PySparkSQL之PySpark解析Json集合数据
数据样本
12341234123412342|asefr-3423|[{"name":"spark","score":"65"},{"name":"airlow","score":"70"},{"name":"flume","score":"55"},{"name":"python","score":"33"},{"name":"scala","score":"44"},{"name":"java","score":"70"},{"name":"hdfs","score":"66"},{"name":"hbase","score":"77"},{"name":"qq","score":"70"},{"name":"sun","score":"88"},{"name":"mysql","score":"96"},{"name":"php","score":"88"},{"name":"hive","score":"97"},{"name":"oozie","score":"45"},{"name":"meizu","score":"70"},{"name":"hw","score":"32"},{"name":"sql","score":"75"},{"name":"r","score":"64"},{"name":"mr","score":"83"},{"name":"kafka","score":"64"},{"name":"mo","score":"75"},{"name":"apple","score":"70"},{"name":"jquery","score":"86"},{"name":"js","score":"95"},{"name":"pig","score":"70"}]正菜:
#-*- coding:utf-8 –*- from __future__ import print_function from pyspark import SparkContext from pyspark.sql import SQLContext from pyspark.sql.types import Row, StructField, StructType, StringType, IntegerType import sys reload(sys) import jsonif __name__ == "__main__":sc = SparkContext(appName="PythonSQL")sqlContext = SQLContext(sc)fileName = sys.argv[1]lines = sc.textFile(fileName)sc.setLogLevel("WARN")def parse_line(line):fields=line.split("|",-1)keyword=fields[2]return keyworddef parse_json(keyword):return keyword.replace("[","").replace("]","").replace("},{","}|{")keywordRDD = lines.map(parse_line)#print(keywordRDD.take(1))#print("---------------") jsonlistRDD = keywordRDD.map(parse_json)#print(jsonlistRDD.take(1)) jsonRDD = jsonlistRDD.flatMap(lambda jsonlist:jsonlist.split("|"))schema = StructType([StructField("name", StringType()),StructField("score", IntegerType())])df = sqlContext.read.schema(schema).json(jsonRDD)# df.printSchema()# df.show() df.registerTempTable("json")df_result = sqlContext.sql("SELECT name,score FROM json WHERE score > 70")df_result.coalesce(1).write.json(sys.argv[2])sc.stop()
提交作业
spark-submit .\demo2.py "C:\\Users\\txdyl\\Desktop\\test.txt" "c:\\users\\txdyl\\Desktop\\output"
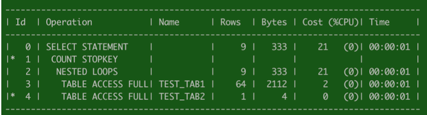
数据结果