yolov3(一:模型训练)
第一部分:训练已有的voc datasets 搞清楚该算法的模型训练流程
Darknet是Joseph维护的开源的神经网络框架,使用C语言编写:https://pjreddie.com/darknet/yolo/
Darknet快速,易于安装,同时支持CPU和GPU计算:项目源码可以在github :https://github.com/pjreddie/darknet
1 初步使用darknet进行预测
1.1 安装框架
git clone https://github.com/pjreddie/darknet.git
cd darknet
make

1.2 测试
使用YOLO提供的模型利用darknet进行预测,在如下地址下载yolov3.weights的权重文件(模型)
wget https://pjreddie.com/media/files/yolov3.weights
#执行
./darknet detect cfg/yolov3.cfg yolov3.weights data/person.jpg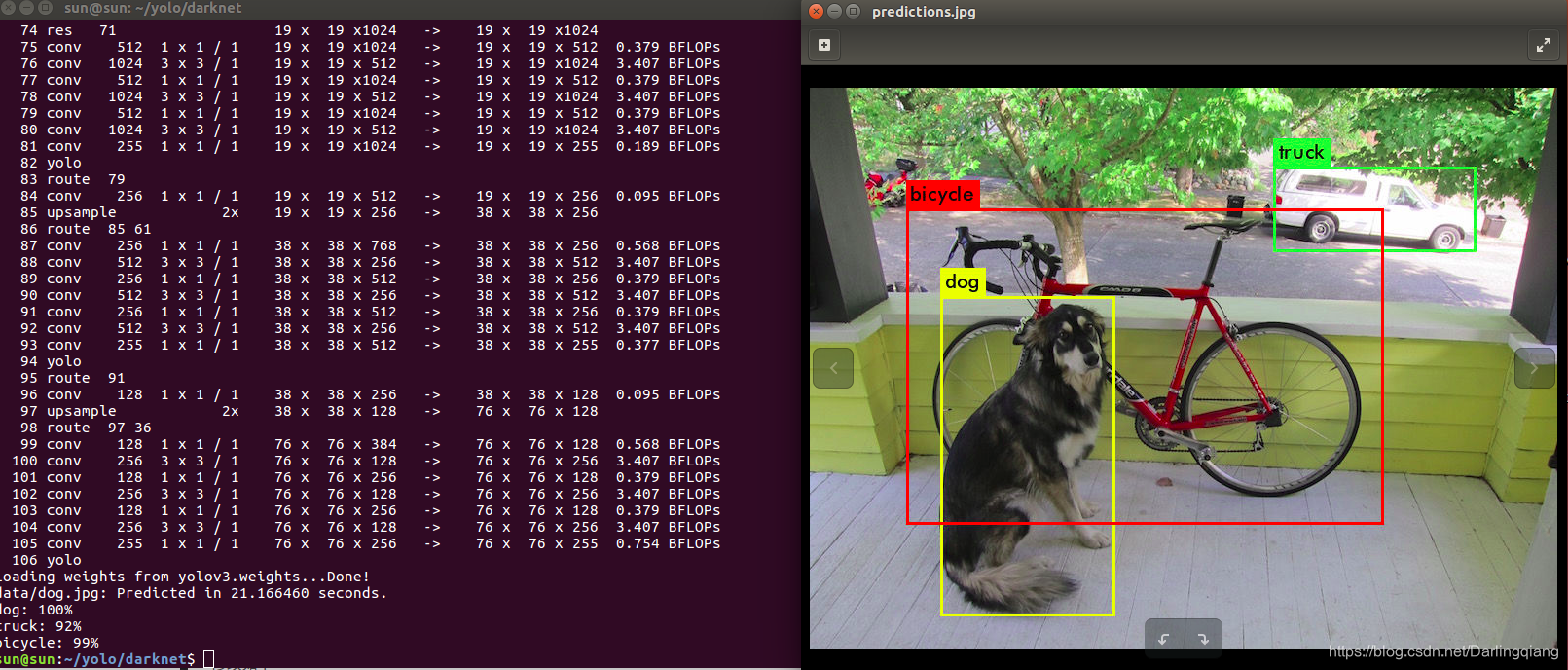
1.3 改变检测阈值
YOLO只会把置信度超过0.5的对象定位出来,你可以修改这一阈值。执行命令的时候指定-thresh参数即可:
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg -thresh 0.5上面的设置是:即使置信度是0.5也将目标显示定位出来 。
1.4 配置GPU
程序跑通之后,需要了解一些基本的配置
打开makefile可以看到如下内容(在这之前,要安装anaconda并配置环境)
GPU=1
CUDNN=1
OPENCV=0
OPENMP=0
DEBUG=0
......如果想要指定使用哪块显卡,你可以在命令行中附加参数-i用阿里指定你想使用的显卡序号,例如:
./darknet -i 1 imagenet test cfg/alexnet.cfg alexnet.weights你也可以使用CUDA进行编译,使用CPU进行计算,使用-nogpu参数即可:
./darknet -nogpu imagenet test cfg/alexnet.cfg alexnet.weights2 对YOLO训练VOC数据集
这里可以探索一下如何使用YOLO训练其他数据集
2.1 下载数据
wget https://pjreddie.com/media/files/VOCtrainval_11-May-2012.tar
wget https://pjreddie.com/media/files/VOCtrainval_06-Nov-2007.tar
wget https://pjreddie.com/media/files/VOCtest_06-Nov-2007.tar
tar xf VOCtrainval_11-May-2012.tar
tar xf VOCtrainval_06-Nov-2007.tar
tar xf VOCtest_06-Nov-2007.tar上面的数据下载到一起后,解压会同时存在与VOCdevkit/目录
2.2 生成VOC数据集的标签
VOCdevkit的目录结构大致如下
drwxrwxrwx 2 root root 266240 Nov 6 2007 Annotations
drwxrwxrwx 5 root root 4096 Nov 6 2007 ImageSets
drwxrwxrwx 2 root root 274432 Nov 6 2007 JPEGImages
drwxrwxrwx 2 root root 20480 Nov 6 2007 SegmentationClass
drwxrwxrwx 2 root root 20480 Nov 6 2007 SegmentationObject
drwxr-xr-x 2 root root 274432 Jan 8 04:30 labels
xml文件作为标签是很繁琐和复杂,在VOCdevkit 同级目录下运行 python脚本,下面运行官方提供的脚本生成指定格式的label文件。
wget https://pjreddie.com/media/files/voc_label.py
python voc_label.py根据每张图片对应的xml文件,会分别在VOCdevkit/VOC2007/labels/和VOCdevkit/VOC2012/labels/位置生成对应于每张图片的.txt文件,作为图片的标签,例如
16 0.437 0.764 0.446 0.466666666667
# 符合如下形式
<object-class> <x> <y> <width> <height>object-class代表类别,x\y\width\height代表图片的相对位置和高宽。
根目录下面则多了几个txt文件:

这些txt文件汇总了所需训练或者验证的图片的绝对路径,后面训练的时候需要用到
合并这些训练集:
cat 2007_train.txt 2007_val.txt 2012_*.txt > train.txt
2.3 修改训练的配置和下载预训练权重
打开cfg/voc.data文件修改训练集和测试集文件的路径
classes= 20
train = /root/yolo/darknet/vocdata/train.txt
valid = /root/yolo/darknet/vocdata/2007_test.txt
names = data/voc.names
backup = backup然后下载预训练权重
wget https://pjreddie.com/media/files/darknet53.conv.742.4 训练VOC模型
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74 2>1 | tee visualization/train_yolov3.log ./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74 -gpus 0,1,2,3# visualization 训练过程可视化./darknet detector train ./cfg/voc.data ./cfg/yolov3-voc.cfg darknet53.conv.74 2>1 | tee visualization/train_yolov3.log2.4.1 训练过程 train_yolov3.log 可视化
python3 extract_log.py
python3 visualization_loss.py
python3 visualization_iou.py#!/usr/bin/python
#coding=utf-8
#该文件用于提取训练log,去除不可解析的log后使log文件格式化,生成新的log文件供可视化工具绘图
import inspect
import os
import random
import sys
def extract_log(log_file, new_log_file, key_word):with open(log_file, 'r') as f:with open(new_log_file, 'w') as train_log:for line in f:#去除多GPU的同步log;去除除零错误的logif ('Syncing' in line) or ('nan' in line):continueif key_word in line:train_log.write(line)f.close()train_log.close()extract_log('./2048/train_log2.txt', './2048/log_loss2.txt', 'images')
extract_log('./2048/train_log2.txt', 'log_iou2.txt', 'IOU')#!/usr/bin/python
#coding=utf-8import pandas as pd
import numpy as np
import matplotlib.pyplot as plt#根据自己的log_loss.txt中的行数修改lines, 修改训练时的迭代起始次数(start_ite)和结束次数(end_ite)。
lines = 4500
start_ite = 6000 #log_loss.txt里面的最小迭代次数
end_ite = 15000 #log_loss.txt里面的最大迭代次数
step = 10 #跳行数,决定画图的稠密程度
igore = 0 #当开始的loss较大时,你需要忽略前igore次迭代,注意这里是迭代次数y_ticks = [0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0, 1.1, 1.2, 1.3, 1.4]#纵坐标的值,可以自己设置。
data_path = '2048/log_loss2.txt' #log_loss的路径。
result_path = './2048/avg_loss' #保存结果的路径。####-----------------只需要改上面的,下面的可以不改动
names = ['loss', 'avg', 'rate', 'seconds', 'images']
result = pd.read_csv(data_path, skiprows=[x for x in range(lines) if (x<lines*1.0/((end_ite - start_ite)*1.0)*igore or x%step!=9)], error_bad_lines=\
False, names=names)
result.head()
for name in names:result[name] = result[name].str.split(' ').str.get(1)result.head()
result.tail()for name in names:result[name] = pd.to_numeric(result[name])
result.dtypes
print(result['avg'].values)fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)###-----------设置横坐标的值。
x_num = len(result['avg'].values)
tmp = (end_ite-start_ite - igore)/(x_num*1.0)
x = []
for i in range(x_num):x.append(i*tmp + start_ite + igore)
#print(x)
print('total = %d\n' %x_num)
print('start = %d, end = %d\n' %(x[0], x[-1]))
###----------ax.plot(x, result['avg'].values, label='avg_loss')
#ax.plot(result['loss'].values, label='loss')
plt.yticks(y_ticks)#如果不想自己设置纵坐标,可以注释掉。
plt.grid()
ax.legend(loc = 'best')
ax.set_title('The loss curves')
ax.set_xlabel('batches')
fig.savefig(result_path)
#fig.savefig('loss')训练完成后权重保存在 backup 文件夹内,依据训练情况可手动停止训练
-gpu 0可指定 GPU 训练, -gpus 0,1,2,3 可指定多 GPU训练
2.4.2 训练参数详解
Avg IOU:当前迭代中,预测的box与标注的box的平均交并比,越大越好,期望数值为1;
Class: 标注物体的分类准确率,越大越好,期望数值为1;
obj: 越大越好,期望数值为1;
No obj: 越小越好;
.5R: 以IOU=0.5为阈值时候的recall; recall = 检出的正样本/实际的正样本
0.75R: 以IOU=0.75为阈值时候的recall;
count:正样本数目。 1: 1452.927612, 1452.927612 avg, 0.000000 rate, 1.877576 seconds, 32 images
第几批次,总损失,平均损失,当前学习率,当前批次训练时间,目前为止参与训练的图片总数
1: 指示当前训练的迭代次数
1452.927612: 是总体的Loss(损失)结果:
50200: -nan, nan avg, 0.000010 rate, 0.083617 seconds, 50200 images
Saving weights to backup/yolov3-voc.backup
Saving weights to backup/yolov3-voc_final.weights
3. 测试
./darknet detector test ./cfg/voc.data ./cfg/yolov3-voc.cfg ./backup/yolov3-voc_30000.weights ./data/test.jpg./darknet detector demo ../cfg/voc.data ./cfg/yolov3-voc.cfg ./backup/yolov3-voc_30000.weights ./data/test.mp4第二部分:根据所需要数据训练更有针对性的模型
相关文章:
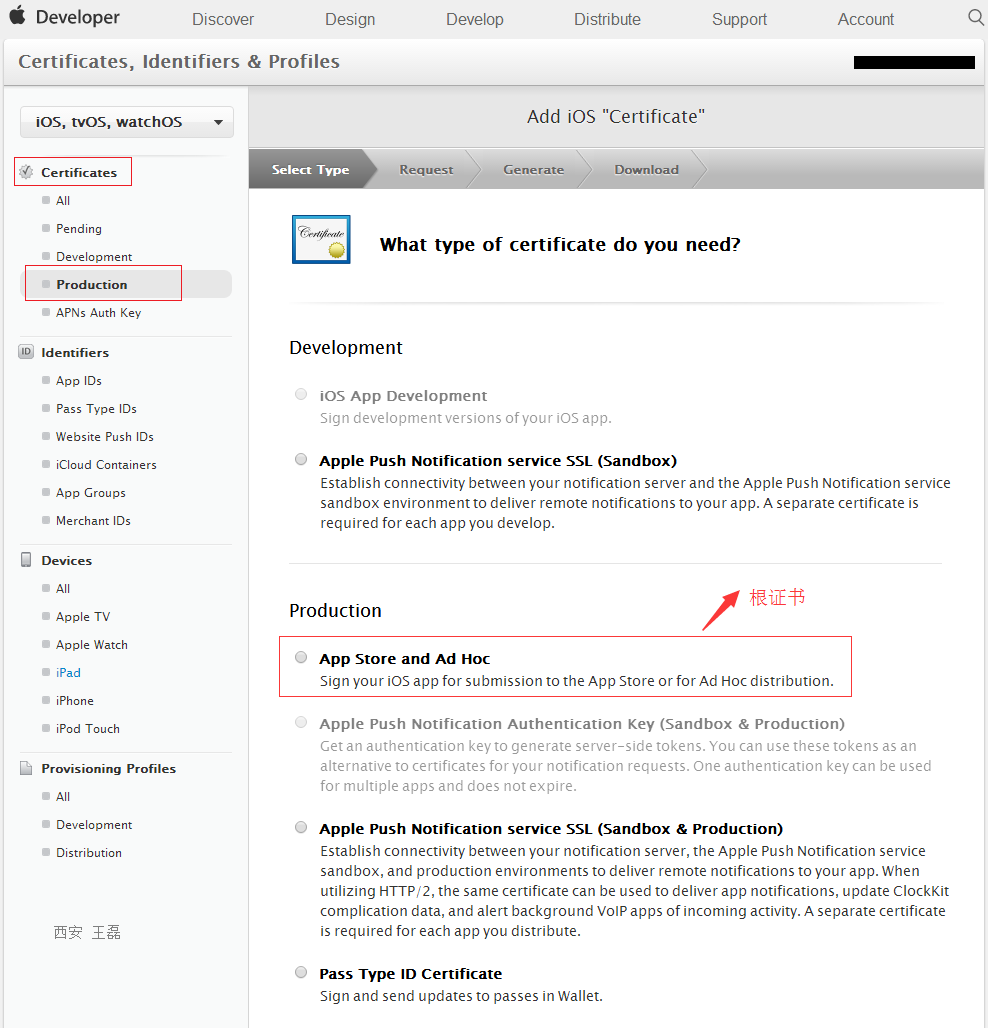
Ios生产证书申请(含推送证书)
一、Mac机上生成请求文件。 Mac机上点击证书助手 > 从证书颁发机构请求证书 > 得到CertificateSigningRequest.certSigningRequest请求文件(此请求证书建议一直保存,因为根证书的生成需要使用此请求文件,根证书多个app可以使用一个&…
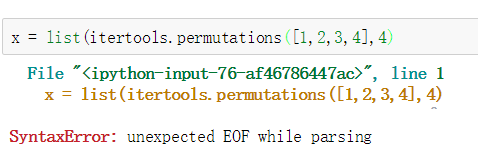
【Python】SyntaxError: unexpected EOF while parsing
找到错误的地方是 少打了半个括号 emmm 1、可能是语法问题,需要自己检查代码 2、可能是用python2.7来运行python3.0的代码不兼容

华为云家庭视频监控帮你一起守护家
设想一下?离开家了突然想起家里空调没关怎么办?家里没人有陌生人入侵了怎么办?不在家家里老人出事了怎么办? 不用愁,总有办法解决的,这些日常生活中极容易遇到的事情,没有分身术的时候ÿ…

SLAM之特征匹配(三)————RANSAC------LO-RANSAC Algorithm
matlab 编译loransac,lapack mex ranH.c时一直链接错误。 原来mex在编译多个文件时要把所有的C文件都列出来。命令如下: mex loransacH.mex.c ranH.c utools.c Htools.c lapwrap.c matutl.c rtools.c -ID:\lapack\headers\lapack -LD:\lapack - lcbia.l…

【Codeforces】1136C Nastya Is Transposing Matrices (矩阵转置)
http://codeforces.com/contest/1136/problem/C 第一个矩阵可否通过转置,变换成第二个矩阵,可以的话输出“YES”,不可以的话,输出“NO” 转置之后,对角线元素是不变的 用map,或者vector 都可以 #includ…
linux基础篇-02,linux时间管理date hwclock cal 简述
################################################时间管理1,date:系统时钟查看当前系统时间[rootJameszhan etc]# date2016年 11月 14日 星期一 20:16:37 CST################################################设定系统时间 2016年 07月 20日 星期三 10:30:00 CST…
Spark shuffle调优
Spark shuffle是什么Shuffle在Spark中即是把父RDD中的KV对按照Key重新分区,从而得到一个新的RDD。也就是说原本同属于父RDD同一个分区的数据需要进入到子RDD的不同的分区。现在的spark版本默认使用的是sortshuffle;shuffle在哪里产生shuffle在spark的算子中产生,也就…
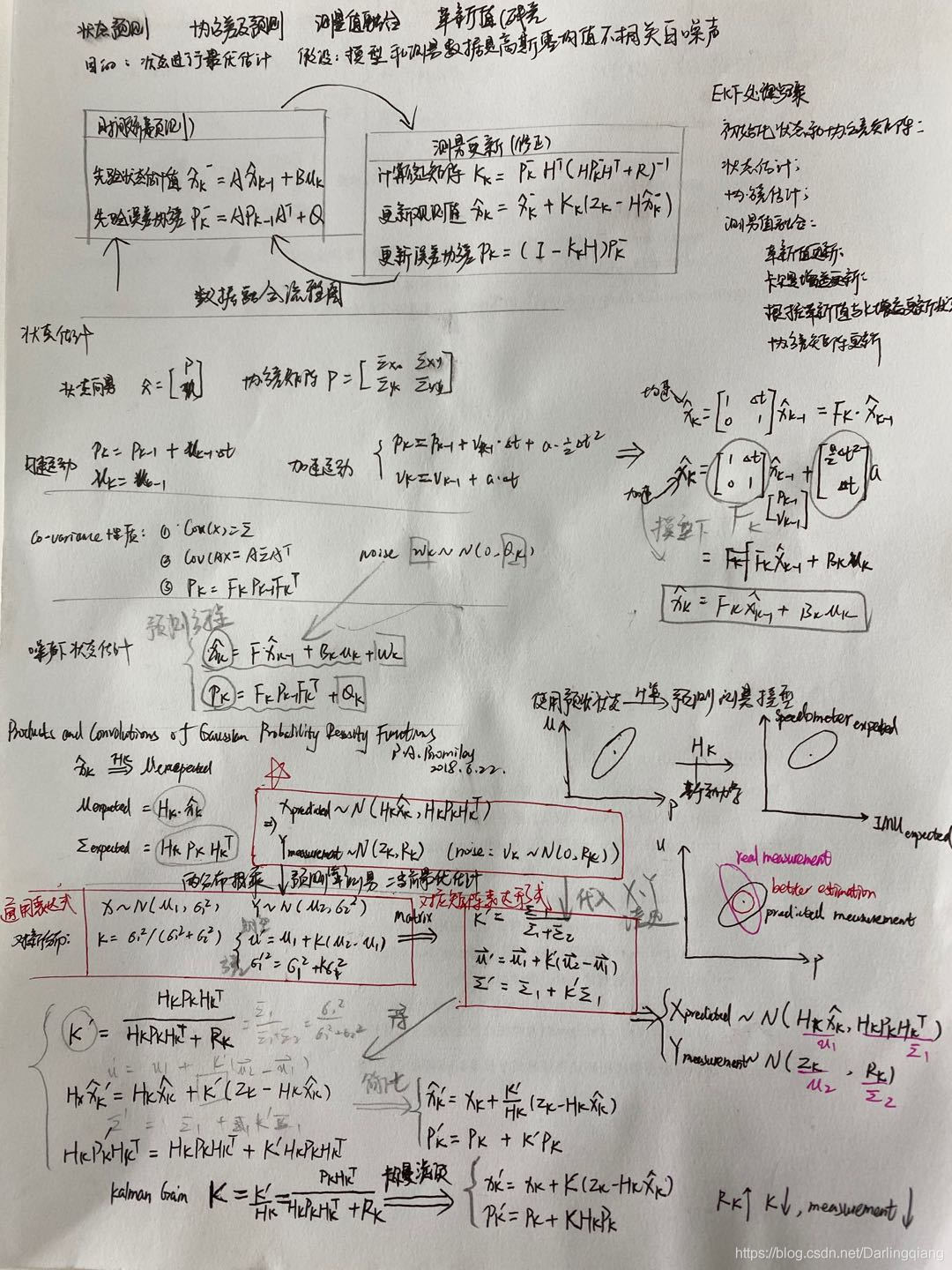
多传感器融合之滤波(一)——卡尔曼滤波(KF)推导
c参考资料:https://www.bzarg.com/p/how-a-kalman-filter-works-in-pictures/ 卡尔曼滤波本质上是一个数据融合算法,将具有同样测量目的、来自不同传感器、(可能) 具有不同单位 (unit) 的数据融合在一起,得到一个更精确的目的测量值。 卡尔…
【HDU】1284 钱币兑换问题 (想一想)
http://acm.hdu.edu.cn/showproblem.php?pid1284 除以三,看最多能放多少个三分的硬币,加一表示全部都是一分的硬币着一种情况。之后用一个循环看一下,有多少种情况 因为确定了有几个三分,有几个两分,一分的也就自然…
抓取网页的脚本 【修复】
之前张耀老师的网页脚本由于51cto升级,课程列表页面改用javascript失效了笔者发现视频课程页面右边的列表都为静态化后的视频课程地址,遂将老师初始版本的脚本进行了修改,在对视频课程页面使用时结果正常,遂将及修改后的脚本和部分…
实例规格 ECS (共享计算型)和 (通用型-原独享)性能上有什么区别?...
实例规格 ECS (共享计算型)和 (通用型-原独享)性能上有什么区别? 实例规格 共享计算型 和 通用型(原独享), 如果同样是2核4G 或者4核8G ; 性能上有什么差异/差距大吗? 内存型比通用性性能好些,而且CPU和内存配比: 通用型为1:2&…
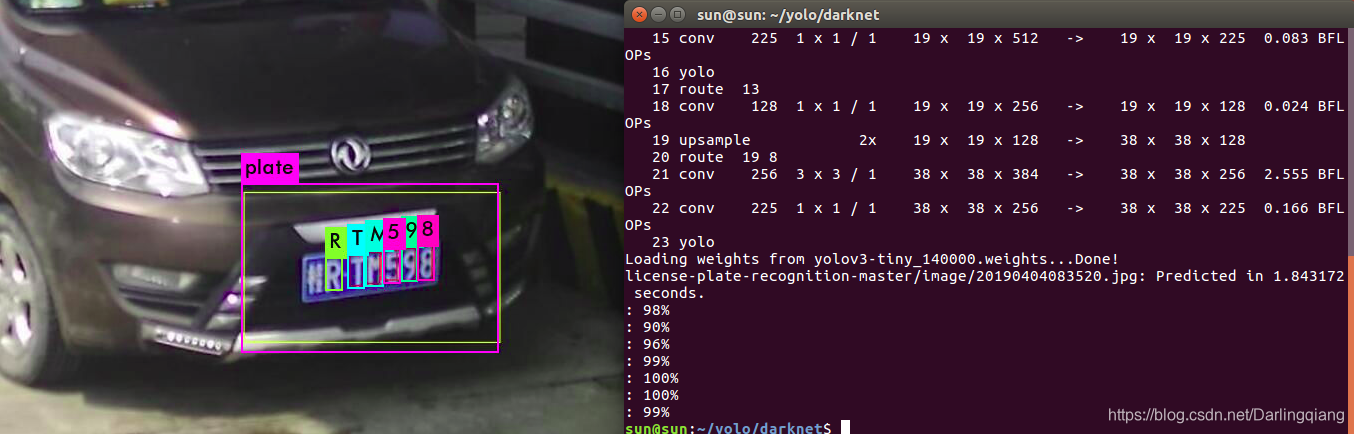
yolov3(二:车牌识别)
0.按照:https://blog.csdn.net/Darlingqiang/article/details/103889245步骤训练自己的模型 1.下载[data.zip]:链接: https://pan.baidu.com/s/1NahLmB5YajUJT_Gk1OgN7A 提取码: 8888 2.进入data/voc目录下运行voc_label.bat重新生成2019_train.txt, 201…

[转]CSS hack大全详解
转自:CSS hack大全&详解 1、什么是CSS hack?CSS hack是通过在CSS样式中加入一些特殊的符号,让不同的浏览器识别不同的符号(什么样的浏览器识别什么样的符号是有标准的,CSS hack就是让你记住这个标准),…
【Python】打印魔方阵
1.将“1”放在第一行,中间一列; 2.从2开始至N*N各数按如下规律: 每一个数存放的行比上一个数的行减1; 每一个数存放的列比上一个数的列加1; 3.当一个数行为1,下一个数行为N; 4.当一个数列数为N,下一个…

读书笔记:《图解HTTP》第三章 HTTP报文
原文地址博客积累地址 HTTP报文的作用 HTTP报文时是HTTP进行请求和响应时用来交换信息的,可以理解它为搬东西的包裹,来搬运交换的信息报文流 HTTP报文在HTTP应用程序(客户端、服务器、代理)之间发送数据块,这些数据块以…
在Web.config或App.config中的添加自定义配置
.Net中的System.Configuration命名空间为我们在web.config或者app.config中自定义配置提供了完美的支持。最近看到一些项目中还在自定义xml文件做程序的配置,所以忍不住写一篇用系统自定义配置的随笔了。 如果你已经对自定义配置了如指掌,请忽略这篇文章…
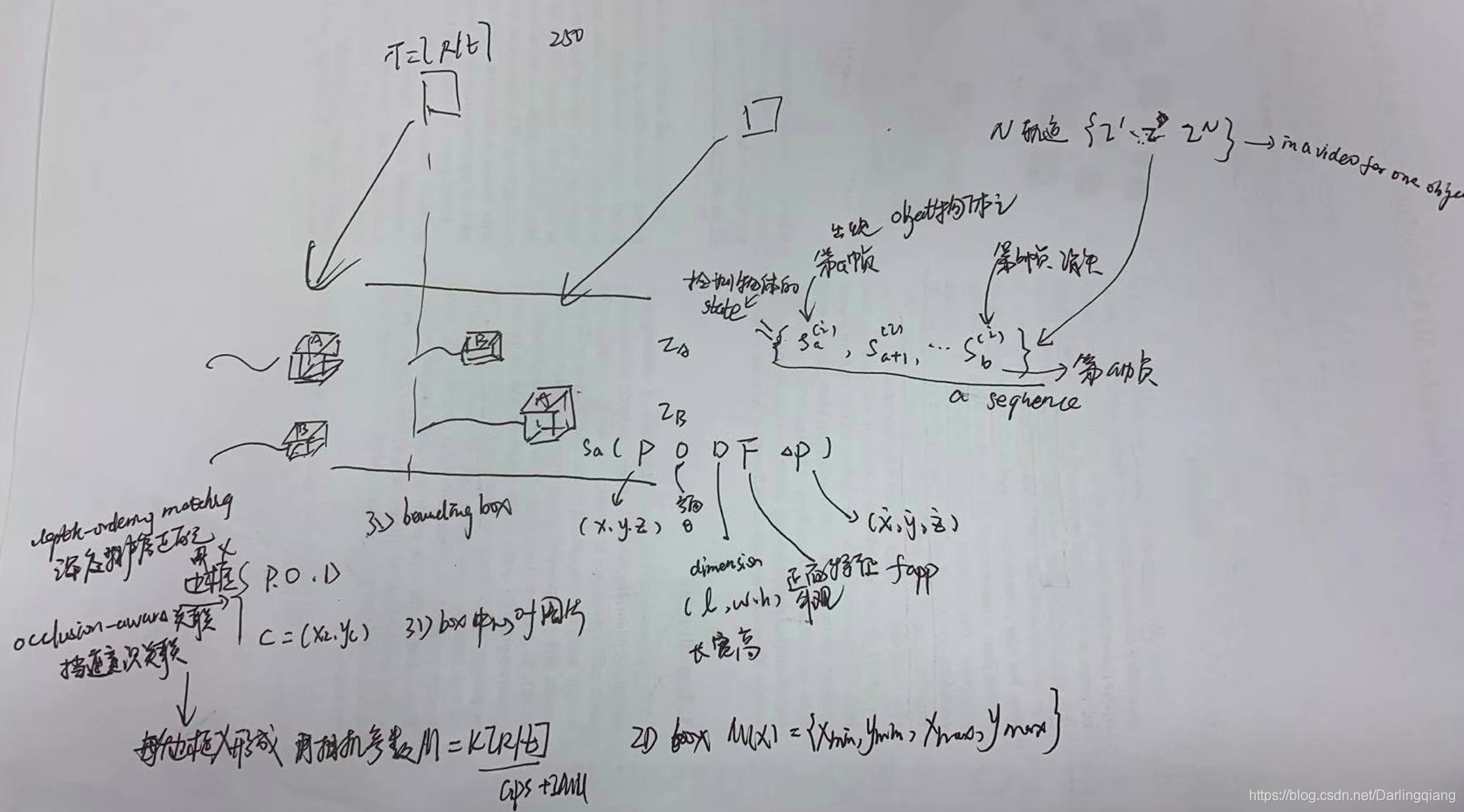
yolov3(三:算法框架解析)
应用见: https://blog.csdn.net/Darlingqiang/article/details/103889245 https://blog.csdn.net/Darlingqiang/article/details/104040582 首先通过一些简单的应用实现去理解yolov3的网络框架,接着让我们开始对yolov3的网络框架解析之旅。 首先&…
【牛客】简单排序 (STL)
https://ac.nowcoder.com/acm/contest/547/F 首先将一系列数存入到数组中,然后利用set的upper_bound返回第一个大于他的函数,如果存在这样的,就把大于他的那个数删除,加入这个新的数,否则就表示序列中没有大于他的数&…
python基础04
python基础04 python2在编译安装时,可以通过参数 -----enable----unicodeucs2 或 -----enable--unicodeucs4 分别用于指定使用2个字节,4个字节表示一个Unicode字符。python3无法进行选择,默认使用usc4. 查看当前python中表示Unicode字符串时占…
【Java】字符串(一)
目录 一、创建字符串 二、连接字符串 连接多个字符串 连接其他数据类型 三、获取字符串的信息 获取字符串的长度 字符串查找 获取指定索引位置的字符 四、字符串操作 获取子字符串 去除空格 字符串的替换 判断字符串是否相等 按字典顺序比较两个字符串 字母大小…
每天一命令 git checkout
检出 checkout 是git常用命令之一.主要用于创建切换分支,覆盖本地修改等 git checkout 用于显示工作区,暂存区,版本库中文件的区别 git checkout -b branch 用于创建一个新的分支, git checkout branch 用于检出一个分支 git checkout [commit] --filename 用暂存…

python数据结构与算法:排序算法(面试经验总结)
快排:最优复杂度 O(n*logn) 最坏时间复杂度O(n^2)平均时间复杂度n^(1.3) 归并排序:最优/平均/最坏 时间复杂度均O(nlogn),但是内存占用为list大小的两倍,算法稳定 ####…
go微服务框架go-micro深度学习(一) 整体架构介绍
产品嘴里的一个小项目,从立项到开发上线,随着时间和需求的不断激增,会越来越复杂,变成一个大项目,如果前期项目架构没设计的不好,代码会越来越臃肿,难以维护,后期的每次产品迭代上线…
多传感器融合之滤波(二)EKF
扩展卡尔曼滤波算法是解决非线性状态估计问题最为直接的一种处理方法,尽管EKF不是最精确的”最优“滤波器,但在过去的几十年成功地应用到许多非线性系统中。所以在学习非线性滤波问题时应该先从EKF开始。 EKF算法是将非线性函数进行泰勒展开,…
【Java】字符串(二)
目录 字符串格式化 日期和时间字符串格式化 日期格式化 时间格式化 格式化常见的日期时间组合 常见类型格式化 正则表达式(未完待续) 字符串生成器 字符串格式化 String类使用静态format()方法用于创建格式化的字符串。 format(String format&a…

为什么vue.js一眼看上去很美?
对其他框架我是佩服,对vue.js我则是爱。我就是一眼看上了vue.js,于是用它做各种东西,反反复复多次,然后觉得有些融会贯通,然后,我稍微细的思量了下,到底vue.js靓丽在哪? 还是上案例对比说明。这…

阿里云MWC 2019发布7款产品:Blink每秒可完成17亿次计算
在巴塞罗那举行的MWC 2019上,国内厂商不仅展示了目前的5G发展进程,也带来了一些云计算方面的进展。据报道,阿里云面向全球发布了7款产品,涵盖无服务器计算、高性能存储、全球网络、企业级数据库、大数据计算等主要云产品ÿ…

运用面向对象原则,设计一款音乐点唱机
2019独角兽企业重金招聘Python工程师标准>>> .设计内容及要求 能够实现简单的音乐播放器功能,如:打开本地文件,播放,暂停,停止,背景播放,单曲循环等等,界面充…
多传感器融合之滤波(三)--------
多传感器融合之滤波(三):IMU,GPS,Lidar,Ladar数据处理
【Codeforces】835B The number on the board (贪心)
把所有字符串上的数字加起来,看是否超过k,没有超过k的话,把字符串sort,从第一位开始,将字符变成9,直到sum大于等于k为止。 #include <iostream> #include <cstring> #include <string> …