python scrapy菜鸟教程_scrapy学习笔记(一)快速入门
安装Scrapy
Scrapy是一个高级的Python爬虫框架,它不仅包含了爬虫的特性,还可以方便的将爬虫数据保存到csv、json等文件中。
首先我们安装Scrapy。
pip install scrapy
在Windows上安装时可能会出现错误,提示找不到Microsoft Visual C++。这时候我们需要到它提示的网站visual-cpp-build-tools下载VC++ 14编译器,安装完成之后再次运行命令即可成功安装Scrapy。
error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C++ Build Tools": http://landinghub.visualstudio.com/visual-cpp-build-tools
快速开始
第一个爬虫
以下是官方文档的第一个爬虫例子。可以看到,和我们手动使用request库和BeautifulSoup解析网页内容不同,Scrapy专门抽象了一个爬虫父类,我们只需要重写其中的方法,就可以迅速得到一个可以不断爬行的爬虫。
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
def start_requests(self):
urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/',
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
page = response.url.split("/")[-2]
filename = 'quotes-%s.html' % page
with open(filename, 'wb') as f:
f.write(response.body)
self.log('Saved file %s' % filename)
上面的爬虫有几个地方需要解释一下:
爬虫类的name属性,用来标识爬虫,该名字在一个项目必须是唯一的。
start_requests()方法,必须返回一个可迭代的列表(可以是列表,也可以是生成器),Scrapy会从这些请求开始抓取网页。
parse() 方法用于从网页文本中抓取相应内容,我们需要根据自己的需要重写该方法。
开始链接
在上面的例子中使用start_requests()方法来设置起始URL,如果只需要简单指定URL还可以使用另一种简便方法,那就是设置类属性start_urls,Scrapy会读取该属性来设置起始URL。
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/',
]
提取数据
这部分的练习可以使用Scrapy的shell功能。我们可以使用下面的命令启动Scrapy shell并提取百思不得姐段子的内容,成功运行之后会打开一个交互式shell,我们可以进行交互式编程,随时查看代码的运行结果。
scrapy shell 'http://www.budejie.com/text/'
可能会出现下面的错误,遇到这种情况是因为没有安装pypiwin32模块。
ModuleNotFoundError: No module named 'win32api'
这时候可以使用下面的命令安装。
pip install pypiwin32
运行成功之后在终端中看到以下内容,列举了在交互式shell中可以进行的操作。
[s] Available Scrapy objects:
[s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc)
[s] crawler
[s] item {}
[s] request
[s] response <200 http://www.budejie.com/text/>
[s] settings
[s] spider
[s] Useful shortcuts:
[s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed)
[s] fetch(req) Fetch a scrapy.Request and update local objects
[s] shelp() Shell help (print this help)
[s] view(response) View response in a browser
例如,如果我们要查看网页的内容,可以输入view(response),会打开默认浏览器并进入相应页面。
In [2]: view(response)
Out[2]: True
如果需要使用CSS选择器提取网页内容,可以输入相应的内容,比如说下面就获取了网页上的标题标签。
In [3]: response.css('title')
Out[3]: []
如果需要提取标签内容,可以使用Scrapy扩展的CSS选择器::text并使用extract()方法。如果直接对标签调用extract()会获取包含标签在内的整个文本。
In [8]: response.css('title::text').extract()
Out[8]: ['内涵段子_内涵笑话-百思不得姐官网,第1页']
如果选中的标签含有复数内容,可以使用extract_first()方法获取第一个元素。
response.css('title::text').extract_first()
也可以使用索引来选取内容。不过假如没有元素的话,extract_first()方法会返回None而索引会抛出IndexError,因此使用extract_first()更好。
response.css('title::text')[0].extract()
除了CSS选择器之外,Scrapy还支持使用re方法以正则表达式提取内容,以及xpath方法以XPATH语法提取内容。关于XPATH,可以查看菜鸟教程,写的还不错。
下面是提取百思不得姐段子的简单例子,在交互环境中执行之后,我们就可以看到提取出来的数据了。
li=response.css('div.j-r-list-c-desc')
content=li.css('a::text')
编写爬虫
确定如何提取数据之后,就可以编写爬虫了。下面的爬虫爬取了百思不得姐首页的用户名和段子。
class Baisibudejie(scrapy.Spider):
name = 'jokes'
start_urls = ['http://www.budejie.com/text/']
def parse(self, response):
lies = response.css('div.j-r-list >ul >li')
for li in lies:
username = li.css('a.u-user-name::text').extract()
content = li.css('div.j-r-list-c-desc a::text').extract()
yield {'username': username, 'content': content}
写好了爬虫之后,就可以运行了。我们可以使用下面的命令运行这个爬虫。运行成功之后,会出现user.json,其中就是我们爬取的数据。Scrapy支持多种格式,除了json之外,还可以将数据导出为XML、CSV等格式。
scrapy runspider use_scrapy.py -o user.json
页面跳转
如果爬虫需要跨越多个页面,需要在parse方法中生成下一步要爬取的页面。下面的例子是爬取我CSDN博客所有文章和连接的爬虫。这个爬虫没有处理CSDN博客置顶文章,所以置顶文章爬取的文章标题是空。
class CsdnBlogSpider(scrapy.Spider):
name = 'csdn_blog'
start_urls = ['http://blog.csdn.net/u011054333/article/list/1']
def __init__(self, **kwargs):
super().__init__(**kwargs)
self.base_url = 'http://blog.csdn.net'
def parse(self, response):
articles = response.css('div#article_list div.article_item')
for article in articles:
title = article.css('div.article_title a::text').extract_first().strip()
link = self.base_url + article.css('div.article_title a::attr(href)').extract_first().strip()
yield {'title': title, 'link': link}
pages = response.css('div#papelist')
next_page_url = pages.css('a').re_first('下一页')
if next_page_url is not None:
yield scrapy.Request(urllib.parse.urljoin(self.base_url, next_page_url))
scrapy命令
为了更好的实现工程化管理,Scrapy还提供了scrapy命令来帮助我们管理爬虫。详细的命令用法请参考官方文档。
创建项目
下面的命令可以创建一个Scrapy爬虫项目,它为我们规定了标准的项目格式。
scrapy startproject myproject [project_dir]
创建好之后,应该会出现如下的项目结构。spiders模块中放置所有爬虫,scrapy.cfg是项目的全局配置文件,其余文件是Scrapy的组件。

创建爬虫
使用下面的命令可以创建一个爬虫,爬虫会放置在spider模块中。
scrapy genspider mydomain mydomain.com
生成的爬虫具有基本的结构,我们可以直接在此基础上编写代码。
# -*- coding: utf-8 -*-
import scrapy
class MydomainSpider(scrapy.Spider):
name = "mydomain"
allowed_domains = ["mydomain.com"]
start_urls = ['http://mydomain.com/']
def parse(self, response):
pass
运行爬虫
在已经生成好的项目中,我们使用项目相关的命令来运行爬虫。首先需要列出所有可运行的爬虫,这会列出所有爬虫类中指定的name属性。
scrapy list
然后,我们可以按照name来运行爬虫。
scrapy crawl 'csdn_blog' -o blog.json
注意这两个命令都是项目相关的,只能用于已存在的项目。
设置编码
如果你使用上面的爬虫并导出为json格式,可能会发现所有汉字全变成了Unicode字符(类似\uA83B这样的)。自Scrapy1.2 起,增加了FEED_EXPORT_ENCODING属性,用于设置输出编码。我们在settings.py中添加下面的配置即可。
FEED_EXPORT_ENCODING = 'utf-8'
然后再重新导出一次。这次所有汉字都能正常输出了。
以上就是Scrapy的快速入门了。我们了解了如何编写最简单的爬虫。如果查阅Scrapy的官方文档会发现Scrapy的功能远不止这里介绍的。本文就是起一个抛砖引玉的作用,如果希望进一步了解Scrapy这个爬虫框架,请查阅相关文档进一步学习。
相关文章:

执行eclipse,迅速failed to create the java virtual machine。
它们必须在一排,否则会出现The Eclipse executable launcher was unable to locate its companion shared library的错误 打开eclipse文件夹下的eclipse.ini文件。改动–launcher.XXMaxPermSize属性,当中此属性有两处 -startup plugins/org.eclipse.equi…
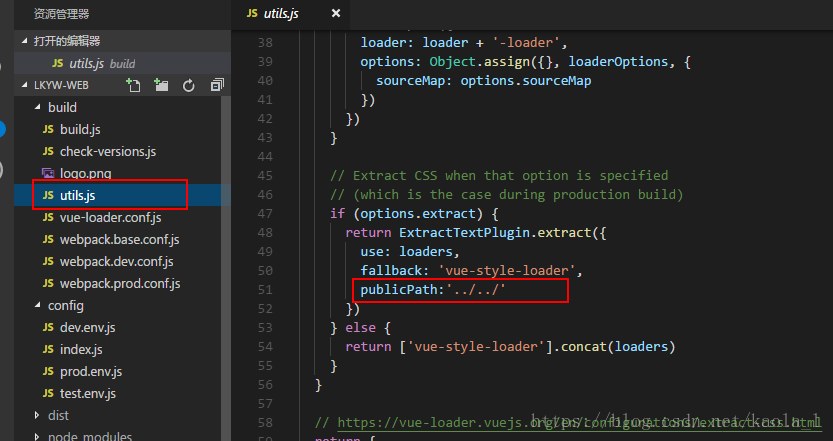
vue打包后图片找不到情况
打包之前需要修改如下配置文件: 配置文件一:build>>>utils.js (修改publicPath:"../../" , 这样写是处理打包后找不到静态文件(图片路径失效)的问题) 配置文件二:config>>>index.js(修改a…

UBUNTU安装SSH和xrdp
一、安装SSH,通过PUTTY访问 命令:sudo apt-get install ssh 查看:netstat -l 二、安装xrdp,通过远程桌面访问 命令:sudo apt-get install xrdp 开启远程桌面访问权限 系统-->首选项-->remote desktop 三、去掉远…
python中opencv中inrange用法_python-opencv中的cv2.inRange函数
本次目标是将一副图像从rgb颜色空间转换到hsv颜色空间,颜色去除白色背景部分具体就调用了cv2的两个函数,一个是rgb转hsv的函数具体用法hsv cv2.cvtColor(rgb_image, cv2.COLOR_BGR2HSV)然后利用cv2.inRange函数设阈值,去除背景部分mask cv2…
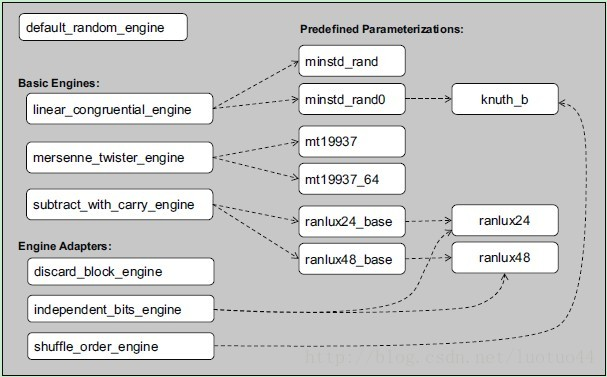
[转]C++11 随机数学习
相对于C 11之前的随机数生成器来说,C11的随机数生成器是复杂了很多。这是因为相对于之前的只需srand、rand这两函数即可获取随机数来说,C11提供了太多的选择和东西。 随机数生成算法: 随机数生成算法有很多,C11之前的C/C只…
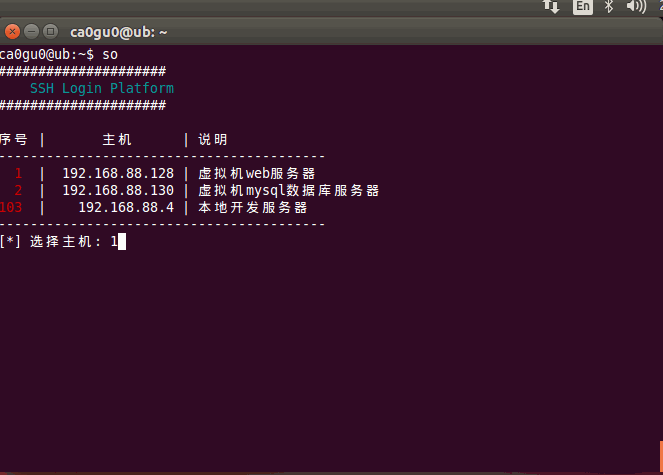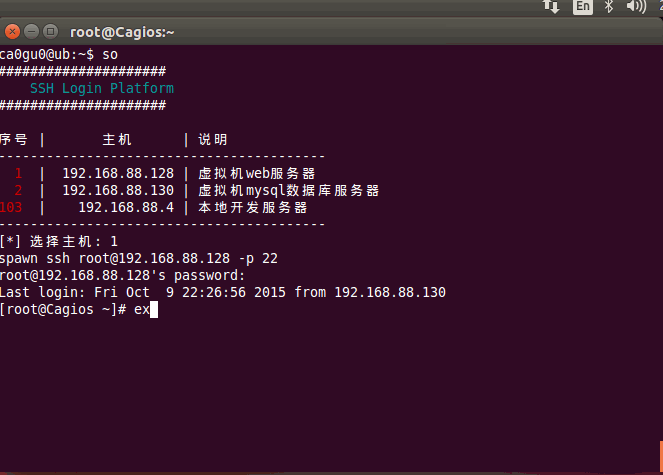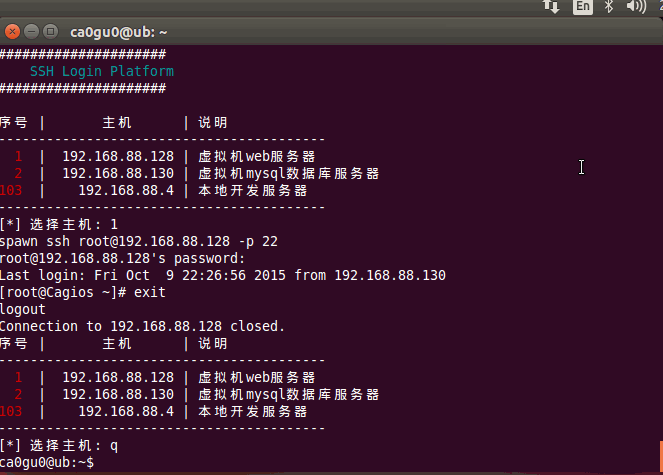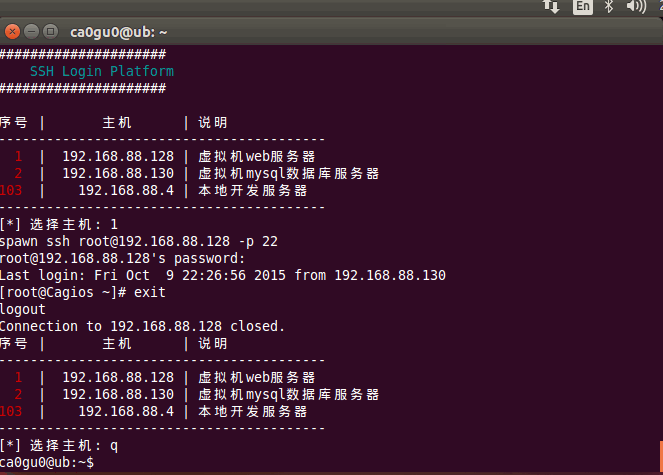
Linux Shell ssh登录脚本
Linux 登陆服务器敲命令太多,某时候确实不便,所以就用shell写了一个 我的blog地址: http://www.cnblogs.com/caoguo 一.说明 支持秘密和密钥两种格式用户名和密码都是写文件的,明文保存二.配置 密码文件配置:序号:IP:端口:用户:密码:说明 1:192.168.88.128:22:root:toor:虚拟机…

C# 温故而知新:Stream篇(二)
C# 温故而知新:Stream篇(二) TextReader 和StreamReader 目录: 为什么要介绍 TextReader? TextReader的常用属性和方法 TextReader 示例 从StreamReader想到多态 简单介绍下Encoding 编码 StreamReader 的定义及作用 S…
usaco Pollutant Control
第一问是求最小割。第二问求最小割中集合中边最少的集合的大小。 第三问求集合中边最少且字典序最小的边的下标。 第一问直接求最大流就能解,第二问将原来的边的容量都改为1,求出来的最大流就是元素最少的一个最小割的大小。 将容量都改为1之后ÿ…
洛谷P4705 玩游戏(生成函数+多项式运算)
题面 传送门 题解 妈呀这辣鸡题目调了我整整三天……最后发现竟然是因为分治\(NTT\)之后的多项式长度不是\(2\)的幂导致把多项式的值存下来的时候发生了一些玄学错误……玄学到了我\(WA\)的点全都是\(WA\)在\(2\)的幂次行里…… 看到这种题目二话不说先推倒 \[ \begin{aligned}…
blast程序 介绍 简介
每次找都挺麻烦,又记不住,于是抄下来: blastp:将待查询的蛋白质序列及其互补序列一起对蛋白质序列数据库进行查询;blastn:将待查询的核酸序列及其互补序列一起对核酸序列数据库进行查询;blastx:先将待查询的核酸序列按…
java泛型的实现和原理_java 泛型实现原理
泛型思想最早在C语言的模板(Templates)中产生,Java后来也借用了这种思想。虽然思想一致,但是他们存在着本质性的不同。C中的模板是真正意义上的泛型,在编译时就将不同模板类型参数编译成对应不同的目标代码,List和List是两种不同的…
java out of range_关于Parameter index out of range求解决办法
程序:提示参数越界,但我实在不知道我到底哪里越界了。明明该我那样写的嘛。求高手帮我看看,现在我是弄得我有气无力了!要死了。在去死亡的路上等着你帮帮我!Document : replyokCreated on : 2008-9-29, 6:05:31Autho…

FineReport——权限分配以及自定义首页
权限分配可以有两种方法,第一种方法是根据部门职位分配权限,第二种是根据角色分配权限; FR自带有三个JQ对象,用以保存用户名参数/角色参数/部门参数——$fr_username/$fr_authority/$fr_userposition 根据部门职位: 以…
去掉[]中的英文(正则表达式)C#
这个问题本来是以为信息科技大学的老师问蒋委员长的问题,蒋委员长用正则表达式完成了这个问题 1,问题的情况有哪些? abc[abc]abc,abc[-abc]abc,abc[一abc]abc,abc[一abc一]abc等等. 2,问题的解决目标? 写一个通用的方法来完成提出的问题. 3,解决方案 -->正则表达式方法 其…
Event Loop
事件队列 Javascript是单线程,单线程就意味着所有任务需要排队。然后会将所有任务分成两类:同步任务和异步任务!同步任务:在主线程上执行的任务,只有前一个任务执行完成,才会执行后一个!异步任务…
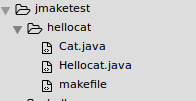
java makefile jar包_java makefile学习实践(编译的javac命令写在makefile中,运行命令java写在shell脚本中)...
学习makefile教程,ubuntu中文网1.写一个简单的java项目,不需要外部jar,用的简单的importjava.util.ArrayList;是可以从CLASSPATH环境变量中找到的,在javac阶段不需要特殊添加-cphellocatHellocat.javaimportjava.util.ArrayList;importjava.u…
Python字符编码详解
Python字符编码详解 转自http://www.cnblogs.com/huxi/archive/2010/12/05/1897271.html Python字符编码详解 本文简单介绍了各种常用的字符编码的特点,并介绍了在python2.x中如何与编码问题作战 :) 请注意本文关于Python的内容仅适用于2.x&a…
《编写有效用例》读书笔记1
第一章 引言 本章主要介绍用例是什么样子的,并描述为什么不同的项目组需要采用不同 的用例编写风格以及在什么地方使用用例有利于做需求收集工作,也让我们了解 在编写用例之前,需要做哪些准备工作。 用例是代表系统中各个项目相关人员之间就系…
顺序结构,判断结构 if,switch
1:顺序结构:从上往下执行程序代码,为顺序结构 ---------------------------------------------------------------------- 2:判断结构: if 如果 判断是两个选择一个,要么对要么错 if中的条件表达式 返回…

php转换文字Unicode,php实现将中文转为unicode的方法
相关函数说明:iconv命令是用来转换文件的编码方式的,比如它可以将UTF8编码的转换成GB18030的编码,反过来也行。str_split() 函数把字符串分割到数组中。bin2hex() 函数把 ASCII 字符的字符串转换为十六进制值。字符串可通过使用 pack() 函数再…
kail安装和vmtools安装
因位太费劲我直接把我做的Word文档直接上传了,如果想安装可以下载,我就不麻烦在写一遍了,这个教程主要给小白讲的,大佬请绕过 kail安装教程.docx https://pan.wps.cn/l/sm43o7f 密码:f43341转载于:https://www.cnblogs…

Windows计数器做性能监控(window server 2008服务器)
使用Windows计数器 一、创建数据收集器集 二、创建数据收集器 三、使用数据收集器 1、修改数据收集器的属性 2、手动启用、手动停止数据收集器集 3、计划任务 4、在性能监视器中查看 一、性能监视器 Windows 服务器操作系统提供一个名为“性能监视器”的图形工具,可…

使用浏览器wpf应用程序时访问数据库需要报权限错误的解决方法
在这篇wpf教程中,如果选用浏览器wpf应用程序模板我遇到了 访问数据库时权限不够 不能打开连接 将项目属性的安全性中设置为完全信任后即解决 转载于:https://www.cnblogs.com/langu/archive/2012/03/29/2423620.html
gprs 神奇宝典java,2016联通笔试知识点大全
答:呼叫转移是指用户在工作忙或手机无网络等无法用本机接听电话的情况下,即可将来电设置呼叫转移到另一个号码上,实现号码转移。注:呼叫转移业务目前无需月功能费,用户设置呼叫转移后,如正常接听来电则按照…

内存管理器(二)边界标识法
边界标识算法 前言 首先说明,我们这里的内存管理器主要是以模拟各种内存分配算法为主,从内存申请一片内存然后根据我们所选定的数据结构和算法,实现程序的堆空间的分配,至于内存分配详情我们会在Linux内核内存管理的简单分析中探讨…

XDOC Office Server 开源了,Office文档完美转换为PDF
百度智能云 云生态狂欢季 热门云产品1折起>>> 项目地址:https://gitee.com/xdoc/xoffice XDOC是一个文档自动化平台,提供免费的Office文档生成服务。有用户提出要PDF格式,便于阅读、发布。在尝试了OpenOffice、WPS、微软Office、P…
js的defer属性
js的defer属性说明:<script src"js.js" type"text/javascript defer"defer"/>中defer的作用 给外链的js脚本添加defer"defer" 或 defer"true",使用defer属性可以让脚本在整个页面装载完成之后再解析,…
怎么读取java文件,Java怎么读取文件
当前位置:我的异常网 J2SE Java怎么读取文件Java怎么读取文件www.myexceptions.net 网友分享于:2013-12-20 浏览:60次Java如何读取文件?源文件如下,小弟没有学过Java,下面是一段JAVA用RSA加密字符串的程序,命令行的形式是Java PublicExample ABC…
Android环境变量的设置(详细图解版)
Android环境变量的设置(详细图解版) 转载于:https://www.cnblogs.com/zhujiabin/p/4875182.html
用加密货币连接业务的6种方法
如今,区块链技术和加密货币已经变得更加接近传统业务。在某些情况下,商人们能够找到一种将传 统商业与新技术相结合的有价值的模式。事实上,进入加密货币市场有很多选择,本文将讨论6种主 要的合作方式。 创建加密货币平台是为了完…