2019独角兽企业重金招聘Python工程师标准>>> 
Spark的核心是根据RDD来实现的,Spark Scheduler则为Spark核心实现的重要一环,其作用就是任务调度。Spark的任务调度就是如何组织任务去处理RDD中每个分区的数据,根据RDD的依赖关系构建DAG,基于DAG划分Stage,将每个Stage中的任务发到指定节点运行。基于Spark的任务调度原理,我们可以合理规划资源利用,做到尽可能用最少的资源高效地完成任务计算。
分布式运行框架
Spark可以部署在多种资源管理平台,例如Yarn、Mesos等,Spark本身也实现了一个简易的资源管理机制,称之为Standalone模式。由于工作中接触较多的是Saprk on Yarn,不做特别说明,以下所述均表示Spark-on-Yarn。Spark部署在Yarn上有两种运行模式,分别为yarn-client和yarn-cluster模式,它们的区别仅仅在于Spark Driver是运行在Client端还是ApplicationMater端。如下图所示为Spark部署在Yarn上,以yarn-cluster模式运行的分布式计算框架。

其中蓝色部分是Spark里的概念,包括Client、ApplicationMaster、Driver和Executor,其中Client和ApplicationMaster主要是负责与Yarn进行交互;Driver作为Spark应用程序的总控,负责分发任务以及监控任务运行状态;Executor负责执行任务,并上报状态信息给Driver,从逻辑上来看Executor是进程,运行在其中的任务是线程,所以说Spark的任务是线程级别的。通过下面的时序图可以更清晰地理解一个Spark应用程序从提交到运行的完整流程。
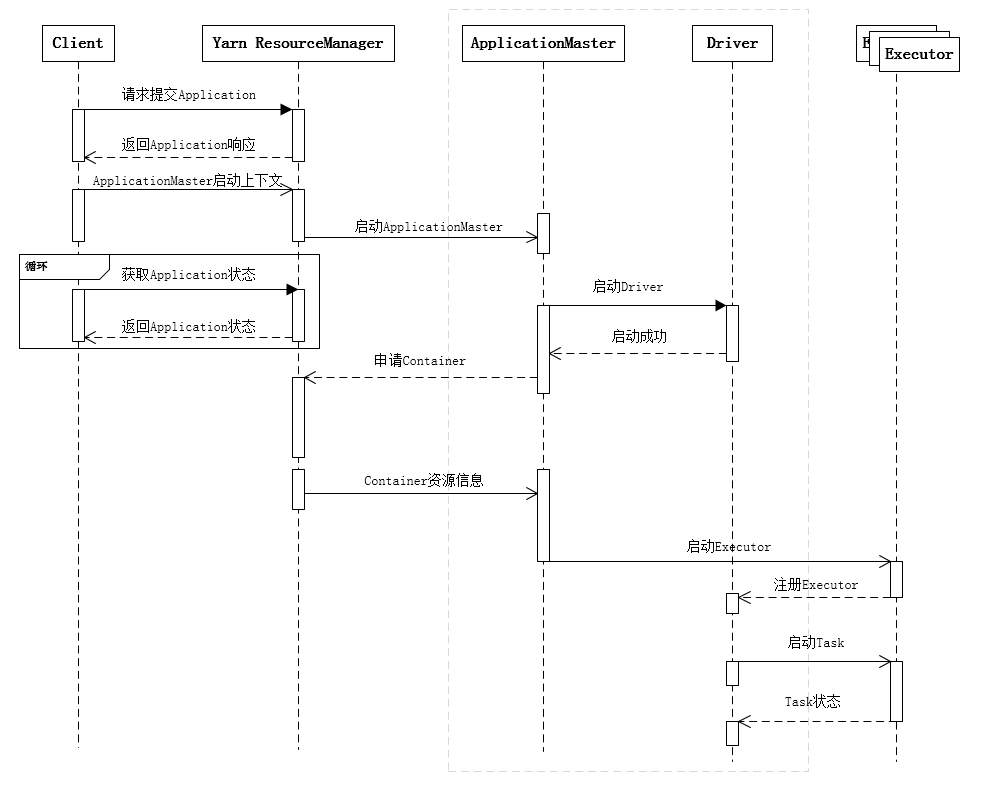
提交一个Spark应用程序,首先通过Client向ResourceManager请求启动一个Application,同时检查是否有足够的资源满足Application的需求,如果资源条件满足,则准备ApplicationMaster的启动上下文,交给ResourceManager,并循环监控Application状态。
当提交的资源队列中有资源时,ResourceManager会在某个NodeManager上启动ApplicationMaster进程,ApplicationMaster会单独启动Driver后台线程,当Driver启动后,ApplicationMaster会通过本地的RPC连接Driver,并开始向ResourceManager申请Container资源运行Executor进程(一个Executor对应与一个Container),当ResourceManager返回Container资源,则在对应的Container上启动Executor。
Driver线程主要是初始化SparkContext对象,准备运行所需的上下文,然后一方面保持与ApplicationMaster的RPC连接,通过ApplicationMaster申请资源,另一方面根据用户业务逻辑开始调度任务,将任务下发到已有的空闲Executor上。
当ResourceManager向ApplicationMaster返回Container资源时,ApplicationMaster就尝试在对应的Container上启动Executor进程,Executor进程起来后,会向Driver注册,注册成功后保持与Driver的心跳,同时等待Driver分发任务,当分发的任务执行完毕后,将任务状态上报给Driver。
Driver把资源申请的逻辑给抽象出来,以适配不同的资源管理系统,所以才间接地通过ApplicationMaster去和Yarn打交道。
从上述时序图可知,Client只管提交Application并监控Application的状态。对于Spark的任务调度主要是集中在两个方面: 资源申请和任务分发,其主要是通过ApplicationMaster、Driver以及Executor之间来完成,下面详细剖析Spark任务调度每个细节。
Spark任务调度总览
当Driver起来后,Driver则会根据用户程序逻辑准备任务,并根据Executor资源情况逐步分发任务。在详细阐述任务调度前,首先说明下Spark里的几个概念。一个Spark应用程序包括Job、Stage以及Task三个概念:
- Job是以Action方法为界,遇到一个Action方法则触发一个Job;
- Stage是Job的子集,以RDD宽依赖(即Shuffle)为界,遇到Shuffle做一次划分;
- Task是Stage的子集,以并行度(分区数)来衡量,分区数是多少,则有多少个task。
Spark的任务调度总体来说分两路进行,一路是Stage级的调度,一路是Task级的调度,总体调度流程如下图所示。

Spark RDD通过其Transactions操作,形成了RDD血缘关系图,即DAG,最后通过Action的调用,触发Job并调度执行。DAGScheduler负责Stage级的调度,主要是将DAG切分成若干Stages,并将每个Stage打包成TaskSet交给TaskScheduler调度。TaskScheduler负责Task级的调度,将DAGScheduler给过来的TaskSet按照指定的调度策略分发到Executor上执行,调度过程中SchedulerBackend负责提供可用资源,其中SchedulerBackend有多种实现,分别对接不同的资源管理系统。有了上述感性的认识后,下面这张图描述了Spark-On-Yarn模式下在任务调度期间,ApplicationMaster、Driver以及Executor内部模块的交互过程。

Driver初始化SparkContext过程中,会分别初始化DAGScheduler、TaskScheduler、SchedulerBackend以及HeartbeatReceiver,并启动SchedulerBackend以及HeartbeatReceiver。SchedulerBackend通过ApplicationMaster申请资源,并不断从TaskScheduler中拿到合适的Task分发到Executor执行。HeartbeatReceiver负责接收Executor的心跳信息,监控Executor的存活状况,并通知到TaskScheduler。下面着重剖析DAGScheduler负责的Stage调度以及TaskScheduler负责的Task调度。
Stage级的调度
Spark的任务调度是从DAG切割开始,主要是由DAGScheduler来完成。当遇到一个Action操作后就会触发一个Job的计算,并交给DAGScheduler来提交,下图是涉及到Job提交的相关方法调用流程图。
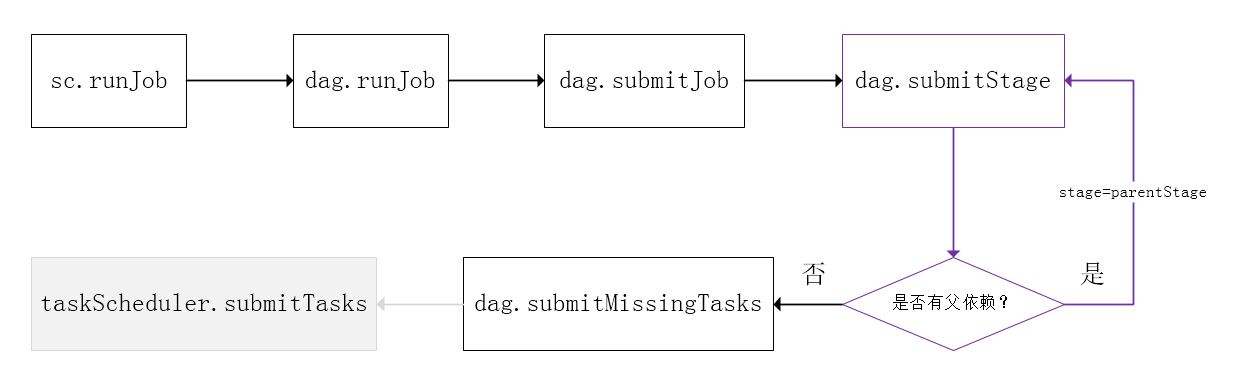
Job由最终的RDD和Action方法封装而成,SparkContext将Job交给DAGScheduler提交,它会根据RDD的血缘关系构成的DAG进行切分,将一个Job划分为若干Stages,具体划分策略是,由最终的RDD不断通过依赖回溯判断父依赖是否是宽依赖,即以Shuffle为界,划分Stage,窄依赖的RDD之间被划分到同一个Stage中,可以进行pipeline式的计算,如下图紫色流程部分。划分的Stages分两类,一类叫做ResultStage,为DAG最下游的Stage,由Action方法决定,另一类叫做ShuffleMapStage,为下游Stage准备数据,下面看一个简单的例子WordCount。
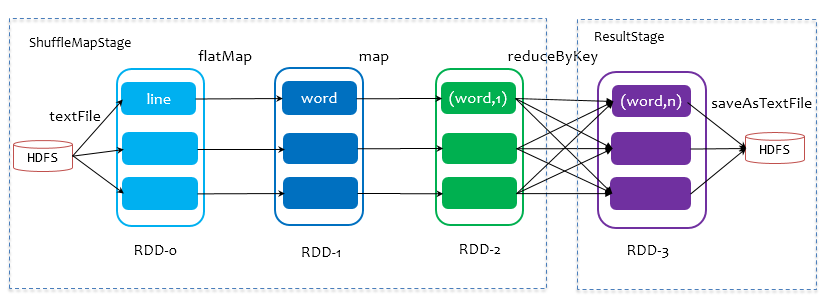
Job由saveAsTextFile触发,该Job由RDD-3和saveAsTextFile方法组成,根据RDD之间的依赖关系从RDD-3开始回溯搜索,直到没有依赖的RDD-0,在回溯搜索过程中,RDD-3依赖RDD-2,并且是宽依赖,所以在RDD-2和RDD-3之间划分Stage,RDD-3被划到最后一个Stage,即ResultStage中,RDD-2依赖RDD-1,RDD-1依赖RDD-0,这些依赖都是窄依赖,所以将RDD-0、RDD-1和RDD-2划分到同一个Stage,即ShuffleMapStage中,实际执行的时候,数据记录会一气呵成地执行RDD-0到RDD-2的转化。不难看出,其本质上是一个深度优先搜索算法。
一个Stage是否被提交,需要判断它的父Stage是否执行,只有在父Stage执行完毕才能提交当前Stage,如果一个Stage没有父Stage,那么从该Stage开始提交。Stage提交时会将Task信息(分区信息以及方法等)序列化并被打包成TaskSet交给TaskScheduler,一个Partition对应一个Task,另一方面监控Stage的运行状态,只有Executor丢失或者Task由于Fetch失败才需要重新提交失败的Stage以调度运行失败的任务,其他类型的Task失败会在TaskScheduler的调度过程中重试。
相对来说DAGScheduler做的事情较为简单,仅仅是在Stage层面上划分DAG,提交Stage并监控相关状态信息。TaskScheduler则相对较为复杂,下面详细阐述其细节。
Task级的调度
Spark Task的调度是由TaskScheduler来完成,由前文可知,DAGScheduler将Stage打包到TaskSet交给TaskScheduler,TaskScheduler会将其封装为TaskSetManager加入到调度队列中,TaskSetManager负责监控管理同一个Stage中的Tasks,TaskScheduler就是以TaskSetManager为单元来调度任务。前面也提到,TaskScheduler初始化后会启动SchedulerBackend,它负责跟外界打交道,接收Executor的注册信息,并维护Executor的状态,所以说SchedulerBackend是管“粮食”的,同时它在启动后会定期地去“询问”TaskScheduler有没有任务要运行,也就是说,它会定期地“问”TaskScheduler“我有这么多余量,你要不要啊”,TaskScheduler在SchedulerBackend“问”它的时候,会从调度队列中按照指定的调度策略选择TaskSetManager去调度运行,大致方法调用流程如下图所示。
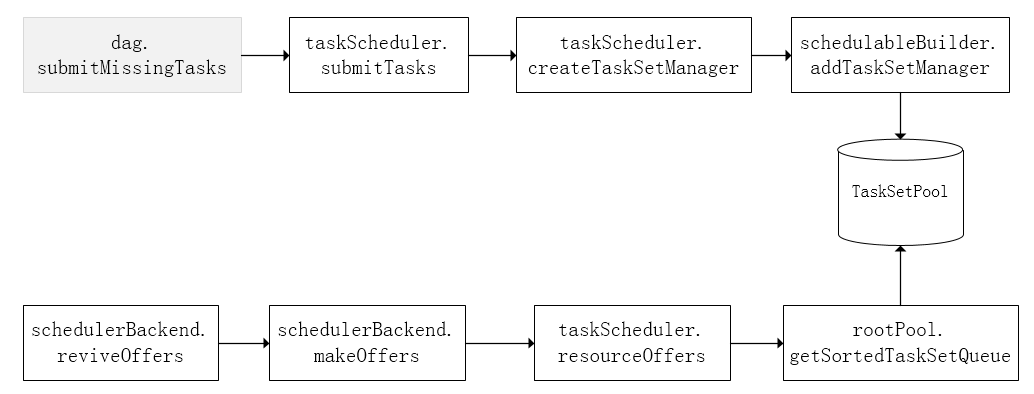
调度策略
前面讲到,TaskScheduler会先把DAGScheduler给过来的TaskSet封装成TaskSetManager扔到任务队列里,然后再从任务队列里按照一定的规则把它们取出来在SchedulerBackend给过来的Executor上运行。这个调度过程实际上还是比较粗粒度的,是面向TaskSetManager的。
TaskScheduler是以树的方式来管理任务队列,树中的节点类型为Schedulable,叶子节点为TaskSetManager,非叶子节点为Pool,下图是它们之间的继承关系。
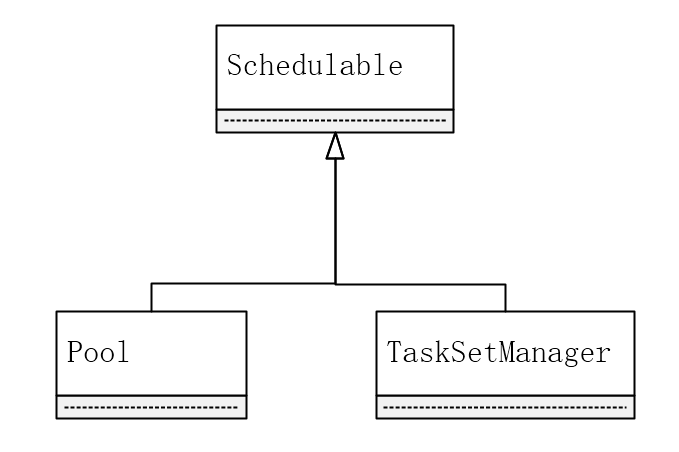
TaskScheduler支持两种调度策略,一种是FIFO,也是默认的调度策略,另一种是FAIR。在TaskScheduler初始化过程中会实例化rootPool,表示树的根节点,是Pool类型。如果是采用FIFO调度策略,则直接简单地将TaskSetManager按照先来先到的方式入队,出队时直接拿出最先进队的TaskSetManager,其树结构大致如下图所示,TaskSetManager保存在一个FIFO队列中。

在阐述FAIR调度策略前,先贴一段使用FAIR调度策略的应用程序代码,后面针对该代码逻辑来详细阐述FAIR调度的实现细节。
object MultiJobTest {// spark.scheduler.mode=FAIRdef main(args: Array[String]): Unit = {val spark = SparkSession.builder().getOrCreate()val rdd = spark.sparkContext.textFile(...).map(_.split("\\s+")).map(x => (x(0), x(1)))val jobExecutor = Executors.newFixedThreadPool(2)jobExecutor.execute(new Runnable {override def run(): Unit = {spark.sparkContext.setLocalProperty("spark.scheduler.pool", "count-pool")val cnt = rdd.groupByKey().count()println(s"Count: $cnt")}})jobExecutor.execute(new Runnable {override def run(): Unit = {spark.sparkContext.setLocalProperty("spark.scheduler.pool", "take-pool")val data = rdd.sortByKey().take(10)println(s"Data Samples: ")data.foreach { x => println(x.mkString(", ")) }}})jobExecutor.shutdown()while (!jobExecutor.isTerminated) {}println("Done!")}
}上述应用程序中使用两个线程分别调用了Action方法,即有两个Job会并发提交,但是不管怎样,这两个Job被切分成若干TaskSet后终究会被交到TaskScheduler这里统一管理,其调度树大致如下图所示。

在出队时,则会对所有TaskSetManager排序,具体排序过程是从根节点rootPool开始,递归地去排序子节点,最后合并到一个ArrayBuffer里,代码逻辑如下。
def getSortedTaskSetQueue: ArrayBuffer[TaskSetManager] = {var sortedTaskSetQueue = new ArrayBuffer[TaskSetManager]val sortedSchedulableQueue = schedulableQueue.asScala.toSeq.sortWith(taskSetSchedulingAlgorithm.comparator)for (schedulable <- sortedSchedulableQueue) {sortedTaskSetQueue ++= schedulable.getSortedTaskSetQueue}sortedTaskSetQueue
}使用FAIR调度策略时,上面代码中的taskSetSchedulingAlgorithm的类型为FairSchedulingAlgorithm,排序过程的比较是基于Fair-share来比较的,每个要排序的对象包含三个属性: runningTasks值(正在运行的Task数)、minShare值、weight值,比较时会综合考量runningTasks值,minShare以及weight值。如果A对象的runningTasks大于它的minShare,B对象的runningTasks小于它的minShare,那么B排在A前面;如果A、B对象的runningTasks都小于它们的minShare,那么就比较runningTasks与minShare的比值,谁小谁排前面;如果A、B对象的runningTasks都大于它们的minShare,那么就比较runningTasks与weight的比值,谁小谁排前面。整体上来说就是通过minShare和weight这两个参数控制比较过程,可以做到不让资源被某些长时间Task给一直占了。
从调度队列中拿到TaskSetManager后,那么接下来的工作就是TaskSetManager按照一定的规则一个个取出Task给TaskScheduler,TaskScheduler再交给SchedulerBackend去发到Executor上执行。前面也提到,TaskSetManager封装了一个Stage的所有Task,并负责管理调度这些Task。
本地化调度
从调度队列中拿到TaskSetManager后,那么接下来的工作就是TaskSetManager按照一定的规则一个个取出Task给TaskScheduler,TaskScheduler再交给SchedulerBackend去发到Executor上执行。前面也提到,TaskSetManager封装了一个Stage的所有Task,并负责管理调度这些Task。

在TaskSetManager初始化过程中,会对Tasks按照Locality级别进行分类,Task的Locality有五种,优先级由高到低顺序:PROCESS_LOCAL(指定的Executor),NODE_LOCAL(指定的主机节点),NO_PREF(无所谓),RACK_LOCAL(指定的机架),ANY(满足不了Task的Locality就随便调度)。这五种Locality级别存在包含关系,RACK_LOCAL包含NODE_LOCAL,NODE_LOCAL包含PROCESS_LOCAL,然而ANY包含其他所有四种。初始化阶段在对Task分类时,根据Task的preferredLocations判断它属于哪个Locality级别,属于PROCESS_LOCAL的Task同时也会被加入到NODE_LOCAL、RACK_LOCAL类别中,比如,一个Task的preferredLocations指定了在Executor-2上执行,那么它属于Executor-2对应的PROCESS_LOCAL类别,同时也把他加入到Executor-2所在的主机对应的NODE_LOCAL类别,Executor-2所在的主机的机架对应的RACK_LOCAL类别中,以及ANY类别,这样在调度执行时,满足不了PROCESS_LOCAL,就逐步退化到NODE_LOCAL,RACK_LOCAL,ANY。
TaskSetManager在决定调度哪些Task时,是通过上面流程图中的resourceOffer方法来实现,为了尽可能地将Task调度到它的preferredLocations上,它采用一种延迟调度算法。resourceOffer方法原型如下,参数包括要调度任务的Executor Id、主机地址以及最大可容忍的Locality级别。
def resourceOffer(execId: String,host: String,maxLocality: TaskLocality.TaskLocality): Option[TaskDescription]延迟调度算法的大致流程如下图所示。
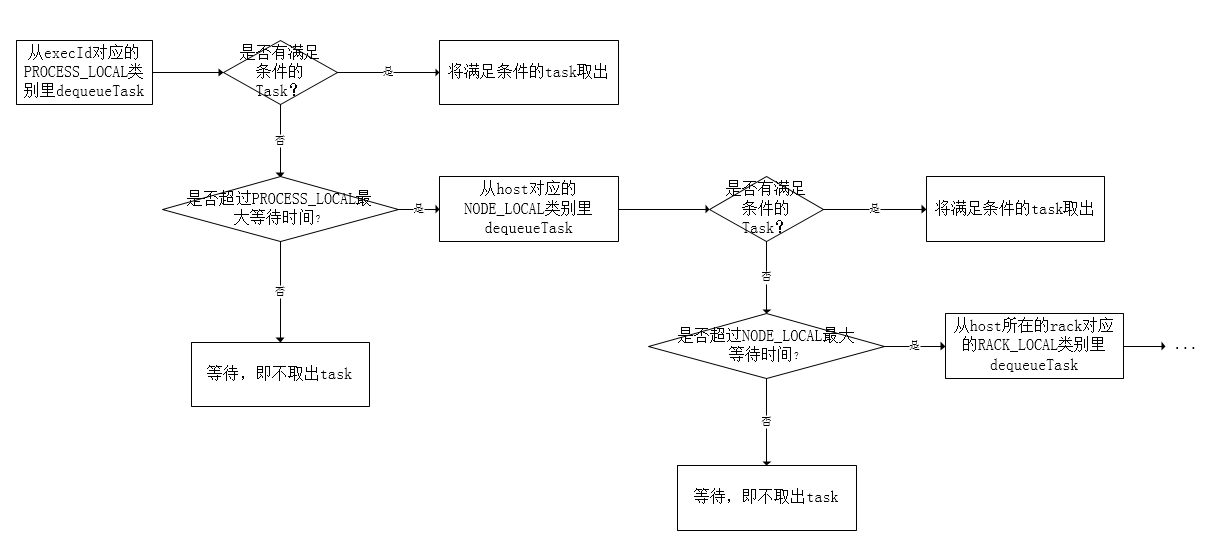
首先看是否存在execId对应的PROCESS_LOCAL类别的任务,如果存在,取出来调度,否则根据当前时间,判断是否超过了PROCESS_LOCAL类别最大容忍的延迟,如果超过,则退化到下一个级别NODE_LOCAL,否则等待不调度。退化到下一个级别NODE_LOCAL后调度流程也类似,看是否存在host对应的NODE_LOCAL类别的任务,如果存在,取出来调度,否则根据当前时间,判断是否超过了NODE_LOCAL类别最大容忍的延迟,如果超过,则退化到下一个级别RACK_LOCAL,否则等待不调度,以此类推…..。当不满足Locatity类别会选择等待,直到下一轮调度重复上述流程,如果你比较激进,可以调大每个类别的最大容忍延迟时间,如果不满足Locatity时就会等待多个调度周期,直到满足或者超过延迟时间退化到下一个级别为止。
失败重试与黑名单机制
除了选择合适的Task调度运行外,还需要监控Task的执行状态,前面也提到,与外部打交道的是SchedulerBackend,Task被提交到Executor启动执行后,Executor会将执行状态上报给SchedulerBackend,SchedulerBackend则告诉TaskScheduler,TaskScheduler找到该Task对应的TaskSetManager,并通知到该TaskSetManager,这样TaskSetManager就知道Task的失败与成功状态,对于失败的Task,会记录它失败的次数,如果失败次数还没有超过最大重试次数,那么就把它放回待调度的Task池子中,否则整个Application失败。
在记录Task失败次数过程中,会记录它上一次失败所在的Executor Id和Host,这样下次再调度这个Task时,会使用黑名单机制,避免它被调度到上一次失败的节点上,起到一定的容错作用。黑名单记录Task上一次失败所在的Executor Id和Host,以及其对应的“黑暗”时间,“黑暗”时间是指这段时间内不要再往这个节点上调度这个Task了。
推测式执行
TaskScheduler在启动SchedulerBackend后,还会启动一个后台线程专门负责推测任务的调度,推测任务是指对一个Task在不同的Executor上启动多个实例,如果有Task实例运行成功,则会干掉其他Executor上运行的实例。推测调度线程会每隔固定时间检查是否有Task需要推测执行,如果有,则会调用SchedulerBackend的reviveOffers去尝试拿资源运行推测任务。

检查是否有Task需要推测执行的逻辑最后会交到TaskSetManager,TaskSetManager采用基于统计的算法,检查Task是否需要推测执行,算法流程大致如下图所示。
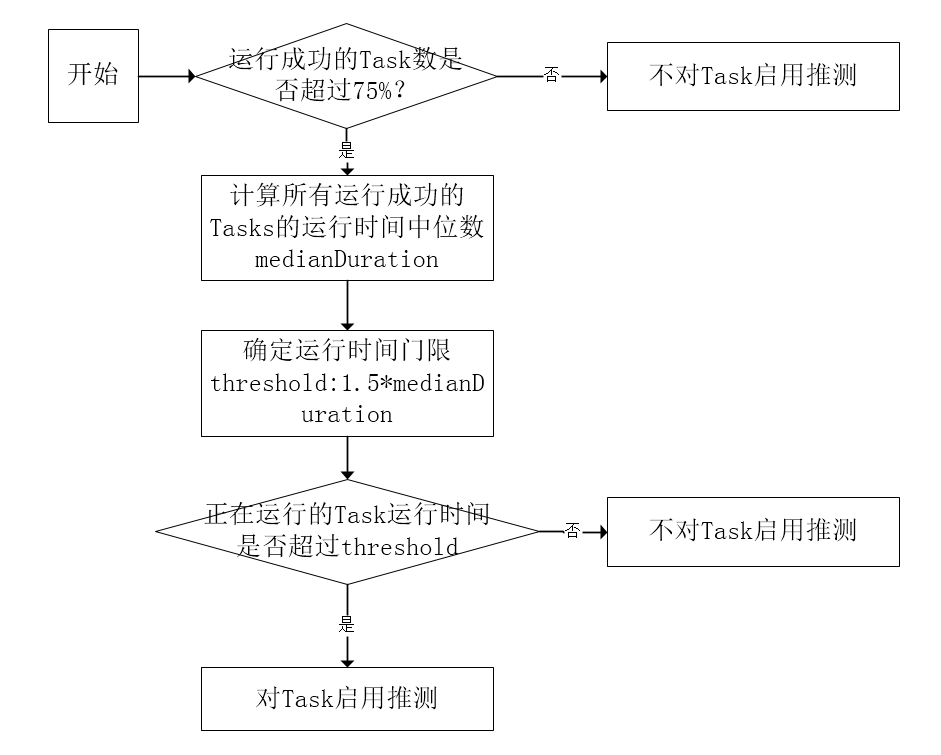
TaskSetManager首先会统计成功的Task数,当成功的Task数超过75%(可通过参数spark.speculation.quantile控制)时,再统计所有成功的Tasks的运行时间,得到一个中位数,用这个中位数乘以1.5(可通过参数spark.speculation.multiplier控制)得到运行时间门限,如果在运行的Tasks的运行时间超过这个门限,则对它启用推测。算法逻辑较为简单,其实就是对那些拖慢整体进度的Tasks启用推测,以加速整个TaskSet即Stage的运行。
资源申请机制
在前文已经提过,ApplicationMaster和SchedulerBackend起来后,SchedulerBackend通过ApplicationMaster申请资源,ApplicationMaster就是用来专门适配YARN申请Container资源的,当申请到Container,会在相应Container上启动Executor进程,其他事情就交给SchedulerBackend。Spark早期版本只支持静态资源申请,即一开始就指定用多少资源,在整个Spark应用程序运行过程中资源都不能改变,后来支持动态Executor申请,用户不需要指定确切的Executor数量,Spark会动态调整Executor的数量以达到资源利用的最大化。
静态资源申请
静态资源申请是用户在提交Spark应用程序时,就要提前估计应用程序需要使用的资源,包括Executor数(num_executor)、每个Executor上的core数(executor_cores)、每个Executor的内存(executor_memory)以及Driver的内存(driver_memory)。
在估计资源使用时,应当首先了解这些资源是怎么用的。任务的并行度由分区数(Partitions)决定,一个Stage有多少分区,就会有多少Task。每个Task默认占用一个Core,一个Executor上的所有core共享Executor上的内存,一次并行运行的Task数等于num_executor*executor_cores,如果分区数超过该值,则需要运行多个轮次,一般来说建议运行3~5轮较为合适,否则考虑增加num_executor或executor_cores。由于一个Executor的所有tasks会共享内存executor_memory,所以建议executor_cores不宜过大。executor_memory的设置则需要综合每个分区的数据量以及是否有缓存等逻辑。下图描绘了一个应用程序内部资源利用情况。
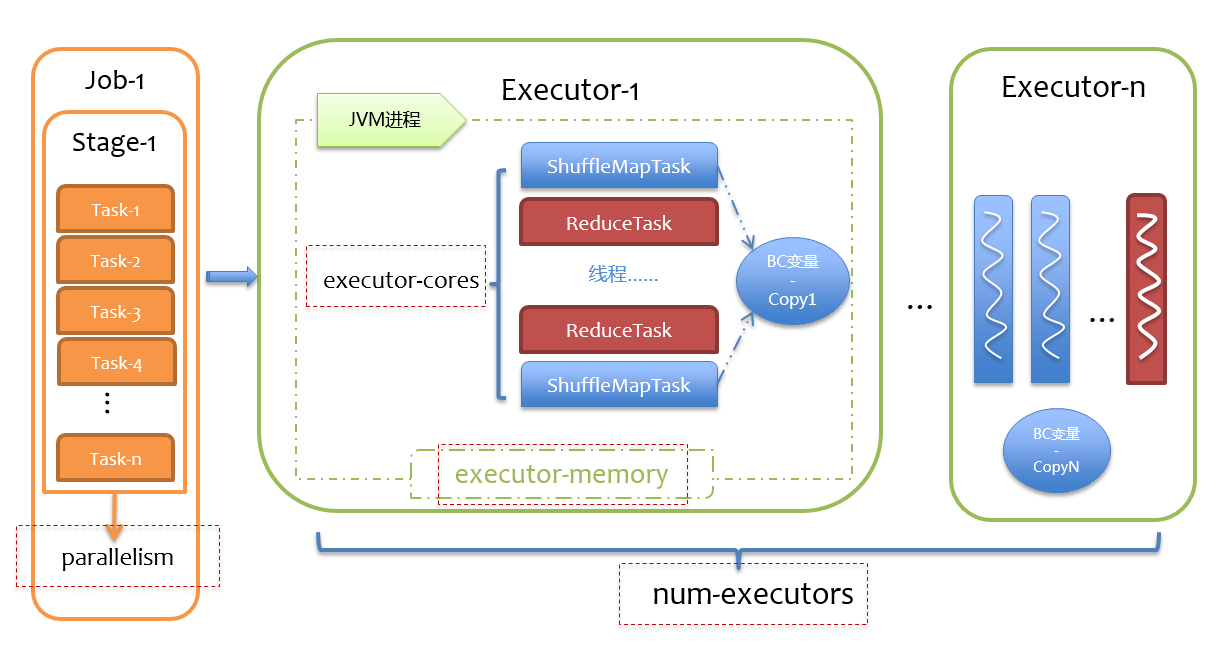
动态资源申请
动态资源申请目前只支持到Executor,即可以不用指定num_executor,通过参数spark.dynamicAllocation.enabled来控制。由于许多Spark应用程序一开始可能不需要那么多Executor或者其本身就不需要太多Executor,所以不必一次性申请那么多Executor,根据具体的任务数动态调整Executor的数量,尽可能做到资源的不浪费。由于动态Executor的调整会导致Executor动态的添加与删除,如果删除Executor,其上面的中间Shuffle结果可能会丢失,这就需要借助第三方的ShuffleService了,如果Spark是部署在Yarn上,则可以在Yarn上配置Spark的ShuffleService,具体操作仅需做两点:
- 首先在yarn-site.xml中加上如下配置:
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle,spark_shuffle</value> </property> <property><name>yarn.nodemanager.aux-services.spark_shuffle.class</name><value>org.apache.spark.network.yarn.YarnShuffleService</value> </property> <property><name>spark.shuffle.service.port</name><value>7337</value> </property>- 将Spark ShuffleService jar包$SPARK_HOME/lib/spark-*-yarn-shuffle.jar拷贝到每台NodeManager的$HADOOP_HOME/share/hadoop/yarn/lib/下,并重启所有的NodeManager。
当启用动态Executor申请时,在SparkContext初始化过程中会实例化ExecutorAllocationManager,它是被用来专门控制动态Executor申请逻辑的,动态Executor申请是一种基于当前Task负载压力实现动态增删Executor的机制。一开始会按照参数spark.dynamicAllocation.initialExecutors设置的初始Executor数申请,然后根据当前积压的Task数量,逐步增长申请的Executor数,如果当前有积压的Task,那么取积压的Task数和spark.dynamicAllocation.maxExecutors中的最小值作为Executor数上限,每次新增加申请的Executor为2的次方,即第一次增加1,第二次增加2,第三次增加4,…。另一方面,如果一个Executor在一段时间内都没有Task运行,则将其回收,但是在Remove Executor时,要保证最少的Executor数,该值通过参数spark.dynamicAllocation.minExecutors来控制,如果Executor上有Cache的数据,则永远不会被Remove,以保证中间数据不丢失。
希望后续可以改下。。。
参考:Spark Scheduler内部原理剖析 spark DAGScheduler、TaskSchedule、Executor执行task源码分析 Spark核心作业调度和任务调度之DAGScheduler源码 Spark Scheduler模块详解-DAGScheduler实现