mybatis-plus对datetime返回去掉.0_华为AI认证-TensorFlow2.0编程基础

参考《HCIA-AI2.0培训教材》《HCIA-AI2.0实验手册》
认证要求:
- 了解TensorFlow2.0是什么以及其特点
- 掌握TensorFlow2.0基础和高阶操作方法
- 熟悉TensorFlow2.0中的Keras API
简介:
TensorFlow是目前最为流行的深度学习框架,是人工智能领域的第一主要工具。从发布至今,共经历了0.1,1.0,2.0三个版本,认证考试要求掌握的是最新的2.0版本。
TensorFlow1.X中创建Tensor后,不能直接返回结果,只是创建计算图graph,需要在之后使用session会话机制才能运行,这种风格更像是一种硬件编程语言VHDL。
另外,TensorFlow1.X调试困难,API混乱,入门不易,使用更难,很多研究人员转向了PyTorch,但是比如在移动端的部署还是非常头疼。
TensorFlow2.0最大的特性就是去掉了graph和session机制,变得像Python和PyTorch一样,所见即所得。计算图、会话、变量管理与共享、Define-and-Run这些概念将一去不返了。
TensorFlow2.0包括了TensorFlow核心库,JavaScript,Lite,Extend。构成了一个完整的TensorFlow生态系统。
Why TensorFlow?
TensorFlow成为当下最流行的框架主要因为以下几个优势:
- 支持GPU加速
- 支持自动求导
- 丰富的深度学习API
GPU可以对矩阵的加减乘除做并行加速:
import tensorflow as tf
import timeit
with tf.device('/cpu:0'):cpu_a = tf.random.normal([10000,1000])cpu_b = tf.random.normal([1000,2000])print(cpu_a.device,cpu_b.device)def cpu_run():with tf.device('/cpu:0'):c = tf.matmul(cpu_a,cpu_b)return cwith tf.device('/gpu:0'):gpu_a = tf.random.normal([10000,1000])gpu_b = tf.random.normal([1000,2000])print(gpu_a.device,gpu_b.device)def gpu_run():with tf.device('/gpu:0'):d = tf.matmul(gpu_a,gpu_b)return d# warm up
cpu_time = timeit.timeit(cpu_run,number=10)
gpu_time = timeit.timeit(gpu_run,number=10)print('warm up: ',cpu_time,gpu_time)# run time
cpu_time = timeit.timeit(cpu_run,number=10)
gpu_time = timeit.timeit(gpu_run,number=10)print('run time: ',cpu_time,gpu_time)
自动求导tf.Gradient(Tape):
import tensorflow as tfa = tf.constant(1.)
b = tf.constant(2.)
c = tf.constant(4.)with tf.GradientTape() as tape:tape.watch([a,b,c])y = a**2 + b*c + c[da,db,dc] = tape.gradient(y,[a,b,c])print(da)
print(db)
print(dc)
TensorFlow提供大量的深度学习API:

Tensorflow2.0 GPU环境搭建(linux平台下)
Nvidia显卡驱动:需要在Nvidia官网https://www.nvidia.com/Download/index.aspx?lang=en-us查询显卡对应的驱动包,下载。下面提供了一个适合RTX 20XX系列的安装包的百度云链接。链接:https://pan.baidu.com/s/1b1daIaMaz7-oy28sMLjysA 密码:4jeg
下载后进入tty3命令行模式,关闭lightdm,禁用nouveau显卡驱动,并安装Nividia显卡驱动程序,最后重启lightdm回到图形界面。
执行nvidia-smi,验证是否安装成功。
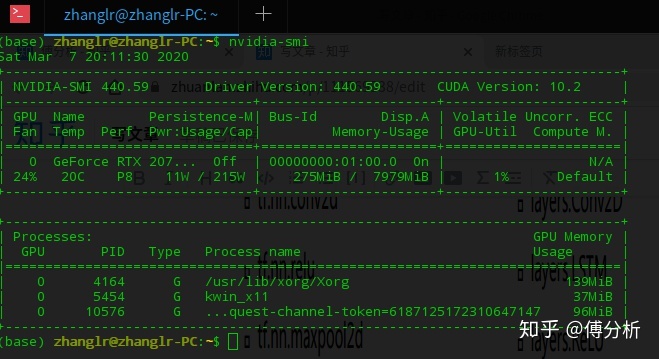
CUDA10.0:下面是CUDA10.0的百度云下载链接。链接:https://pan.baidu.com/s/1L8OyM28D3UZi_IVPaceILA 密码:8e9t
注意在~/.bashrc配置环境变量,否则tensorflow会找不到.so文件。
执行nvcc -V,验证是否安装成功。

cudnn:用于神经网络运算加速。百度云链接:https://pan.baidu.com/s/1bAc8jrRUBeSIA1QQGTuHNg 密码:jc31
miniconda3:使用conda管理python环境,下载地址
Tsinghua Open Source Mirrormirrors.ustc.edu.cn
安装后创建tensorflow2.0实验环境:
conda create -n tf2.0 python=3.6
conda activate tf2.0
pip install ( -i 清华或豆瓣源) tensorflow_gpu == 2.0.0验证GPU加速可用:
import tensorflow as tf
print(tf.test.is_gpu_available()) # 输出True则成功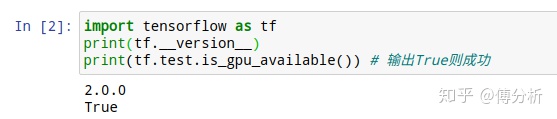
TensorFlow2.0基础操作
1.常见的数据类型载体
- list:灵活,可以随意插入、添加和编辑,内存的管理不是很连续,对高维数据的读取和写入效率很低
- np.array:专门用来解决同类型数据运算的一个载体,很方便高效完成数据吞吐和计算。但没有很好的GPU支持,也不能支持自动求导
- tf.Tensor:和np.array地位相似。为了方便使用NumPy的开发者能够更便利的转到TensorFlow,一些API命名也很相似。功能上更偏重于神经网络计算。TensorFlow中,标量、向量、矩阵、多维数组都被叫做tensor。
2.TensorFlow2.0中的数据类型
- int:tf.constant(1,dtype=tf.int32)
- float:tf.constant(1.,dtype=tf.float32)
- double:tf.constant(1.,dtype=tf.double) = tf.constant(1.,dtype=tf.float64),double是float64的别名
- bool:tf.constant([True,False])
- string:tf.constant('hello world')
3.查看数据所在设备-device
with tf.device('cpu'):a = tf.constant(1)with tf.device('gpu'):b = tf.range(4)print(a.device)
print(b.device)
如果需要在设备间相互转移,则a.gpu();b.cpu()即可 。
4.查看数据维度
- a.ndim #返回数据维度 ,注意若用tf.rank(a),则会返回一个标量的tensor
- a.shape #返回数据shape
这里和numpy是一样的。另外,注意维度和形状的区别,比如shape=(batchsize,h,w,3),它的维度是4,相当于ndim = len(shape)
5.判断是否是tensor

- tf.is_tensor(a)
- isinstance(a,tf.Tensor)
6.数据类型查看与转化
- 用a.dtype属性查看数据类型
- 用
tf.cast(a,dtype=XX)做类型转化 ,cast是投,投射的意思。 - a.numpy()可以直接将Tensor转成np.ndarray
a = tf.constant(1)
print(a.dtype)
a = tf.cast(a,dtype=tf.float32)
print(a.dtype)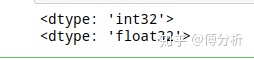
7.用Variable包装Tensor
Variable包装后的变量就具有了可求导的特性,是专门为nn参数设计的属性。
a = tf.range(5)
b = tf.Variable(a)
print(b.name)
print(isinstance(b,tf.Tensor))
print(isinstance(b,tf.Variable))
print(tf.is_tensor(b))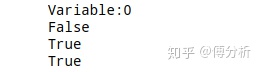
我原来看过一个比方,说Tensor就是赤裸裸的钱,但Variable是支付宝,它不仅装着你的钱,还记录你的钱的流通和去向等信息,可以管理你的钱。
8.创建Tensor
和NumPy及其相似,可参考
傅分析:Python の NumPyzhuanlan.zhihu.com
- tf.convert_to_tensor(python_list or numpy_array )
- tf.zeros(shape) / tf.ones(shape) 同numpy
- tf.fill(shape,value) 千万注意在numpy里叫full
- tf.random.normal(shape[,mean,stddev]) 正态
- tf.random.uniform(shape[,minval,maxval]) 均匀
- tf.random.shuffle(a) 随机打乱
import numpy as np
a = tf.convert_to_tensor([1,1])
print(a)
b = tf.convert_to_tensor(np.ones((2,)))
print(b)
c = tf.ones((2,))
print(c)
d = tf.fill((2,),1)
print(d)
另外,和numpy的random.shuffle()一样,这里也是对axis=0做随机打乱
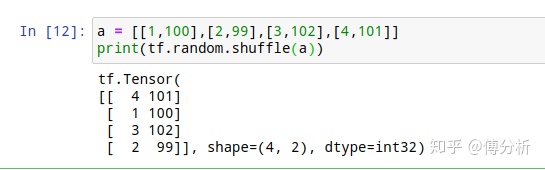
9.索引与切片
索引方式与NumPy完全相同,不赘述。
切片:
- [start:end:step] / [::step]
- [::-1]是倒序切片的技巧
- ...是任意长的:序列,可以有效规避[::,::,::,0]这种冗长的表达,替换为[...,0]
- tf.gather可以指定索引的轴,并指定顺序
a = tf.random.normal((4,5,5,3))
b = a[...,0:2]
print(b.shape) # (4, 5, 5, 2)
c = tf.gather(a,axis=3,indices=[0,1])
print(c.shape) # (4, 5, 5, 2)10.维度变换
view的概念:
- [b,28,28] 原始
- [b,28*28] √
- [b,2,14*28] √
- [b,28,28,1] √
一堆数据存在那,怎么理解数据的shape就是view,但是不能改变数据的存储位置。比如[n,h,w,3]的数据,每个像素点的rgb像素都连续存储,你通过view,想view到[n,3,h,w],即想通过view来让三通道分离,那是万万不可能的,你可以reshape它为[n,3,h,w]但不能达到你要的分离通道的效果,因为数据的存储位置是不变的。若你要改变数据的存储位置,那就不是维度变换的概念了,维度变换就是变化视角,变化view。
a = tf.random.normal((4,5,5,3))
b = tf.reshape(a,(4,-1,3)) # -1 会自动计算
print(b.shape) # (4,25,3)注意,numpy中可以a.reshape(shape),但Tensor没有这个属性,只能tf.reshape()
11.维度转置
刚才说的那个改变数据存储位置的三通道分离的操作,要通过转置实现。
a = tf.random.normal((4,5,5,3))
b = tf.transpose(a,perm=[0,3,1,2])
print(b.shape) # (4,3,5,5)转置会改变数据存储真实的位置关系,会比较慢。
12.维度增减
- 扩张维度用
tf.expend_dims(a,axis),注意是dims不是dim ,另外axis只能是single value,即不能一次扩展多维。 - a:[classes,students,courses]->[4,35,8]可以描述成4个班级,每个班35个学生,每个学生有8门课。增加学校的维度:[1,4,35,8]
# expand dim
a = tf.random.normal((4,35,8))
b = tf.expand_dims(a,axis=0)
print(b.shape)
c = tf.expand_dims(a,axis=-1) # 等同于axis=3
print(c.shape)
- 压缩维度用tf.squeeze(a,axis),如果不声明axis,那么将压缩所有数值为1的维度。
a = tf.zeros((1,2,1,3))
b = tf.squeeze(a,axis=2)
print(b.shape)
c = tf.squeeze(a)
print(c.shape)
13.broadcasting(广播)
- Broadcasting:本质是张量维度扩张的一个手段,指对某个维度上重复n次但没有真正的复制一个数据。
- (4,32,32,3) + (3,)可以对shape为(3,)的Tensor进行广播,(3,)->(1,1,1,3)->(4,32,32,3)。
- 这样比再定义一个同等shape的Tensor大大节省了内存。
- 系统会自动判断是否可以进行广播。
14.数学运算
- +,-,*,/
- **,pow,square
- //,%
- exp,log(注意tf.exp(),tf.math.log())
- @,matmul (矩阵乘法)
TensorFlow2.0高阶操作
1.张量合并
tf.concat((a,b,...),axis)用于多个张量的拼接- 待拼接的轴对应的维度数值可以不等,但其他维度形状需一致
- 不会产生新的维度,只会在原来维度的数值上有所改变
a = tf.ones((2,3))
b = tf.zeros((1,3))
c= tf.concat((a,b),axis=0)
print(c)
tf.stack((a,b,...),axis)用于多个张量的堆叠- 带堆叠张量的所有维度数值必须相等
- 根据指定的axis,产生新的一个维度
a = tf.ones((2,3))
b = tf.zeros((2,3))
c= tf.stack((a,b),axis=0)
print(c)
a = tf.ones((2,3))
b = tf.zeros((2,3))
c= tf.stack((a,b),axis=-1)
print(c)
2.张量分割
tf.unstack(a,axis)是stack的逆操作- 在指定的axis上,把原张量拆开
- 原张量在axis上值为多少,就需要有多少个新变量去承接
abc = tf.ones((3,3))
a,b,c = tf.unstack(abc,axis=0)
print(a)
print(b)
print(c)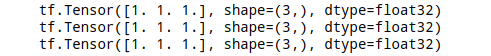
tf.split(a,axis,num_or_size_splits)是unstack基础上更灵活的分法- unstack会把指定axis上全部拆开,但split可以指定拆分的个数或方式
a = tf.ones((4,3))
a1,a2 = tf.split(a,axis=0,num_or_size_splits=2)
print(a1.shape,a2.shape) # (2,3) (2,3)
a1,a2,a3 = tf.split(a,axis=0,num_or_size_splits=[1,2,1])
print(a1.shape,a2.shape,a3.shape) # (1,3) (2,3) (1,3)3.数据统计
tf.reduce_min() tf.reduce_max() tf.reduce_mean()若不指定axis,则完成整个张量的求值,指定axis,则返回每个axis上的求解值。tf.argmax() tf.argmin()分别返回最大最小值所在位置,默认的axis=0,和上面reduce_xxx不一样。tf.equal()返回两个张量的比较结果,每个位置上都会有一个True or False。tf.unique()会去除一维张量中重复的元素 ,第一个返回值是去重后的张量,第二个返回值是对应索引。
a = tf.ones((2,2))
b = tf.ones((2,2))
c = tf.equal(a,b)
print(f'c:{c}') # shape is (2,2)
c = tf.reshape(c,(-1,)) # 必须reshape成(4,)
unique,idx = tf.unique(c) # tf.unique只接受一维张量
print(f'unique:{unique}')
print(f'idx:{idx}')
equal和unique配合使用,可以判断两个多维张量是否全等。
4.张量排序
tf.sort() tf.argsort()分别完成对某个维度的排序和获取排序后的索引位置。
a = tf.random.shuffle(tf.range(5))
print(f'a:{a}')
a_sort = tf.sort(a,direction="DESCENDING") # 降序排列
print(f'a_sort:{a_sort}')
a_argsort = tf.argsort(a,direction="DESCENDING")
print(f'a_argsort:{a_argsort}')
tf.math.top_k()可查看最大的k个元素的值或索引
a = tf.random.uniform((3,3),maxval=10,dtype=tf.int32)
print(f'a:n{a}')
res = tf.math.top_k(a,2)
print(f'values:n{res.values}')
print(f'indices:n{res.indices}')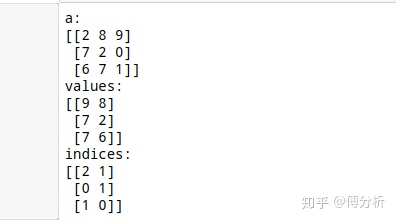
5.张量填充
tf.pad()
对一批图像a = (n,h,w,c),只有h和w需要padding,tf.pad(a,[[0,0],[2,2],[2,2],[0,0]]) 即可填充两行两列0项到图像。
a = tf.random.normal((8,32,32,3))
b = tf.pad(a,[[0,0],[2,2],[2,2],[0,0]])
print(b.shape) # (8,36,36,3)6.张量复制
tf.tile()
指定张量沿着各轴复制多少次,比如a.shape=(2,2),要求a沿0轴复制2次,1轴复制3次,则:
a = tf.ones((2,2))
b = tf.tile(a,(2,3)) # 元组里的每个数值对应该轴复制次数
print(b)
7.随机种子
tf.random.set_seed()
相关文章:

dev c++ 调试时候发生软件崩溃解决办法
dev c 调试时候发生软件崩溃解决办法 安装好dev cpp,准备调试的时候发现软件崩溃,这种情况很好解决。只要在工具菜单中点开编译选项,找到代码生成/优化一栏,将链接器的“产生调试信息”选项改为yes,即可

运行hadoop fs -ls 命令显示本地目录问题
2019独角兽企业重金招聘Python工程师标准>>> 运行hadoop fs -ls 命令显示本地目录问题 问题原因:是因为在hadoop配置文件中没有指定HDFS的默认路径 解决办法:有两个办法 1、使用HDFS全路径访问 hadoop fs -ls hdfs://192.168.1.1:9000/ 2…
李宏毅机器学习笔记(二)-------Why we need learn Machine Learning?
视频: 李宏毅机器学习(2017)_哔哩哔哩 (゜-゜)つロ 干杯~-bilibilihttps://www.bilibili.com/video/av10590361/?p2 真是一个逗波: AI训练师: 为AI选择合适的model和损失函数。然后达到最好的功能

mixamo网站FBX模型带骨骼绑定动作库
mixamo网站FBX模型带骨骼绑定动作库,unity游戏各职业人物动画,兼容3dmax maya c4d iclone blender等主流3D软件 mixamo游戏3D模型带骨骼绑定FBX动作库 大小解压后:17.2G 素材获取:mixamo网站FBX模型带骨骼绑定动作库-云桥网

java modbus通讯协议_物联通讯协议一(Modbus)
1、Modbus是一种串行通信协议,是Modicon公司(现在的施耐德电气 Schneider Electric)于1979年为使用可编程逻辑控制器(PLC)通信而发表。Modbus已经成为工业领域通信协议的业界标准(De facto),并且现在是工业电子设备之间常用的连接方式。2、Modbus是一种串…
hibernate3
hibernate3 (整合到spring中的core核心配置中的hibernate3) <!-- 基于hibernate的Session工厂 --><bean id"sessionFactory"class"org.springframework.orm.hibernate3.annotation.AnnotationSessionFactoryBean"><!…

伦理困境:人工智能浪潮与“AI威胁论”之争
首先,何为伦理? 2018年1月份的《科学与社会》报刊中有如下阐述: 伦理一词,英文为ethics,一词源自于希腊文的“ethos”,其意义与拉丁文“mores”差不多,表示风俗、习惯的意思。西方的伦理学发展流…
在 ASP.NET 网页中不经过回发而实现客户端回调
一、使用回调函数的好处 在 ASP.NET 网页的默认模型中,用户会与页交互,单击按钮或执行导致回发的一些其他操作。此时将重新创建页及其控件,并在服务器上运行页代码,且新版本的页被呈现到浏览器。但是,在有些情况下&…

李宏毅机器学习笔记(三)——Regression: output a scalar amp;amp; Gradient Descent
视频来源: 李宏毅机器学习(2017)_哔哩哔哩 (゜-゜)つロ 干杯~-bilibili https://www.bilibili.com/video/av10590361/?p3机器学习的目的就是找到最优函数,而回归的目的就是我们要找的函数的输出是一个数值。例如下面的例子,不管是输入怎样的…

完整的虚幻引擎超级课程:从初学者到专家
通过这个循序渐进的课程,学习如何像专业人士一样开发游戏和设计! 你会学到什么 如何使用虚幻引擎及其元素 电子游戏力学原理 平衡计分卡几何原理 蓝图脚本的原则 如何设计、开发和编写你的关卡来复制你最喜欢的游戏 流派:电子学习| MP4 |视频:h264&…
atitit.userService 用户系统设计 v5 q330
atitit.userService 用户系统设计 v5 q330 1. 新特性1 2. Admin login1 3. 用户注册登录2 3.1. <!-- 会员注册使用 --> 商家注册2 3.2. <!-- 会员登录使用 -->3 3.3. <!-- 会员退出登录 -->3 3.4. <!-- 进入会员首页 -->3 3.5. <!-- 进入会员信…
python打包为exe文件_Pyinstaller(python打包为exe文件)
需求分析: python脚本如果在没有安装python的机器上不能运行,所以将脚本打包成exe文件,降低脚本对环境的依赖性,同时运行更加迅速。 当然打包的脚本似乎不是在所有的win平台下都能使用,win7有一部分不能使用࿰…

从风投看中国IT行业的发展
创业相关电视剧中经常会出现一个词“风投”,例如主角创业艰辛,得到了风投的帮助,从而走向了人生巅峰。而“风投”并不是一家企业,它是由无数风险投资公司一同组成的行业,今天就带大家了解一下风投与中国IT行业的紧密联…
c++ 字母排序
char a[123] {Z, s, p, l, j, r, q, v, n, m, C, F, D, B, A, 2, 0, Z, };for (int i 0; i < strlen(a); i){//字母排序for (int j i 1; j < strlen(a); j){if (a[j] < a[i]){char pTem a[j];a[j] a[i];a[i] pTem;}}}printf("%s\n", a); 版权声明&a…

李宏毅笔记机器学习(四)——Regression——Demo
视频来源: 李宏毅机器学习(2017)_哔哩哔哩 (゜-゜)つロ 干杯~-bilibili https://www.bilibili.com/video/av10590361/?p4 重点: (1)调节lr(learning rate步长),lr参数的调节。迭代次数为1000次…

Blender 3.0机器人硬面建模材质渲染全流程学习课程
学习在Blender中建模硬表面机器人角色 你会学到什么 Blender 3.0建模工具 Blender 3.0硬面人物造型 机器人角色的UV展开 如何在Blender中渲染 MP4 |视频:h264,1280720 |音频:AAC,44.1 KHz,2 Ch 语言:英语中英文字幕(…
python抓包工具_「docker实战篇」python的docker爬虫技术-fiddler抓包软件详细配置(七)...
挑选常用的功能给各位老铁介绍下。 fiddler第一次进入fiddlerfiddler会请求fiddler的官网,检查更新操作布局分布 工具栏File -capture traffic开启爬虫File -new Viewer新建立一个窗口File - save保存all session,request方式,reponse的方式z…
loadrunner支持https协议的操作方法-经验总结
问题:用户portal支持https协议,用loadrunner录制登陆脚本时发现未录制到用户名和密码 录制到的脚本如下: login() { lr_think_time(10); web_url("verifycode.jsp", "URLhttps://192.168.211.246:56661/portal/common/jsp/ver…

初试linux编译(ubuntu+vim)+玩转智能蛇
一.初试linux编译(ubuntuvim) 步骤: ①下载vmware15ubuntu桌面版映像 ②安装ubuntu ③下载vimgcc 在ubuntu终端输入: sudo apt-get install vim-gtk sudo apt-get install gcc④安装完毕后进行编译测试 1)新建hellow…

shell学习之路:流程控制(if)
1.单分支if条件语句 1 if [ 条件判断式 ];then 2 程序 3 fi 4 或者 5 if [ 条件判断式 ] 6 then 7 程序 8 fi 注意事项: 1.if语句使用fi结尾,和一般语言使用大括号结尾不同 2.[ 条件判断式 ]就是使用test命令判断,所以中括号和条件判断式…

李宏毅机器学习笔记(五)-----Where does the error come from
视频来源: 李宏毅机器学习(2017)_哔哩哔哩 (゜-゜)つロ 干杯~-bilibili https://www.bilibili.com/video/av10590361/?p5 function set model error来源: (1)baise (2)variance问题一: 怎么…

Blender三维建筑场景动画制作学习教程
一起在Blender中创建一个三维低多边形场景动画 你会学到什么 这门课程是为那些喜欢在工作流程中成长的艺术家设计的 初学者 想学会让自己的资产活起来的艺术家。 希望扩展其技能集的游戏开发人员。 MP4 |视频:h264,1280720 |音频:AAC,44.1 KHz&#x…

springcloud 组件_SpringCloud组件mica 2.0.5发布,添加对sentinel、undertow指标收集
一、mica(云母)mica 由如梦技术内部的 lutool(撸秃) 演变而来。lutool 诞生于 2017 年,受 jhipster 启发逐步形成一个微服务的核心集。因 lutool 名称与功能不太符合,故在2019年开源时将其改名为 mica&…
access order by 判断是否除数为0
order by IIF(dz>0,yj/dz,0) desc转载于:https://www.cnblogs.com/slyzly/p/5379482.html
vm无网络解决方法
编辑-虚拟网络编辑器-还原默认
十五天精通WCF——第八天 对“绑定”的最后一点理解
转眼已经中断10几天没有写博客了,也不是工作太忙,正好碰到了端午节,然后最近看天津台的爱情保卫战入迷了。。。太好看了,一直都是回味无穷。。。而且 涂磊老师话说的真是tmd的经典,然后就这样耽搁了,好了&a…
2018年目标
2018年又一个新的开始2018年的学习目标: (1)每天学习算法和Python。尝试用Python写出不同的算法 (2)每天完成一篇CSDN专栏大数据相关 (3)每天进步一点点的打卡完成 (4)集…

GameMaker Studio从头开始学习设计和开发3款游戏
从头开始学习设计和开发3款游戏(无需经验) 你会学到什么 如何塑造令人敬畏的角色 如何使用GameMakerStudio 2 视频游戏编程 基本二维动画 如何查找和修复bug 如何给你的游戏编故事 从哪里获得游戏资产(免费) 如何添加声音效果 如何发展你的游戏理念 游戏设计力学 如何制作有趣…

商淘多b2b2c商城系统怎么在个人电脑上安装_社交电商系统开发是否有价值?
电商平台已经呈现出平稳发展之势,再加上近年来星期的社交,让社交电商平台蓬勃发展,不仅是小平台,京东、唯品会、小米等纷纷有了自己的社交电商平台,说明了社交电商是发展的大趋势,开发社交电商系统也是创…
AngularJS中的按需加载ocLazyLoad
欢迎大家讨论与指导 : ) 初学者,有不足的地方希望各位指出 一、前言 ocLoayLoad是AngularJS的模块按需加载器。一般在小型项目里,首次加载页面就下载好所有的资源没有什么大问题。但是当我们的网站渐渐庞大起来,这样子的加载策略让…