zookeeper集群部署以及zookeeper原理
简介
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
ZooKeeper包含一个简单的原语集,提供Java和C的接口。
ZooKeeper代码版本中,提供了分布式独享锁、选举、队列的接口,代码在$zookeeper_home\src\recipes。其中分布锁和队列有Java和C两个版本,选举只有Java版本。
工作原理
ZooKeeper是以Fast Paxos算法为基础的,Paxos 算法存在活锁的问题,即当有多个proposer交错提交时,有可能互相排斥导致没有一个proposer能提交成功,而Fast Paxos做了一些优化,通过选举产生一个leader (领导者),只有leader才能提交proposer,具体算法可见Fast Paxos。因此,要想弄懂ZooKeeper首先得对Fast Paxos有所了解。
ZooKeeper的基本运转流程:
1、选举Leader。
2、同步数据。
3、选举Leader过程中算法有很多,但要达到的选举标准是一致的。
4、Leader要具有最高的执行ID,类似root权限。
5、集群中大多数的机器得到响应并接受选出的Leader。
特性
在Zookeeper中,znode是一个跟Unix文件系统路径相似的节点,可以往这个节点存储或获取数据。如果在创建znode时Flag设置为EPHEMERAL,那么当创建这个znode的节点和Zookeeper失去连接后,这个znode将不再存在在Zookeeper里,Zookeeper使用Watcher察觉事件信息。当客户端接收到事件信息,比如连接超时、节点数据改变、子节点改变,可以调用相应的行为来处理数据。Zookeeper的Wiki页面展示了如何使用Zookeeper来处理事件通知,队列,优先队列,锁,共享锁,可撤销的共享锁,两阶段提交。
那么Zookeeper能做什么事情呢,简单的例子:假设我们有20个搜索引擎的服务器(每个负责总索引中的一部分的搜索任务)和一个总服务器(负责向这20个搜索引擎的服务器发出搜索请求并合并结果集),一个备用的总服务器(负责当总服务器宕机时替换总服务器),一个web的cgi(向总服务器发出搜索请求)。搜索引擎的服务器中的15个服务器提供搜索服务,5个服务器正在生成索引。这20个搜索引擎的服务器经常要让正在提供搜索服务的服务器停止提供服务开始生成索引,或生成索引的服务器已经把索引生成完成可以提供搜索服务了。使用Zookeeper可以保证总服务器自动感知有多少提供搜索引擎的服务器并向这些服务器发出搜索请求,当总服务器宕机时自动启用备用的总服务器。
官网地址
准备
节点准备
三个节点
- IP(192.168.0.101) 端口(2181/2881/3881)
- IP(192.168.0.102) 端口(2181/2881/3881)
- IP(192.168.0.103) 端口(2181/2881/3881)
环境准备
JAVA
将jdk-8u141-linux-x64.tar.gz上传到三台服务器安装配置。
解压到/data/program/software/
并将文件夹重命名为java8
配置jdk全局变量。
#vi /etc/profile
export JAVA_HOME=/data/program/software/java8
export JRE_HOME=/data/program/software/java8/jre
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
主机映射
修改操作系统的/etc/hosts文件,添加IP与主机名映射:
#zookeeper cluster servers
192.168.0.101 bigdata1
192.168.0.102 bigdata2
192.168.0.103 bigdata3
下载zookeeper-3.4.9.tar.gz 到/data/program/software/目录
# pan.baidu.com/s/1TIscICrzaBHj7fTA01apMA?pwd=n1om
部署
解压zookeeper安装包,并对节点重民名
#tar -zxvf zookeeper-3.4.9.tar.gz
服务器1:
#mv zookeeper-3.4.9 zookeeper
服务器2:
#mv zookeeper-3.4.9 zookeeper
服务器3:
#mv zookeeper-3.4.9 zookeeper
2.5 在zookeeper的各个节点下 创建数据和日志目录
#cd zookeeper
#mkdir data
#mkdir logs
2.6 重命名配置文件
将zookeeper/conf目录下的zoo_sample.cfg文件拷贝一份,命名为zoo.cfg:
#cp zoo_sample.cfg zoo.cfg
修改zoo.cfg 配置文件
clientPort=2181
dataDir=/data/program/software/zookeeper/data
dataLogDir=/data/program/software/zookeeper/logs
server.1=bigdata1:2881:3881
server.2=bigdata2:2881:3881
server.3=bigdata3:2881:3881
参数说明:
tickTime=2000
tickTime这个时间是作为Zookeeper服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个tickTime时间就会发送一个心跳。
initLimit=10
initLimit这个配置项是用来配置Zookeeper接受客户端(这里所说的客户端不是用户连接Zookeeper服务器的客户端,而是Zookeeper服务器集群中连接到Leader的Follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数。当已经超过10个心跳的时间(也就是tickTime)长度后Zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。总的时间长度就是10*2000=20 秒。
syncLimit=5
syncLimit这个配置项标识Leader与Follower之间发送消息,请求和应答时间长度,最长不能超过多少个tickTime的时间长度,总的时间长度就是5*2000=10秒。
dataDir=/data/program/software/zookeeper/data
dataDir顾名思义就是Zookeeper保存数据的目录,默认情况下Zookeeper将写数据的日志文件也保存在这个目录里。
clientPort=2181
clientPort这个端口就是客户端(应用程序)连接Zookeeper服务器的端口,Zookeeper会监听这个端口接受客户端的访问请求。
server.A=B:C:D
server.1=bigdata1:2881:3881
server.2=bigdata2:2881:3881
server.3=bigdata3:2881:3881
A是一个数字,表示这个是第几号服务器;
B是这个服务器的IP地址(或者是与IP地址做了映射的主机名);
C第一个端口用来集群成员的信息交换,表示这个服务器与集群中的Leader服务器交换信息的端口;
D是在leader挂掉时专门用来进行选举leader所用的端口。
注意:如果是伪集群的配置方式,不同的 Zookeeper 实例通信端口号不能一样,所以要给它们分配不同的端口号。
2.8 创建myid文件
在dataDir= dataDir=/data/program/software/zookeeper/data 下创建myid文件
编辑myid文件,并在对应的IP的机器上输入对应的编号。如在1上,myid文件内容就是1, 2上就是2, 3上就是3:
#vi /myid## 值为1
#vi /myid## 值为2
#vi /myid## 值为3
2.9 启动测试zookeeper
(1)进入/bin目录下执行:
~~~shell
# /zkServer.sh start
# /zkServer.sh start
# /zkServer.sh start

(2)输入jps命令查看进程:

其中,QuorumPeerMain是zookeeper进程,说明启动正常
(3)查看状态:
# /zkServer.sh status

(4)查看zookeeper服务输出信息:
由于服务信息输出文件在/bin/zookeeper.out
$ tail -500 f zookeeper.out
相关文章:

SpringCloud Alibaba集成 Gateway(自定义负载均衡器)、Nacos(配置中心、注册中心)、Loadbalancer
要为未被某些网关路由谓词处理的请求提供相同的CORS配置,请将属性spring.cloud.gateway.globalcors.add-to-simple-url-handler-mapping设置为true。断言(Predicate):Java8中的断言函数,Spring Cloud Gateway中的断言函数输入类型是 Spring5.0框架中的ServerWebExchange。对于所有GET请求的路径,来自docs.spring.io的请求都将允许CORS请求。
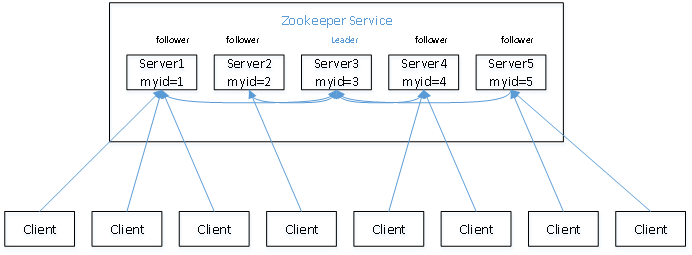
Zookeeper概要、协议、应用场景
Zoopkeeper提供了一套很好的分布式集群管理的机制,就是它这种基于层次型的目录树的数据结构并对树中的节点进行有效管理,从而可以设计出多种多样的分布式的数据管理模型,作为分布式系统的沟通调度桥梁。

SSO 单点登录和 OAuth2.0 有何区别?
此方法的缺点是它依赖于浏览器和会话状态,对于分布式或者微服务系统而言,可能需要在服务端做会话共享,但是服务端会话共享效率比较低,这不是一个好的方案。在单点登录的上下文中,OAuth 可以用作一个中介,用户在一个“授权服务器”上登录,并获得一个访问令牌,该令牌可以用于访问其他“资源服务器”上的资源。首先,SSO 主要关注用户在多个应用程序和服务之间的无缝切换和保持登录状态的问题。这种方法通过将登录认证和业务系统分离,使用独立的登录中心,实现了在登录中心登录后,所有相关的业务系统都能免登录访问资源。
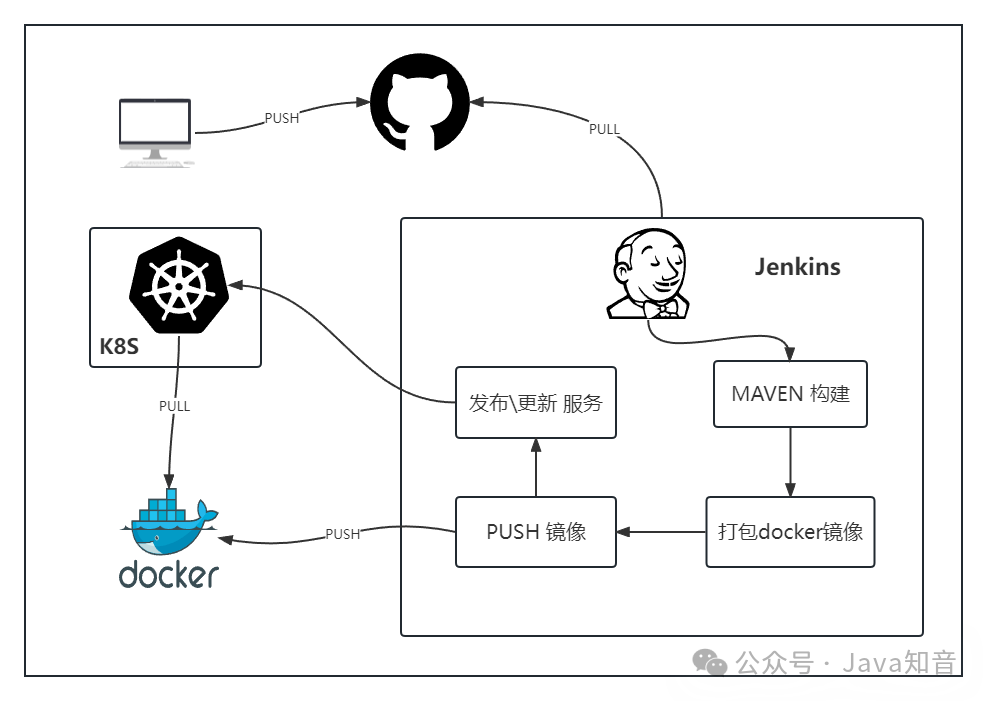
一键部署 SpringCloud 微服务,这套流程值得学习一波儿!
一键部署 springcloud 微服务,需要用到 Jenkins K8S Docker等工具。本文使用jenkins部署,流程如下图开发者将代码push到git运维人员通过jenkins部署,自动到git上pull代码通过maven构建代码将maven构建后的jar打包成docker镜像 并 push docker镜像到docker registry通过k8s发起 发布/更新 服务 操作其中 2~5步骤都会在jenkins中进行操作。
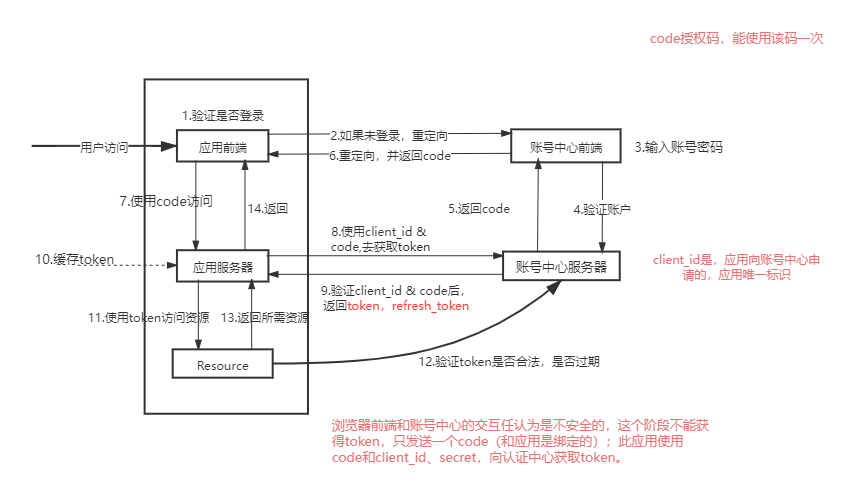
Springboot + oauth2 单点登录 - 原理篇
OAuth 协议为用户资源的授权提供了一个安全的、开放而又简易的标准,允许用户授权第三方移动应用访问他们存储在另外的服务提供者上的信息,而不需要将用户名和密码提供给第三方移动应用或分享他们数据的所有内容,OAuth2.0是OAuth协议的延续版本,但不向后兼容OAuth 1.0即完全废止了OAuth1.0。授权码模式(authorization code)密码模式(resource owner password credentials)客户端模式(client credentials) 不常用。
JAVA 中 13 种锁的实现方式
分布式系统时代,线程并发,资源抢占,慢慢变得很重要。那么常见的锁都有哪些?
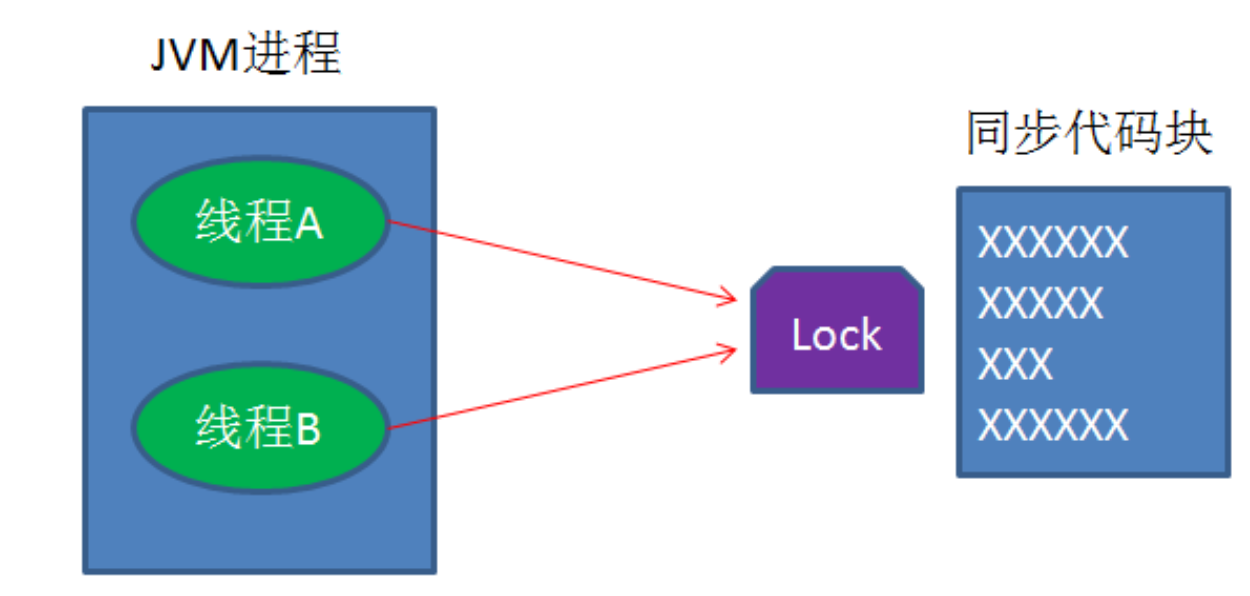
三种方式实现分布式锁
通过以上过程你可以发现锁的获取是按照创建时间来的,谁先来争取锁谁就先获得锁,因此它实现的是公平锁。答案是不能,以Synchronized关键字为例,Synchronized关键字无论是在偏向锁、轻量级锁还是重量级锁状态都不能实现这点,如重量级锁,重量级锁是靠系统底层的互斥量Mutex实现的,也就是说每个节点(服务器)所使用的互斥量是分开的,节点A的互斥量是无法锁住节点B的线程访问临界区,因此Synchronized关键字只能保证单服务器内的JVM进程的不同线程同步,是不能用做分布式环境中来保证线程同步。
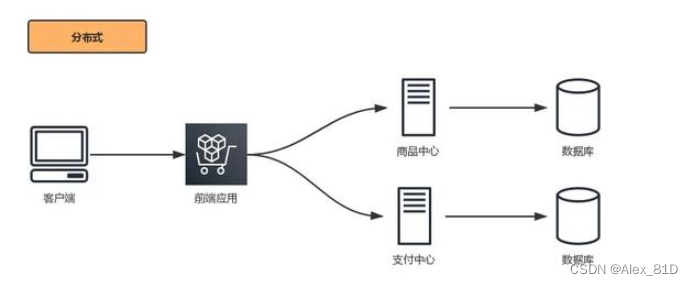
浅谈Java分布式与集群
在日常操作中,相信很多人在怎么理解Java分布式与集群问题上存在疑惑,今天就大概说说,不注意听,觉得两个可能是同一个东西,其实这个是两个概念。一句话概括:分布式是以缩短单个任务的执行时间来提升效率的,而集群则是通过提高单位时间内执行的任务数来提升效率。
java面试题:分布式和微服务的区别
分布式架构解决的是如何将一个大的系统划分为多个业务模块这些业务模块会分别部署到不同的机器上,通过接口进行数据交互的问题。微服务是指很小的服务,可以小到只完成一个功能,这个服务可以单独部署运行,不同服务之间通过rpc调用。分布式架构是将一个大的系统划分为多个业务模块,这些业务模块会分别部署到不同的机器上,通过接口进行数据交互。微服务架构是架构设计方式,是设计层面的东西,一般考虑如何将系统从逻辑上进行拆分,也就是垂直拆分。分布式系统是部署层面的东西,即强调物理层面的组成,即系统的各子系统部署在不同计算机上。

k8s搭建部署(超详细)
Kubernetes是Google 2014年创建管理的,是Google 10多年大规模容器管理技术Borg的开源版本。它是容器集群管理系统,是一个开源的平台,可以实现容器集群的自动化部署、自动扩缩容、维护等功能。快速部署应用快速扩展应用无缝对接新的应用功能节省资源,优化硬件资源的使用可移植: 支持公有云,私有云,混合云,多重云(multi-cloud)可扩展: 模块化, 插件化, 可挂载, 可组合自动化: 自动部署,自动重启,自动复制,自动伸缩/扩展。
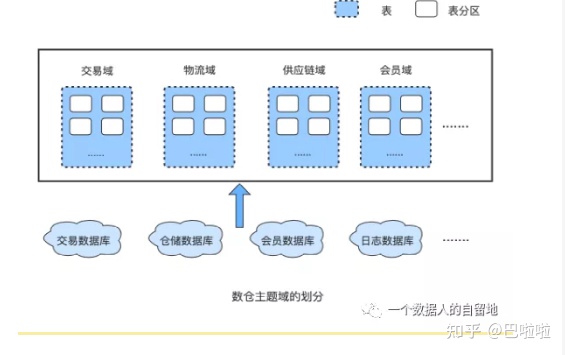
什么是数据中台?
说完了数据中台诞生的历史背景,现在,我们应该对数据中台有了一定的了解,那我们现在给数据中台下个定义。自2016年,数据中台被提出以来,不同的人对数据中台有不同的理解,就像一千个读者心中有一千个哈姆雷特,因此也有许多不同的定义,以下是我从一些文章、书籍中搜集到的关于数据中台的定义:数据中台是DT时代的大背景下,为实现数据快(快速)、准(准确)、省(低成本)赋能业务发展的目标,将企业的数据统一整合起来,基于Onedata方法论借助大数据平台完成数据的统一加工处理,对外提供数据服务的一套机制。
弹性搜索引擎Elasticsearch:本地部署与远程访问指南
本文主要讲解如何使用Elasticsearch分布式搜索分析引擎本地部署与远程访问。

分布式系统架构设计之分布式数据存储的备份恢复和监控故障排查
架构师通过设计和实施数据备份和恢复策略,可以最大程度地保障分布式系统在面对数据损失、硬件故障、灾难性事件等情况下的稳定性和可用性。在分布式数据存储中,数据备份和恢复是保障数据存储系统可靠性和容灾性的重要组成部分。通过合理的监控和故障排查策略,可以确保分布式数据存储系统在运行过程中保持高可用性、高性能,并且能够及时应对潜在的故障情况。在分布式系统中,对数据存储进行有效的监控和出现问题后故障排查策略是确保系统稳定性和性能可靠性的关键。

【微服务】springboot整合skywalking使用详解
springboot整合skywalking
光伏发电模式中,分布式和集中式哪种更受欢迎?
5.可实现远距离输送,集中式光伏电站发出的电经高压并网,将电一层层的输送到更高的电压等级,如将高压电输送到华东等地区,以实现西电东输。分布式光伏发电:一般建在楼顶、屋顶、厂房等地方,较多的是基于建筑物表面,就近解决用户的用电问题,通过并网实现供电差额的补偿与外送。1.光伏电源处于用户侧,自发自用,就近发电,就近用电,发电供给当地负荷,视作负载,可以减少对电网供电的依赖,减少线路损耗。4.分布式光伏一般就近并网,线路的损耗很低或者可以说没有,可非常方便的补充当地的电量,供当地及附近的用电用户使用。

Elasticsearch分布式搜索分析引擎本地部署与远程访问
本文主要讲解如何使用Elasticsearch分布式搜索分析引擎本地部署与远程访问

Gitlab基础篇: Gitlab docker 安装部署、Gitlab 设置账号密码
安装docker gitlab前确保docker环境,如果没有搭建docker请查阅“Linux docker 安装文档”可以看到在docker ps -a 打印中看到 容器ID ps 展示的容器ID只时原来的一部分。修改docker镜像的gitlab容器端口前需要把gitlab容器以及docker镜像关闭。通过容器ID就能找到containers下具体哪一个是gitlab容器的配置。修改config.v2.json、hostconfig.json文件。docker 下载 gitlab容器。

docker搭建maven私库Nexus3
阿里代理地址:http://maven.aliyun.com/nexus/content/groups/public/由于nexus的默认端口为8081,我们在启动的时候改为18091后需要修改nexus的配置文件。这样就可以在本地浏览器进入nexus页面了,地址为 服务器ip:18091。右上角登录用户名为admin,密码为之前查看的密码。配置maven-central的代理地址。删除nuget开头的仓库。同时查看admin密码。
Nginx基础篇:Nginx搭建、Nginx反向代理、文件服务器部署配置。
Nginx (engine x) 是一个高性能的HTTP和反向代理web服务器,同时也提供了IMAP/POP3/SMTP服务。Nginx是由伊戈尔·赛索耶夫为俄罗斯访问量第二的Rambler.ru站点(俄文:Рамблер)开发的,公开版本1.19.6发布于2020年12月15日。其将源代码以类BSD许可证的形式发布,因它的稳定性、丰富的功能集、简单的配置文件和低系统资源的消耗而闻名。2022年01月25日,nginx 1.21.6发布。

分布式事务有哪些解决方案?
分布式事务是分布式系统中非常重要的一部分,最典型的例子是银行转账和扣款,A 和 B 的账户信息在不同的服务器上,A 给 B 转账 100 元,要完成这个操作,需要两个步骤,从 A 的账户上扣款,以及在 B 的账户上增加金额,两个步骤必须全部执行成功;否则如果有一个失败,那么另一个操作也不能执行。分布式事务的经典应用比如转账扣款,下订单扣库存,新会员送积分等等涉及多个业务共同参与在一个请求中。
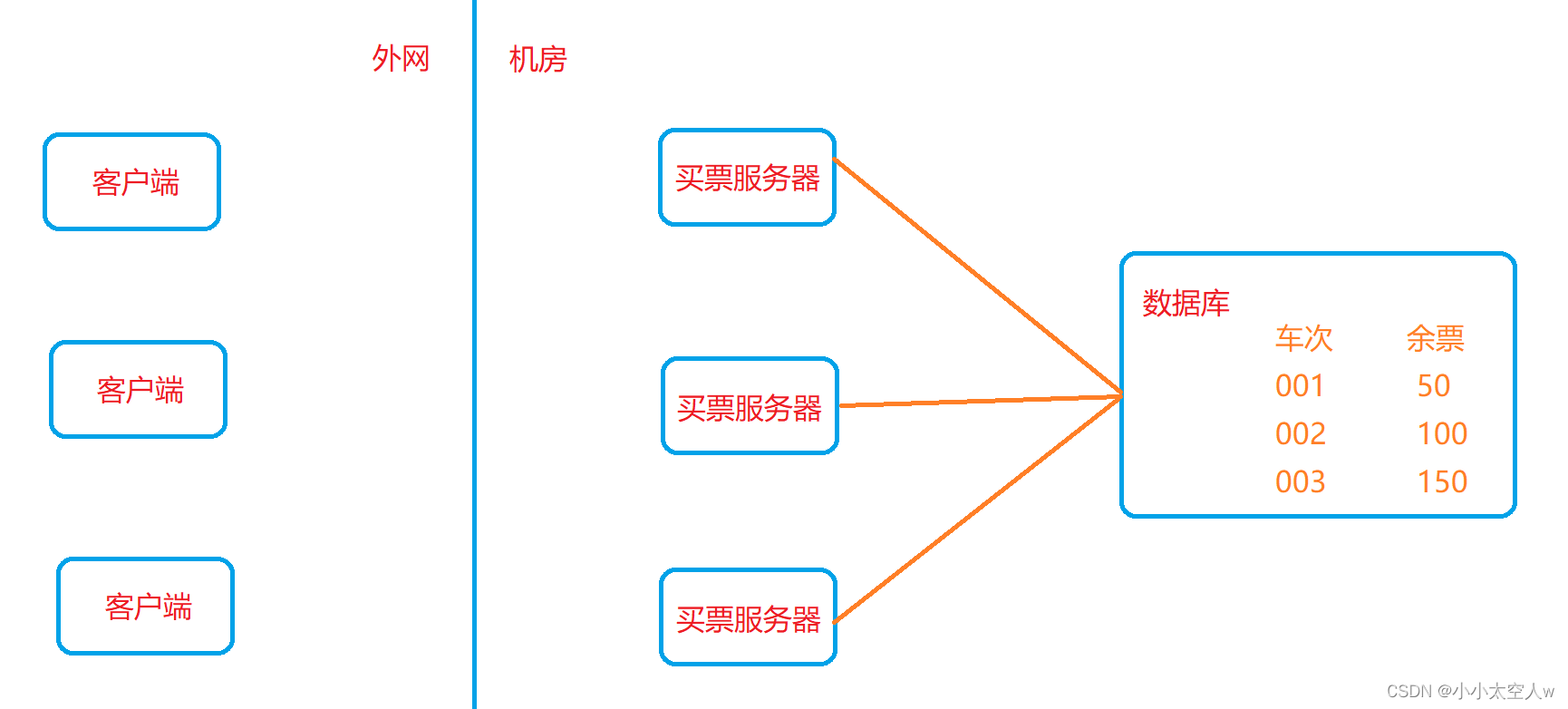
什么是分布式锁?Redis实现分布式锁详解
文章浏览阅读151次,点赞4次,收藏3次。在分布式系统中,涉及多个主机访问同一块资源,此时就需要锁来做互斥控制,避免出现类似线程安全问题。而Java中的synchronized只是对当前进程中的线程有效,多个主机实际上是多个进程,那么它就无能为力了,此时就需要分布式锁。
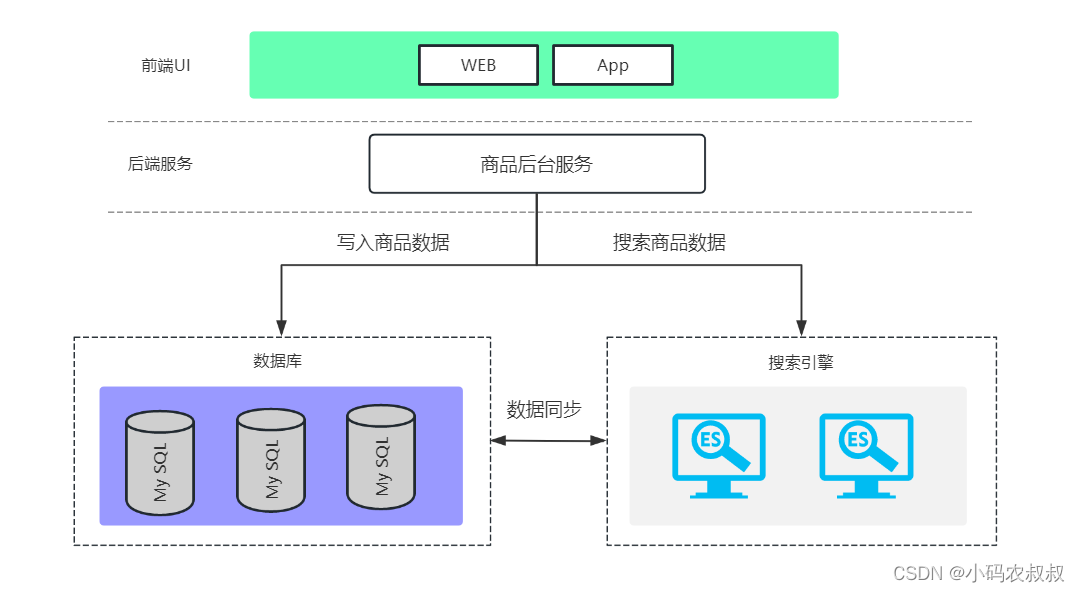
【微服务】mysql + elasticsearch数据双写设计与实现
在很多电商网站中,对商品的搜索要求很高,主要体现在页面快速响应搜索结果。这就对服务端接口响应速度提出了很高的要求。