(DBA之路【五】)关于锁的故事
首先很抱歉:这篇文章我其实整合了很多别人的文章,但是因为太多,一开始被没留意出处所以很难声明来源,很抱歉,但是这篇文章只用来作为学习笔记,作为新手,我以后会注意的。
(一):什么是锁:
我觉得锁这个东西就像未退出的word文档,begin开始事务后到commit之前,如果做错了可以rollbak回滚。
有了锁之后,不像antocommit那样每句提交浪费效率,而且innodb还有行锁,这样也不占内存,修改效率高。
锁的分类:
读锁:
也叫共享锁、S锁,若事务T对数据对象A加上S锁,则事务T可以读A但不能修改A,其他事务只能再对A加S锁,而不能加X锁,直到T释放A上的S 锁。这保证了其他事务可以读A,但在T释放A上的S锁之前不能对A做任何修改。
写锁:
又称排他锁、X锁。若事务T对数据对象A加上X锁,事务T可以读A也可以修改A,其他事务不能再对A加任何锁,直到T释放A上的锁。这保证了其他事务在T释放A上的锁之前不能再读取和修改A。
表锁:操作对象是数据表。Mysql大多数锁策略都支持(常见mysql innodb),是系统开销最低但并发性最低的一个锁策略。事务t对整个表加读锁,则其他事务可读不可写,若加写锁,则其他事务增删改都不行。
行级锁:操作对象是数据表中的一行。是MVCC技术用的比较多的,但在MYISAM用不了,行级锁用mysql的储存引擎实现而不是mysql服务器。但行级锁对系统开销较大,处理高并发较好。
(二)MySQL锁概述
相对其他数据库而言,MySQL的锁机制比较简单,其最显著的特点是不同的存储引擎支持不同的锁机制。比如,MyISAM和MEMORY存储引擎采用的是表级锁(table-level locking);BDB存储引擎采用的是页面锁(page-level locking),但也支持表级锁;InnoDB存储引擎既支持行级锁(row-level locking),也支持表级锁,但默认情况下是采用行级锁。
开销、加锁速度、死锁、粒度、并发性能
表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低。
行级锁:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
页面锁:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般。
MySQL表级锁的锁模式
MySQL的表级锁有两种模式:表共享读锁(Table Read Lock)和表独占写锁(Table Write Lock)
如何加锁:
例子:lock table actor read;(但是通过别名访问会提示错误)
需要对别名分别锁定:lock table actor as a read,actor as b read;此时按照别名的查询可以正确执行
释放锁
mysql> unlock tables;
(三)大神说的需要的一些基础背景知识:
1)堆组织表:(无序表)此类型的表中,数据会以堆的方式进行管理,增加数据时候,会使用段中找到的第一个能放下
此数据的自由空间。当从表中删除数据时候,则允许以后的UPDATE和INSERT重用这部分空间,它是以一种有些随机的方式使用。
e.g:
create table t(
a int,
b varchar2(4000) default rpad('*', 4000, '*'),
c varchar2(3000) default rpad('*', 3000,'*')
);
insert into t(a) values (1);
insert into t(a) values (2);
insert into t(a) values (3);
delete from t where a=2;
insert into t(a) values (4);
SQL> select a from t;
A
----------
1
4
3
2)索引组织表(index organized table, IOT):就是存储在一个索引结构中的表,数据按主键进行存储和排序。
适用的场景:
a.完全由主键组成的表。这样的表如果采用堆组织表,则表本身完全是多余的开销,
因为所有的数据全部同样也保存在索引里,此时,堆表是没用的。
b.代码查找表。如果你只会通过一个主键来访问一个表,这个表就非常适合实现为IOT.
c.如果你想保证数据存储在某个位置上,或者希望数据以某种特定的顺序物理存储,IOT就是一种合适的结构。 IOT提供如下的好处:
·提高缓冲区缓存效率,因为给定查询在缓存中需要的块更少。
·减少缓冲区缓存访问,这会改善可扩缩性。
·获取数据的工作总量更少,因为获取数据更快。
·每个查询完成的物理I/O更少。
如果经常在一个主键或唯一键上使用between查询,也是如此。如果数据有序地物理存储,就能提升这些查询的性能。
语法:create table indexTable(
ID varchar2 (10),
NAME varchar2 (20),
constraint pk_id primary key (ID)
) organization index;
3)MVCC:mvcc为每个记录行追加了2个列,一个保存了记录的创建时间,也就是insert的插入时间,这个其实是系统的版本号,一个是保存了记录的删除时间,也就是delete的时间,mvcc自身也有当前事务版本号,每次执行操作版本号都会自动自动加一。mvcc要求在select数据的时候,只查找记录的创建系统版本号小于或者等于当前的事务版本号而且行的删除版本号要么未定义要么,要么高于当前的事务版本号即可。
4)二项锁2PL:事务提交后所有锁将会被释放
分为两个阶段:1)无锁释放,全部加锁,且锁的数目只增不减
2)全部释放,一锁都不用
可以简单的理解在事务提交前,加的锁只能增加不能释放,只会越来越多,而事务一旦提交,所有锁将会被释放。
5)查询mysql的sql执行计划(在sql语句前加上explain就行了):即在查询前就能预先估计查询究竟要涉及多少行、使用哪些索引、运行多久这些类似信息。
例子:
EXPLAIN
SELECT COUNT(*) FROM ××××××WHERE XXXXX
EXPLAIN列的解释
table
显示这一行的数据是关于哪张表的
type
这是重要的列,显示连接使用了何种类型。从最好到最差的连接类型为const、eq_reg、ref、range、indexhe和ALL(后面有详细说明)
possible_keys
显示可能应用在这张表中的索引。如果为空,没有可能的索引。可以为相关的域从WHERE语句中选择一个合适的语句
key
实际使用的索引。如果为NULL,则没有使用索引。很少的情况下,MYSQL会选择优化不足的索引。这种情况下,可以在SELECT语句中使用USE INDEX(indexname)来强制使用一个索引或者用IGNORE INDEX(indexname)来强制MYSQL忽略索引
key_len
使用的索引的长度。在不损失精确性的情况下,长度越短越好
ref
显示索引的哪一列被使用了,如果可能的话,是一个常数
rows
MYSQL认为必须检查的用来返回请求数据的行数
Extra
坏的例子是Using temporary和Using filesort,意思MYSQL根本不能使用索引,结果是检索会很慢
extra列返回的描述的意义
Distinct
一旦MYSQL找到了与行相联合匹配的行,就不再搜索了
Not exists
MYSQL优化了LEFT JOIN,一旦它找到了匹配LEFT JOIN标准的行,就不再搜索了
Range checked for each
Record(index map:#)
没有找到理想的索引,因此对于从前面表中来的每一个行组合,MYSQL检查使用哪个索引,并用它来从表中返回行。这是使用索引的最慢的连接之一
Using filesort
看到这个的时候,查询就需要优化了。MYSQL需要进行额外的步骤来发现如何对返回的行排序。它根据连接类型以及存储排序键值和匹配条件的全部行的行指针来排序全部行
Using index
列数据是从仅仅使用了索引中的信息而没有读取实际的行动的表返回的,这发生在对表的全部的请求列都是同一个索引的部分的时候
Using temporary
看到这个的时候,查询需要优化了。这里,MYSQL需要创建一个临时表来存储结果,这通常发生在对不同的列集进行ORDER BY上,而不是GROUP BY上
Where used
使用了WHERE从句来限制哪些行将与下一张表匹配或者是返回给用户。如果不想返回表中的全部行,并且连接类型ALL或index,这就会发生,或者是查询有问题
不同连接类型的解释(按照效率高低的顺序排序)
system
表只有一行:system表。这是const连接类型的特殊情况
const
表中的一个记录的最大值能够匹配这个查询(索引可以是主键或惟一索引)。因为只有一行,这个值实际就是常数,因为MYSQL先读这个值然后把它当做常数来对待
eq_ref
在连接中,MYSQL在查询时,从前面的表中,对每一个记录的联合都从表中读取一个记录,它在查询使用了索引为主键或惟一键的全部时使用
ref
这个连接类型只有在查询使用了不是惟一或主键的键或者是这些类型的部分(比如,利用最左边前缀)时发生。对于之前的表的每一个行联合,全部记录都将从表中读出。这个类型严重依赖于根据索引匹配的记录多少—越少越好
range
这个连接类型使用索引返回一个范围中的行,比如使用>或<查找东西时发生的情况
index
这个连接类型对前面的表中的每一个记录联合进行完全扫描(比ALL更好,因为索引一般小于表数据)
ALL
这个连接类型对于前面的每一个记录联合进行完全扫描,这一般比较糟糕,应该尽量避免
6)mysql不同扫描方式分析
(下面的数据来自扫描少量数据)


查询是否存在缓存,打开表及锁表这些操作时间是差不多,我们不会计入。具体还是看init,optimizing等环节消耗的时间。
1.从这个表中,我们看到非主键索引和覆盖索引在准备时间上需要开销很多的时间,预估这两种查询方式都需要进行回表操作,所以花在准备上更多时间。
2.第二项optimizing上,可以清晰知道,覆盖索引话在优化上大量的时间,这样在二级索引上就无需回表。
3. Sendingdata,全表扫描慢就慢在这一项上,因为是加载所有的数据页,所以花费在这块上时间较大,其他三者都差不多。
4. 非主键查询话在freeingitems上时间最少,那么可以看出它在读取数据块的时候最少。
5.相比较主键查询和非主键查询,非主键查询在Init,statistics都远高于主键查询,只是在freeingitems开销时间比主键查询少。因为这里测试数据比较少,但是我们可以预见在大数据量的查询上,不走缓存的话,那么主键查询的速度是要快于非主键查询的,本次数据不过是太小体现不出差距而已。
6.在大多数情况下,全表扫描还是要慢于索引扫描的。
tips:
过程中的辅助命令:
1.清楚缓存
reset query cache ;
flush tables;
2.查看表的索引:
show index from tablename;
7)Mysql5.6里的index_condition_pushdown:指的是在存储器引擎层面先过滤了信息,在进行sql语句里的具体查询等工作,有时可能会比主键扫描等更慢。
8)semi-consistent read(仅仅针对于update操作):是read committed与consistent read两者的结合。一个update语句,如果读到一行已经加锁的记录,此时InnoDB返回记录最近提交的版本,由MySQL上层判断此版本是否满足update的where条件。若满足(需要更新),则MySQL会重新发起一次读操作,此时会读取行的最新版本(并加锁)。
semi-consistent read只会发生在read committed隔离级别下,或者是参数innodb_locks_unsafe_for_binlog被设置为true。
semi-consistent优缺点分析
优点
减少了更新同一行记录时的冲突,减少锁等待。
无并发冲突,读记录最新版本并加锁;有并发冲突,读事务最新的commit版本,不加锁,无需锁等待。
可以提前放锁,进一步减少并发冲突概率。
对于不满足update更新条件的记录,可以提前放锁,减少并发冲突的概率。
在理解了semi-consistent read原理及实现方案的基础上,可以酌情考虑使用semi-consistent read,提高系统的并发性能。
缺点
非冲突串行化策略,因此对于binlog来说,是不安全的
两条语句,根据执行顺序与提交顺序的不同,通过binlog复制到备库后的结果也会不同。不是完全的冲突串行化结果。
因此只能在事务的隔离级别为read committed(或以下),或者设置了innodb_locks_unsafe_for_binlog参数的情况下才能够使用。
9)产生死锁的条件:
(1) 互斥条件:一个资源每次只能被一个进程使用。
(2) 请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
(3) 不剥夺条件:进程已获得的资源,在末使用完之前,不能强行剥夺。
(4) 循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
(四)说说MYSQL中具体的问题
MyISAM的锁问题
并发插入(Concurrent Inserts)
上文提到过MyISAM表的读和写是串行的,但这是就总体而言的。在一定条件下,MyISAM表也支持查询和插入操作的并发进行。
MyISAM存储引擎有一个系统变量concurrent_insert,专门用以控制其并发插入的行为,其值分别可以为0、1或2。l
当concurrent_insert设置为0时,不允许并发插入。
当concurrent_insert设置为1时,如果MyISAM表中没有空洞(即表的中间没有被删除的行),MyISAM允许在一个进程读表的同时,另一个进程从表尾插入记录。这也是MySQL的默认设置。
当concurrent_insert设置为2时,无论MyISAM表中有没有空洞,都允许在表尾并发插入记录。
优先级以及调度
写进程永远在读进程前
如何调度
1)通过指定启动参数low-priority-updates,使MyISAM引擎默认给予读请求以优先的权利。
2)通过执行命令SET LOW_PRIORITY_UPDATES=1,使该连接发出的更新请求优先级降低。
3)通过指定INSERT、UPDATE、DELETE语句的LOW_PRIORITY属性,降低该语句的优先级。
虽然上面3种方法都是要么更新优先,要么查询优先的方法,但还是可以用其来解决查询相对重要的应用(如用户登录系统)中,读锁等待严重的问题。
另外,MySQL也提供了一种折中的办法来调节读写冲突,即给系统参数max_write_lock_count设置一个合适的值,当一个表的读锁达到这个值后,MySQL就暂时将写请求的优先级降低,给读进程一定获得锁的机会。
InnoDB锁问题
innodb行锁分类
record lock:记录锁,也就是仅仅锁着单独的一行
gap lock:区间锁,仅仅锁住一个区间(注意这里的区间都是开区间,也就是不包括边界值。
next-key lock:record lock+gap lock,所以next-key lock也就半开半闭区间,且是下界开,上界闭。
next-key 锁定范围:(负无穷大,最小第一记录],(记录之间],(最大记录,正无穷大)
IX,IS为表锁,一下为这四种锁的冲突情况。

1)并发事务处理带来的问题
相对于串行处理来说,并发事务处理能大大增加数据库资源的利用率,提高数据库系统的事务吞吐量,从而可以支持更多的用户。但并发事务处理也会带来一些问题,主要包括以下几种情况。
更新丢失(lost update):当两个或多个事务选择同一行,由于每个事务都不知道其他事务的存在,就会发生丢失更新问题--最后的更新覆盖了由其他事务所做的更新。例如,两个编辑人员制作了同一文档的电子副本。每个编辑人员独立地更改其副本,然后保存更改后的副本,这样就覆盖了原始文档。最后保存其更改副本的编辑人员覆盖另一个编辑人员所做的更改。如果在一个编辑人员完成并提交事务之前,另一个编辑人员不能访问同一文件,则可避免此问题。
脏读 :就是读取未提交的数据,根据未提交的数据而进一步做相应的操作会发生错误。
e.g.
1.Mary的原工资为1000, 财务人员将Mary的工资改为了8000(但未提交事务)
2.Mary读取自己的工资 ,发现自己的工资变为了8000,欢天喜地!
3.而财务发现操作有误,回滚了事务,Mary的工资又变为了1000
像这样,Mary记取的工资数8000是一个脏数据。
不可重复读 :重点在修改内容,两次读取的内容不一样。是指在一个事务内,多次读同一数据。在这个事务还没有结束时,另外一个事务也访问该同一数据,那么两次读取到的内容就可能不一样。
e.g.
1.在事务1中,Mary 读取了自己的工资为1000,操作并没有完成
2.在事务2中,这时财务人员修改了Mary的工资为2000,并提交了事务.
3.在事务1中,Mary 再次读取自己的工资时,工资变为了2000
解决办法:如果只有在修改事务完全提交之后才可以读取数据,则可以避免该问题。
幻读 :重点在增加、删除,两次读取到的记录数不一样。 是指当事务不是独立执行时发生的一种现象,例如第一个事务对一个表中的数据进行了修改,这种修改涉及到表中的全部数据行。同时,第二个事务也修改这个表中的数据,这种修改是向表中插入一行新数据。那么,以后就会发生事务一两次读取到了两个不同的数目。
e.g.
目前工资为1000的员工有10人。
1.事务1,读取所有工资为1000的员工。
2.这时事务2向employee表插入了一条员工记录,工资也为1000
3.事务1再次读取所有工资为1000的员工 共读取到了11条记录
2)innodb锁争用解决
通过设置InnoDB Monitors来进一步观察发生锁冲突的表、数据行等,并分析锁争用的原因。
具体方法如下:
mysql> CREATE TABLE innodb_monitor(a INT) ENGINE=INNODB;
Query OK, 0 rows affected (0.14 sec)
然后就可以用下面的语句来进行查看:
mysql> Show innodb status\G;
监视器可以通过发出下列语句来停止查看:
mysql> DROP TABLE innodb_monitor;
Query OK, 0 rows affected (0.05 sec)
设置监视器后,在SHOW INNODB STATUS的显示内容中,会有详细的当前锁等待的信息,包括表名、锁类型、锁定记录的情况等,便于进行进一步的分析和问题的确定。打开监视器以后,默认情况下每15秒会向日志中记录监控的内容,如果长时间打开会导致.err文件变得非常的巨大,所以用户在确认问题原因之后,要记得删除监控表以关闭监视器,或者通过使用“--console”选项来启动服务器以关闭写日志文件。
InnoDB行锁实现方式
InnoDB行锁是通过给索引上的索引项加锁来实现的。只有通过索引条件检索数据,InnoDB才使用行级锁,否则,InnoDB将使用表锁!
SQL 标准中定义了 4 个隔离级别: read uncommited , read commited , repeatable read , serializable 。
read uncommited 即脏读,一个事务修改了一行,另一个事务也可以读到该行。如果第一个事务执行了回滚,那么第二个事务读取的就是从来没有正式出现过的值。
read commited 即一致读,试图通过只读取提交的值的方式来解决脏读的问题,但是这又引起了不可重复读取的问题。
repeatable read 即可重复读,在一个事务对数据行执行读取或写入操作时锁定了这些数据行。(innodb默认)
serializable即可串行操作:在数据表上放置了排他锁,以防止在事务完成之前由其他用户更新行或向数据集中插入行,这是最严格的锁。它防止了脏读、不可重复读取和幻象数据。但是因为innodb为并行操作所以不建议用此模式。
转载于:https://blog.51cto.com/10170308/1660293
相关文章:

Android Studio Day03-1(Android studio 系统界面简介)
IDE(integrated Development Environment)的主要的目的就是用来编辑文本的。 在界面中的分布如下(以下的两张图片均为的《Android studio实战快速高效地构建Android应用》一书中的)

全流程游戏模型制作学习教程
尤金彼得罗夫|时长:36小时 |视频:H264 19201080 |音频:AAC 44,1 kHz 2ch |大小解压后 35 GB 含课程文件 |语言:英语 (无字幕,) 在本教程中,我将介绍为现代FPS视频游戏创建游戏就绪武器资产的整个过程。我将展示我的工作管道,使用…
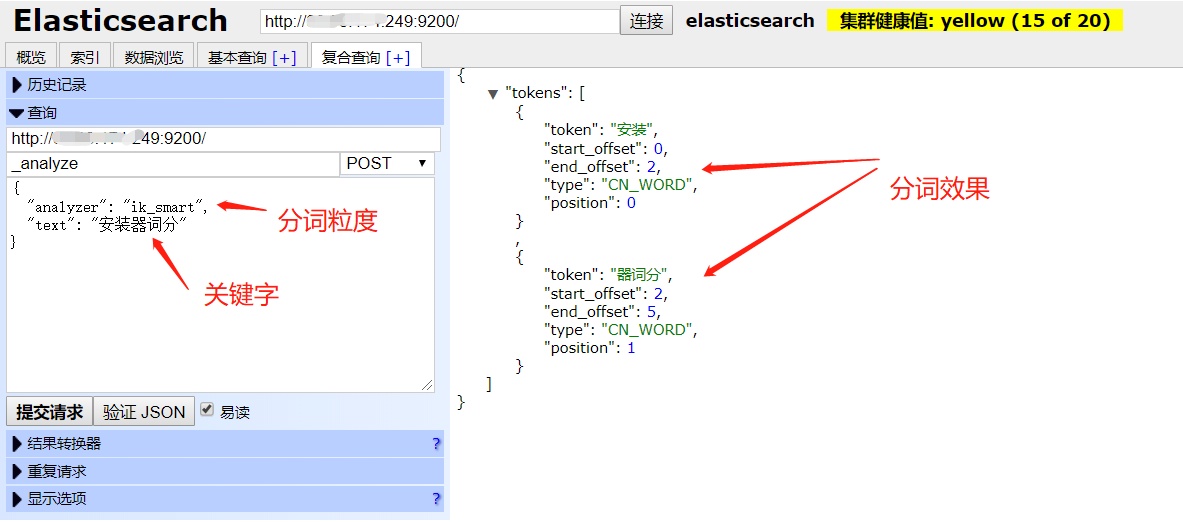
requirednew基于xml配置日志不回滚_Elasticsearch配置IK分词器的远程词库
在生活中很多很多地方都涉及到了全文检索,最常见的就好比日常使用到的百度搜索等搜索引擎,也都是基于全文检索来实现的;全文检索种类较多,就好比Elasticsearch、Sorl等。为Ealsticsearch配置词库,可以很好的解决生活中…
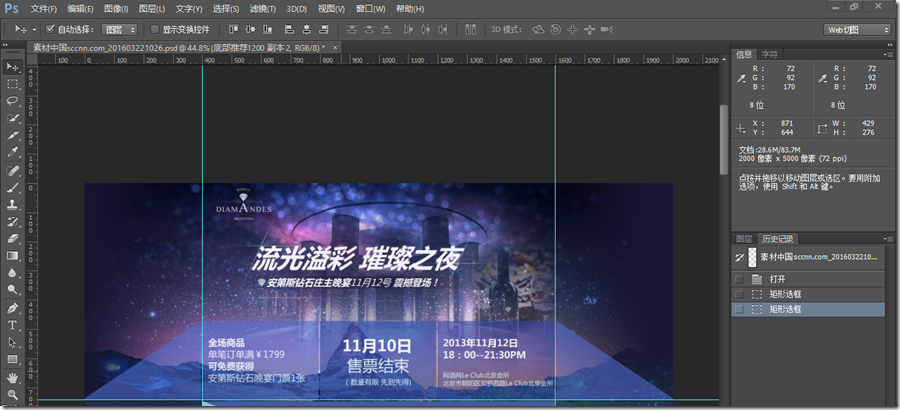
PS切图篇(一)---界面设置
#工作区设置 四大主要面板:信息 字符 图层 历史记录 打开必要属性: 选择工具设置 选择图层的方式:ctrl鼠标左击想选择的图层转载于:https://www.cnblogs.com/yinzf/p/5339873.html
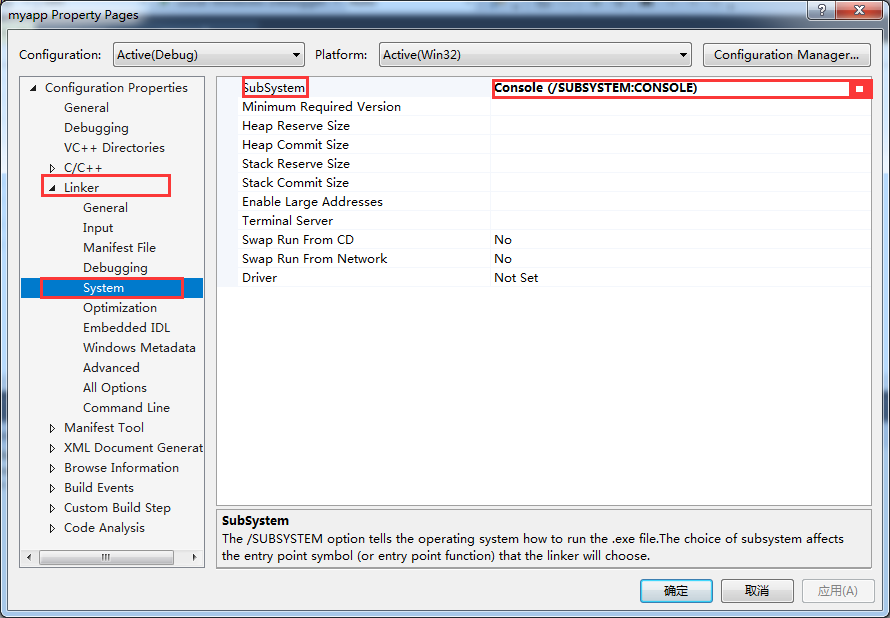
简单解决用VS编写hello world时命令行一闪而过
一、在return 0;前一行加一个getchar(); 二、使用项目模板为 windows 桌面向导 c 3、命令行控制台一闪而过。这是我们使用空文件夹加载的项目,默认不是控制台应用程序,新建控制台程序,或者在代码中加入system(“pause”);这种通过代码人为的…

粒子群算法(1)----粒子群简要
一、历史粒子群算法从复杂适应系统衍生PSO算法(Complex Adaptive System,CAS)。CAS理论于1994年正式提出,CAS中的成员称为主体。比方研究鸟群系统,每一个鸟在这个系统中就称为主体。主体有适应性,它能够与环境及其它的…

Android Studio Day03-2(常用操作)
(1)选择文本 1.CtrlA 选中全文 2.在将光标置于任意的单词中时按住CtrlW,选中整个词 继续按CtrlW 选中的区域将扩大,扩大至包含任意数量的相邻的单词 按CtrlwShift 进行区域的缩小 (2)Undo和Redo&…

Blender数字雕刻终极指南学习教程
CGBoost–Blender中的3D雕刻大师–数字雕刻终极指南 大小:29G 含课程项目文件 Master 3D Sculpting in Blender – The Ultimate Guide to Digital Sculpting 本课程教你所有重要的Blender雕刻基础知识,以及如何仅使用免费工具从头开始创建令人惊叹的3D雕…

生产指挥调度系统_市安全生产应急救援指挥中心将大型装载机械设备储备信息纳入应急指挥调度系统...
为拓展应急救援力量体系,发挥社会力量在开展全市重特大突发事件应急救援中的重要作用,近日,市安全生产应急救援指挥中心在加强应急指挥信息平台“一网七库”建设的基础上,成功对接甘肃省非道路移动机械监管平台,做到数…
java.sql.Exception:setString 只能处理少于 32766 个字符的字符串
java.sql.Exception:setString 只能处理少于 32766 个字符的字符串 解决方式是 : 升级ojdbc的版本, 将原来的 ojdbc14_10.2.0.2.0.jar 升级到 ojdbc6_11.2.0.1.0.jar这边行方用的是 oracle版本是 Oracle Database 11g Enterprise Edition Release 11.2.0.4.0maven 安装到本地…
无需自己输入include这些的方法
使用项目模板为 windows 桌面向导 c 不用空白项 直接默认 不用勾选其他
第二次团队冲刺2
实现了查询的webservice服务端,做了查询时等待界面,对查询速度做了一点优化。 还写了一个入馆须知模块,介绍图书馆借阅规则。 还有借阅个人信息没做出来,还没进行界面优化。 转载于:https://www.cnblogs.com/318abc/p/4569576.htm…

Android StudioDay03-3(键盘导航)
Android Studio Day03-3(键盘导航) (1)打开Select In 快捷键:altF1 如下图: (2)打开Class CtrlN Class操作允许用后导航到特定的JAVA类),因此此操作也只能在Java文件中使用。 Android studio已…

虚幻中的风格化环境制作学习教程
Learn Squared-Tyler Smith-虚幻中的风格化环境 信息: 像AAA游戏开发者一样在虚幻引擎中创建风格化的环境。行业领先的游戏艺术家泰勒史密斯将教你在虚幻引擎中构建美丽的实时世界的规划、构建、集成和优化阶段使用多种巧妙的技术。 大小解压后:22G 时长6h 13m 19…
【转】oracle PLSQL基础学习
【转】oracle PLSQL基础学习 --oracle 练习;/**************************************************PL/SQL编程基础***************************************************************/--firstday--》》》数据类型-- Create tablecreate table T_CSCUSTOMER( CUST_NO…
python如何创建不同元素的矩阵_python – 如何在数据帧中创建矩阵元素的数...
我在.TXT文件中有3个参数’A’,’B’,’C’的数据集,在我用2420矩阵打印后,我需要收集’A’,’B’,’C’的第一个元素熊猫数据帧中的长数组,然后是每个第二个元素,然后是第3个,直到第480个元素为止. 所以我的数据在文本文件中是这样的: 我的数据是txt文件如下&#…
wps多窗口打开
在wps中打开wps文档不在一个窗口的方法如下: 1、启动wps文档,点击wps文字→选项,在弹出的选项对话框点击视图选项卡,勾选 在任务栏中显示所有窗口;
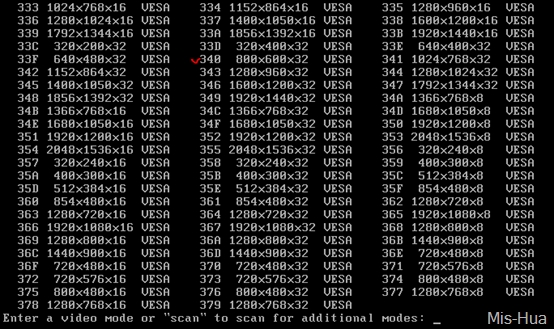
RHEL7.0系列 修改字符终端分辨率
由于是在VM里面安装的,完了之后终端界面的分辨率非常高,很难操作 因为RHEL7用了grub2,而不再是grub了,在grub2中要修改的文件是/boot/grub2/grub.cfg; 这里有一张分辨率的对照表(在grub.cfg中添加vgaask,系统重启后就会…

Java Day01-1
1.JAVA语言介绍 (1)特点:可移植性,平台无关性,面相对性,健壮性,分布式,多线程 (2)版本:JavaSE(标准版)、JavaME…

Autocad 3D 完全学习教程
Autocad 3D 完全学习教程 你会学到什么 如何使用AutoCAD三维基本特征 了解如何在AutoCAD中创建和开发三维模型 准备实体、网格和曲面几何图形 不同的命令2d和3D 要求 不需要事先了解 18章 63节讲座 全长5小时7分 语言:英语中英文字幕(根据原英文字幕机译…

[转]JAVA中Action层, Service层 ,modle层 和 Dao层的功能区分
首先这是现在最基本的分层方式,结合了SSH架构。modle层就是对应的数据库表的实体类。Dao层是使用了Hibernate连接数据库、操作数据库(增删改查)。Service层:引用对应的Dao数据库操作,在这里可以编写自己需要的代码&…

springmvc工作流程简单易懂_三极管的结构和工作特性,简单易懂
今天,我们来认识另一种十分重要的半导体器件:三极管。生活中,授课、集会、维持秩序等场合需要用到扩音器、音响等设备,这些设备之所以能够放大声音是因为它们都包含放大器,而放大器的核心部件就是三极管。那三极管究竟…
多个excel文件(内含多个工作表)查找
1.在父目录查找处输入关键词 2.将找到的文件进去查找-工作簿

git ssh key创建和github使用
github拉代码需要ssh验证 git是分布式的代码管理工具,远程的代码管理是基于ssh的,所以要使用远程的git则需要ssh的配置。一 、设置git:设置git的user name和email:$ git config --global user.name "xxx"$ git config -…
C语言常见面试题:什么是变量?变量有哪些作用?
变量是编程中的一个基本概念,其定义和用法因编程语言和上下文而异。但通常来说,变量是用于存储数据的容器,这些数据可以是数字、文本、布尔值等。总的来说,变量在编程中扮演着重要的角色,它们使得我们能够有效地存储、操作和使用数据。不同的编程语言和上下文可能会对变量的具体定义和使用方式有所不同,但上述作用是通用的。总的来说,变量和常量都是编程中重要的概念,它们各自有其特定的用途和特性。在编程中正确地使用它们可以帮助我们更好地组织和控制程序的行为。变量和常量在编程中都是重要的概念,但它们之间存在明显的区别。

Java Day01-2
一、字节码的解释 字节码:是一种在Java运行系统(JVM)中执行的更高度优化的指令集。 C/C 是一种编译型的语言; 文件经过编辑,编译,执行之后生成的是一种.exe的可执行文件。 Java:是一种解释型的语言&…

SparkSQL和Hadoop(面向数据科学家和大数据分析师)
了解HDFS命令、Hadoop、Spark SQL、SQL查询、ETL和数据分析| Spark Hadoop集群虚拟机|完全解决的问题 你会学到什么 作为本课程的一部分,学生将获得在Spark Hadoop环境中工作的实践经验,该环境是免费且可下载的。 学生将有机会在沙箱环境中使用Hadoop集…
uva 401.Palindromes
题目链接:https://uva.onlinejudge.org/index.php?optioncom_onlinejudge&Itemid8&pageshow_problem&problem342 题目意思:给出一段字符串(大写字母数字组成)。判断是否为回文串 or 镜像串 or 回文镜像串 or 什么都不…
python解压_python解压缩
解压缩 如果我们给出一个列表,我们需要一次性取出多个值,我们是不是可以用下面的方式实现呢? name_list [chen, python, jason] x name_list[0] y name_list[1] z name_list[2] print(fx:{x}, y:{y}, z:{z}) #输出: x:chen, y…

用Construct 2制作入门小游戏~
今天在软导课上了解到了Construct 2这个神器,本零基础菜鸟决定尝试做一个简单的小游戏(实际上是入门的教程啊 首先呢,肯定是到官网下载软件啊,点击我下载~ 等安装完毕后我便按照新手教程开始捣鼓了 ①先下载素材(准…