爽的果酸和稳定的单宁使酸浆果的味道达到极致,口感独特。
预测价格:41.028854实际价格: 49.0
事实证明,葡萄酒的描述与价格之间存在某种联系。也许人类可能无法凭直觉进行推断,但ML模型可以。
相关文章:

如何发布自己的NPM包(模块)?
1.注册NPM 账号 注册地址:https://www.npmjs.com/。 2.初始化自己要发布的项目 搭建本地环境:安装node.js,包含了npm命令。新建目录,在该目录下,初始化项目:npm init。按照提示填写初始化信息,我…

PHP对于浮点型的数据需要用不同的方法去解决
Php: BCMathbc是Binary Calculator的缩写。bc*函数的参数都是操作数加上一个可选的 [int scale],比如string bcadd(string $left_operand, string $right_operand[, int $scale]),如果scale没有提供,就用bcscale的缺省值。这里大数直接用一个…
mysql提示符详解_MySQL字符集使用详解
查看字符集相关变量mysql> show variables like character%;————————–——————————-| Variable_name | Value |————————–——————————-| character_set_client | latin1 || character_set_connection | latin1 || character_set_database…
Apache漏洞修复
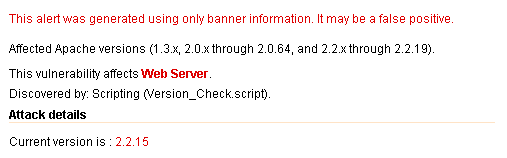
今天受同事的委托,修复一台服务器的Apache漏洞,主要集中在以下几点: 1.Apache httpd remote denial of service(中危) 修复建议:将Apache HTTP Sever升级到2.2.20或更高版本。 解决方法:升级HTT…
Java遍历Map对象的四种方式
关于java中遍历map具体哪四种方式,请看下文详解吧。 方式一 这是最常见的并且在大多数情况下也是最可取的遍历方式。在键值都需要时使用。 1 2 3 4 Map<Integer, Integer> map new HashMap<Integer, Integer>(); for (Map.Entry<Integer, Intege…
Tokyo Cabinet 安装
tokyocabinet :一个key-value的DBM数据库,但是没有提供网络接口,以下称TC。 tokyotyrant :是为TC写的网络接口,他支持memcache协议,也可以通过HTTP操作,以下称TT。 Tokyo Cabinet 是一款 DBM 数据库,Tokyo …
Packagist / Composer 中国全量镜像
Packagist 镜像 请各位使用本镜像的同学注意: 本镜像已经依照 composer 官方的数据源安全策略完全升级并支持 https 协议!请各位同学 按照下面所示的两个方法将 http://packagist.phpcomposer.com 修改为 https://packagist.phpcomposer.com 还没安装 co…
centos yum mysql-devel 5.5_CentOS 6.5下yum安装 MySQL-5.5全过程图文教程
在linux安装mysql是一个困难的事情,yum安装一般是安装的mysql5.1,现在经过自己不懈努力终于能用yum安装mysql5.5了。下面通过两种方法给大家介绍CentOS 6.5下yum安装 MySQL-5.5全过程,一起学习吧。方法一:具体方法和步骤如下所示&…
py 的 第 31 天
1.osi 7层模型 5层: 应用层 应用层 表示层 会话层 传输层 网络层 数据链路层 物理层 4层: 应用层 应用层 表示层 会话层 传输层 网络层 物理层 数据链路层 物理层 注意:7层背会。 2.tcp的三次握手&…
mysql实训报告_mysql数据库技术》实验报告.doc
mysql数据库技术》实验报告MySQL数据库技术实验报告系 别班 级学 号姓 名地点地点机房课程名称MySQL数据库技术实验名称实验1 MySQL的使用实 验 过 程目的要求:(1)掌握MySQL服务器安装方法(2)掌握MySQL Administrator的基本使用方法(3)基本了解数据库及其对象实验准…
PHP中魔术方法的用法
PHP中魔术方法的用法 /** PHP把所有以__(两个下划线)开头的类方法当成魔术方法。所以你定义自己的类方法时,不要以 __为前缀。 * */// __toString、__set、__get__isset()、__unset() /*The __toString method allows a class to decide how …
“互联网+”的时代,易佳互联也随着时代步伐前进着
一谈到互联网,我想大家的心里都不陌生,咱们总理工作报告中提出,制定“互联网”行动计划,推动移动互联网、云计算、大数据、物联网等与现代制造业结合,促进电子商务、工业互联网和互联网金融健康发展,引导互…
PHP 获取数组最后一个值
<?PHP$array array(1,2,4,6,8);echo end($array);?> <?PHP$array array(1,2,4,6,8);echo array_pop($array);?> <?PHP$array array(1,2,4,6,8);$k array_slice($array,-1,1);print_r($k); //结果是一维数组?>
解决nginx 502 bad gateway--团队的力量
nginx 502 bad gateway可以采取客户端强制刷新的方法,但是真正的解决要么改配置或者放CDN上。遇到这个问题,首先是有人发现可以加index.html访问,因为我们是线上网站,没有太多时间去研究,所以先临时这样;然…

MYSQL企业常用架构与调优经验分享
小道消息:2016爱维Linux高薪实战运维提高班全新登场,课程大纲:http://www.iivey.com/666-2一、选择Percona Server、MariaDB还是MYSQL1、Mysql三种存储引擎MySQL提供了两种存储引擎:MyISAM和 InnoDB,MySQL4和5使用默认的MyISAM存储…
mysql 5.x 安装_mysql 5.5.x zip直接解压版安装方法
到官网下载mysql-5.5.10-win32.zip,然后将mysql解压到任意路径,如:C:\mysql-5.5.10-win32打开计算机->属性->高级系统设置->环境变量,新建一个环境变量,变量名为:MYSQL_HOME,变量值为你…
阿里云移动数据分析服务使用教程
阿里云大学课程:阿里云移动数据分析服务使用教程课程介绍:移动数据分析 (Mobile Analytics) 是阿里云推出的一款移动App数据统计分析产品,为开发者提供一站式数据化运营服务:通用的多维度用户行为分析、数据开放并支持自定义分析、…
Apache的服务端包含--SSI
SSI定义: SSI(服务器端包含)提供了一种对现有HTML文档增加动态内容的方法。 作用: 一般出于效率的考虑,网站都会把内容尽可能的静态化成HTML文件,但是网站页面的布局往往比较复杂,各个部分的更新…
mysql校对规则_MySQL中的校对规则
详解MySQL中的校对规则Welcome to the MySQL monitor. Commands end with ; or \g.Your MySQL connection id is 7Server version: 5.6.14 MySQL Community Server (GPL)Copyright (c) 2000, 2013, Oracle and/or its affiliates. All rights reserved.Oracle is a registered…
c#操作oracle的通用类
using System;using System.Collections;using System.Collections.Generic;using System.Data;using System.Linq;using System.Text;using DDTek.Oracle;using System.Configuration;namespace Common{ <summary> /// OracleHelper 的摘要说明。 /// </summary> …
react es6+ 代码优化之路-1
这里集合了一些代码优化的小技巧 在初步接触 es6 和 react 的时候总结的一些让代码跟加简化和可读性更高的写法大部分知识点是自己在平时项目中还不知道总结的,一致的很多优化的点没有写出来,逐步增加中,目的是使用最少的代码,高效的解决问题…

反向ajax实现
英文原文: Reverse Ajax, Part 1: Introduction to Comet在过去的几年中,web开发已经发生了很大的变化。现如今,我们期望的是能够通过web快速、动态地访问应用。在这一新的文章系列中,我们学习如何使用反向Ajax(Revers…
ef关联多实体查询_Mybatis基本知识十二:关联关系查询之延迟加载:侵入式延迟加载...
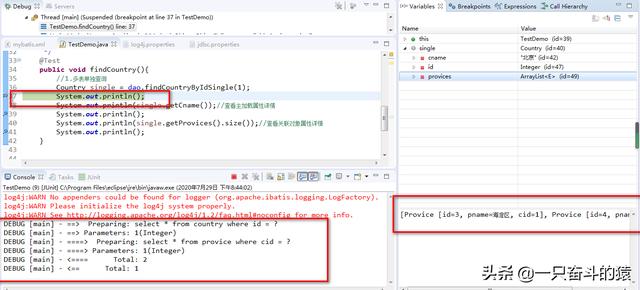
上一篇文章:《Mybatis基本知识十一:关联关系查询之延迟加载策略:直接加载》若文中有纰漏,请多多指正!!!1.前言延续上一章节,本章节主要讲解和演示在关联关系查询中侵入式延迟加载是怎么回事。与…

Java高危漏洞被再度利用 可攻击最新版本服务器
2019独角兽企业重金招聘Python工程师标准>>> 安全研究人员警告称,甲骨文在2013年发布的一个关键 Java 漏洞更新是无效的,黑客可以轻松绕过。这使得此Java高危漏洞可以被再度利用,击运行最新版本 Java 的个人计算机及服务器。甲骨文…
不断演进的 Chrome 安全标识
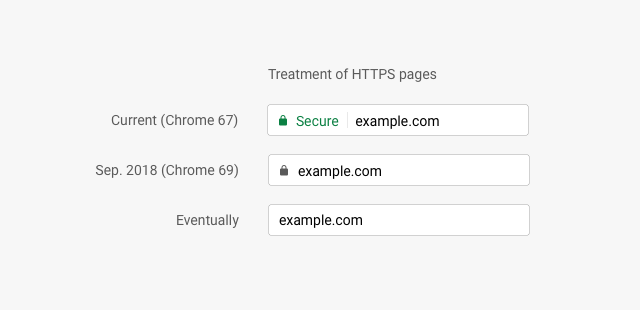
文 / Chrome Security 产品经理 Emily Schechter 此前,我们曾发布一项提议,建议将所有 HTTP 网页标记为确定 “不安全” 并移除 HTTPS 网页的安全标识。自从我们在 Chrome 中引入安全标识以来,网络上的 HTTPS 使用量迅速增加。今年晚些时候&a…
gcc -E 选项
-E 只激活预处理,这个不生成文件,你需要把它重定向到一个输出文件里面.例子用法:gcc -E hello.c > pianoapan.txtgcc -E hello.c | more慢慢看吧,一个hello word 也要与处理成800行的代码 -E选项,表示让gcc只进行“预处理”就行了。 所谓的预处理,就是…

剑指offer青蛙跳台阶问题
(1)一只青蛙一次可以跳上 1 级台阶,也可以跳上2 级。求该青蛙跳上一个n 级的台阶总共有多少种跳法。//递归方式 public static int f(int n) { //参数合法性验证 if (n < 1) { System.out.println("参数必须大于1!&quo…

mysql 亿级表count_码云社 | 砺锋科技-MySQL的count(*)的优化,获取千万级数据表的总行数 - 用代码改变世界...
专注于Java领域优质技术号,欢迎关注作者:李长念一、前言这个问题是今天朋友提出来的,关于查询一个1200w的数据表的总行数,用count(*)的速度一直提不上去。找了很多优化方案,最后另辟蹊径,选择了用explain来…

使用mysql内连接查询年龄_Mysql的连表查询
若一个查询同时涉及到两个以上的表,称为连表查询准备表create table department(id int auto_increment PRIMARY KEY,name varchar(20));departmentcreate table employee(id int primary key auto_increment,name varchar(20),sex enum(male,female) not null defa…
FastDFS安装与使用
安装注意要修改:/etc/fdfs/client.confvim /etc/fdfs/client.confbase_path/home/yuqing/fastdfs 修改为: base_path/home/fastdfstracker_server192.168.209.121:22122 修改为: tracker_server10.201.20.237:22122##include http.conf 修改…