袁永福 2008-5-15
系列课程说明![]() 为了让大家更深入的了解和使用C#,我们将开始这一系列的主题为“C#发现之旅”的技术讲座。考虑到各位大多是进行WEB数据库开发的,而所谓发现就是发现我们所不熟悉的领域,因此本系列讲座内容将是C#在WEB数据库开发以外的应用。目前规划的主要内容是图形开发和XML开发,并计划编排了多个课程。在未来的C#发现之旅中,我们按照由浅入深,循序渐进的步骤,一起探索和发现C#的其他未知的领域,更深入的理解和掌握使用C#进行软件开发,拓宽我们的视野,增强我们的软件开发综合能力。
为了让大家更深入的了解和使用C#,我们将开始这一系列的主题为“C#发现之旅”的技术讲座。考虑到各位大多是进行WEB数据库开发的,而所谓发现就是发现我们所不熟悉的领域,因此本系列讲座内容将是C#在WEB数据库开发以外的应用。目前规划的主要内容是图形开发和XML开发,并计划编排了多个课程。在未来的C#发现之旅中,我们按照由浅入深,循序渐进的步骤,一起探索和发现C#的其他未知的领域,更深入的理解和掌握使用C#进行软件开发,拓宽我们的视野,增强我们的软件开发综合能力。
本系列课程配套的演示代码下载地址为 http://files.cnblogs.com/xdesigner/cs_discovery.zip 。
本系列课程已发布的文章有
C#发现之旅第一讲 C#-XML开发
C#发现之旅第二讲 C#-XSLT开发
C#发现之旅第三讲 使用C#开发基于XSLT的代码生成器
C#发现之旅第四讲 Windows图形开发入门
C#发现之旅第五讲 图形开发基础篇
C#发现之旅第六讲 C#图形开发中级篇
C#发现之旅第七讲 C#图形开发高级篇
C#发现之旅第八讲 ASP.NET图形开发带超链接的饼图
C#发现之旅第九讲 ASP.NET验证码技术
C#发现之旅第十讲 文档对象模型
本课程介绍了使用C#进行XML开发。重点介绍使用System.Xml名称空间来读取,保存和处理XML文档。
XML介绍 XML基础规范XML全名是可扩展标记语言,是W3C国际标准组织规定的一种基于文本的数据存储格式,它是从IBM的SGML技术派生的,HTML也是从SGML派生的。SGML内容非常复杂,而XML使用了SGML的20%的语法实现了SGML的80%的功能。
从软件开发人员的角度看, XML语法主要有
- XML是国际标准,绝大部分软件厂商,开发工具和编程语言都支持相同的基本XML规范。XML文档可用于任何开发平台上,这是XML技术最大的优势。相对来说,JAVA这种非国际标准的技术跨平台则是不太容易的。
- XML是基于纯文本的,XML文档中是不能包含二进制数据。而且存储文件时会涉及到文本编码格式的问题。
- XML文件具有层次结构,其中使用一对尖括号来定义一个XML元素,一个XML元素可以包含若干个属性,而XML元素下面可以包含若干个子XML节点。
- 一个XML文档只能而且必须定义一个根元素,不可多定义,也不能不定义。
- XML元素不能错乱套嵌定义,比如“<a><b></a></b>”是错误的XML文档。
- XML格式是为了各系统交流数据而设计的,其设计过程考虑了方便的数据的临时存储和交流,而不考虑数据的长期存储,因此XML文档比较冗余,文件体积大,因此不适合存储大数据量,网络传输效率低。在软件开发中需要注意到这个问题。
XPath是W3C国际标准组织提出的在一个XML文档中快速检索和定位XML节点的标准。关于它将在下节课程详细介绍。
XSLTXSLT也是W3C国际标准组织在XML标准的基础上提出的XML文档转换的标准,它是一种非常重要的XML应用,它也是跨平台的,受到众多软件厂商的支持。在下节课程将详细介绍XSLT。
W3C此处多次提到W3C国际标准组织,那么到底什么是W3C国际标准组织呢?
W3C是大部分软件企业联合起来制定某些重要软件业标准的国际组织。它的成员包括微软,IBM,SUN等软件巨头。它制定和维护了HTML,XHTML,HTTP,XML,VML,XPath,XForm等软件行业内重要的标准,绝大多数软件厂商都支持W3C制定的标准,它制定的标准是真正的跨平台的全球通用的。因此它对全球软件业界,尤其是WEB软件业界有着巨大的影响。它的网址是 http://www.w3c.org/,在它的网站上可以看到它所制定的上百个标准。大家若要开发具有国际水平的WEB应用系统,应当要好好学习W3C的某些标准。
国际标准的意义在这里说明一下国际标准的意义。
所谓国际标准就是某个权威的非营利性的国际组织,其立场中立,不代表某个具体的公司,而是代表整个业界。它针对某项普遍使用的技术出台一些规范和标准。而各个具体的软件厂商在运用这项技术时自觉遵守这套国际标准。这样能方便各个系统之间交流数据,保障异构系统进行集成,并保持数据结构的长期稳定性和兼容性。这样的国际组织有ISO,ECMA和W3C等等。
我们使用到的一些技术都已经成为国际标准,例如SQL,JavaScript,C#,HTML,XML,XSLT,HTTP等很多技术。
国际标准具有一些特点,首先是稳定性和连贯性,国际标准一旦正式发布,就保持了相当的稳定性,其内容只能慎重的增加而不能删减,国际标准组织不会轻易修改已经正式发布的国际标准,而且在修改标准时会充分考虑到各种因素,保证向上和向下的兼容性,能最大程度的保障业界在旧标准上的投资。而且这些国际组织发布国际标准时有时会事先提出标准的修订计划。
其次国际标准是全球业界都遵守的,虽然没有强制遵守的机制,但绝大多数软件厂商都会遵守或者努力遵守这些国际标准。而且国际标准组织的成员有很多大软件厂商,比如W3C的成员就有微软,IBM,SUN等大公司。因此国际标准是代表了最广大软件业界的根本利益,代表了最先进的软件生产力。
对于应用软件开发商,充分的运用国际标准能很大程度的保护客户在IT系统上的投资。由于国际标准具有相当的稳定性和连贯性,若客户IT系统充分的使用了这些国际标准,则在升级到新标准时能获得很好的兼容性。IT系统不用推倒重来,这样能保护客户在已有系统上的投资。
作为软件开发人员,也应当了解这些国际标准,首先是能比较容易的实现异构系统的集成,并能获得比较好的系统兼容性和可维护性。而且软件开发人员在切换开发平台,比如从Java转移到.NET平台上时,以前学习国际标准的投资就会得到保护,而遵守相同标准的源代码的移植和翻译也是低成本的。
DOT.NET框架对XML的支持.NET框架提供了对XML的强大支持,而且.NET框架本身也普遍采用XML格式来存储各种配置信息。比如web.config文件。
在.NET类库中,名称空间System.Xml下面就包含了大量的操作XML文档的类型。这些类型构成了两种XML文档的处理模型。
流式处理模型在流式处理模型中,我们将XML文档做作一个数据流来进行处理,我们将逐个处理XML文档中的数据,在这种模型下,我们可以只读的快速读取大体积的XML文档,而且内存占用少,程序性能好。类型System.Xml.XmlReader就提供了流式处理模型,使用XmlReader就可以快速读取XML文档。
使用流式处理模型是有缺点的,首先是它只能读取XML文档,不能修改XML文档;其次是检索XML文档内容不方便,不能使用XPath技术;而且编程接口比较简单,处理XML文档不够方便。当程序需要比较简单的从XML文档读取数据则可以采用流式处理模型。
DOM处理模型在DOM处理模型中,我们首先是使用文档对象模型的思想解析整个XML文档,在内存中生成一个对象树来表述XML文档。比如使用一个XmlElement对象来影射到XML文档中的一个元素,使用XmlAttribute对象来影射到XML文档中的一个属性。这样我们编程操作内存中的对象就影射为操作XML文档。
使用DOM处理XML文档具有相当大的优点,首先是处理方便,我们可以使用各种编程技巧来处理XML文档对象树状结构,比如可以递归遍历XML文档的一部分或全部,可以向树状结构插入,修改或删除XML元素,可以设置XML元素的属性。
在DOM模式下,我们可以使用XPath技术在XML文档树状结构中进行快速检索和定位,这为处理XML文档带来比较大的方便。
在C#中,我们可以很简单的使用DOM方式处理XML文档。我们首先实例化一个System.Xml.XmlDocument类型,调用它的Load方法既可加载XML文档并生成XML节点对象树状结构,然后我们就可以遍历这个对象树,新增修改和删除节点,而且其中的任意一个节点都可以使用SelectNodes或SelectSingleNode方法通过XPath相对路径快速查找其它的节点。
在名称空间System.Xml下面大部分类型都是用来支持DOM处理模型的。其中很多类型配合起来共同组织成XMLDOM,XMLDOM是一种很典型的文档对象模型的应用。文档对象模型是一种比较高级的软件设计模式,我会在今后的课程中详细介绍文档对象模型这种软件设计模式。
 System.Xml名称空间下的支持DOM的类型主要有
System.Xml名称空间下的支持DOM的类型主要有
XmlNode 是DOM结构中的所有类型的基础类型,它定义了所有XML节点的通用属性和方法,是XMLDOM的基础。它具有一个ChildNodes属性,表示它所包含的子XML节点。
XmlAttribute 表示XML属性,它只保存在XmlElement的Attributes 列表中。
XmlDocument表示XML文档本身,是XMLDOM模型中的顶级对象,它用于对XML文档进行整体的控制,并且是其它程序访问XML文档对象树的唯一入口。
XmlLinkedNode在XmlNode的基础上实现了访问前后同级节点的方法。
XmlElement元素表示XML元素。是XMLDOM中使用最多的对象类型。它具有Attributes属性可以处理它所拥有的属性,可以使用ChildNodes属性获得它所有的子节点。并提供了一些添加和删除子节点的方法。
XmlCharacterData表示XML文档中的字符数据的基础类型。字符文本数据是分布在各个XMLElement之间的纯文本数据。XmlAttribute中的文本数据是不属于XML文本块的。
XmlCDataSection 表示XML文档中CData节,CData数据是采用”<![CDATA[ ]]>”包括起来的纯文本数据。由于XML采用尖括号进行标记,因此具有和HTML类似的转义字符,在一般的XML纯文本段中若遇到尖括号等特殊字符时需要使用转义字符,当文本段中包含大量的这类特殊字符时,手工书写和察看XML文档将比较困难,为了改善XML文档的可读性,在此可以使用CDATA节。在CDATA节中,所有的字符,包括特殊字符都不需要转义,这样察看和修改XML文档都比较方便。
XmlComment表示一段注释,XML注释和HTML注释一样,使用一对”<!-- -->”来包含起来。
XmlText表示一段纯文本数据。
XmlWhitespace表示XML文档中一段纯粹由空白字符组成的文本块,空白字符包括空格,制表符,换行和回车符,全角空格不属于空白字符。XmlDocument在解析XML文档时会处理空白字符,当XmlDocument对象的PreserveWhiitespace属性为true时,会为XML文档中的纯空白文本块生成XmlWhitespace对象,若该属性为false时,则会忽略掉纯空白文本,不会生成XmlWhitespace对象,好像原始的XML文档中不存在这样的空白文本块一样。
其它处理模型除了流式处理模型和DOM处理模型外,还存在一些比较另类的使用比较少的处理模型,在此简单介绍一下
DBDOM
DBDOM是一种基于数据库的XML文档处理模型,它是一个开源项目。它采用大量的存储过程和数据库操作,将一个个XML元素,XML属性等信息保存到数据库的字段中。使用关系型数据库来模拟实现XML的树状结构。我对这个模型也不甚了解,只是知道大概的原理。
BinaryXML
DOM方式处理XML文档是需要消耗大量的内存的,在处理大型XML文档时,DOM方式会比较大的影响应用系统的性能的。为此有人开始提出BinaryXML的处理模型。在这个模型中,XML文档是当作二进制数据加载到内存中,然后解析文档,使用大量的指针来指向XML文档中的关键位置,通过指针可以快速定位XML文档,能修改XML文档,并能提供类似DOM的编程接口。这种方式能大大节省内存,所消耗的内存仅比XML文件大小稍微大些。但实际运行效果我也不清楚。
XML对WEB开发的意义XML技术对WEB开发具有重大意义。若要开发高水平的WEB系统,应当好好使用XML技术。
XML和HTMLXML和HTML都源自SGML,具有相同的来源,而且两者都是采用尖括号的标记语言,两者具有很大的相似性。使用XML完全可以模拟出HTML,而且W3C提出了现代WEB站点应当采用的XHTML标准就是XML和HTML的结合。
在使用ASP.NET开发WEB系统中,除了使用ASP.NET控件展示数据外,还需要由程序拼凑出大量的HTML代码来展现数据。简单的进行字符串连接操作来生成HTML页面不是一种可持续性的软件开发和维护的过程。程序代码很容易杂乱无章,生成的HTML代码可读性不好。若在生成HTML代码的过程借鉴XML技术则有助于改善这种问题,从而能更好的控制WEB软件的开发过程,提高软件质量。
XML和WebServiceWebService基础就是XML,WebService的原理是将编程对象序列化成一个XML文档,然后通过HTTP协议传递给客户端,客户端接受这个XML文档,通过反序列化重现编程对象。因此WebService的基础就是XML序列化技术。在开发和调试稍微复杂的WebService是需要一定的XML技术基础。
Ajax技术的底层也是使用XML来传递数据的,可以看作一种特殊的WebService。可以这样比喻,WebService是WEB系统的公开方法,而Ajax则是私有方法。
XML/XSLT提供一种全新的开发模式XML/XSLT两项技术的配合可以提供一种全新的WEB系统开发模式。在这种模式下,页面将需要显示的纯粹的数据组织生成一个XML文档,并配上XSL转换信息头,然后发送到客户端,在客户端IE浏览器接受解析XML文档,根据其中的XSL转换头信息再下载XSLT文档,执行XSLT转换,然后才显示转换的结果。此时WEB页面既能正常的使用指定的格式显示数据,而且本身就是一个可供其它程序调用的WebService。该页面的输出的源代码就是XML文档,而且只有IE等浏览器类型软件才处理XSLT转换信息头,其他程序是会忽略掉这个信息的。此时页面具有双重功能,便于代码的集成开发和维护。
关于XSLT下节课程将详细介绍。
使用C#输出XML接下来我们将使用C#进行实际的XML开发,由于XML技术对WEB开发特别有用,因此将使用ASP.NET来演示使用C#进行XML开发。此处演示程序已经写好,现在对程序代码进行详细说明。
本程序是一个ASP.NET程序,大家获得程序代码后要在IIS中设置虚拟目录,由于程序还需要访问程序目录下的一些文件,因此还需要进行一些权限的配置。程序目录下的 demomdb.mdb 是程序使用的数据库文件。
网站配置完毕后,我们在浏览器中输入网站的地址即可打开它的默认页面。可以看到默认页面上有些程序内容的简单说明。
首先我们看看 recordxml.aspx 页面,我们看看 recordxml.aspx 的 HTML页面代码,可以看到该页面HTML代码很简单,只有一行。因此该页面的所有内容都是用C#代码生成的。
我们切换到该页面的C#代码,可以看到在 Page_Load 函数里面添加了代码输出页面内容。代码内容为
| // 此处使用 XmlTextWriter 来快速输出XML文档内容.不构造XML文档对象结构 this.Response.ContentEncoding = System.Text.Encoding.GetEncoding( 936 ); this.Response.ContentType = "text/xml"; // 连接数据库 using( System.Data.OleDb.OleDbConnection conn = new System.Data.OleDb.OleDbConnection()) { conn.ConnectionString = @"Provider=Microsoft.Jet.OLEDB.4.0;Data Source=" + this.Server.MapPath("demomdb.mdb"); conn.Open(); // 查询数据库 using( System.Data.OleDb.OleDbCommand cmd = conn.CreateCommand()) { cmd.CommandText = "Select * From Customers"; System.Data.OleDb.OleDbDataReader reader = cmd.ExecuteReader(); // 获得所有字段名 int FieldCount = reader.FieldCount ; string[] FieldNames = new string[ FieldCount ] ; for( int iCount = 0 ; iCount < FieldCount ; iCount ++ ) { FieldNames[ iCount ] = reader.GetName( iCount ); } // 生成一个XML文档书写器 System.Xml.XmlTextWriter xmlwriter = new System.Xml.XmlTextWriter( this.Response.Output ); xmlwriter.Indentation = 3 ; xmlwriter.IndentChar = ' '; xmlwriter.Formatting = System.Xml.Formatting.Indented ; // 开始输出XML文档 xmlwriter.WriteStartDocument(); // 输出XSLT样式表信息头 string strXSLRef = this.Request.QueryString["xsl"] ; if( strXSLRef != null && strXSLRef.Length > 0 ) { xmlwriter.WriteProcessingInstruction( "xml-stylesheet" , "type='text/xsl' href='" + strXSLRef + "'"); } xmlwriter.WriteStartElement("Table"); while( reader.Read()) { // 输出一条记录 xmlwriter.WriteStartElement("Record"); for( int iCount = 0 ; iCount < FieldCount ; iCount ++ ) { // 输出一个字段值 xmlwriter.WriteStartElement( FieldNames[ iCount ] ); object v = reader.GetValue( iCount ); if( v == null || DBNull.Value.Equals( v )) { xmlwriter.WriteAttributeString("Null" , "1"); } else { xmlwriter.WriteString( Convert.ToString( v )); } xmlwriter.WriteEndElement(); } xmlwriter.WriteEndElement(); }//while( reader.Read()) reader.Close(); xmlwriter.WriteEndElement(); xmlwriter.WriteEndDocument(); xmlwriter.Close(); }//using( System.Data.OleDb.OleDbCommand cmd = conn.CreateCommand()) }//using( System.Data.OleDb.OleDbConnection conn = new System.Data.OleDb.OleDbConnection()) |
Page_Load 函数的执行流程为
设置HTTP输出类型首先设置HTTP的输出类型,我们设置输出的编码格式为 GB2312,此处使用 GetEncoding(936 ) 就是获得GB2312的编码格式。
我们还设置 ContentType 来设置文档的输出格式。大家若了解一些HTTP传输协议的都知道,ContentType属性描述了文档输出类型,当文档传递到客户端时,客户端浏览器获得ContentType属性值,查询注册表和Windows中注册的COM信息,获得该属性值确定的文件类型,然后使用相应的模式显示文档。比如若设置ContentType属性为application/vnd.ms-excel ,则客户端浏览器查询注册表得知对应的文件类型信息在注册项目 HKEY_CLASS_ROOT\.xls下面,本地文件类型为”Excel.Sheet.8”,然后又根据其他信息转而调用EXCEL的COM组件来显示获得的HTTP文档。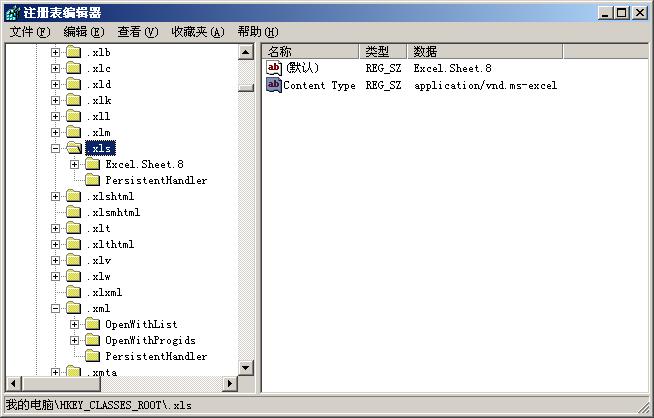
从ContentType属性的说明我们可以了解,很深入的掌握WEB开发,有时候是需要了解一些Windows编程的知识,因为B/S系统的客户端,也就是各种浏览器,特别是IE浏览器就是比较复杂的Windows程序。
查询数据库设置了HTTP文档输出模式后,我们开始输出XML文档内容,首先是连接数据库,使用了程序目录下的demomdb.mdb数据库,执行一个SQL查询,获得一个数据读取器reader。
使用XmlTextWriter输出XML文档查询得到数据后,我们就可以遍历查询所得的数据库记录,开始输出XML文档,此处我们使用XmlTextWriter输出文档。
输出XML文档我们有两种方式,一种是使用XmlTextWriter输出,另外一种是从XmlDocument类型开始构造XML文档对象结构,然后使用XmlDocument的Save方法输出XML文档。两种方法有各自特点。
使用XmlTextWriter是只写的向前的快速输出XML文档,而且输出时不能访问已经输出的XML文档内容,不能修改已经生成的XML文档。这种方法速度快,占用内存少,但不够灵活。
而使用XmlDocument类型构造XML文档结构后再输出XML文档的方法比较灵活,我们可以随时访问和修改已经输出的Xml文档。这种方法速度慢,占用内存多,但很灵活。
在这里我们要尝试使用XmlTextWriter来输出XML文档,在另外的一个页码使用XmlDocument输出XML文档。
我们首先在页面输出流上新建一个XmlTextWriter对象,设置它启动缩进。它的Indentation,IndentChar和Formating就是控制缩进样式,具体说明可以查看MSDN。XML文档缩进是为了改善XML文档的可读性,有缩进的XML文档便于人们直接阅读和修改,但对应用程序来说,XML文档是否有缩进是没差别的。
XmlTextWriter是一个基于其他流的针对输出XML文档的包装,它本身不能打开文件,因此在初始化XmlTextWriter时必须指明底层的输出对象,输出对象可以为流或者文本书写器。理论上我们可以使用字符串拼凑来生成XML文档,但实际开发中使用字符串拼凑XML文档不是明智之举,建议使用XmlTextWriter。
我们在web开发中有时会使用字符串拼凑来生成HTML文档,由于HTML文档没有很严格的语法限制,IE浏览器能解释劣质的HTML代码,因此有时会有开发者这样字符串拼凑HTML文档,但这会导致代码比较杂乱,可读性不好。而XML文档具有很严格的语法检查,只要一个XML语法错误就会导致整个XML文档解析错误,因此我们应当使用XmlTextWriter,因此它能帮助我们检查基本的XML语法,确保我们能输出合格的XML文档。
我们调用WriteStartDocument来开始输出XML文档,XmlTextWriter提供了很多配对使用的成员,使用一个方法后需要使用另外一个配对的方法。比如WriteStartDocument和WriteEndDocument配对,WriteStartElement和WriteEndElement配对,配对的方法必须成对调用。此处我们使用WriteStartDocument开始书写Xml文档,我们就必须使用WriteEndDocument 来完成输出XML文档的。而且在使用XmlTextWriter输出XML文档的时候,WriteStartDocument必须是第一个调用的方法。
然后我们使用一个名称为xsl的页面参数来输出XML文档的xml-stylesheet信息头,关于XSL下节课将详细介绍,在本节课不管这个参数。
我们调用WriteStartElement 方法来输出XML文档的根节点,这里参数为字符串 “Table” , 则表示输出的XML文档的根节点名称为Table。
然后我们使用数据库数据读取器的Read函数来遍历所有的查询的数据,对于每一条记录,使用XML书写器的WriteStartElement方法来输出XML元素,这里参数为字符串”Record”,表示输出的XML元素名为Record,而且这个节点添加到XML文档的根节点下。
对于每一条记录我们还遍历其所有的字段值,对每一个字段值使用WriteStartElement新增一个XML元素,元素名称就是各个字段的名称。若字段值是空则使用WriteAttributeString输出名为Null 的XML属性,否则使用WriteString来输出字段值的字符串表达值。
由于WriteStartElement和WriteEndElement配对使用,因此每输出完一个XML元素后需要调用WriteEndElement来结束输出XML元素。当所有的内容输出完毕后我们调用WriteEndDocument来结束输出整个XML文档的。
使用XmlDocument输出XML文档页面record.aspx功能和recordxml.aspx类似。但它使用 XmlDocument来构造XML文档对象结构,然后输出XML文档。现对其过程进行说明。
打开record.aspx的HTML代码,可以看到代码非常简单,只有一行,所有的页面输出都在程序代码中实现。打开它的C#代码,可以看到在Page_Load 方法中添加了代码执行页面输出,其代码为
| // 此处代码动态构造 XmlDocument对象 来输出XML文档 System.Xml.XmlDocument XmlDoc = new System.Xml.XmlDocument(); XmlDoc.AppendChild( XmlDoc.CreateElement("Table")); // 连接数据库 using( System.Data.OleDb.OleDbConnection conn = new System.Data.OleDb.OleDbConnection()) { conn.ConnectionString = @"Provider=Microsoft.Jet.OLEDB.4.0;Data Source=" + this.Server.MapPath("demomdb.mdb"); conn.Open(); // 查询数据库 using( System.Data.OleDb.OleDbCommand cmd = conn.CreateCommand()) { cmd.CommandText = "Select * From Customers"; System.Data.OleDb.OleDbDataReader reader = cmd.ExecuteReader(); // 获得所有字段名 int FieldCount = reader.FieldCount ; string[] FieldNames = new string[ FieldCount ] ; for( int iCount = 0 ; iCount < FieldCount ; iCount ++ ) { FieldNames[ iCount ] = reader.GetName( iCount ); } while( reader.Read()) { // 输出一条记录 System.Xml.XmlElement RecordElement = XmlDoc.CreateElement("Record"); XmlDoc.DocumentElement.AppendChild( RecordElement ); for( int iCount = 0 ; iCount < FieldCount ; iCount ++ ) { // 输出一个字段值 System.Xml.XmlElement FieldElement = XmlDoc.CreateElement( FieldNames[ iCount ] ); RecordElement.AppendChild( FieldElement ); object v = reader.GetValue( iCount ); if( v == null || DBNull.Value.Equals( v )) { FieldElement.SetAttribute("Null" , "1" ); } else { FieldElement.AppendChild( XmlDoc.CreateTextNode( Convert.ToString( v ))); } } }//while( reader.Read()) reader.Close(); }//using( System.Data.OleDb.OleDbCommand cmd = conn.CreateCommand()) }//using( System.Data.OleDb.OleDbConnection conn = new System.Data.OleDb.OleDbConnection()) string strXSLRef = this.Request.QueryString["xsl"] ; if( strXSLRef != null && strXSLRef.Length > 0 ) { // 根据页面参数指定的XSLT样式表名称执行XSLT转换 strXSLRef = this.Server.MapPath( strXSLRef ); System.Xml.Xsl.XslTransform transform = new System.Xml.Xsl.XslTransform(); transform.Load( strXSLRef ); transform.Transform( XmlDoc , null , this.Response.Output , null ); } else { // 直接输出生成的XML文档 this.Response.Write( XmlDoc.DocumentElement.OuterXml ); } |
现对该方法的执行过程进行说明。
首先是创建一个XmlDocument对象,XmlDocument创建时是一个空的XML文档,没有任何内容,没有根元素,因此第一步就是使用文档对象的AppendChild方法来添加根元素。在这里我们使用了文档对象的CreateElement函数来创建一个名为Table的XMLElement元素对象。
各种类型的XML文档对象,包括元素,属性,文本块,注释等等,都不能直接实例化,只能使用XmlDocument的一系列以Create开头的函数来创建对象实例。创建的XML文档对象是一个个离散的对象,必须及时的添加到XML文档对象结构中才能真正成为XML文档的一部分。一般的使用XML文档对象或元素对象的AppendChild方法将新创建的XML文档对象添加到指定对象下面,如此才加入了XML文档结构的大家庭中。
这种处理模式类似向DataTable添加新的数据行。DataRow本身不能直接实例化,我们首先得使用DataTable 的NewRow创建一个新的DataRow,然后使用DataTable的Rows属性的Add方法向数据表添加刚刚创建的数据行。
初始化一个XML文档对象后,我们连接数据库,查询数据库获得一个数据读取器,然后遍历查询所得的数据库记录,输出XML文档。
对每一个数据库记录,首先创建一个RecordElement对象,添加到XML文档的根节点下,然后遍历数据库记录的每一个字段值,创建一个FieldElement对象并添加到RecordElement下面,若当前数据库字段值为空,则调用FieldElement的SetAttribute 方法,设置名为Null的属性值为1,否则向FieldElement添加一个XML文本节点。
完成生成XML文档后,我们就向页面输出XML文档的内容,若页面参数中指定了XSLT转换文档名称则执行XSLT转换,并输出转换结果。关于XSLT下节课程将详细说明。
若未指明XSLT转换信息,则输出XML文档根节点的外围XML字符串。
每一个XML文档对象都具有InnerXml属性和OuterXml属性,这两个属性都直接返回表示该XML文档片断的不带缩进的XML字符串,但两者有差别。InnerXml返回表示该节点所有子孙节点的XML字符串。而OuterXml返回表示该节点本身和所有子孙节点的XML字符串。例如对于XML文档”<a><b />123</a>”,则它的根节点的InnerXml就是”<b />123”,而它的根节点的OuterXml就是”<a><b />123</a>”。注意这个字符串是不带缩进的。而XML文档直接保存到指定名称的文件中是带缩进的。
在IE浏览器中查看该页面,可以看到IE只是显示XML文档中的纯文本内容,并不像显示其他XML文档时的那种带缩进的显示。这是因为该ASPX的代码中没有设置ContentType为XML格式,而是使用默认的HTML格式,因此IE浏览器接受该页面文档代码,并把它当作HTML进行解析和显示,由于Table,Record等XML名称都不是HTML标签,因此IE浏览器忽略掉这些XML标记,只显示出其中的纯文本内容。但你查看该页面的源代码,可以看出该文档的内容仍然是标准的XML格式,这里的源代码没有缩进处理。
小结在本课程中,我们简单介绍了XML的基本语法,说明了处理XML文档的流式处理模式和DOM处理模式。还使用C#演示了输出XML文档。
XML是一项不简单的技术,而且在其上面派生了很多其他的技术,作为当代的软件开发人员,尤其是WEB开发人员,应当熟练掌握和使用XML技术及其某些派生技术,熟悉XML技术有助于开发者长期保持相当水平的软件开发能力,也是学习其他先进生产力的重要基础。大家应当好好学习XML技术。