SQL Server 2014新特性——基数评估(白皮书阅读笔记)
基数评估
目录
基数评估
说明
基数评估准确的重要性
模型假设
启用新的基数评估
验证基数评估的版本
在迁移到新的基数评估前要测试
校验基数评估
偏差问题
需要手动处理的变化
避免因为新的CE造成性能下降
SQL Server 2014中的修改
增加多个谓词的相关性的假设
修改超出统计信息范围的评估
Join评估算法修改
Join包含(Containment)假设的修改
不同值计数评估的变化
诊断输出
新基数评估的调优方法
修改数据库兼容级别
使用跟踪标记
基础调优方法
说明
查询优化器的目的是为了找出有效的执行计划,根据cost运算,取出cost最小的计划,作为执行计划。其中影响cost最重要的一项就是基数评估(估计行数)。SQL Server 2014对基数评估做了修改。
基数评估准确的重要性
基数评估提供以下信息:
1.响应行数评估(the distribution of data)
2.不同值个数评估(distinct value count)
3.重复值个数,作为上一级基数评估(duplicate count as input for parent operator estimation calculations)
基数评估是通过计算统计信息的出来的结果,而统计信息通过优化器创建或者通过索引创建。
统计信息分为:头,密度向量,直方图。
当统计信息存在的时候基数评估器使用密度向量和直方图来计算评估。
基数评估主要回答以下几个问题:
1.一个或多个谓词或过滤几行
2.2个表之间的连接谓词会过滤几行
3.预计一个指定列集合中有多少不同值(distinct value)
Sql server中有2种谓词:1.过滤谓词,2.连接谓词
基数评估(CE):试图回答where,join,having这些谓词的选择性。也试图回答group,distinct的不同值(distinct value)。
CE的计算从图形执行计划中是从右到左的,下一级的评估作为上一级计算评估的输入。

每个执行计划中的运算符都有评估值输入,这个值决定了优化器使用什么算法的操作符,同时也决定了最终的执行计划。所以如果评估出现偏差,会导致执行计划选择出现偏差,导致无法选出一个高效的执行计划。
评估出现偏差会出现以下结果:
如果评估过小:
1.原本可以使用并行计划更加有效的,现在使用串行计划
2.不合适的join算法
3.不合适的索引选择,和索引访问方法
如果评估过大:
1.原本使用串行计划更加有效,现在使用并行计划
2.不可合适的join算法
3.不合适的索引选择,和索引访问方法
4.过多的内存分配
5.内存浪费和没必要的并发
模型假设
内核有以下假设:
Independence:假设,在没有额外的相关信息之外,数据在不同的列是没有关联的
Uniformity:在统计信息的直方图的step,数据分布式均匀分布在step上的。
Containment: 2个表连接,那么高密度的一定被低密度的包含。
Inclusion:如果对一列对常数过滤,那么认为这个常数数据一定存在在这个列中。
启用新的基数评估
当数据库的兼容级别为120的时候,就是启用了新的基数评估,默认使用新的基数评估。
但是可以通过查询跟踪标记来指定:
2312:在兼容级别低于120的时候使用新的基数评估
9481:在兼容级别在120下,使用老的基数评估
验证基数评估的版本
可以从图形执行计划或者XML执行计划中找到CardinalityEstimationModelVersion,如果为120就是新的基数评估,70就是老的基数评估。
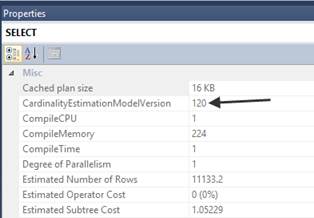
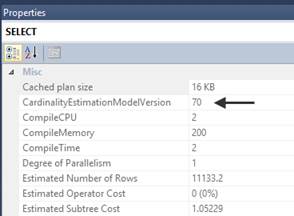
在迁移到新的基数评估前要测试
新的基数评估虽然总体提示了性能,但是对个别查询来说,会被影响,性能变差,所以要测试。
1.在类似生产环境下,测试大多数的负荷
2.可以先迁移到sql server 2014,但是使用不运行在120兼容级别
3.也可以到120兼容级别,但是在全局范围开9481跟踪标记
4.新建数据库推荐使用默认会使用120兼容级别。
校验基数评估
没有什么特别的就是通过实际值和评估值对个对比。
偏差问题
评估值偏差,是存在的,那么多少算是偏差太大了?其实没有一个固定的值,主要是看以下2点:
1.偏差是不是造成了资源过度使用
2.偏差是不是造成了特定查询的性能问题
如果任意一个出现问题的话,那么就能认为偏差太大了。
需要手动处理的变化
只有评估值变化的情况下,看性能是否下降超过预期,如果超过要进行手动干预。
如果评估值和老CE一样,并且计划没有什么变化,就不需要处理。
避免因为新的CE造成性能下降
1.能够从新基数评估得到性能优化的查询,就使用新基数评估,其他的进行重新调整。
2.有好处的查询使用新的基数评估,其他的使用跟踪标记9481
3.使用老的基数评估,特定的查询可以指定跟踪标记2312
4.直接调试有问题的sql
5.使用老的基数评估
SQL Server 2014中的修改
增加多个谓词的相关性的假设
在没有多列统计信息的情况下,SQL Server优化器会认为谓词之间是不相关的。
老的基数评估:各个谓词的选择度相乘
新的基数评估:选择度从低到高排序,然后使用以下公式:
修改超出统计信息范围的评估
如果超出统计信息范围,那么老的基数评估就认为不存在,评估行数为1。
新的基数评估会用,密度*总行数来当评估。
Join评估算法修改
简单Join
老的基数评估是以线性增长的方式一步一步对齐2个直方图。(根本不知道是怎么玩的)
新的基数评估,使用相对简单的join评估算法,只是用直方图的最大最小边界来对齐。(文章并没有给出详细的算法很坑爹)。
新的基数评估是用这种原则,很容易发现评估值不够准确。
多Join条件
多个join条件,对于老的基数评估来说,是独立的谓词,是用选择度相乘的方法来组合。
新的基数评估,是用2个不同值个数(distinct value count)中较小的一个,然后乘以2边的平均频率。(搞不懂)
Join带相等和不相等的谓词
老的基数评估,是独立的谓词,是用选择度相乘的方法来组合。
新的基数评估,认为大表小标多对1的关系。即大表中的一行,必定存在于表的一样与之对应。这个算法把大表的评估作为评估。(这个简单)
Join包含(Containment)假设的修改
如果是等值连接,那么就会假设这个列表2边都是存在的。如果存在join表上有非join谓词,老的基数评估那么会认为一些级别的相关,这种相关叫做简单包含(Simple Containment)。
老的基数评估的JOIN评估,假设在使用join谓词之前,任意存在的谓词会缩小直方图,而谓词之间是不相关的。老CE用这样的评估方式会让评估值偏大。
USE [AdventureWorks2012];
GO
SELECT [od].[SalesOrderID], [od].[SalesOrderDetailID]
FROM Sales.[SalesOrderDetail] AS [od]
INNER JOIN Production.[Product] AS [p]
ON [od].[ProductID] = [p].[ProductID]
WHERE [p].[Color] = 'Red' AND
[od].[ModifiedDate] = '2008-06-29 00:00:00.000'
OPTION (QUERYTRACEON 9481); -- CardinalityEstimationModelVersion 70

新的基数评估是使用基本包含(Base Containment),新的基数评估,是直接从基表上面获取选择度,而不是经过谓词过滤之后。

不同值计数评估的变化
对于新的基数评估和老的相比在多对多连接中,不同值计数评估相差很小。如果join条件会放大基数,老的基数评估可能会不准确。
新的基数评估根据join谓词和非join谓词选择不同值。新的基数评估使用环境基数(ambient cardinality),环境基数是group by或者distinct列的最小不同值集合(The new CE uses “ambient cardinality”, which is the cardinality of the smallest set of joins that contains the GROUP BY or DISTINCT columns.)。
诊断输出
使用新的xevent,query_optimizer_estimate_cardinality来输出
CREATE EVENT SESSION [CardinalityEstimate] ON SERVER
ADD EVENT sqlserver.query_optimizer_estimate_cardinality
ADD TARGET package0.event_file( SET filename = N'S:\CE\CE_Data.xel' ,
max_rollover_files =( 2 ) )
WITH ( MAX_MEMORY = 4096 KB ,
EVENT_RETENTION_MODE = ALLOW_SINGLE_EVENT_LOSS ,
MAX_DISPATCH_LATENCY = 30 SECONDS ,
STARTUP_STATE = OFF );
GO
-- Start the session
ALTER EVENT SESSION [CardinalityEstimate] ON SERVER STATE=START;
--
-- Your workload to be analyzed executed here (or in another session)
--
-- Stop the session after the workload is executed
ALTER EVENT SESSION [CardinalityEstimate] ON SERVER STATE=STOP;
也可以使用A first look at the query_optimizer_estimate_cardinality XE event中的方法。
新基数评估的调优方法
修改数据库兼容级别
如果新的CE出现性能问题,可以通过修改兼容级别回到以前的CE版本。
使用跟踪标记
可以使用QUERYTRACEON来使用查询级别选项,这个跟踪标记会影响一个语句的CE级别。
基础调优方法
统计信息丢失
统计信息丢失,但是没有及时创建,应该查看是否启用了统计信息自动创建选项。
统计信息过期
统计信息可能太老,导致查询性能问题,考虑是否要手动跟新统计信息。
统计信息采样率
表如果数据分布不均衡,无法在直方图上表现,看看统计信息头中的rows sampled和rows的差距,可以考虑使用调整采样率或者直接fullscan。
过滤统计信息(filtered statistics)
对于大的表存在数据不均衡,过滤统计信息可以很好的解决这个问题。
注意点:过滤统计信息的更新阀值是基于表的,而不是过滤谓词。
在没有recompile提示之下,过滤索引和过滤统计信息不会被应用到参数化的字段过滤。(In the absence of a RECOMPILE hint, filtered indexes and statistics will not be used in conjunction with parameterization that refers to the filter column.)。
多列统计信息
自动创建统计信息,只会创建单列的,多列统计信息是手工创建的,创建多列统计信息可以提高评估的准确性。提高查询性能。
参数敏感性(Parameter Sensitivity)
参数敏感性是因为数据分布不均衡,参数化的执行计划会以第一次运行的时候的参数来创建,如果数据不均衡,参数变化,会导致执行计划不是很理想的状况。可以加上OPTIMIZE FOR或者RECOPILE来解决。
表变量
在SQL Server 2014上面表变量没有相关的统计信息的,如果要在表变量上存大量的数据建议使用临时表。
多语句用户定义表变量函数
和表变量差不多,多语句表变量函数也没有统计信息,只是用一个固定的基数100。考虑使用内联表变量函数。
内联表变量函数式没有函数体的,直接return 一个表
而多语句表变量函数式有函数体的。
XML Reader表变量函数操作
使用nodes() XQUERY方法如果没有XML索引,会导致很烂的评估,因为XML索引可以带统计信息。解决这个问题的方法是在XML列上加上XML索引。
数据类型转化
如果谓词数据类型,不对会导致数据类型转化,这样也会导致基数评估不准确,是因为列的统计信息无法使用了。
Intra-column比较
Cardinality estimate issues can occur when performing comparisons between columns in the same table. If this is an issue, consider creating computed columns. The computed column can then be referenced in a filter predicate. You can automatically generate the computed column’s associated statistics (by activating automatic statistics creation at the database level) to improve overall estimates. If intra-table column comparison cardinality estimation is a frequent issue, consider normalization techniques (separate tables), derived tables, or common table expressions.
查询提示
尽量避免使用查询提示,查询提示会覆盖优化器的选择,对于某些情况可能会导致更烂的性能。
分布式查询
当通过连接服务器查询数据的时候,如果没有权限访问统计信息的话,会导致查询性能很烂。
在使用前先确定访问统计信息需要多大的权限。
递归CTE
递归CTE也有评估偏差问题,可以看Optimize Recursive CTE Query.
谓词复杂性
避免在谓词列上使用函数或者表达式,这个没啥好说,严重影响性能。
查询复制性
复制的查询也会让评估带来偏差,评估本来就是不准确的,来回怎么倒腾就更加不准确了,应该简化查询。
本文转自 Fanr_Zh 博客园博客,原文链接:http://www.cnblogs.com/Amaranthus/p/3678647.html,如需转载请自行联系原作者
相关文章:

【直播】张晋:心跳信号分类模型融合
心跳信号分类模型融合 目前 Datawhale第23期组队学习 正在如火如荼的进行中。为了大家更好的学习,零基础入门数据挖掘(心跳信号分类) 的课程设计者张晋,将为大家带来一场直播分享——心跳信号分类模型融合。 直播信息 主讲人&am…

无密码SSH配置
由于Hadoop和以后用到的Git分布式版本控制都用到了SSH,故这里把无密码登录的SSH的配置过程记录下: 1. 首先切换到想要使用ssh的用户下,不一定是root用户 2. ssh-keygen –t rsa –P ‘’ (这个用来产生id_rsa.pub和id_rsa…

学Java技术,这些问题要避免
参加java培训学习java技术不是一朝一夕就能学会的事情,在学习的过程中还要注意学习方式,有一些错误是要避免的,下面我们就为大家详细的介绍一下学java技术要避免哪些问题? Java培训分享:学Java技术,这些问题要避免 1.…

Activity悬浮并可拖动(访悬浮歌词)
强烈推荐: 最无私的Android资料(书籍代码)分享-不要积分(求置顶)http://www.eoeandroid.com/thread-80891-1-1.html 大量项目源码分享http://www.eoeandroid.com/thread-162339-1-1.html 基于Android系统的影音播放器开…

实现单向访问控制
[Router]acl 3000 match-order auto //配置acl 3000[Router-acl3000]rule 1 deny icmp source 192.168.10.30 0.0.0.0 destination 192.168.10.20 0.0.0.0 icmp-type echo // 禁止主机PC2 ping主机PC1。[Router-acl3000]rule 2 deny tcp source 192.168.10.30 0.0.0.0 destin…

【直播】鱼佬:数据挖掘师之路(河北高校数据挖掘邀请赛)
数据挖掘师之路 目前 河北高校数据挖掘邀请赛 正在如火如荼的进行中。为了大家更好的参赛,王茂霖分享了 从0梳理1场数据挖掘赛事!,完整梳理了从环境准备、数据读取、数据分析、特征工程到数据建模的整个过程。03月28日晚,王贺也为…

Python培训班线上线下哪种靠谱
Python近几年在人工智能领域的快速发展,引起了很多人的注意,各种Python培训机构也越来越多,很多零基础的同学都想通过报培训班学习,目前互联网的发达,Python培训分为线上和线下,那么Python培训班线上线下哪…
3-openstack之keystone上
3.1 keystone 安装linux-node1上面 3.2 配置源 12http://mirrors.aliyun.com/centos/7.2.1511/cloud/x86_64/openstack-newton/centos-release-openstack-newton-1-1.el7.noarch.rpm yumlocalinstall -y centos-release-openstack-newton-1-1.el7.noarch.rpm安装:…
全面认识一下.NET 4.0的缓存功能
很多关于.NET 4.0新特性的介绍,缓存功能的增强肯定是不会被忽略的一个重要亮点。在很多文档中都会介绍到在.NET 4.0中,缓存功能的增强主要是在扩展性方面做了改进,改变了原来只能利用内存进行缓存的局限,允许用户在不改变代码的情…

【直播】王茂霖:二手车交易价格预测 Baseline 提高(河北高校数据挖掘邀请赛)
二手车交易价格预测 Baseline 提高 目前 河北高校数据挖掘邀请赛 正在如火如荼的进行中。为了大家更好的参赛,王茂霖分享了 从0梳理1场数据挖掘赛事!,完整梳理了从环境准备、数据读取、数据分析、特征工程到数据建模的整个过程。04月01日晚&a…

java培训要学习多久?
java技术要学习的内容有很多,那么究竟java培训要学习多久?这是很多同学都比较关注的一个问题,首先我们来详细的了解一下java培训的学习路线都有哪些,具体要花多少时间学习吧。 java培训要学习多久? 1.Java语言介绍 从基础语法、面向对…
数据库范式温习
简介 关系数据库中的关系必须满足一定的要求,即满足不同的范式。 目前关系数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、第四范式(4NF)、…
使用 git 管理 portage tree
安装 git.备份原来的 portage tree.克隆 funtoo.cd /usr && rm -rf portage && git clone git://github.com/funtoo/portage.git 仓库中有gentoo.org, funtoo.org, master三个分支. 分支 gentoo.org 就是 gentoo 的官方 portage tree, 只不过是由 Daniel Robb…
02 Scratch等级考试(二级)模拟题
青少年编程竞赛交流群已成立(适合6至18周岁的青少年),公众号后台回复【Scratch】或【Python】,即可进入。如果加入了之前的社群不需要重复加入。 微信后台回复“资料下载”可获取以往学习的材料(视频、代码、文档&…

怎样找到适合自己的UI设计培训班
UI设计这个行业近几年有越来越多的人都比较关注,市面上的UI设计培训机构也越来越多,很多零基础同学都在寻找适合自己的UI设计培训机构,那么怎样找到适合自己的UI设计培训班呢?来 怎样找到适合自己的UI设计培训班? 一、看课程内容 UI设计行业…
Global.asax详解
在网上找了N多相关的东西总说的不够细,现在终于找到了.可以了解web.cofig和Global.asax之间的关系以及执行的顺序. 在Global.asax.cs文件中 protected void Application_BeginRequest(Object sender, EventArgs e){ Application["StartTime"] System.DateTime.Now…
Openfire服务器的安装部署
Openfire是一个强大的即时消息(IM)和聊天服务器,它实现了XMPP协议,可以使用它轻易的构建高效率的即时通信服务器. 其安装和部署都十分简单,并利用Web进行管理。单台服务器可支持上万并发用户,由于是采用开放的XMPP协议…

【直播】耿远昊:Pandas入门讲解(安泰第四届数据科学训练营)
Pandas入门讲解 直播信息 主讲人:耿远昊,Datawhale成员,joyful-pandas作者。 直播时间:2021年04月07日 20:00~21:00 直播内容: 时间序列中的必知必会:深入理解时间对象掌握滑动窗口熟悉重采样操作 直播…

女生参加软件测试培训合适吗
女生参加软件测试培训合适吗?这个问题困扰着很多女性朋友,大部分女性觉得软件测试属于IT技术行业,学起来是比较麻烦的,不知道是否适合女性,我们来看看下面的详细介绍。 女生参加软件测试培训合适吗?当然合适,如果说要…
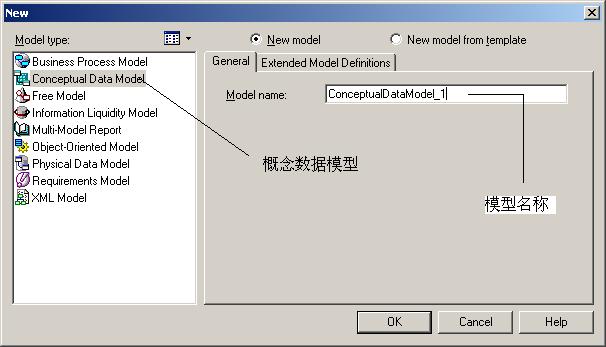
三、概念数据模型CDM(Conceptual Database Model )
最后整理一下正确的是: 脚本1: .set_value(_First, true, new) .foreach_part(%Name%, "#") .if (%_First%) .delete(%CurrentPart%) .enddelete.set_value(_First, false, update) .else %CurrentPart% .endif .next 这个例子是把Name内容的…
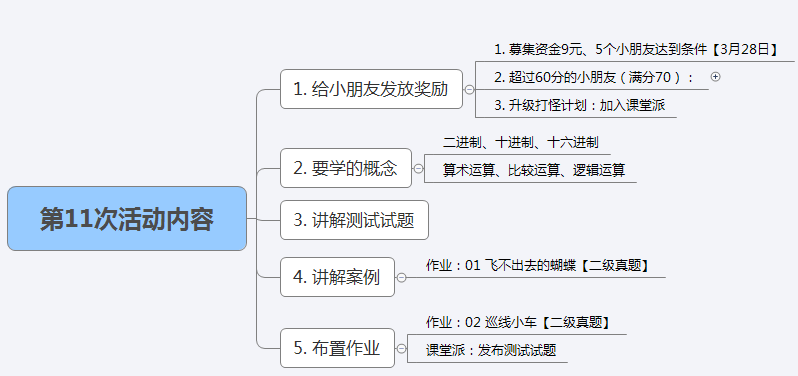
【第11周复盘】小朋友们 100% 闯关成功!
「青少年编程竞赛交流群」已成立(适合6至18周岁的青少年),公众号后台回复【Scratch】或【Python】,即可进入。如果加入了之前的社群不需要重复加入。 微信后台回复“资料下载”可获取以往学习的材料(视频、代码、文档&…
keepalived and heartbeat
Keepalived使用的vrrp协议方式,虚拟路由冗余协议 (Virtual Router Redundancy Protocol,简称VRRP);Heartbeat是基于主机或网络的服务的高可用方式;keepalived的目的是模拟路由器的双机heartbeat的目的是用户service的双机lvs的高可…

ui设计师要养成哪些职场习惯呢?
很多参加UI设计培训学完后的同学,都比较担心后期找工作的问题,不知道自己在职场中应该如何应对,小编本期为大家详细的介绍一下ui设计师要养成哪些职场习惯呢?希望能够帮助到大家在职场中更好的表现。 UI设计培训分享:ui设计师要养…
Html-Css 从入门到放弃(一)基础知识
注意要点: 1、ID属性不要以数字开头,数字开头的ID在 Mozilla/Firefox 浏览器中不起作用。 2、class 选择器用于描述一组元素的样式,class 选择器有别于id选择器,class可以在多个元素中使用。 3、不要在属性值与单位之间留有空格。…
六一:如何在Datawhale开源学习小程序中管
我们的组队学习马上就要开营了,本次组队学习与以往不同的是小程序中增加了队伍管理的功能。 为了方便大家组队,Datawhale的 六一同学 为大家准备了在Datawhale开源学习小程序中队伍管理的教程。 一、进入课程详情界面 1、打开小程序主页后,…
C#让windows程序只运行一次
方法一:使用Mutex来进行1.首先要添加如下的namespace: using System.Threading;2.修改系统Main函数,大致如下: bool bCreatedNew;//Create a new mutex using specific mutex nameMutex m new Mutex(…

java培训分享:学习Java需要什么软件
在参加java培训过程中学习java技术,需要用到很多辅助工具,这些辅助工具是具有多功能性和实用性的,从代码构建到bug压缩。学习这些工具可以帮助您提高代码的质量,并成为一个更高效的Java开发人员。那么具体学习Java需要什么软件呢?…
J2SE基础夯实系列之数组
java中经常使用的是数组,前一段时间突然忘记了怎么定义char类型的二位数组: char[][] c {{},{},{A,B,C},{D,E,F},{G,H,I},{J,K,L},{M,N,O},{P,Q,R,S},{T,U,V},{W,X,Y,Z},};这个是char型的二维数组,思考一下,如果是定义String的二…

【组队学习】【24期】Datawhale组队学习内容介绍
第24期 Datawhale 组队学习活动马上就要开始啦! 本次组队学习的内容为: 零基础入门语音识别(食物声音识别)Docker教程数据挖掘实践(智慧海洋)集成学习(中)河北邀请赛(二…
centos5.6 (64bit)编译安装vsftpd-2.3.4的配置(两种用户登录)[连载之电子商务系统架构]...
centos5.6 (64bit)编译安装vsftpd-2.3.4的配置(两种用户登录)出处:http://jimmyli.blog.51cto.com/我站在巨人肩膀上Jimmy Li 作者:Jimmy Li关键词:电子商务,系统架构,vsftpd,本地用户登录,虚拟…