本面试题由2344095 (有心人)整理, 由ashzs((可以包含中文字符)) 解答,感谢二位!
1.磁盘柜上有14块73G的磁盘, 数据库为200G 大小包括日志文件,如何设置磁盘(要说明这14磁盘是怎么用的)?
2.有两服务器群集,分别为node1和node2 现在要打win200系统补丁,打完后,要重新启动,如何打补丁,不能影响用户使用(要用群集的术语详细说明)。
3.有一个A 数据库,分别复制到B和C B 要求 每次数据更新 也同时更新,C 每天更新一次就行,如何制定复制策略!
4.有一个order 表,有90个字段,20个索引,15个复合索引,其中有3个索引字段超过10个,如何进行优化
5.有一个数据库200G大小,每天增加50M 允许用户随时访问,制定备份策略(详细说明)。
6.管理50台数据库,日常工作是检查数据库作业是否完成,你该如何完成这项检查工作?
7.自定义函数和存储过程的区别是什么,什么情况下只能用自定义函数,什么情况下只能用存储过程
8.SQL 2005 的新特性是什么 ? 与oracle 有什么区别?
9.DBA 的品质应该有哪些,你有哪些, 有什么欠缺的?
10。如果想配置SQL Mail 应该在服务器安装哪些软件!
ashzs((可以包含中文字符)) 解答如下:
1.磁盘柜上有14块73G的磁盘, 数据库为200G 大小包括日志文件,如何设置磁盘(要说明这14磁盘是怎么用的)?
这个问题应该是考察硬件知识和数据库物理部署。
首先需要知道这些磁盘是否要用于存放数据库备份文件和数据库性能(读/写)要求。来决定raid的级别。
1)、如果偏重于性能考虑,而且不用存放数据库备份文件的话,考虑使用raid0+1,这样可使用的磁盘容量为:14*73*50%=511G。
2)、如果读/写性能要求不高,而且还比较抠门的话,可以考虑raid5,这样可使用的磁盘容量为:13*73=949G。
至于如何使用应该是说数据库物理文件的部署。注意说出将tempdb,data file,log file分开存放以减少I/O竞争即可。其实现在的条带化磁盘一般都会自动将文件分存,人为的分布已经越来越不重要了。
2.有两服务器群集,分别为node1和node2 现在要打win200系统补丁,打完后,要重新启动,如何打补丁,不能影响用户使用(要用群集的术语详细说明)。
这个具体操作有点忘了。大致是:首先看哪个节点正在使用,通过节点IP(私有)访问另一个空闲节点,为其打上补丁,然后在群集管理器中停止该节点(也可以用命令行方式),重新启动。等到启动完毕,将切换使用节点,为另一个节点打补丁。然后重新启动。
3.有一个A 数据库,分别复制到B和C B 要求 每次数据更新 也同时更新,C 每天更新一次就行,如何制定复制策略!
这个应该考察的是复制知识。
a->b
1)、如果使用SQL Server复制功能,那么让a->b使用事务性复制方式(同步复制)。
2)、如果表不多,也可以自己写触发器,利用linkserver+distribute transaction。
a->c
1)、如果使用SQL Server复制功能,那么让a->b使用快照复制方式,在某一时间点进行一次性复制。
2)、也可以自己写bat,将a备份后,通过ftp传输备份介质,恢复c。(比较麻烦,不推荐)
4.有一个order 表,有90个字段,20个索引,15个复合索引,其中有3个索引字段超过10个,如何进行优化
这个问题问的比较没水平。你不详细说明这个表的使用方式(读写类的,还是几乎是静态表),就问人家怎么优化?!!还不如问问索引的分布访问原理更好。
看得出他就想让你说:那三个索引超过10个,B树遍例效率很低,适当减少字段数目。如果是SQL2005,可以将选择性不好的字段放在“索引附加字段”中,以保证索引覆盖。而且SQL Server由于有锁升级的毛病,可以考虑拆开表。
5.有一个数据库200G大小,每天增加50M 允许用户随时访问,制定备份策略(详细说明)。
这种情况可以采用增量备份方式。每周日做一次全备份,周一到周六作增量备份(由于数据量较少,可以考虑每30分钟增量备份一次)。这样可以尽量减少性能消耗,而且如果transaction log丢失的情况下,可以保证最多丢失30分钟数据。
6.管理50台数据库,日常工作是检查数据库作业是否完成,你该如何完成这项检查工作?
这个比较简单。在每台机器上建立linkserver,然后在DBA管理服务器上做个分布式视图,每次查询该视图,各个机器上的作业情况一目了然。分布式视图写法:
create view vw_job
as
select '机器一' as MName,* from linkserver1..sysjobactivity
union all
select '机器二' as MName,* from linkserver2..sysjobactivity
union all
select '机器三' as MName,* from linkserver3..sysjobactivity
。。。
7.自定义函数和存储过程的区别是什么,什么情况下只能用自定义函数,什么情况下只能用存储过程
这个应该是考察存储过程编写经验。一般自定义函数主要用于其他sql中的调用,如:
select yourfunc(...) from table
这种情况下,一般只能通过函数实现。
存储过程的功能要远远强于函数,例如动态执行sql(sp_executesql)的使用和一些特殊的功能,自定义函数中是不支持的,只能用存储过程实现。
8.SQL 2005 的新特性是什么 ? 与oracle 有什么区别?
SQL 2005 的新特性一般都是和Oracle学的。
下面是当时被leimin逼着写的,你可以做个参考:
一、数据库设计方面
1、字段类型。
varchar(max)\nvarchar(max)类型的引入大大的提高了编程的效率,可以使用字符串函数对CLOB类型进行操作,这是一个亮点。但是这就引发了对varchar和char效率讨论的老问题。到底如何分配varchar的数据,是否会出现大规模的碎片?是否碎片会引发效率问题?这都是需要进一步探讨的东西。
varbinary(max)代替image也让SQL Server的字段类型更加简洁统一。
XML字段类型更好的解决了XML数据的操作。XQuery确实不错,但是个人对其没好感。(CSDN的开发者应该是相当的熟了!)
2、外键的级联更能扩展
可能大部分的同行在设计OLTP系统的时候都不愿意建立外键,都是通过程序来控制父子数据的完整性。但是再开发调试阶段和OLAP环境中,外键是可以建立的。新版本中加入了SET NULL 和 SET DEFAULT 属性,能够提供能好的级联设置。
3、索引附加字段
这是一个不错的新特性。虽然索引的附加字段没有索引键值效率高,但是相对映射到数据表中效率还是提高了很多。我做过试验,在我的实验环境中会比映射到表中提高30%左右的效率。
4、计算字段的持久化
原来的计算字段其实和虚拟字段很像。只是管理方面好了而已,性能方面提高不多。但是SQL2005提供了计算字段的持久化,这就提高了查询的性能,但是会加重insert和update的负担。OLTP慎用。OLAP可以大规模使用。
5、分区表
分区表是个亮点!从分区表也能看出微软要做大作强SQL Server的信心。资料很多,这里不详细说。但是重点了解的是:现在的SQL Server2005的表,都是默认为分区表的。因为它要支持滑动窗口的这个特性。这种特性对历史数据和实时数据的处理是很有帮助的。
但是需要注意的一点,也是我使用过程中发现的一个问题。在建立function->schema->table后,如果在现有的分区表上建立没有显式声明的聚集索引时,分区表会自动变为非分区表。这一点很让我纳闷。如果你觉得我的非分区索引无法对起子分区,
你可以提醒我一下呀!没有任何的提醒,直接就变成了非分区表。不知道这算不算一个bug。大家也可以试试。
分区表效率问题肯定是大家关心的问题。在我的试验中,如果按照分区字段进行的查询(过滤)效率会高于未分区表的相同语句。但是如果按照非分区字段进行查询,效率会低于未分区表的相同语句。但是随着数据量的增大,这种成本差距会逐渐减小,趋于相等。(500万数量级只相差10%左右)
6、CLR类型
微软对CLR作了大篇幅的宣传,这是因为数据库产品终于融入.net体系中。最开始我们也是狂喜,感觉对象数据库的一些概念可以实现了。但是作了些试验,发现使用CLR的存储过程或函数在达到一定的阀值的时候,系统性能会呈指数级下滑!这是非常危险的!只使用几个可能没有问题,当一旦大规模使用会造成严重的系统性能问题!
其实可以做一下类比,Oracle等数据库产品老早就支持了java编程,而且提供了java池参数作为用户配置接口。但是现在有哪些系统大批使用了java存储过程?!连Oracle自己的应用都不用为什么?!还不是性能有问题!否则面向对象的数据库早就实现了!
建议使用CLR的地方一般是和应用的复杂程度或操作系统环境有很高的耦合度的场景。如你想构建复杂的算法,并且用到了大量的指针和高级数据模型。或者是要和操作系统进行Socket通讯的场景。否则建议慎重!
7、索引视图
索引视图2k就有。但是2005对其效率作了一些改进但是schema.viewname的作用域真是太限制了它的应用面。还有一大堆的环境参数和种种限制都让人对它有点却步。
8、语句和事务快照
语句级快照和事务级快照终于为SQL Server的并发性能带来了突破。个人感觉语句级快照大家应该应用。事务级快照,如果是高并发系统还要慎用。如果一个用户总是被提示修改不成功要求重试时,会杀人的!
9、数据库快照
原理很简单,对要求长时间计算某一时间点的报表生成和防用户操作错误很有帮助。但是比起Oracle10g的闪回技术还是细粒度不够。可惜!
10、Mirror
Mirror可以算是SQL Server的Data guard了。但是能不能被大伙用起来就不知道了。
二、开发方面
1、Ranking函数集
其中最有名的应该是row_number了。这个终于解决了用临时表生成序列号的历史,而且SQL Server2005的row_number比Oracle的更先进。因为它把Order by集成到了一起,不用像Oracle那样还要用子查询进行封装。但是大家注意一点。如下面的例子:
select ROW_NUMBER() OVER (order by aa)
from tbl
order by bb
会先执行aa的排序,然后再进行bb的排序。
可能有的朋友会抱怨集成的order by,其实如果使用ranking函数,Order by是少不了的。如果担心Order by会影响效率,可以为order by的字段建立聚集索引,查询计划会忽略order by 操作(因为本来就是排序的嘛)。
2、top
可以动态传入参数,省却了动态SQL的拼写。
3、Apply
对递归类的树遍历很有帮助。
4、CTE
个人感觉这个真是太棒了!阅读清晰,非常有时代感。
5、try/catch
代替了原来VB式的错误判断。比Oracle高级不少。
6、pivot/unpivot
个人感觉没有case直观。而且默认的第三字段(还可能更多)作为group by字段很容易造成新手的错误。
三、DBA管理方面
1、数据库级触发器
记得在最开始使用2k的时候就要用到这个功能,可惜2k没有,现在有了作解决方案的朋友会很高兴吧。
2、多加的系统视图和实时系统信息
这些东西对DBA挑优非常有帮助,但是感觉粒度还是不太细。
3、优化器的改进
一直以来个人感觉SQL Server的优化器要比Oracle的聪明。SQL2005的更是比2k聪明了不少。(有次作试验发现有的语句在200万级时还比50万级的相同语句要快show_text的一些提示没有找到解释。一直在奇怪。)
论坛例子:
http://community.csdn.net/Expert/topic/4543/4543718.xml?temp=.405987
4、profiler的新事件观察
这一点很好的加强了profiler的功能。但是提到profiler提醒大家注意一点。windows2003要安装sp1补丁才能启动profiler。否则点击没有反应。
5、sqlcmd
习惯敲命令行的朋友可能会爽一些。但是功能有限。适合机器跑不动SQL Server Management Studio的朋友使用。
四、遗憾
1、登陆的控制
始终遗憾SQL Server的登陆无法分配CPU/内存占用等指标数。如果你的SQL Server给别人分配了一个只可以读几个表的权限,而这个家伙疯狂的死循环进行连接查询,会给你的系统带来很大的负担。而SQL Server如果能像Oracle一样可以为登陆分配如:5%的cpu,10%的内存。就可以解决这个漏洞。
2、数据库物理框架没有变动
undo和redo都放在数据库得transaction中,个人感觉是个败笔。如果说我们在设计数据库的时候考虑分多个数据库,可能能在一定程度上避免I/O效率问题。但是同样会为索引视图等应用带来麻烦。看看行级和事务级的快照数据放在tempdb中,就能感觉到目前架构的尴尬。
3、还是没有逻辑备份
备份方面可能还是一个老大难的问题。不能单独备份几个表总是感觉不爽。灵活备份的问题不知道什么时候才能解决。
4、SSIS(DTS)太复杂了
SQL Server的异构移植功能个人感觉最好了。(如果对比过SQL Server的链接服务器和Oracle的透明网关的朋友会发现SQL Server的sp_addlinkedserver(openquery)异构数据库系列比Oracle真是强太多了。)
以前的DTS轻盈简单。但是现在的SSIS虽然功能强大了很多,但是总是让人感觉太麻烦。看看论坛中询问SSIS的贴子就知道。做的功能太强大了,往往会有很多用户不会用了。
与oracle 有什么区别?
这个问题相当变态!不同点我能给他讲一天!首先名字就不一样嘛!! :)
9.DBA 的品质应该有哪些,你有哪些, 有什么欠缺的?
略
10。如果想配置SQL Mail 应该在服务器安装哪些软件!
需要哪些软件?安个outlook express就可以了。sql server提供接口存储过程,非常简单。
首先从数据库设计人员角度来看:
1、SQL Server2005之前是不支持分区表的,所以要在设计系统时考虑今后数据量大以后的数据转移问题。
2、对于树表设计来说,SQL Server由于没有start with ... connect by这样的查询方式,最好在设计表时除了ID、ParentID外,再加入TreePath字段,以避免递归循环。
3、由于SQL Server有锁升级的毛病,频繁DML的表最好减少字段数量,以减少锁升级带来的阻塞!
4、在设计数据库物理分布的时侯,由于SQL Server每个数据库都有自己的Transaction Log(其中包含Undo和Redo信息),为了减轻Transaction Log的I/O争用,可以考虑多数据库(使用聚集索引视图Clustered View的除外)。而Oracle是数据库和实例一一对应的(RAC除外),多个表空间使用公用Undo segement和redo file。
5、SQL Server的索引只有cluster index和nocluster index,而Oracle有Btree index\bitmap index\function index等。
6、SQL Server的最基本存储结构是页(8K),而Oracle最基本的是block可以根据OLTP和DSS的应用不同(后者可以选择大一点,利于查找效率),选择2K-32K不同block大小。
7、SQL Server的结构是实例->多个数据库->表、存储过程...。Oracle的是数据库=实例(RAC是多个实例对应一个数据库存储)->schema(用户)表空间 ->表、存储过程...。
1.磁盘柜上有14块73G的磁盘, 数据库为200G 大小包括日志文件,如何设置磁盘(要说明这14磁盘是怎么用的)?
答:可以做成
a. 磁盘比较充裕,做RAID10 ,就是14块硬盘分一半,2个7块做Raid0,容量:7*73G=511G,然后把它们组成Raid1,最后容量(14/2)*73G=511G. RAID10 优点,数据一次需要写入两个区块,读的时候可以从任意一个比较快的地方读取,效率很高,缺点成本较高。
b.Raid5, 13块硬盘做Raid5,1块做热冗余; 容量: (14-2)*73G=876G, Raid5优点,稳定系数高,性价比高。
c.Raid51,7块硬盘做Raid5,另7块也做Raid5,再把这2个Raid5做成Raid1,容量: (14/2-1)*73G=438G,优点:比RAID10更稳定,效率和RAID10相当.
2.有两服务器群集,分别为node1和node2 现在要打win200系统补丁,打完后,要重新启动,如何打补丁,不能影响用户使用(要用群集的术语详细说明)。
答:
a.假设node1联机并控制资源,那么先给node2 先打补丁,重起node2,这时联机并控制资源情况不会改变,不影响客户服务.
b.等node2 重起补丁完毕,手工把node1的服务和资源切换到node2,使node2处于联机状态,然后给node1打补丁,重起补丁完毕,再把node2的服务和资源切换后node1正常运作.
sql server面试题
转载于:https://www.cnblogs.com/itelite/articles/1047337.html
相关文章:

利用BP神经网络教计算机识别语音特征信号(代码部分SSR)
本图文已经更新,详细地址如下: http://blog.csdn.net/lsgo_myp/article/details/54094884

JDBC使用步骤
JDBC编程步骤: 一、注冊载入JDBC驱动程序; 注冊载入驱动driver。也就是强制类载入:其注冊载入JDBC驱动有三种方法: 方法一:Class.forName(DriverName); 当中DriverNameDriver包名。Driver类名;…
在mac下搭建java开发环境
刚刚从windows系统转到使用mac系统,感觉不是特别熟悉,需要一定的适应时间。下面简单介绍一下mac下搭建基本的java开发环境。 1.安装jdk 安装jdk1.7后,发现不需要进行环境变量配置,直接在terminal中就能使用java和javac命令了。j…

IT项目管理入门知识
转载于:https://www.cnblogs.com/sophia194910/p/6854462.html

什么是BP神经网络?
BP人工神经网络原理
mac下的intellij idea常用快捷键
最近用mac进行开发,纪录下mac下的intellij idea的快捷键,方便以后查询。 command点到具体方法 查看调用 commandN查找类 commandshiftN查找文件 commandR替换 commandY 删除行 commandX剪切删除行 commandw 用光标圈起代码 commandD复制一行 com…

struct和union的大小问题
union类型以其中size最大的为其大小struct类型以其中所有size大小之和为其大小 #include<iostream>usingnamespacestd;intmain(){ typedef union {long i; int k[5]; char c;} DATE; struct data { int cat; DATE cow; double dog;} too; DATE max; cout<…

利用BP神经网络教计算机识别语音特征信号(代码部分SL)
本图文已经更新,详细地址如下: http://blog.csdn.net/lsgo_myp/article/details/54094884
Redis相关命令
一、命令示例 1. KEYS/RENAME/DEL/EXISTS/MOVE/RENAMENX: #在Shell命令行下启动Redis客户端工具。/> redis-cli#清空当前选择的数据库,以便于对后面示例的理解。redis 127.0.0.1:6379> flushdbOK#添加String类型的模拟数据。redis 127.0.0.1:6379> set myk…
手把手 | 教你爬下100部电影数据:R语言网页爬取入门指南
前言 网页上的数据和信息正在呈指数级增长。如今我们都使用谷歌作为知识的首要来源——无论是寻找对某地的评论还是了解新的术语。所有这些信息都已经可以从网上轻而易举地获得。 网络中可用数据的增多为数据科学家开辟了可能性的新天地。我非常相信网页爬取是任何一个数据科学…
如何在OSCOMMERCE中安装中文语言包
步骤如下: 下载中文语言包,可以从以下连结下载 http://www.oscommerce.com/community/contributions,1054 安装步骤如下: (演示地址:http://www.MedOnclick.com) 1. 打开你下载的包含本语言包的压缩文件(cosc-v0.3.zip)。 2. 将…

利用BP神经网络教计算机识别语音特征信号(代码部分SLR)
本图文已经更新,详细地址如下: http://blog.csdn.net/lsgo_myp/article/details/54094884
Intellij Idea 生成serialVersionUID的方法
默认情况下Intellij IDEA是关闭了继承了java.io.Serializable的类生成serialVersionUID的警告。如果需要ide提示生成serialVersionUID,那么需要做以下设置: 1、setting->Inspections->Serialization issues,将serialzable class withou…
小牛生产小牛的问题解决集粹
问题:一只刚出生的小牛,4年后生一只小牛,以后每年生一只。现有一只刚出生的小牛,问N年后共有牛多少只?1.原始笨方法privateintComput(intyears) { //初始化为1头牛 int count 1; …
构建基于Chromium的应用程序(Winform程序加载Html页面)
chromium是google chrome浏览器所采用的内核,最开始由苹果的webkit发展而出,由于webkit在发展上存在分歧,而google希望在开发上有更大的自由度,2013年google决定自己开发webcore的分支,叫做Blink引擎,而后g…
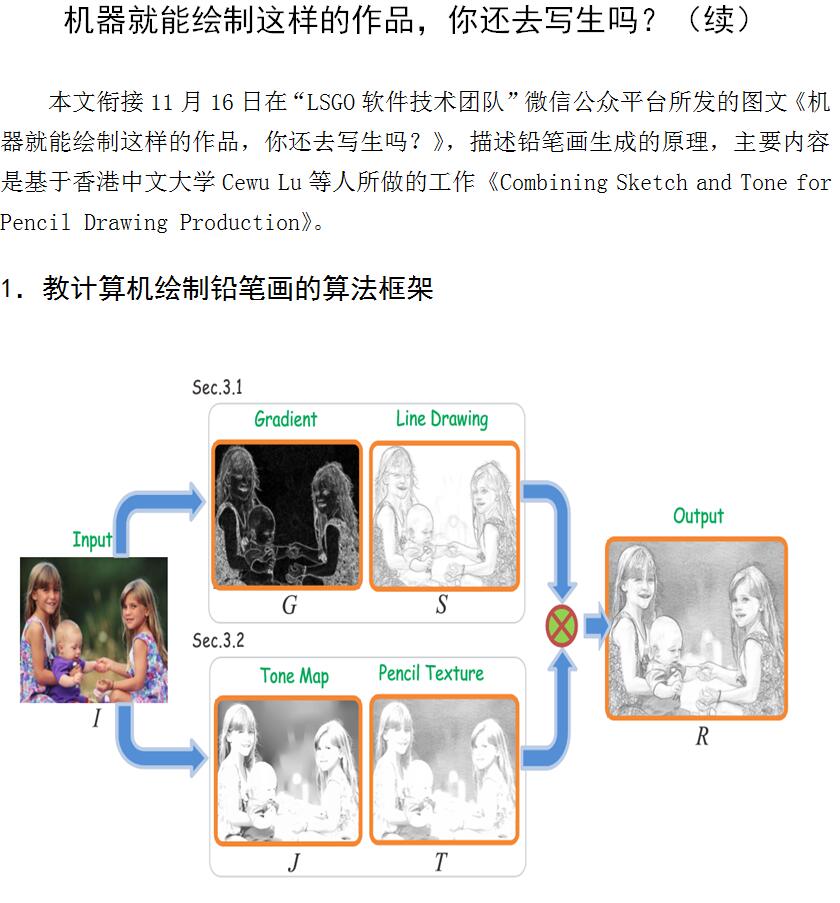
机器就能绘制这样的作品,你还去写生吗?(续)
本文介绍了利用程序让计算机把输入图像呈现铅笔素描画和彩绘画效果的算法原理。
Apache工具类ToStringBuilder用法简介
ToStringBuilder比较适合在打日志时,输出参数的信息,特别是在参数为对象时,该工具类能够很方便的自动打印对象中的属性值。 package test; /** * * author zhengtian * time 2012-6-28 */ public class User { privat…
自然语言处理:汉语分词
NLPIR/ICTCLAS 汉语分词系统(http://ictclas.nlpir.org)PyNLPIR 是该汉语分词系统的 python 封装版(http://pynlpir.readthedocs.io...) 安装步骤:① pip install pynlpir② pynlpir update 官方文档的汉语分词示例&am…
再也不买仙剑正版盘了
奶奶的,好不容易心血来潮买了一回,windows 2003安装上蓝屏,在xp虚拟机上装报错,狗日的大宇,以后专门玩盗版气它 转载于:https://www.cnblogs.com/charie/archive/2008/02/21/1076772.html

利用BP神经网络教计算机进行非线函数拟合(代码部分单层)
单层BP神经网络 本图文已经更新,详细地址如下: http://blog.csdn.net/lsgo_myp/article/details/54425751
ps aux|grep
ps a 显示现行终端机下的所有程序,包括其他用户的程序。 2)ps -A 显示所有程序。 3)ps c 列出程序时,显示每个程序真正的指令名称,而不包含路径,参数或常驻服务的标示。 4)ps -e 此参数的效果…

排序(一)归并、快排、优先队列等(图文具体解释)
排序(一) 0基础排序算法 选择排序 思想:首先,找到数组中最小的那个元素。其次,将它和数组的第一个元素交换位置。再次。在剩下的元素中找到最小的元素。将它与数组的第二个元素交换位置。如此往复,直到将整个数组排序。 【图例】 …

利用BP神经网络教计算机进行非线函数拟合(代码部分多层)
利用BP神经网络教计算机进行非线函数拟合(代码部分多层) 本图文已经更新,详细地址如下: http://blog.csdn.net/lsgo_myp/article/details/54425751
年年英雄会,岁岁侠客行
虽然今年工作比较忙,但还是坚持参加了CSDN组织的英雄会第二届。如去年所约,CSDN在持续发展着,而英雄会这一中国独特的程序员式的聚会,胜利地举办了第二届。 虽然不能成为MVB,但还是感谢CSDN记得发给我邀请。这份情意还…
Velocity判断空的方法
Velocity中没有null,那么怎么判断null呢 1、在velocity中,非null被认为是真的,所以,可以如下用: #if($!变量名)// 变量不为空的代码 #else// 变量为空的代码 #end
js对Dom操作
<div id"myWebPanelForm"style"width:400;height:200;display:none"><div id"WebPanel_Body"style"width:400;height:200;display:none">测试</div></div><script type"text/javascript">win…
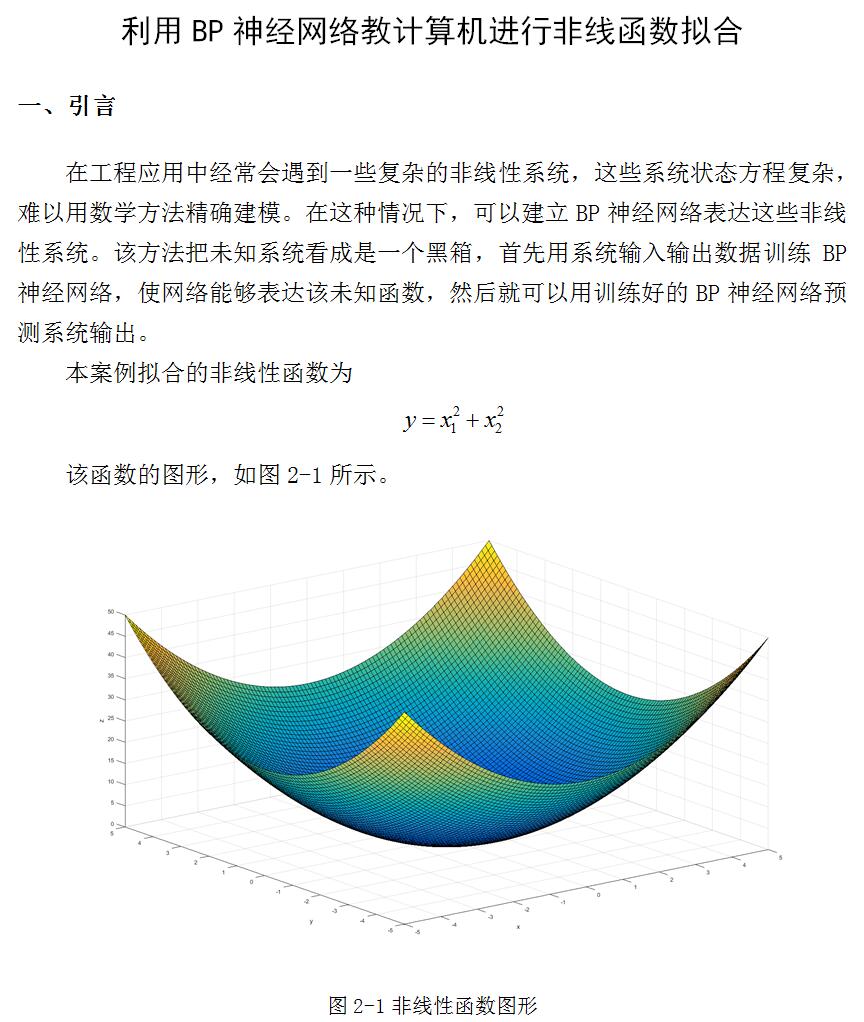
利用BP神经网络教计算机进行非线函数拟合
利用BP神经网络教计算机进行非线函数拟合 本图文已经更新,详细地址如下: http://blog.csdn.net/lsgo_myp/article/details/54425751

phpstorm failed to create jvm:error code -6 解决办法 解决方法
phpStorm 软件打开运行提示 failed to create JVM的解决办法。 修改文件 D:\Program Files (x86)\JetBrains\PhpStorm 7.1.3\bin\PhpStorm.exe.vmoptions 把内存值改成标准值,文件全部内容如下: [plain] view plaincopy -server -Xms128m -Xmx512m -X…

maven jar包冲突常见报错及解决方法
见到如下错误,可以想到是不是jar包冲突 1.java.lang.NoSuchMethodError2.java.lang.ClassNotFoundException3.java.lang.NoClassDefFoundError解决办法 以一个错误为例:解决方法:1.首先定位到具体类。查到org.apache.httpHost对应的maven依赖…

[轉]如果把HTML當成飾品....
轉自:http://blog.onlyone.idv.tw/997.htm [轉]如果把HTML當成飾品.... 如果有一天,有個人把HTML做成耳環掛在耳朵上,那麼… 不過,在國外,就真的有人把這玩意拿出來賣了! 在該購物網站的商品說明,還很KUSO這…