技术图文:Numpy 一维数组 VS. Pandas Series
背景
Numpy 提供的最重要的数据结构是 ndarray,它是 Python 中 list 的扩展。
Pandas 提供了两种非常重要的数据结构 Series和DataFrame。
Numpy 中的一维数组与 Series 相似,一维数组只是提供了从0开始与位置有关的索引,而Series除了位置索引之外还可以附加额外的索引。本文将从对象的创建、属性的访问、数据的获取以及常用方法等方面来总结这两种结构的异同。
1. 如何创建对象
1.1 创建一维数组对象
- 通过 list或tuple 创建一维数组。
- 通过数值范围来创建一维数组,比如
linspace()函数,返回指定间隔内的等间隔数字。arange()函数,返回给定间隔内的均匀间隔的值。
import numpy as npa0 = np.array((10, 40, 5, 90, 35, 40))
print(a0)
# [10 40 5 90 35 40]a1 = np.array([10, 40, 5, 90, 35, 40])
print(a1)
# [10 40 5 90 35 40]a2 = np.linspace(start=0, stop=5, num=5)
print(a2)
# [0. 1.25 2.5 3.75 5. ]a3 = np.arange(10, 15)
print(a3)
# [10 11 12 13 14]
1.2 创建Series对象
Series 可以看作是能够附加索引的一维数组,所以可以像 Numpy 创建一维数组一样使用 list或tuple 来创建,甚至可以使用 Numpy的一维数组 直接创建。
- 通过列表
list、元组tuple创建Series。 - 通过 Numpy 创建
Series。
另外,Series 可以附加索引,所以可以在创建的时候直接指定需要附加的索引,以及利用字典的key-value键值对 来直接创建。
- 通过指定
index关键字的方式创建带有自定义索引的Series。 - 通过字典
dict创建Series。
import pandas as pd
import numpy as nps0 = pd.Series((10, 40, 5, 90, 35, 40))
print(s0)
# 0 10
# 1 40
# 2 5
# 3 90
# 4 35
# 5 40
# dtype: int64s1 = pd.Series([10, 40, 5, 90, 35, 40])
print(s1)
# 0 10
# 1 40
# 2 5
# 3 90
# 4 35
# 5 40
# dtype: int64s2 = pd.Series(np.linspace(start=0, stop=5, num=5))
print(s2)
# 0 0.00
# 1 1.25
# 2 2.50
# 3 3.75
# 4 5.00
# dtype: float64s3 = pd.Series(np.arange(10, 15))
print(s3)
# 0 10
# 1 11
# 2 12
# 3 13
# 4 14
# dtype: int32s4 = pd.Series([100, 79, 65, 77],index=["chinese", "english", "history", "maths"],name='score')
print(s4)
# chinese 100
# english 79
# history 65
# maths 77
# Name: score, dtype: int64s5 = pd.Series({"name": "张三", "Gender": "男", "age": 20,"height": 180, "weight": 66})
print(s5)
# name 张三
# Gender 男
# age 20
# height 180
# weight 66
# dtype: object
2. 如何获取属性
2.1 获取一维数组对象属性
在使用 Numpy 时,有时会想知道数组的某些信息,可以通过以下属性来得到:
numpy.ndarray.ndim用于返回数组的维数(轴的个数)也称为秩,一维数组的秩为 1,二维数组的秩为 2,以此类推。numpy.ndarray.shape表示数组的维度,返回一个元组,这个元组的长度就是维度的数目,即ndim属性(秩)。numpy.ndarray.size数组中所有元素的总量,相当于数组的shape中所有元素的乘积,例如矩阵的元素总量为行与列的乘积。numpy.ndarray.dtypendarray对象的元素类型。
import numpy as npa0 = np.array([10, 40, 5, 90, 35, 40])
print(a0.ndim) # 1
print(a0.size) # 6
print(a0.shape) # (6,)
print(a0.dtype) # int32
2.2 获取Series对象属性
Series 除了拥有 Numpy 中ndim、size、shap、dtype属性外,还拥有下列属性:
index附加的索引values存储的数据name对象的名称
import pandas as pds0 = pd.Series((10, 40, 5, 90, 35, 40))
print(s0.ndim) # 1
print(s0.size) # 6
print(s0.shape) # (6,)
print(s0.dtype) # int64
print(s0.index)
# RangeIndex(start=0, stop=6, step=1)
print(s0.values)
# [10 40 5 90 35 40]
print(s0.name)
# Nones1 = pd.Series([100, 79, 65, 77],index=["chinese", "english", "history", "maths"],name='score')
print(s1.index)
# Index(['chinese', 'english', 'history', 'maths'], dtype='object')print(s1.values)
# [100 79 65 77]
3. 如何获取数据
3.1 获取一维数组对象数据
一维数组只有默认的位置索引,即从0开始的索引,所以获取数据只有通过位置索引这一种方式。
- 通过整数索引(要获取数组的单个元素,指定元素的索引即可。)
- 通过切片索引(切片操作是指抽取数组的一部分元素生成新数组。)
- 通过整数数组索引(方括号内传入多个索引值,可以同时选择多个元素。)
- 通过布尔索引(通过一个布尔数组来索引目标数组。)
import numpy as npa0 = np.array([10, 40, 5, 90, 35, 40])
print(a0[0]) # 10
print(a0[0:2]) # [10 40]
print(a0[2:]) # [ 5 90 35 40]
print(a0[0::2]) # [10 5 35]
print(a0[[0, 1, 2]]) # [10 40 5]
print(a0[:5]) # [10 40 5 90 35]
print(a0[-5:]) # [40 5 90 35 40]
print(a0[a0 > 35]) # [40 90 40]
print(a0[a0 != 35]) # [10 40 5 90 40]
3.2 获取Series对象数据
因为不附加索引的 Series 也拥有位置索引,所以可以延用一维数组获取数据的方式。另外 Series 也可以通过附加索引来获取数据。
- 通过位置获取数据
- 通过索引获取数据
- 通过
head()和tail()获取数据
import pandas as pds0 = pd.Series((10, 40, 5, 90, 35, 40))
print(s0[0]) # 10
print(s0[0:2])
# 0 10
# 1 40
# dtype: int64
print(s0[2:])
# 2 5
# 3 90
# 4 35
# 5 40
# dtype: int64
print(s0[0::2])
# 0 10
# 2 5
# 4 35
# dtype: int64
print(s0.head())
# 0 10
# 1 40
# 2 5
# 3 90
# 4 35
# dtype: int64
print(s0.tail())
# 1 40
# 2 5
# 3 90
# 4 35
# 5 40
# dtype: int64
print(s0[[0, 1, 2]])
# 0 10
# 1 40
# 2 5
# dtype: int64s1 = pd.Series([100, 79, 65, 77],index=["chinese", "english", "history", "maths"],name='score')
print(s1["chinese"]) # 100
print(s1[["english", "history"]])
# english 79
# history 65
# dtype: int64
print(s1[s1.values > 70])
# chinese 100
# english 79
# maths 77
# Name: score, dtype: int64
print(s1[s1.index != 'chinese'])
# english 79
# history 65
# maths 77
# Name: score, dtype: int64s2 = pd.Series({"name": "张三", "Gender": "男", "age": 20,"height": 180, "weight": 66})
print(s2["name"]) # 张三
print(s2[["name", "height", "weight"]])
# name 张三
# height 180
# weight 66
# dtype: object
4. 基本运算
4.1 查看描述性统计数据
一维数组对象
描述性统计分析最常见的函数如下:
numpy.min()函数:返回数组的最小值或沿轴的最小值。numpy.max()函数:返回数组的最大值或沿轴的最大值。numpy.quantile()函数:计算沿指定轴的数据的分位数。numpy.median()函数:沿指定轴计算中位数。返回数组元素的中位数。numpy.mean()函数:计算沿指定轴的算术平均值。numpy.std()函数:计算沿指定轴的标准偏差。
import numpy as npa0 = np.array([10, 40, 5, 90, 35, 40])
print(np.size(a0)) # 6
print(np.mean(a0)) # 36.666666666666664
print(np.std(a0, ddof=1)) # 30.276503540974915
print(np.max(a0)) # 90
print(np.min(a0)) # 5
print(np.median(a0)) # 37.5
print(np.quantile(a0, [.25, .5, .75])) # [16.25 37.5 40. ]
Series对象
除了一维数组所提供的函数之外,Series也提供了更多的函数用于描述性统计分析。
import pandas as pds0 = pd.Series((10, 40, 5, 90, 35, 40))
print(type(s0.values)) # <class 'numpy.ndarray'>
print(s0.count()) # 6
print(s0.mean()) # 36.666666666666664
print(s0.std()) # 30.276503540974915
print(s0.max()) # 90
print(s0.min()) # 5
print(s0.median()) # 37.5
print(s0.quantile([.25, .5, .75]))
# 0.25 16.25
# 0.50 37.50
# 0.75 40.00
# dtype: float64print(s0.mode())
# 0 40
# dtype: int64
print(s0.value_counts())
# 40 2
# 35 1
# 5 1
# 90 1
# 10 1
# dtype: int64
print(s0.describe())
# count 6.000000
# mean 36.666667
# std 30.276504
# min 5.000000
# 25% 16.250000
# 50% 37.500000
# 75% 40.000000
# max 90.000000
# dtype: float64
4.2 数学运算
一维数组对象
numpy.add()函数:按元素相加。numpy.subtract()函数:按元素相减。numpy.multiply()函数:按元素相乘。numpy.divide()函数:返回输入的实际除法(按元素)。numpy.floor_divide()函数:返回小于或等于输入除法的最大整数(地板除)。numpy.power()函数:按元素做幂运算。
在 Numpy 中对以上函数进行了运算符的重载,且运算符为 元素级。也就是说,它们只用于位置相同的元素之间,所得到的运算结果组成一个新的数组。
import numpy as npa0 = np.array([10, 40, 5, 90, 35, 40])
print(a0 + 1) # [11 41 6 91 36 41]
print(a0 - 1) # [ 9 39 4 89 34 39]
print(a0 * 2) # [ 20 80 10 180 70 80]
print(a0 / 2) # [ 5. 20. 2.5 45. 17.5 20. ]
print(a0 // 2) # [ 5 20 2 45 17 20]
print(a0 % 2) # [0 0 1 0 1 0]
print(a0 ** 2) # [ 100 1600 25 8100 1225 1600]print(np.sqrt(a0))
# [3.16227766 6.32455532 2.23606798 9.48683298 5.91607978 6.32455532]
print(np.log(a0))
# [2.30258509 3.68887945 1.60943791 4.49980967 3.55534806 3.68887945]
Series对象
Series 与 Numpy 中的一维数组一样支持常用运算符的重载,并且可以把 Series对象 作为参数带入到 Numpy 的数学运算中。
numpy.sqrt()函数:按元素返回数组的非负平方根。numpy.log()函数:按元素取自然对数。
import pandas as pd
import numpy as nps0 = pd.Series((10, 40, 5, 90, 35, 40))
print(type(s0.values)) # <class 'numpy.ndarray'>
print(s0 + 1)
# 0 11
# 1 41
# 2 6
# 3 91
# 4 36
# 5 41
# dtype: int64print(s0 - 1)
# 0 9
# 1 39
# 2 4
# 3 89
# 4 34
# 5 39
# dtype: int64print(s0 * 2)
# 0 20
# 1 80
# 2 10
# 3 180
# 4 70
# 5 80
# dtype: int64print(s0 / 2) # 对每个值除2
# 0 5.0
# 1 20.0
# 2 2.5
# 3 45.0
# 4 17.5
# 5 20.0
# dtype: float64print(s0 // 2) # 对每个值除2后取整
# 0 5
# 1 20
# 2 2
# 3 45
# 4 17
# 5 20
# dtype: int64print(s0 % 2) # 取余
# 0 0
# 1 0
# 2 1
# 3 0
# 4 1
# 5 0
# dtype: int64print(s0 ** 2) # 求平方
# 0 100
# 1 1600
# 2 25
# 3 8100
# 4 1225
# 5 1600
# dtype: int64print(np.sqrt(s0)) # 求开方
# 0 3.162278
# 1 6.324555
# 2 2.236068
# 3 9.486833
# 4 5.916080
# 5 6.324555
# dtype: float64print(np.log(s0)) # 求对数
# 0 2.302585
# 1 3.688879
# 2 1.609438
# 3 4.499810
# 4 3.555348
# 5 3.688879
# dtype: float64
4.3 其它运算
由于 Series 可以附加索引,所以两个 Series对象 进行相加的时候,必须满足索引对齐。另外,Series 可以通过to_numpy()方法转化成 Numpy 的一维数组。
import pandas as pd
import numpy as nps1 = pd.Series({'a': 10, 'b': 40, 'c': 5, 'd': 90, 'e': 35, 'f': 40}, name='数值')
s2 = pd.Series({'a': 10, 'b': 20, 'd': 23, 'g': 90, 'h': 35, 'i': 40}, name='数值')
s3 = s1 + s2
print(s3)
# a 20.0
# b 60.0
# c NaN
# d 113.0
# e NaN
# f NaN
# g NaN
# h NaN
# i NaN
# Name: 数值, dtype: float64
print(s3[s3.isnull()])
# c NaN
# e NaN
# f NaN
# g NaN
# h NaN
# i NaN
# Name: 数值, dtype: float64
print(s3[s3.notnull()])
# a 20.0
# b 60.0
# d 113.0
# Name: 数值, dtype: float64
s4 = s3.fillna(s3.mean())
print(s4)
# a 20.000000
# b 60.000000
# c 64.333333
# d 113.000000
# e 64.333333
# f 64.333333
# g 64.333333
# h 64.333333
# i 64.333333
# Name: 数值, dtype: float64a1 = s1.to_numpy()
print(a1) # [10 40 5 90 35 40]
a2 = s2.to_numpy()
print(a2) # [10 20 23 90 35 40]
a3 = s3.to_numpy()
print(a3) # [ 20. 60. nan 113. nan nan nan nan nan]
print(a3[np.logical_not(np.isnan(a3))]) # [ 20. 60. 113.]
m = np.mean(a3[np.logical_not(np.isnan(a3))])
a4 = np.copy(a3)
a4[np.argwhere(np.isnan(a4))] = m
print(a4)
# [ 20. 60. 64.33333333 113. 64.33333333
# 64.33333333 64.33333333 64.33333333 64.33333333]
总结
我们通过实例从对象的创建、属性的获取、数据的访问以及常用函数等维度对比了 Numpy 的一维数组和 Pandas 的 Series 结构。很多知识都是相通的,多对比多总结就会对整个模块有更深入的了解。今天就到这里吧,See You。
后台回复「搜搜搜」,随机获取电子资源!
欢迎关注,请扫描二维码:


相关文章:

【Python】向函数传递任意数量的实参
传递任意数量的实参 有时候,你预先不知道函数需要接受多少个实参,好在Python允许函数从调用语句中收集任意数量的实参 def get_letter(*letters):for i in letters:print(i) get_letter(A,B,C,D,E)形参名*letters中的星号让Python创建一个名为letters的空…
word中插入下标
Word2007中为数字加上下标的几种方法: 一:通过插入>公式>>选择,通过此上下标。 二:写下数字,例如5,然后按ctrlshift号三个键,就可添加上标,按ctrl号两键,就可标…

手机应用软件测试的思路与要点
软件测试主要针对于移动互联网行业,那么APP等相关软件的测试工作是非常多的,尤其对于产品的手机项目(应用软件),主要是进行系统测试。针对手机应用软件的系统测试,通常从如下几个角度开展:功能测试,兼容性测…
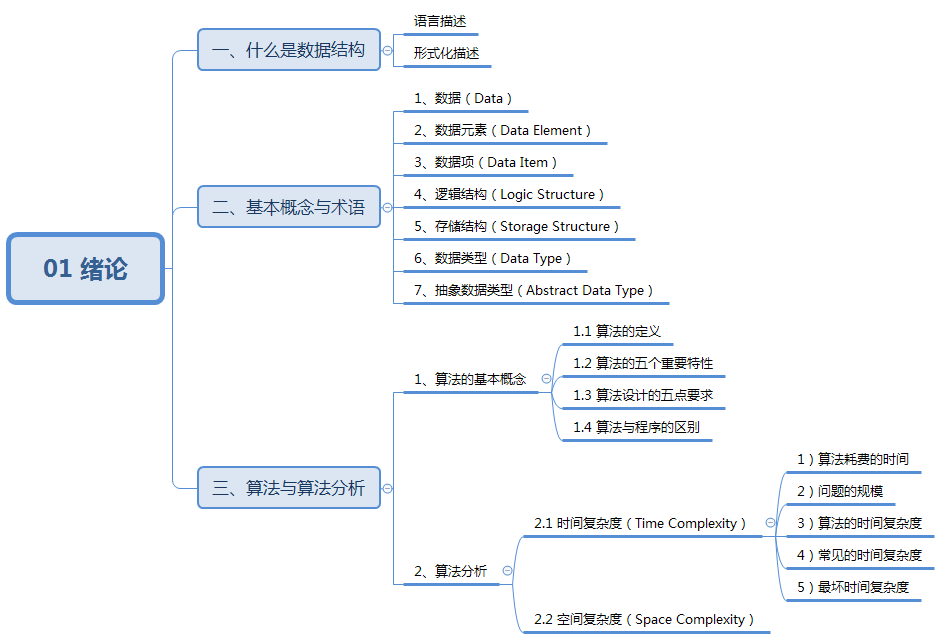
数据结构与算法:01 绪论
绪论 知识结构: 一、什么是数据结构 例1:电话号码薄的查询问题。 (a1,b1),(a2,b2),…,(an,bn)(a_1,b_1),(a_2,b_2),\dots,(a_n,b_n) (a1,b1),(a2,b2),…,(an,bn) aia_iai:表示姓名,bib_ibi:表示电话…
rar for linux缺少GLIBC_2.7
今天安装rar4.0 for linux,遇到了一个缺少GLIBC_2.7的问题,弄了好久才成功,记录一下,以备不时之需。 系统版本为CentOS 5.5。下载了rar4.0 for linux源码包,解压后,按照makfile文件的提示,进行安…
硅谷产学研的创新循环
在现代社会形态形成的几百年历史中,大学与产业界在分化的体制轨道中形成了各自不同的目标、结构和文化,有关大学与产业合作的种种争议无不缘自于此。今天当知识和技术逐步取代了自然资源和简单劳动力资源而成为首要的创造财富的源泉时,产业界…
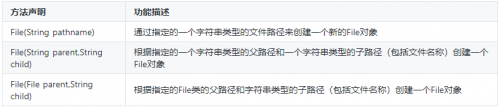
java技术培训之File类中常用的构造方法
File类用于封装一个路径,这个路径可以是从系统盘符开始的绝对路径,如:“D:\file\a.txt”,也可以是相对于当前目录而言的相对路径,如:“src\Hello.java”。File类内部封装的路径可以指向一个文件,…

数据结构与算法:02 C#语言基本语法结构
02 C#语言基本语法结构 知识结构: 1、数据类型 第一种分类: 简单数据类型:byte、short、int、long、float、double、char、bool组合数据类型:struct、enum、class、interface 类型描述byte无符号8位整型(ushort) short&#x…
积少成多 Flash(ActionScript 3.0 Flex 3.0) 系列文章索引
[源码下载]积少成多 Flash(ActionScript 3.0 & Flex 3.0) 系列文章索引作者:webabcdFlash 之 ActionScript 3.0 1、积少成多Flash(1) - ActionScript 3.0 基础之数据类型、操作符和流程控制语句介绍Flash ActionScript 3.0 中所有的数据类型都是对象,…

WPF Snoop 2.7 源码研究
转载于:https://www.cnblogs.com/puncha/archive/2012/04/01/3877001.html

java培训基础知识都学哪些
很多人都开始学习java技术,觉得java语言在未来的发展前景空间非常大,事实却是如此,那么针对于零基础的同学, 学习java技术需要学哪些呢?下面我们就来看看java培训基础知识都学哪些? java培训基础知识都学哪些? 1.JavaWeb Linux…
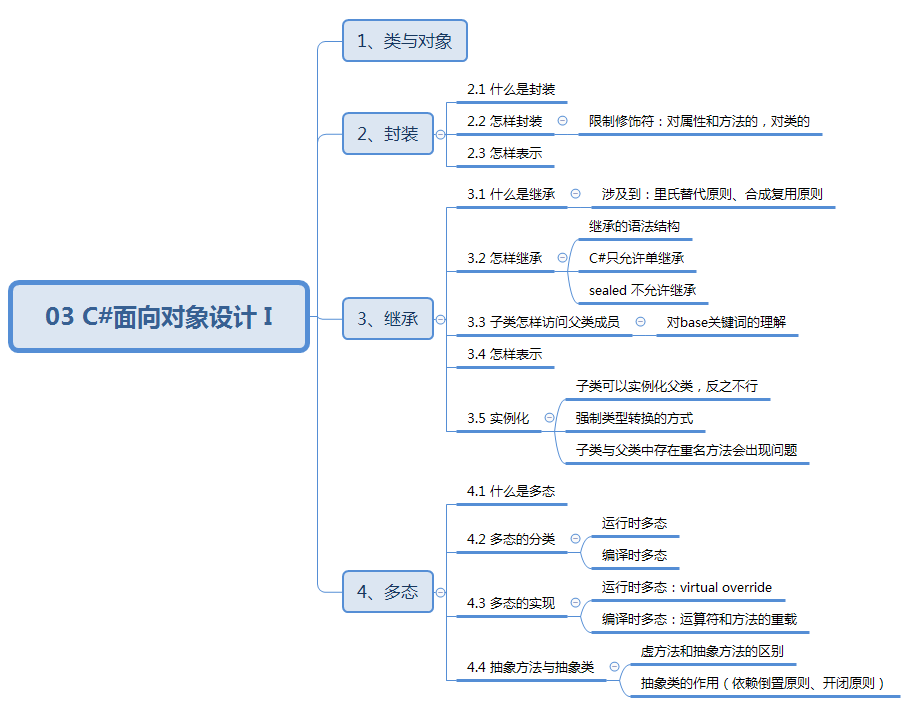
数据结构与算法:03 C#面向对象设计 I
03 C#面向对象设计 I 知识结构: 1、类与对象 类:用高级程序语言实现的一个ADT描述。对象:通过类声明的变量。 2、封装 2.1 什么是封装 把类的内部隐藏起来以防止外部看到内部的实现过程。 2.2 怎样封装 通过限制修饰符private、protect…
Centos7安装编译安装zabbix2.219及mariadb-5.5.46
mariadb-5.5.46的安装: 首先下载mariadb-5.5.46-linux-x86_64.tar.gz,然后使用tar -xf mariadb-5.5.46-linux-x86_64.tar.gz -C /usr/local目录下 添加数据库组 # groupadd mysql 添加数据库用户 # useradd -g mysql mysql cd /usr/local ln -sv…

软件测试开发:常见测试类型概念
软件测试是软件开发中非常重要的一个环节,软件测试工程师需要对每个环节进行严格把控,才能保证系统在每个阶段得以控制。下面小编就为大家详细介绍一下软件测试开发:常见测试类型概念的相关内容。 软件测试开发:常见测试类型概念: (1)边界测试…
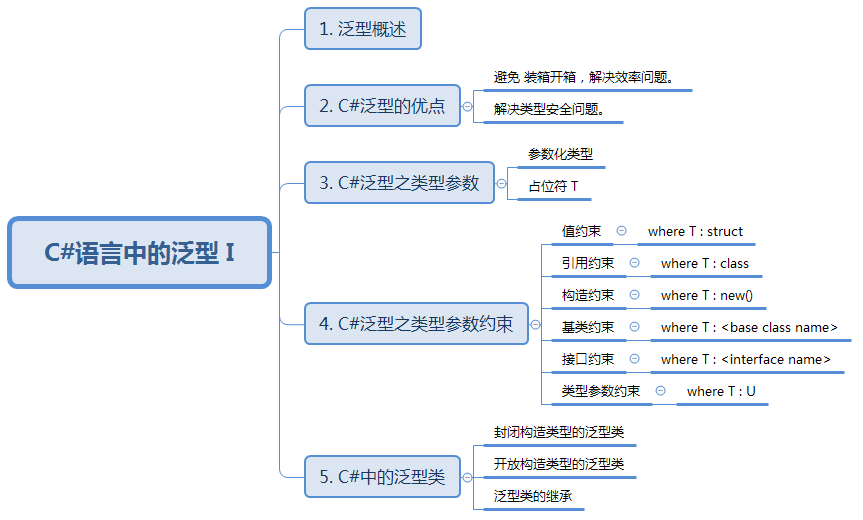
技术图文:C#语言中的泛型 I
C#语言中的泛型 I 知识结构: 1. 泛型概述 泛型广泛应用于容器(Collections)和对容器操作的方法中。 从 .NET Framework2.0 开始,微软提供了一个新的命名空间System.Collections.Generic,其中包含了一些新的基于泛型…
ubuntu搭建svn、git遇到的问题及解决办法
不错的git笔记博客: http://www.cnblogs.com/wanqieddy/category/406859.html http://blog.csdn.net/zxncvb/article/details/22153019 Git学习教程(六)Git日志 http://fsjoy.blog.51cto.com/318484/245261/ 图解git http://my.oschina.net/x…

webstorm同时打开多个project方法
曾经多次碰到过想要打开多个project的时候,可每次打开其他项目时,必须选择新窗口还是替换次窗口,如果新窗口的话就无法跟现在的项目在同一个webstorm中同时进行编辑,需要来回切换窗口,很是不方便,今天无意中…

什么业务场景适合使用Redis?
Redis(Remote Dictionary Server ),即远程字典服务,是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。从2010年3月15日起,Redis的开发工作由VMware主持。从2013年…
Linux基础知识汇总(2)...持续更新中
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566软件安装: {软件安装的几种形式 rpm 由厂商提供二进制包 yum rpm源的前端管理器 src 源码包configure安装 bin 包含rpm和shell将安装一步执…
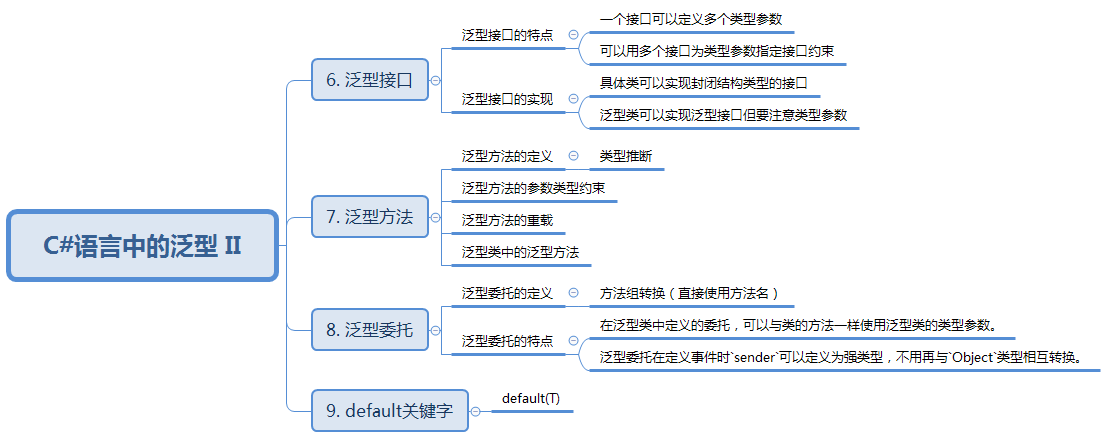
技术图文:C#语言中的泛型 II
C#语言中的泛型 II 知识结构: 6. 泛型接口 泛型类与泛型接口结合使用是很好的编程习惯,比如用IComparable<T>而非IComparable,以避免值类型上的装箱和拆箱操作。若将接口指定为类型参数的约束(接口约束)&#…
linux档案权限
Linux 下的档案当你对一个档案具有w权限时,你可以具有写入/编辑/新增/修改档案的内容的权限, 但并丌具备有删除该档案本身的权限!对二档案的rwx来说, 主要都是针对『档案的内容』而觊,不档案档名的存在不否没有关系喔&…

新手UI设计师需要掌握的知识和技能
UI设计岗位在近几年的需求是越来越高的,很多零基础学员都开始学习UI设计技术,那么想要成为一名合格的UI设计师,新手UI设计师需要掌握的知识和技能是比较要会的,来看看下面的详细介绍。 新手UI设计师需要掌握的知识和技能ÿ…
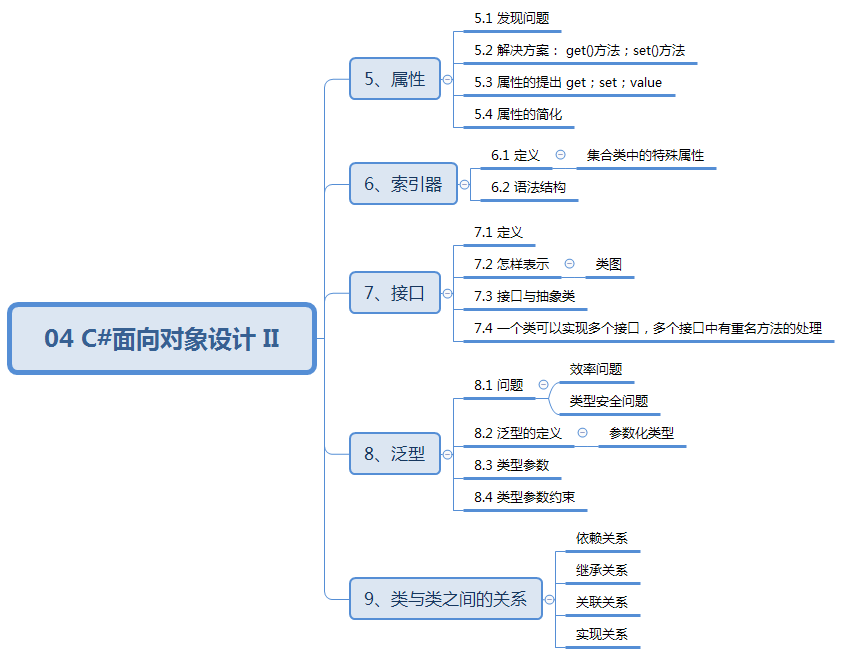
数据结构与算法:04 C#面向对象设计 II
04 C#面向对象设计 II 知识结构: 5、属性 例1:属性概念的引入(问题) public class Animal {public int Age;public double Weight;public bool Sex;public Animal(int age, double weight, bool sex){Age age;Weight weight;S…
SharePoint迁移和升级方案
这是之前针对SharePoint迁移和升级写的方案,去掉了敏感的部分,共大家交流吧。SharePointMigrationSolution转载于:https://www.cnblogs.com/zhaojunqi/archive/2012/04/12/2444803.html

零基础如何掌握web前端开发技能
很多零基础学员想要进入到互联网行业都会选择web前端做首选技术语言来学习,但是学习web前端不是那么容易的,想要成为一名合格的web前端工程师,所要掌握的技能一定要会,下面小编就为大家详细的介绍一下零基础如何掌握web前端开发技…
数据结构与算法:05 Leetcode同步练习(一)
Leetcode同步练习(一) 题目01:两数之和 题号:1难度:简单https://leetcode-cn.com/problems/two-sum/ 给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那 两个整数,…
用Asp.net实现简单的文字水印
经常看见MOP上有人贴那种动态的图片,就是把一个字符串作为参数传给一个动态网页,就会生成一个带有这个字符串的图片,这个叫做文字水印。像什么原来的熊猫系列,还有后来的大树和金条,都挺有意思。这东西看着挺好玩的&am…
yum国内镜像
Centos-7修改yum源为国内的yum源 国外地址yum源下载慢,下到一半就断了,就这个原因就修改它为国内yum源地址 国内也就是ali 与 网易 以centos7为例 ,以 修改为阿里的yum源 先确定有wget 备份本地yum源 mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo_…

HTML的标签分为哪几类?各标签语法格式是怎样的?
HTML的标签分为哪几类?各标签语法格式是怎样的?相信大家在学习HTML课程的时候,有讲到这方面的知识,根据标签的组成特点,通常将HTML标签分为两大类,分别是“双标签”、“单标签”,对它们的具体介绍如下。 1.双标签 双…

数据结构与算法:06 线性表
06 线性表 知识结构: 1. 线性表的定义与操作 1.1 线性表的定义 线性表(Linear List)是由n(n≥0)n (n≥0)n(n≥0)个相同类型的数据元素a0,a1,⋯,an−1a_0,a_1,⋯,a_{n-1}a0,a1,⋯,an−1组成的序列。即表中除首尾元素外,其…