技术图文:浅析 C# Dictionary实现原理
背景
对于 C# 中的 Dictionary类 相信大家都不陌生,这是一个 Collection(集合) 类型,可以通过 Key/Value (键值对) 的形式来存放数据;该类最大的优点就是它查找元素的时间复杂度接近 O(1),实际项目中常被用来做一些数据的本地缓存,提升整体效率。
那么是什么样的设计能使得 Dictionary类 能实现 O(1) 的时间复杂度呢?那就是本篇文章想和大家讨论的东西;这些都是个人的一些理解和观点,如有表述不清楚、错误之处,请大家批评指正,共同进步。
理论知识
对于 Dictionary 的实现原理,其中有两个关键的算法,一个是 Hash 算法,一个是用于应对 Hash 碰撞冲突解决算法。
1、Hash算法
Hash 算法是一种数字摘要算法,它能将不定长度的二进制数据集给映射到一个较短的二进制长度数据集,常见的 MD5 算法就是一种 Hash 算法,通过 MD5 算法可对任何数据生成数字摘要。而实现了 Hash 算法的函数叫做 Hash 函数。Hash 函数有以下几点特征。
- 相同的数据进行 Hash 运算,得到的结果一定相同。
HashFunc(key1) == HashFunc(key1)。- 不同的数据进行 Hash 运算,其结果也可能会相同,(Hash 会产生碰撞)。
key1 != key2 => HashFunc(key1) == HashFunc(key2)。- Hash 运算是不可逆的,不能由 hashCode 获取原始的数据。
key1 => hashCode但是hashCode =\=> key1。
下图就是 Hash 函数的一个简单说明,任意长度的数据通过 HashFunc 映射到一个较短的数据集中。
关于 Hash 碰撞下图很清晰的就解释了,可从图中得知 Sandra Dee 和 John Smith 通过 hash 运算后都落到了02 的位置,产生了碰撞和冲突。
2、Hash桶算法
说到 Hash 算法大家就会想到 Hash 表,一个 Key 通过 Hash 函数运算后可快速的得到 hashCode,通过 hashCode 的映射可直接 Get 到 Value,但是 hashCode 一般取值都是非常大的,经常是 2^32 以上,不可能对每个 hashCode 都指定一个映射。
因为这样的一个问题,所以人们就将生成的 HashCode 以分段的形式来映射,把每一段称之为一个 Bucket(桶),一般常见的 Hash 桶就是直接对结果取余。
假设将生成的 hashCode 可能取值有2^32个,然后将其切分成一段一段,使用8个桶来映射,那么就可以通过 bucketIndex = HashFunc(key1) % 8 这样一个算法来确定这个 hashCode 映射到具体的哪个桶中。
大家可以看出来,通过 hash 桶这种形式来进行映射,所以会加剧 hash 的冲突。
3、解决冲突算法
对于一个 hash 算法,不可避免的会产生冲突,那么产生冲突以后如何处理,是一个很关键的地方,目前常见的冲突解决算法为拉链法(Dictionary实现采用)。
拉链法:这种方法的思路是将产生冲突的元素建立一个单链表,并将头指针地址存储至 hash 表对应桶的位置。这样定位到 hash 表桶的位置后可通过遍历单链表的形式来查找元素。
对于拉链法有一张图来描述,通过在冲突位置建立单链表,来解决冲突。
hashCode 的作用:查找的快捷性。
比如我们有一个能存放 1000 个数的内存,在其中要存放 1000 个不一样的数字,用最笨的方法,就是存一个数字,就遍历一遍,看有没有相同的数,当存了 900 个数字,开始存 901 个数字的时候,就需要跟 900 个数字进行对比,这样就很麻烦,很是消耗时间。
可以用 hashcode 来记录对象的位置。hash 表中有 1、2、3、4、5、6、7、8 个位置,存第一个数,hashcode 为 1,该数就放在 hash 表中 1 的位置,存到 100 个数字,hash 表中 8 个位置会有很多数字了,1 中可能有 20 个数字,存 101 个数字时,先查 hashcode 值对应的位置,假设为 1,那么就有 20 个数字和它的 hashcode 相同,它只需要跟这 20 个数字相比较(equals),如果没有一个相同,那么就放在1这个位置,这样比较的次数就少了很多,实际上hash 表中有很多位置,这里只是举例只有 8 个,所以比较的次数会让你觉得也挺多的,实际上,如果hash表很大,那么比较的次数就很少很少了。
Dictionary实现
Dictionary 实现我们主要对照源码来解析,目前对照源码的版本是 .Net Framwork 4.7。
源码地址:
https://referencesource.microsoft.com/#mscorlib/system/collections/generic/dictionary.cs,d3599058f8d79be0
1. Entry 结构体
首先我们引入 Entry 这样一个结构体,它的定义如下代码所示。这是 Dictionary 中存放数据的最小单位,调用 Add(Key,Value) 方法添加的元素都会被封装在这样的一个结构体中。
private struct Entry {public int hashCode; // 除符号位以外的31位hashCode值, 如果该Entry没有被使用,那么为-1public int next; // 下一个元素的下标索引,如果没有下一个就为-1public TKey key; // 存放元素的键public TValue value; // 存放元素的值
}
2. 其它关键私有变量
除了Entry结构体外,还有几个关键的私有变量,其定义和解释如下代码所示。
private int[] buckets; // Hash桶
private Entry[] entries; // Entry数组,存放元素
private int count; // 当前entries的index位置
private int version; // 当前版本,防止迭代过程中集合被更改
private int freeList; // 被删除Entry在entries中的下标index,这个位置是空闲的
private int freeCount; // 有多少个被删除的Entry,有多少个空闲的位置
private IEqualityComparer<TKey> comparer; // 比较器
private KeyCollection keys; // 存放Key的集合
private ValueCollection values; // 存放Value的集合
上面代码中,需要注意的是 buckets、entries 这两个数组,这是实现 Dictionary 的关键。
3. Dictionary - Add 操作
首先我们用图的形式来描述一个 Dictionary 的数据结构,其中只画出了关键的地方。桶大小为 4 以及 Entry 大小也为 4 的一个数据结构。
然后我们假设需要执行一个Add操作,dictionary.Add("a","b"),其中key = "a",value = "b"。
- 根据 key 的值,计算出它的 hashCode。我们假设 “a” 的 hash 值为 6(GetHashCode(“a”) = 6)。
- 通过对 hashCode 取余运算,计算出该 hashCode 落在哪一个 buckets 桶中。现在桶的长度(buckets.Length)为4,那么就是 6 % 4 最后落在 index 为 2 的桶中,也就是 buckets[2]。
- 避开一种其它情况不谈,接下来它会将 hashCode、key、value 等信息存入 entries[count] 中,因为 count 位置是空闲的;继续 count++ 指向下一个空闲位置。上图中第一个位置,index = 0 就是空闲的,所以就存放在 entries[0] 的位置。
- 将 Entry 的下标 entryIndex 赋值给 buckets 中对应下标的 bucket。步骤3中是存放在 entries[0] 的位置,所以 buckets[2]=0。
- 最后 version++,集合发生了变化,所以版本需要 +1。只有增加、替换和删除元素才会更新版本。
上文中的步骤 1~5 只是方便大家理解,实际上有一些偏差,后文再谈 Add 操作小节中会补充。
完成上面 Add 操作后,数据结构更新成了下图这样的形式。
这样是理想情况下的操作,一个 bucket 中只有一个 hashCode 没有碰撞的产生,但是实际上是会经常产生碰撞;那么 Dictionary 类中又是如何解决碰撞的呢。
我们继续执行一个Add操作,dictionary.Add("c","d"),假设GetHashCode(“c”)=6,最后6 % 4 = 2。最后桶的index也是 2,按照之前的步骤 1~3 是没有问题的,执行完后数据结构如下图所示。
如果继续执行 步骤4 那么 buckets[2] = 1,然后原来的 buckets[2]=>entries[0] 的关系就会丢失,这是我们不愿意看到的。现在 Entry 中的 next 就发挥大作用了。
如果对应的 buckets[index] 有其它元素已经存在,那么会执行以下两条语句,让新的 entry.next 指向之前的元素,让 buckets[index] 指向现在的新的元素,就构成了一个单链表。
entries[index].next = buckets[targetBucket];
...
buckets[targetBucket] = index;
经过上面的步骤以后,数据结构就更新成了下图这个样子。
4. Dictionary - Find 操作
为了方便演示如何查找,我们继续 Add 一个元素dictionary.Add("e","f"),GetHashCode(“e”) = 7;,7% buckets.Length=3,数据结构如下所示。
假设我们现在执行这样一条语句dictionary.GetValueOrDefault("a"),会执行以下步骤.
- 获取 key 的 hashCode,计算出所在的桶位置。我们之前提到,“a” 的 hashCode=6,所以最后计算出来 targetBucket=2。
- 通过 buckets[2]=1 找到 entries[1],比较 key 的值是否相等,相等就返回 entryIndex,不相等就继续 entries[next] 查找,直到找到与 key 相等的元素或者 next == -1 的时候。这里我们找到了 key == “a” 的元素,返回 entryIndex =0。
- 如果 entryIndex >= 0 那么返回对应的 entries[entryIndex] 元素,否则返回 default(TValue)。这里我们直接返回 entries[0].value。
整个查找的过程如下图所示:
将查找的代码摘录下来,如下所示:
// 寻找Entry元素的位置
private int FindEntry(TKey key)
{if( key == null) {ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key);}if (buckets != null) {int hashCode = comparer.GetHashCode(key) & 0x7FFFFFFF; // 获取HashCode,忽略符号位// int i = buckets[hashCode % buckets.Length] 找到对应桶,然后获取entry在entries中位置// i >= 0; i = entries[i].next 遍历单链表for (int i = buckets[hashCode % buckets.Length]; i >= 0; i = entries[i].next) {// 找到就返回了if (entries[i].hashCode == hashCode && comparer.Equals(entries[i].key, key)) return i;}}return -1;
}
...
internal TValue GetValueOrDefault(TKey key)
{int i = FindEntry(key);// 大于等于0代表找到了元素位置,直接返回value// 否则返回该类型的默认值if (i >= 0) {return entries[i].value;}return default(TValue);
}
5. Dictionary - Remove 操作
前面已经向大家介绍了增加、查找,接下来向大家介绍 Dictionary 如何执行删除操作。我们沿用之前的 Dictionary 数据结构。
删除前面步骤和查找类似,也是需要找到元素的位置,然后再进行删除的操作。
我们现在执行这样一条语句dictionary.Remove("a"),hashFunc 运算结果和上文中一致。步骤大部分与查找类似,我们直接看摘录的代码,如下所示。
public bool Remove(TKey key)
{if(key == null) {ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key);}if (buckets != null) {// 1. 通过key获取hashCodeint hashCode = comparer.GetHashCode(key) & 0x7FFFFFFF;// 2. 取余获取bucket位置int bucket = hashCode % buckets.Length;// last用于确定是否当前bucket的单链表中最后一个元素int last = -1;// 3. 遍历bucket对应的单链表for (int i = buckets[bucket]; i >= 0; last = i, i = entries[i].next) {if (entries[i].hashCode == hashCode && comparer.Equals(entries[i].key, key)) {// 4. 找到元素后,如果last<0,代表当前是bucket中最后一个元素,那么直接让bucket内下标赋值为 entries[i].next即可if (last < 0) {buckets[bucket] = entries[i].next;}else {// 4.1 last不小于0,代表当前元素处于bucket单链表中间位置,需要将该元素的头结点和尾节点相连起来,防止链表中断entries[last].next = entries[i].next;}// 5. 将Entry结构体内数据初始化entries[i].hashCode = -1;// 5.1 建立freeList单链表entries[i].next = freeList;entries[i].key = default(TKey);entries[i].value = default(TValue);// *6. 关键的代码,freeList等于当前的entry位置,下一次Add元素会优先Add到该位置freeList = i;freeCount++;// 7. 版本号+1version++;return true;}}}return false;
}
执行完上面代码后,数据结构就更新成了下图所示。需要注意version、freeList、freeCount的值都被更新了。
6. Dictionary - Resize 操作(扩容)
6.1 扩容操作的触发条件
首先我们需要知道在什么情况下,会发生扩容操作;第一种情况自然就是数组已经满了,没有办法继续存放新的元素。如下图所示的情况。
从上文中大家都知道,Hash 运算会不可避免的产生冲突,Dictionary中使用拉链法来解决冲突的问题,但是大家看下图中的这种情况。
所有的元素都刚好落在buckets[3]上面,结果就是导致了时间复杂度 O(n),查找性能会下降;所以第二种,Dictionary 中发生的碰撞次数太多,会严重影响性能,也会触发扩容操作。
目前 .Net Framwork 4.7中设置的碰撞次数阈值为100。
public const int HashCollisionThreshold = 100;
6.2 扩容操作如何进行
为了给大家演示的清楚,模拟了以下这种数据结构,大小为 2 的Dictionary,假设碰撞的阈值为 2;现在触发 Hash 碰撞扩容。
- 申请两倍于现在大小的 buckets、entries
- 将现有的元素拷贝到新的 entries
- 如果是 Hash 碰撞扩容,使用新 HashCode 函数重新计算 Hash 值
新的 Hash 函数并一定能解决碰撞的问题,有可能会更糟,像下图中一样的还是会落在同一个 bucket 上。
- 对 entries 每个元素 bucket = newEntries[i].hashCode % newSize 确定新 buckets 位置
- 重建hash链,newEntries[i].next = buckets[bucket]; buckets[bucket] = i;
因为 buckets 也扩充为两倍大小了,所以需要重新确定 hashCode 在哪个 bucket 中;最后重新建立 hash 单链表。
这就完成了扩容的操作,如果是达到 Hash 碰撞阈值触发的扩容可能扩容后结果会更差。
在JDK中,HashMap如果碰撞的次数太多了,那么会将单链表转换为 红黑树 提升查找性能。目前 .Net Framwork 中还没有这样的优化, .Net Core 中已经有了类似的优化。
每次扩容操作都需要遍历所有元素,会影响性能。所以创建Dictionary实例时最好设置一个预估的初始大小。
private void Resize(int newSize, bool forceNewHashCodes)
{Contract.Assert(newSize >= entries.Length);// 1. 申请新的Buckets和entriesint[] newBuckets = new int[newSize];for (int i = 0; i < newBuckets.Length; i++) newBuckets[i] = -1;Entry[] newEntries = new Entry[newSize];// 2. 将entries内元素拷贝到新的entries总Array.Copy(entries, 0, newEntries, 0, count);// 3. 如果是Hash碰撞扩容,使用新HashCode函数重新计算Hash值if(forceNewHashCodes) {for (int i = 0; i < count; i++) {if(newEntries[i].hashCode != -1) {newEntries[i].hashCode = (comparer.GetHashCode(newEntries[i].key) & 0x7FFFFFFF);}}}// 4. 确定新的bucket位置// 5. 重建Hahs单链表for (int i = 0; i < count; i++) {if (newEntries[i].hashCode >= 0) {int bucket = newEntries[i].hashCode % newSize;newEntries[i].next = newBuckets[bucket];newBuckets[bucket] = i;}}buckets = newBuckets;entries = newEntries;
}
7. Dictionary - 再谈 Add 操作
在我们之前的 Add 操作步骤中,提到了这样一段话,这里提到会有一种其它的情况,那就是有元素被删除的情况。
- 避开一种其它情况不谈,接下来它会将 hashCode、key、value 等信息存入 entries[count] 中,因为 count 位置是空闲的;继续 count++ 指向下一个空闲位置。上图中第一个位置,index = 0 就是空闲的,所以就存放在 entries[0] 的位置。
因为 count 是通过自增的方式来指向 entries[] 下一个空闲的 entry,如果有元素被删除了,那么在 count 之前的位置就会出现一个空闲的 entry;如果不处理,会有很多空间被浪费。
这就是为什么 Remove 操作会记录 freeList、freeCount,就是为了将删除的空间利用起来。实际上 Add 操作会优先使用 freeList 的空闲 entry 位置,摘录代码如下。
private void Insert(TKey key, TValue value, bool add)
{if( key == null ) {ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key);}if (buckets == null) Initialize(0);// 通过key获取hashCodeint hashCode = comparer.GetHashCode(key) & 0x7FFFFFFF;// 计算出目标bucket下标int targetBucket = hashCode % buckets.Length;// 碰撞次数int collisionCount = 0;for (int i = buckets[targetBucket]; i >= 0; i = entries[i].next) {if (entries[i].hashCode == hashCode && comparer.Equals(entries[i].key, key)) {// 如果是增加操作,遍历到了相同的元素,那么抛出异常if (add) { ThrowHelper.ThrowArgumentException(ExceptionResource.Argument_AddingDuplicate);}// 如果不是增加操作,那可能是索引赋值操作 dictionary["foo"] = "foo"// 那么赋值后版本++,退出entries[i].value = value;version++;return;}// 每遍历一个元素,都是一次碰撞collisionCount++;}int index;// 如果有被删除的元素,那么将元素放到被删除元素的空闲位置if (freeCount > 0) {index = freeList;freeList = entries[index].next;freeCount--;}else {// 如果当前entries已满,那么触发扩容if (count == entries.Length){Resize();targetBucket = hashCode % buckets.Length;}index = count;count++;}// 给entry赋值entries[index].hashCode = hashCode;entries[index].next = buckets[targetBucket];entries[index].key = key;entries[index].value = value;buckets[targetBucket] = index;// 版本号++version++;// 如果碰撞次数大于设置的最大碰撞次数,那么触发Hash碰撞扩容if(collisionCount > HashHelpers.HashCollisionThreshold && HashHelpers.IsWellKnownEqualityComparer(comparer)) {comparer = (IEqualityComparer<TKey>) HashHelpers.GetRandomizedEqualityComparer(comparer);Resize(entries.Length, true);}
}
8. Collection 版本控制
在上文中一直提到了version这个变量,在每一次新增、修改和删除操作时,都会使version++;那么这个version存在的意义是什么呢?
首先我们来看一段代码,这段代码中首先实例化了一个Dictionary实例,然后通过foreach遍历该实例,在foreach代码块中使用dic.Remove(kv.Key)删除元素。
结果就是抛出了System.InvalidOperationException:"Collection was modified..."这样的异常,迭代过程中不允许集合出现变化。如果在 Java 中遍历直接删除元素,会出现诡异的问题,所以 .Net 中就使用了version来实现版本控制。
那么如何在迭代过程中实现版本控制的呢?我们看一看源码就很清楚的知道。
在迭代器初始化时,就会记录dictionary.version版本号,之后每一次迭代过程都会检查版本号是否一致,如果不一致将抛出异常。
这样就避免了在迭代过程中修改了集合,造成很多诡异的问题。
应用举例
public Dictionary();构造函数public Dictionary(int capacity);构造函数public void Add(TKey key, TValue value);将指定的键和值添加到字典中。public bool Remove(TKey key);将带有指定键的值移除。public bool ContainsKey(TKey key);确定是否包含指定键。public bool ContainsValue(TValue value);确定否包含特定值。public TValue this[TKey key] { get; set; }获取或设置与指定的键关联的值。public KeyCollection Keys { get; }获得键的集合。public ValueCollection Values { get; }获得值的集合。
public static void DicSample1()
{Dictionary<string, string> dic = new Dictionary<string, string>();try{if (dic.ContainsKey("Item1") == false){dic.Add("Item1", "ZheJiang");}if (dic.ContainsKey("Item2") == false){dic.Add("Item2", "ShangHai");}else{dic["Item2"] = "ShangHai";}if (dic.ContainsKey("Item3") == false){dic.Add("Item3", "BeiJing");}}catch (Exception e){Console.WriteLine("Error: {0}", e.Message);}//判断是否存在相应的key并显示if (dic.ContainsKey("Item1")){Console.WriteLine("Output: " + dic["Item1"]);}//遍历Keyforeach (string key in dic.Keys){Console.WriteLine("Output Key: {0}", key);}//遍历Valueforeach (string value in dic.Values){Console.WriteLine("Output Value: {0}", value);}//遍历Key和Valueforeach (KeyValuePair<string, string> d in dic){Console.WriteLine("Output Key : {0}, Value : {1} ", d.Key, d.Value);}
}
注意:增加键值对之前需要判断是否存在该键,如果已经存在该键而不判断,将抛出异常。
总结
本篇图文介绍了哈希函数、哈希表、哈希桶、哈希碰撞、拉链法、哈希碰撞扩容等概念,以及Dictionary的具体实现原理与应用。希望通过这些介绍大家可以更加自信的使用Dictionary这种数据结构。今天就到这里吧,See You!
参考文献
- https://www.cnblogs.com/InCerry/p/10325290.html
- https://www.cnblogs.com/whgk/p/6071617.html
- https://www.cnblogs.com/linlf03/archive/2011/12/09/2282574.html
往期活动
LSGO软件技术团队会定期开展提升编程技能的刻意练习活动,希望大家能够参与进来一起刻意练习,一起学习进步!
- Python基础刻意练习活动即将开启,你参加吗?
- Task01:变量、运算符与数据类型
- Task02:条件与循环
- Task03:列表与元组
- Task04:字符串与序列
- Task05:函数与Lambda表达式
- Task06:字典与集合
- Task07:文件与文件系统
- Task08:异常处理
- Task09:else 与 with 语句
- Task10:类与对象
- Task11:魔法方法
- Task12:模块
我是 终身学习者“老马”,一个长期践行“结伴式学习”理念的 中年大叔。
我崇尚分享,渴望成长,于2010年创立了“LSGO软件技术团队”,并加入了国内著名的开源组织“Datawhale”,也是“Dre@mtech”、“智能机器人研究中心”和“大数据与哲学社会科学实验室”的一员。
愿我们一起学习,一起进步,相互陪伴,共同成长。
后台回复「搜搜搜」,随机获取电子资源!
欢迎关注,请扫描二维码:

相关文章:

思念水饺吃成泡沫水饺(图)思念质量门
思念再曝水饺吃出泡沫 !思念带着“创可贴汤圆”和“泡沫水饺”“拜晚年”了,而失去新国标的“护身符”,思念这次还要找出什么样的借口为汤圆里的创可贴和水饺里的泡沫找“台阶”下呢?思念汤圆刚被爆吃出创可贴,思念水饺…
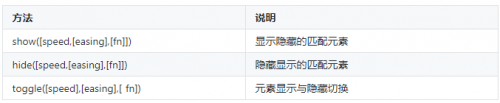
jQuery动画的显示与隐藏效果
jQuery中用于控制元素显示和隐藏效果的方法如表1所示。 表1 控制元素的显示和隐藏 在表1中,参数speed表示动画的速度,可设置为动画时长的毫秒值(如1000),或预定的3种速度(slow、fast和normal);参数easing表示切换效果,默认效果为s…

技术图文:字典技术在求解算法题中的应用
背景 前段时间,在知识星球立了一个Flag,这是总结Leetcode刷题的第二篇图文。 在总结这篇图文的时候,顺便总结了 C# 中Dictionary类的实现,大家可以参考一下: 浅析 C# Dictionary实现原理 理论部分 C# 中字典的常…

[WCF REST] 解决资源并发修改的一个有效的手段:条件更新(Conditional Update)
条件获取(Conditional Update)可以避免相同数据的重复传输,进而提高性能。条件更新(Conditional Update)用于解决资源并发操作问题。如果我们预先获取一个资源进行修改或者删除,条件更新检验帮助我们确认资…

Netty 之 Zero-copy 的实现(下)
上一篇说到了 CompositeByteBuf ,这一篇接着上篇的讲下去。 FileRegion 让我们先看一个Netty官方的example // netty-netty-4.1.16.Final\example\src\main\java\io\netty\example\file\FileServerHandler.java public void channelRead0(ChannelHandlerContext ctx…

Java中final关键字如何使用?
final变量只能赋值一次,赋值的方式有三种: 1)声明变量时直接赋值; 2)非静态成员变量在{}块中赋值,静态成员变量在static{}块中赋值; 3)非静态成员变量在构造方法中赋值。 final修饰类 final类不能被继承,因此不会有子类。final类中…
技术图文:双指针在求解算法题中的应用
背景 前段时间,在知识星球立了一个Flag,这是总结Leetcode刷题的第三篇图文。 理论部分 Python list 的源码地址: https://github.com/python/cpython/blob/master/Include/listobject.h https://github.com/python/cpython/blob/master/O…
【CSON原创】HTML5游戏框架cnGameJS开发实录(外部输入模块篇)
返回目录 1.为什么我们需要外部输入模块? 在游戏中我们常常用到类似这样的操作:鼠标点击某位置,玩家对象移动到该位置,或者按鼠标方向键,玩家向不同方向移动,等等。这些操作无一不用与外部输入设备打交道。…
中国科协(深圳)海外人才离岸创新创业基地源创力中心开业,主打国际创业服务...
2017年9月28日,由深圳市科学技术协会主办、深圳市罗湖区人民政府支持,深圳市源创力离岸创新中心承办的“梧桐山基地开园仪式暨梧桐湾未来论坛”于深圳举办。 据介绍, “中国科协(深圳)海外人才离岸创新创业基地”是在深…

找java培训机构如何挑选
java技术在互联网行业的需求率还是非常高的,它的发展前景非常可观,想要学好java技术,那么寻找一个好的java培训机构是非常重要的,那么找java培训机构如何挑选呢?来看看下面的详细介绍。 找java培训机构如何挑选? 在选择…
技术图文:集合技术在求解算法题中的应用
背景 前段时间,在知识星球立了一个Flag,这是总结Leetcode刷题的第四篇图文。 理论部分 HashSet C# 语言中 HashSet<T> 是包含不重复项的无序列表,称为“集合(set)”。由于set是一个保留字,所以用HashSet来表示。 public…
sql server 2008数据导入Oracle方法
试了几种sql server数据导入Oracle的方法,发现还是sql server 的导入导出工具最好使。使用方法很简单,照着向导做就可以。不过使用中需要注意以下几点: 系统盘需要足够大。因为SSIS的临时文件都是生成在系统盘的,系统盘太小&#…
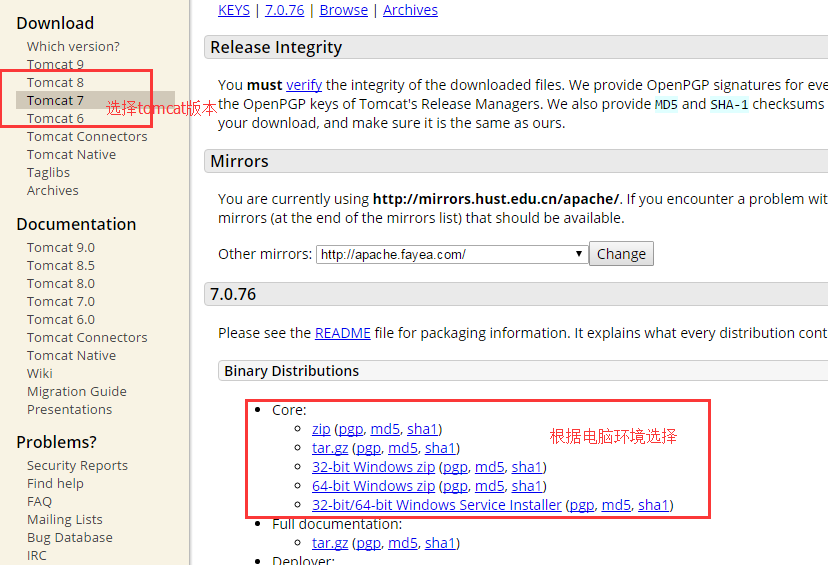
nginx+tomcat配置负载均衡集群
一、Hello world 1、前期环境准备 准备两个解压版tomcat,如何同时启动两个tomcat,方法如下: 首先去apache tomcat官网下载一个tomcat解压版。 解压该压缩包,生成n份tomcat 分别命名为 tomcat1,tomcat2, 然后…

参加UI设计培训要学多久
UI设计要学习的内容有很多,至于参加UI设计培训要学多久这个问题,要看你的学习能力和所在的UI设计培训机构都教些什么,我们来看看下面的详细介绍。 参加UI设计培训要学多久?千锋教育的课程大纲分享给大家参考学习一下: 阶段一&…
技术图文:C# 语言中的扩展方法
背景 前段时间,在知识星球立了一个Flag,在总结 Leetcode 刷题的第五篇图文时遇到了扩展方法 这个知识点,于是先总结一下。 1.扩展方法概述 扩展方法能够向现有类型“添加”方法,而无需创建新的派生类型、重新编译或以…
如何在ToolBar中显示文字和图标,自定义图标大小,并和MenuItem关联
要注意以下几个方面,先后顺序未必正确,有可能多设几次 1.设置ToolBar可以显示文字ToolBar.ShowCaption : True;2.设置ToolButton大小ImageList.WidthImageList.Height3.设置菜单关联4.设置运行时显示图标(这个是关键)ToolButton.Menuitum.ImageIndex要保证MenuItem所在的MainMe…

C#程序调用cmd执行命令
酷小孩 原文 C#程序调用cmd执行命令 对于C#通过程序来调用cmd命令的操作,网上有很多类似的文章,但很多都不行,竟是漫天的拷贝。我自己测试整理了一下。 代码: string str Console.ReadLine();System.Diagnostics.Process p new …
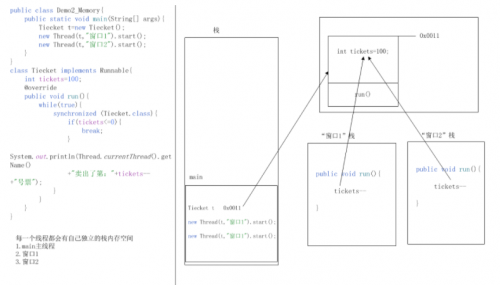
Java虚拟机的内存空间有几种
Java虚拟机的内存空间有几种?(1)问题分析: JVM(虚拟机)的内存划分 不同的数据使用的是哪一块内存空间 (2)核心答案讲解: Java虚拟机有那几块内存空间: 1)栈内存:方法运行时所进入的内存,里面还会存储程序的…
技术图文:排序技术在求解算法题中的应用
背景 前段时间,在知识星球立了一个Flag,这是总结Leetcode刷题的第五篇图文。 理论部分 C# 中的排序 对集合类的排序,我们通常使用位于 System.Core 程序集,System.Linq命名空间下,Enumerable静态类中的扩展方法。 …
如果有电脑——计算机达人成长之路(36)
5、电脑情缘(一)王新华的电脑 现在的大学生一般都有一个工具,就是计算机,尤其是计算机科学系的学生,几乎人手一台。对此,木鸿飞只能深深的说上一句:“幸福啊!” 现在人可能不能了解这…
Javascript中二进制数据处理方法
Javascript中二进制数据处理方法 转载于:https://www.cnblogs.com/motadou/archive/2012/02/19/2358514.html

正规Java培训机构是什么样的
正规Java培训机构是什么样的?这对于很多想真正学习到java技术的人来说是非常重要的,选择一个适合自己的靠谱的Java培训机构,学有所成工作也是比较稳定的,下面我们来看看详细的介绍。 正规Java培训机构是什么样的?其实对于这个问题…
《40期》 我们要把世纪末日变成重生日
2012年.传说中一个会是世纪末日的一年。(ps:电影看多了……- _-!!!),但是寒假过后的北京。天气却是十分的晴朗、出奇的好。而就在今天也就是2012年2月9日40期的开班典礼就选了这一天。地点就是在育荣教学园区2栋教学楼…
LeetCode刷题宝典 V1.0 PDF下载
前段时间,在知识星球立了一个Flag,现在 Flag 的进度为 100%,很是开心。 为了大家学习的方便,所以整理了这份150多页的小册子。可以作为学习数据结构与算法或备考计算机类研究生的参考资料,希望对大家有所帮助。 小册子…
机器学习:信用风险评估评分卡建模方法及原理
#课程介绍 信用风险评分卡为信用风险管理提供了一种有效的、经验性的解决方法,是消费信贷管理中广泛应用的技术手段。 评分卡是信用风险评估领域常见的建模方法。评分卡并不加单对应于某一种机器学习算法,而是一种通用的建模框架,讲原始数据通…

0基础学怎么学习python
Python相对于其他编程语言来说是比较简单的,非常适合零基础的小白学习,想要进入到互联网行业,可以优先选择学习Python,那么下面小编就来为大家详细的介绍一下0基础学怎么学习python? 0基础学怎么学习python? 1、要读书…

nginx技术(2)nginx的配置详解
nginx的配置 1,启动nginx 1234567[rootcentos6 nginx-1.2.9]# /usr/sbin/nginx -c /etc/nginx/nginx.conf 启动nginx [rootcentos6 nginx-1.2.9]# ps -ef|grep nginx 查看进程 root 5479 1 0 04:15 ? 00:00:00 nginx: master process /usr/sbin/nginx -…

javascript 基础篇2 数据类型,语句,函数
文章里如果有错误的话,希望能帮忙指正~我也是边看视频边学习中,这个算是个笔记吧~自认为总结出来的东西比看视频要节省点时间~能帮到别人最好了~帮不到也起码恩能帮到我自己 嘿~ 写内容之前废话一句:因为旧版有些浏览器不支持javascript脚本&…
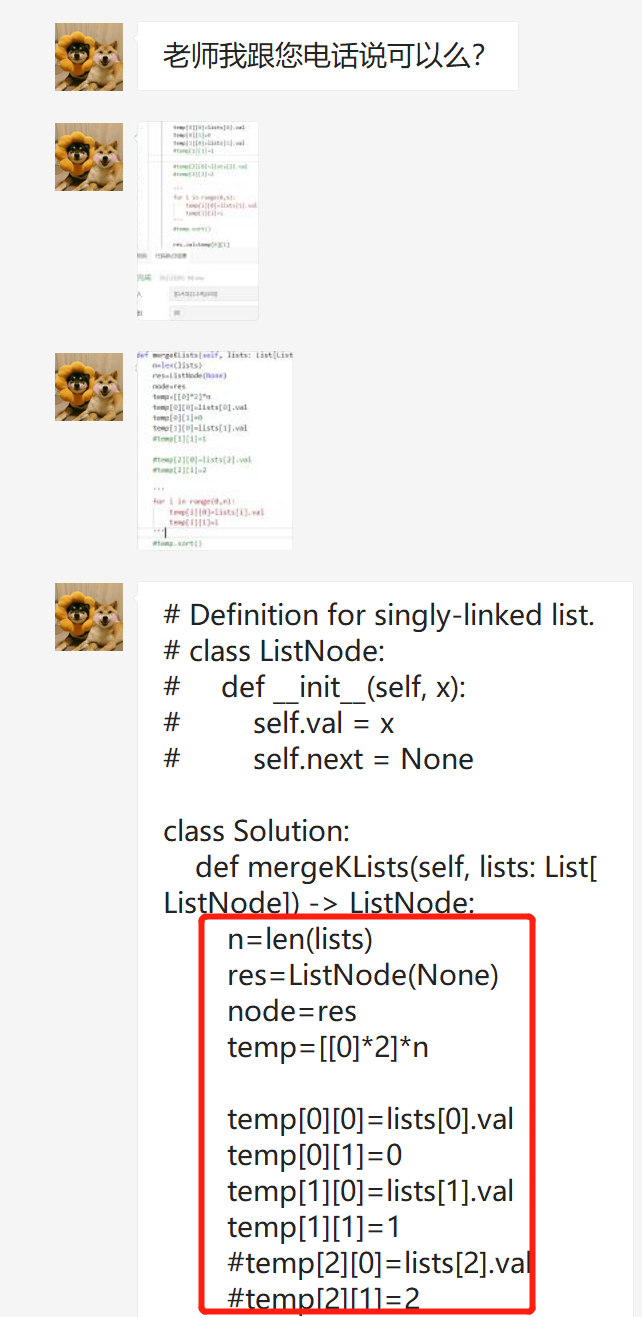
技术图文:如何在Python中定义二维数组?
背景 前几天,有位同学问我如下的问题: “temp[0][0]修改后,为什么temp[1][0]、temp[2][0]也发生了变化?” “在Python中二维数组是怎样定义和使用的?” 今天就来谈谈这个问题。 技术分析 在 C# 语言中有直接定义二…

javascript的垃圾回收机制指的是什么
定义:指一块被分配的内存既不能使用,又不能回收,直到浏览器进程结束。 像 C 这样的编程语言,具有低级内存管理原语,如 malloc()和 free()。开发人员使用这些原语显式地对操作系统的内存进行分配和释放。 而 JavaScript…