计算机视觉技术 图像分类_如何训练图像分类器并教您的计算机日语
计算机视觉技术 图像分类
介绍 (Introduction)
Hi. Hello. こんにちは
你好 你好。 こんにちは
Those squiggly characters you just saw are from a language called Japanese. You’ve probably heard of it if you’ve ever watched Dragon Ball Z.
您刚刚看到的那些蠕动的字符来自一种叫做日语的语言。 如果您曾经看过《龙珠Z》,可能已经听说过。
Here’s the problem though: you know those ancient Japanese scrolls that make you look like you’re going to unleash an ultimate samurai ninja overlord super combo move.
但是,这就是问题所在:您知道那些古老的日本卷轴,使您看起来像是要发动最终的武士忍者霸主超级连击。
Yeah, those. I can’t exactly read them, and it turns out that very few people can.
是的,那些。 我看不懂它们,事实证明很少有人能读。
Luckily, a bunch of smart people understands how important it is that I master the Bijudama-Rasenshuriken, so they invented this thing called deep learning.
幸运的是,一群聪明的人了解我掌握Bijudama-Rasenshuriken的重要性,因此他们发明了称为深度学习的东西。
So pack your ramen and get ready. In this article, I’ll show you how to train a neural network that can accurately predict Japanese characters from their images.
因此,打包您的拉面并做好准备。 在本文中,我将向您展示如何训练一个神经网络,该网络可以从图像中准确预测日语字符。
To ensure that we get good results, I’m going to use of an incredible deep learning library called fastAI, which is a wrapper around PyTorch that makes it easy to implement best practices from modern research. You can read more about it on their docs.
为确保获得良好的结果,我将使用一个名为fastAI的令人难以置信的深度学习库,该库是PyTorch的包装,可轻松实施现代研究中的最佳实践。 您可以在他们的文档中了解更多信息。
With that said, let’s get started.
话虽如此,让我们开始吧。
KMNIST (KMNIST)
OK, so before we can create anime subtitles, we’re going to need a dataset. Today we’re going to focus on KMNIST.
好的,因此在创建动漫字幕之前,我们将需要一个数据集。 今天,我们将专注于KMNIST。
This dataset takes of examples of characters from the Japanese Kuzushiji script, and organizes them into 10 labeled classes. The images measure 28x28 pixels, and there are 70,000 images in total, mirroring the structure of MNIST.
该数据集采用了日语Kuzushiji脚本中的字符示例,并将其组织为10个带有标签的类。 图像尺寸为28x28像素,总共有70,000张图像,反映了MNIST的结构。
But why KMNIST? Well firstly, it has “MNIST” in its name, and we all know how much people in machine learning love MNIST.
但是为什么要KMNIST? 首先,它的名称为“ MNIST”,我们都知道有多少机器学习人员喜欢MNIST。
So in theory, you could just change a few lines of that Keras code that you copy-pasted from Stack Overflow and BOOM! You now have computer code that can revive an ancient Japanese script.
因此,从理论上讲,您只需更改从Stack Overflow和BOOM复制粘贴的Keras代码的几行即可! 现在,您拥有可以恢复古老的日语脚本的计算机代码。
Of course, in practice, it isn’t that simple. For starters, the cute little model that you trained on MNIST probably won’t do that well. Because, you know, figuring out whether a number is a 2 or a 5 is just a tad easier than deciphering a forgotten cursive script that only a handful of people on earth know how to read.
当然,实际上,这不是那么简单。 对于初学者来说,您在MNIST上训练的可爱小模型可能效果不佳。 因为,您知道弄清楚数字是2还是5只是比破译一个被遗忘的草书(仅地球上只有少数人会识字)更容易的一点。
Apart from that, I guess I should point out that Kuzushiji, which is what the “K” in KMNIST stands for, is not just 10 characters long. Unfortunately, I’m NOT one of the handfuls of experts that can read the language, so I can’t describe in intricate detail how it works.
除此之外,我想指出的是,KMNIST中的“ K”代表的Kuzushiji不仅仅是10个字符长。 不幸的是,我不是能读懂该语言的少数专家之一,因此我无法详细描述它的工作原理。
But here’s what I do know: There are actually three variants of these Kuzushiji character datasets — KMNIST, Kuzushiji-49, and Kuzushiji-Kanji.
但是,这就是我所知道的:这些Kuzushiji字符数据集实际上有三个变体-KMNIST,Kuzushiji-49和Kuzushiji-Kanji。
Kuzushiji-49 is variant with 49 classes instead of 10. Kuzushiji-Kanji is even more insane, with a whopping 3832 classes.
Kuzushiji-49是49个班级的替代版本,而不是10个班级。Kuzushiji-Kanji更疯狂,有3832个班级。
Yep, you read that right. It’s three times as many classes as ImageNet.
是的,您没看错。 它是ImageNet的三倍。
如何不弄乱您的数据集 (How to Not Mess Up Your Dataset)
To keep things as MNIST-y as possible, it looks like the researchers who put out the KMNIST dataset kept it in the original format (man, they really took that whole MNIST thing to heart, didn’t they).
为了使事情尽可能保持MNIST-y的状态,看起来像是研究人员,他们将KMNIST数据集保留为原始格式(伙计,他们确实将整个MNIST事情牢记在心,不是)。
If you take a look at the KMNIST GitHub repo, you’ll see that the dataset is served in two formats: the original MNIST thing, and as a bunch of Numpy arrays.
如果查看KMNIST GitHub存储库 ,您会看到该数据集以两种格式提供:原始MNIST数据和一堆Numpy数组。
Of course, I know you were probably too lazy to click that link. So here you go. You can thank me later.
当然,我知道您可能懒得单击该链接。 所以,你去。 您可以稍后感谢我。
Personally, I found the NumPy array format easier to work with when using fastai, but the choice is yours. If you’re using PyTorch, KMNIST comes for free as a part of torchvision.datasets.
就个人而言,我发现使用fastai时更容易使用NumPy数组格式,但是选择是您自己的。 如果您使用的是PyTorch,则KMNIST作为torchvision.datasets的一部分免费torchvision.datasets 。
The next challenge is actually getting those 10,000-year-old brush strokes onto your notebook (or IDE, who am I to judge). Luckily, the GitHub repo mentions that there’s this handy script called download_data.py that’ll do all the work for us. Yay!
下一个挑战实际上是将这些具有10,000年历史的画笔笔触放到您的笔记本电脑(或IDE,我要判断谁)上。 幸运的是,GitHub回购提到了一个名为download_data.py的便捷脚本,它将为我们完成所有工作。 好极了!
From here, it’ll probably start getting awkward if I continue talking about how to pre-process your data without actual code. So check out the notebook if you want to dive deeper.
从这里开始,如果我继续谈论如何在没有实际代码的情况下预处理数据,它可能会变得尴尬。 因此,如果您想进一步潜水,请查看笔记本 。
Moving on…
继续…
我应该使用超超高的Inception ResNet XXXL吗? (Should I use a hyper ultra Inception ResNet XXXL?)
简短答案 (Short Answer)
Probably not. A regular ResNet should be fine.
可能不是。 定期使用ResNet应该可以。
简短回答少一些 (A Little Less Short Answer)
Ok, look. By now, you’re probably thinking, “KMNIST big. KMNIST hard. Me need to use very new, very fancy model.”
好,看 到现在为止,您可能会想,“ KMNIST大。 KMNIST努力。 我需要使用非常新颖,非常漂亮的模型。”
Did I overdo the Bizzaro voice?
我是否超越了Bizzaro的声音?
The point is, you DON’T need a shiny new model to do well on these image classification tasks. At best, you’ll probably get a marginal accuracy improvement at the cost of a whole lot of time and money.
问题的关键是,你并不需要一个全新的模型来对这些图像分类工作做得很好。 充其量,您可能会以大量的时间和金钱为代价获得少量的精度提高。
Most of the time, you’ll just waste a whole lot of time and money.
在大多数情况下,您将浪费大量时间和金钱。
So heed my advice — just stick to good ol’ fashion ResNets. They work really well, they're relatively fast and lightweight (compared to some of the other memory hogs like Inception and DenseNet), and best of all, people have been using them for a while, so it shouldn’t be too hard to fine-tune.
因此,请注意我的建议-坚持使用流行的ResNets。 它们工作得非常好,它们相对较快且轻便(与其他一些内存生猪如Inception和DenseNet相比),并且最重要的是,人们已经使用了一段时间,因此使用它应该不会太难微调。
If the dataset you’re working with is simple like MNIST, use ResNet18. If it’s medium-difficulty, like CIFAR10, use ResNet34. If it’s really hard, like ImageNet, use ResNet50. If it’s harder than that, you can probably afford to use something better than a ResNet.
如果您使用的数据集很简单,例如MNIST,请使用ResNet18。 如果是中等难度,例如CIFAR10,请使用ResNet34。 如果真的很难,例如ImageNet,请使用ResNet50。 如果比这困难,您可能可以负担得起使用比ResNet更好的东西。
Don’t believe me? Check out my leading entry for the Stanford DAWNBench competition from April 2019:
不相信我吗 查看我从2019年4月起参加斯坦福DAWNBench竞赛的主要参赛作品:
What do you see? ResNets everywhere! Now come on, there’s got to be a reason for that.
你看到了什么? ResNets无处不在! 现在来,一定有一个理由。
超参数 (Hyperparameters Galore)
A few months ago, I wrote an article on how to pick the right hyperparameters. If you’re interested in a more general solution to this herculean task, go check that out. Here, I’m going to walk you through my process of picking good-enough hyperparameters to get good-enough results on KMNIST.
几个月前,我写了一篇关于如何选择正确的超参数的文章 。 如果您对这个繁重的任务有一个更通用的解决方案感兴趣,请检查一下。 在这里,我将引导您完成选择足够好的超参数以在KMNIST上获得足够好的结果的过程。
To start off, let’s go over what hyperparameters we need to tune.
首先,让我们看一下需要调整哪些超参数。
We’ve already decided to use a ResNet34, so that’s that. We don’t need to figure out the number of layers, filter size, number of filters, etc. since that comes baked into our model.
我们已经决定使用ResNet34,仅此而已。 由于模型中包含了层数,滤镜大小,滤镜数量等,因此我们无需弄清楚。
See, I told you it would save time.
看,我告诉过您,这样可以节省时间。
So what’s remaining is the big three: learning rate, batch size, and the number of epochs (plus stuff like dropout probability for which we can just use the default values).
因此剩下的就是三大要素:学习率,批处理大小和时期数(加上诸如辍学概率之类的东西,我们可以使用默认值)。
Let’s go over them one by one.
让我们一一介绍。
纪元数 (Number of Epochs)
Let’s start with the number of epochs. As you’ll come to see when you play around with the model in the notebook, our training is pretty efficient. We can easily cross 90% accuracy within a few minutes.
让我们从时期数开始。 当您看到使用笔记本中的模型时,我们的培训非常有效。 我们可以在几分钟内轻松达到90%的精度。
So given that our training is so fast in the first place, it seems extremely unlikely that we would use too many epochs and overfit. I’ve seen other KMNIST models train for over 50 epochs without any issues, so staying in the 0-30 range should be absolutely fine.
因此,考虑到我们的培训是如此之快,我们似乎不太可能使用过多的时间和过度拟合。 我已经看到其他KMNIST型号训练了50个以上的纪元而没有任何问题,因此,将其保持在0-30范围内绝对可以。
That means within the scope of the restrictions we’ve put on the model when it comes to epochs, the more, the merrier. In my experiments, I found that 10 epochs strike a good balance between model accuracy and training time.
这意味着在涉及时代的情况下,我们在模型上施加的限制范围内,越多越好。 在我的实验中,我发现10个纪元在模型准确性和训练时间之间取得了很好的平衡。
学习率 (Learning Rate)
What I’m about to say is going to piss a lot of people off. But I’ll say it anyway — We don’t need to pay too much attention to the learning rate.
我要说的是要惹恼很多人。 但是我还是要说-我们不需要太在意学习率。
Yep, you heard me right. But give me a chance to explain.
是的,你没听错。 但是给我一个解释的机会。
Instead of going “Hmm… that doesn’t seem to work, let’s try again with lr=3e-3 ,” we’re going to use a much more systematic and disciplined approach to finding a good learning rate.
与其说“嗯……似乎不起作用,不如让我们再次尝试使用lr = 3e-3”,我们将使用一种更加系统化和规范化的方法来找到一个好的学习率。
We’re going to use the learning rate finder, a revolutionary idea proposed by Leslie Smith in his paper on cyclical learning rates.
我们将使用学习率查找器,这是莱斯利·史密斯(Leslie Smith)在其关于周期性学习率的论文中提出的一种革命性想法。
Here’s how it works:
运作方式如下:
- First, we set up our model and prepare to train it for one epoch. As the model is training, we’ll gradually increase the learning rate.首先,我们建立模型并准备将其训练一个时期。 在训练模型的过程中,我们将逐渐提高学习率。
- Along the way, we’ll keep track of the loss at every iteration.在此过程中,我们将跟踪每次迭代的损失。
- Finally, we select the learning rate the corresponds to the lowest loss.最后,我们选择与最低损失相对应的学习率。
When all is said and done, and you plot the loss against the learning rate, you should see something like this:
说完所有事情,然后将损失与学习率进行比较,您应该会看到类似以下的内容:
Now, before you get all giddy and pick 1e-01 as the learning rate, I’ll have you know that it’s NOT the best choice.
现在,在您变得头晕目眩并选择1e-01作为学习率之前,我会让您知道这不是最佳选择。
That’s because fastai implements a smoothening technique called exponentially weighted averages, which is the deep learning researcher version of an Instagram filter. It prevents our plots from looking like the result of giving your neighbors’ kid too much time with a blue crayon.
这是因为fastai实现了一种称为指数加权平均值的平滑技术,这是Instagram过滤器的深度学习研究员版本。 它会阻止我们的地块看起来像是用蓝色蜡笔给您邻居的孩子太多时间的结果。
Since we’re using a form of averaging to make the plot look smooth, the “minimum” point that you’re looking at on the learning rate finder isn’t actually a minimum. It’s an average.
由于我们使用平均的形式来使图看起来更平滑,因此您在学习率查找器上看到的“最小”点实际上并不是最小值。 这是平均水平。
Instead, to actually find the learning rate, a good rule of thumb is to pick the learning rate that’s an order of magnitude lower than the minimum point on the smoothened plot. That tends to work really well in practice.
相反,要真正找到学习率,一个好的经验法则是选择比平滑化图上的最小点低一个数量级的学习率。 在实践中,这往往效果很好。
I understand that all this plotting and averaging might seem weird if all you’ve been brute-forcing learning rate values all your life. So I’d advise you to check out Sylvain Gugger’s explanation of the learning rate finder to learn more.
我了解,如果您一生都在强迫学习率值,那么所有这些绘制和求平均值的过程似乎很奇怪。 因此,我建议您查看Sylvain Gugger对学习率查找器的解释以了解更多信息。
批量大小 (Batch Size)
OK, you caught me red-handed here. My initial experiments used a batch size of 128 since that’s what the top submission used.
好,你在这里抓到我了。 我最初的实验使用的批处理大小为128,因为这是最高提交所使用的。
I know, I know. Not very creative. But it’s what I did. Afterward, I experimented with a few other batch sizes, and I couldn’t get better results. So 128 it is!
我知道我知道。 不太有创意。 但这就是我所做的。 之后,我尝试了其他一些批次大小,但没有得到更好的结果。 所以是128!
In general, batch sizes can be a weird thing to optimize, since it partially depends on the computer you’re using. If you have a GPU with more VRAM, you can train on larger batch sizes.
通常,优化批量大小可能是一件奇怪的事情,因为它部分取决于您所使用的计算机。 如果您的GPU具有更多的VRAM,则可以进行更大批量的训练。
So if I tell you to use a batch size of 2048, for example, instead of getting that coveted top spot on Kaggle and eternal fame and glory for life, you might just end up with a CUDA: out of memory error.
因此,例如,如果我告诉您使用2048的批处理大小,而不是在Kaggle上获得令人垂涎的头把交椅,并获得永恒的成名和荣耀,您可能最终会遇到CUDA:内存不足错误。
So it’s hard to recommend a perfect batch size because, in practice, there are clearly computational limits. The best way to pick it is to try out values that work for you.
因此,很难建议理想的批处理大小,因为在实践中显然存在计算限制。 最好的选择是尝试适合您的价值。
But how would you pick a random number from the vast sea of positive integers?
但是,您如何从广阔的正整数海洋中挑选一个随机数呢?
Well, you actually don’t. Since GPU memory comes is organized in bits, it’s a good idea to choose a batch size that’s a power of 2 so that your mini-batches fit snugly in memory.
好吧,你实际上没有。 由于GPU内存是按位组织的,因此最好选择2的幂的批处理大小,以使您的迷你批处理恰好适合内存。
Here’s what I would do: start off with a moderately large batch size like 512. Then, if you find that your model starts acting weird and the loss is not on a clear downward trend, half it. Next, repeat the training process with a batch size of 256, and see if it behaves this time.
这就是我要做的:从一个中等大的批次(如512)开始。然后,如果您发现模型开始表现怪异并且损失没有明显的下降趋势,则减少一半。 接下来,以256的批量大小重复训练过程,然后查看它是否在这次运行。
If it doesn’t, wash, rinse, and repeat.
如果没有,请清洗,冲洗并重复。
一些漂亮的照片 (A Few Pretty Pictures)
With the optimizations going on here, it’s going to be pretty challenging to keep track of this giant mess of models, metrics, and hyperparameters that we’ve created.
随着优化的进行,跟踪我们创建的模型,指标和超参数的巨大混乱将是非常困难的。
To ensure that we all remain sane human beings while climbing the accuracy mountain, we’re going to use the wandb + fastai integration.
为了确保在攀登准确性山峰时我们所有人仍然保持理智,我们将使用wandb + fastai集成 。
So what does wandb actually do?
那么wandb实际做什么?
It keeps track of a whole lot of statistics about your model and how it’s performing automatically. But what’s really cool is that it also provides instant charts and visualizations to keep track of critical metrics like accuracy and loss, all in real-time!
它跟踪有关模型及其自动执行情况的大量统计信息。 但是真正酷的是它还提供即时图表和可视化效果,以实时跟踪关键指标,如准确性和损失!
If that wasn’t enough, it also stores all of those charts, visualizations, and statistics in the cloud, so you can access them anytime anywhere.
如果这还不够,它还将所有这些图表,可视化效果和统计信息存储在云中,因此您可以随时随地访问它们。
Your days of starting at a black terminal screen and fiddling around with matplotlib are over.
从黑色终端屏幕开始学习和使用matplotlib的日子已经过去。
The notebook tutorial for this article has a straightforward introduction to how it works seamlessly with fastai. You can also check out the wandb workspace, where you can take a look at all the stuff I mentioned without writing any code.
本文的笔记本教程直接介绍了它如何与fastai无缝配合。 您还可以检出wandb工作区 ,在这里您可以查看我提到的所有内容,而无需编写任何代码。
结论 (Conclusion)
これで終わりです
これで终わりです
That means “this is the end.”
那意味着“到此结束。”
But you didn't need me to tell you that, did you? Not after you went through the trouble of getting a Japanese character dataset, using the learning rate finder, training a ResNet using modern best practices, and watching your model rise to glory using real-time monitoring in the cloud.
但是你不需要我告诉你,对吗? 在您遇到了获取日语字符数据集,使用学习率查找器,使用现代最佳实践训练ResNet以及使用云中的实时监控来观察模型升华的麻烦之后。
Yep, in about 20 minutes, you actually did all of that! Give yourself a pat on the back.
是的,在大约20分钟内,您实际上完成了所有这些操作! 拍拍自己的背部。
And please, go watch some Dragonball.
而且,请去看一些龙珠游戏。
翻译自: https://www.freecodecamp.org/news/how-to-teach-your-computer-japanese/
计算机视觉技术 图像分类
相关文章:

history对象
history对象记录了用户曾经浏览过的页面(URL),并可以实现浏览器前进与后退相似导航的功能。 注意:从窗口被打开的那一刻开始记录,每个浏览器窗口、每个标签页乃至每个框架,都有自己的history对象与特定的window对象关联。 语法: w…

无限循环动画实现
先来个效果图 示例代码是先缩小移动,然后无限循环左右晃动,希望能够帮助到你,点个赞吧~ 实现代码 <image class"element1" load"element1_load" :animation"animationData" src"../../static/element…

利用属性封装复杂的选项
1、考虑这样一个场景。 我们的程序中有一个“选项”窗口,这个窗口包含很多选项。其中有一个选项是单选类型的,用户可以从N个选项值中选择一个。 我们需要在用户单击“确定”按钮后把用户选择的值保存到文件中,程序下次启动时再读取到内存中。…
react 渲染道具_关于React道具的另一篇文章
react 渲染道具You could say this topic has been done to death, but lately I’ve started using a technique that I dont recall having come across elsewhere. While its not particularly clever, it is concise. So please forgive one more post on the topic...你…
高可用集群的概念
一:什么是高可用集群 高可用集群(High Availability Cluster,简称HA Cluster),是指以减少服务中断时间为目的得服务器集群技术。它通过保护用户得业务程序对外部间断提供的服务,把因为软件,硬件…
node.js 出现cannot find module ‘xxx‘ 解决办法
找不到模块的解决方案 : 把node_module整个文件夹删掉,然后npm clean cache,看下package.json里有没有express的依赖项,有的话直接npm install,没有的话 npm install express --save npm clean cache 如果不行的话用 npm cache clean

poj 1904 King's Quest
Kings Quest 题意:有N个王子和N个妹子;(1 < N < 2000)第i个王子喜欢Ki个妹子;(详见sample)题给一个完美匹配,即每一个王子和喜欢的一个妹子结婚;问每一个王子可以有几种选择(在自己喜欢的妹子里面选),并输出可选…
数据预处理--噪声_为什么数据对您的业务很重要-以及如何处理数据
数据预处理--噪声YES! Data is extremely important for your business.是! 数据对您的业务极为重要。 A human body has five sensory organs, and each one transmits and receives information from every interaction every second. Today, scientists can det…

C++ template
(转自http://www.cnblogs.com/gw811/archive/2012/10/25/2738929.html) C模板 模板是C支持参数化多态的工具,使用模板可以使用户为类或者函数声明一种一般模式,使得类中的某些数据成员或者成员函数的参数、返回值取得任意类型。 模…
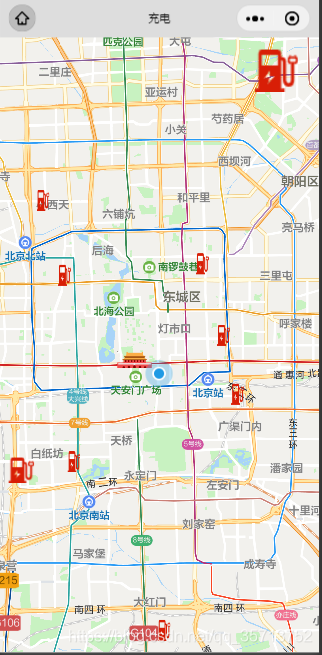
js根据经纬度取随机附近经纬度
实现功能: 小程序根据当前经纬度得出随机的附近经纬度显示在地图上做标记点,效果图 实现代码 // map.js var app getApp() var mymap ; var lat ; var long ; var that;function latlog(lat, lon, d 1,d23) {var angle Math.random(1, 360);var …
讽刺笑话_完全不讽刺的2019年网络设计指南
讽刺笑话I’ve written about how to design for the modern web before, way back in 2018. But the web moves forward quickly so those guidelines are already obsolete and outdated, as more modern conventions have become mainstream.早在2018年,我就已经…
模拟城市2.0
题目背景 博弈正在机房颓一个叫做《模拟城市2.0》的游戏。 2048年,经过不懈努力,博弈终于被组织委以重任,成为D市市委书记!他勤学好问,励精图治,很快把D市建设成富强民主文明和谐的美好城市。为了进一步深化…

bzoj:1221;vijos 1552 软件开发
Description 某软件公司正在规划一项n天的软件开发计划,根据开发计划第i天需要ni个软件开发人员,为了提高软件开发人员的效率,公司给软件人员提供了很多的服务,其中一项服务就是要为每个开发人员每天提供一块消毒毛巾,…

u-charts 曲线图中间有部分没数据,导致点和点无法连成线的问题解决
解决曲线图或者折线图在两端中间没有数据时无法绘画成线的问题源码修改, 解决方案: 在数据之间填充假数据,并且创建一个和点的数据同级的 list 来验证是不是假数据,如果是假数据就不绘制点,是真数据才绘制点,达到点和点之间没数据但是能连线的效果 先看效果图: 数据格…
python构建json_如何使用Python构建JSON API
python构建jsonThe JSON API specification is a powerful way for enabling communication between client and server. It specifies the structure of the requests and responses sent between the two, using the JSON format.JSON API规范是启用客户端和服务器之间通信的…

样式集 - 自适应居中弹窗
效果图: 弹窗1代码 <!-- 答题正确弹窗 --><block v-if"answer_true_show"><view class"answer_true_bg"></view><view class"answer_true"><img class"true_bg_img" :src"qualifyi…
struts2中 ServletActionContext与ActionContext区别
1. ActionContext 在Struts2开发中,除了将请求参数自动设置到Action的字段中,我们往往也需要在Action里直接获取请求(Request)或会话(Session)的一些信息,甚至需要直接对JavaServlet Http的请求(HttpServletRequest),响应(HttpServletResponse)操作. 我们需要在Action中取得req…
[记录]calculate age based on date of birth
calculate age based on date of birth know one new webiste:eval.in run php code转载于:https://www.cnblogs.com/fsong/p/5190273.html
有抱负的Web开发人员应考虑的6件事
Becoming a web developer can be as challenging as working out every day.成为网络开发人员就像每天锻炼一样具有挑战性。 It’s important to know what it will take to succeed as a web developer.重要的是要知道要成为一名Web开发人员要取得成功。 Here are 6 things…

阿里云OSS上传图片实现流程
前置,在阿里云开通OSS对象储存。然后在下图文件管理配置文件储存目录和图中传输管理配置访问域名。 1.复制 uploadFileUtil 文件夹和 uploadFile.js 文件在 util 文件夹 2.在使用的页面 引入 uploadFile 效果图: 实现代码 <template><view c…
修改远程桌面连接3389端口号
修改注册表: HKEY_LOCAL_MACHINE\System\CurrentControlSet\Control\Terminal Server\Wds\Repwd\Tds\Tcp 键:PortNumber,以十进制显示:3389,修改成55555,保存刷新注册表。 HKEY_LOCAL_MACHINE\SYSTEM\Curre…

理解 : UDID、UUID、IDFA、IDFV
iOS获取设备唯一标识的各种方法?IDFA、IDFV、UDID分别是什么含义?iOS获取设备ID总结IDFA解释 关于UUID的理解 : 英文名称是:Universally Unique Identifier,翻译过来就是通用唯一标识符。 UUID是指在一台机器上生成的数字,它保证对…
推箱子2-向右推!_保持冷静,砍箱子-me脚
推箱子2-向右推!Hack The Box (HTB) is an online platform allowing you to test your penetration testing skills. It contains several challenges that are constantly updated. Some of them simulating real world scenarios and some of them leaning more towards a C…
H5面试题---介绍js的基本数据类型
js的基本数据类型 Undefined、Null、Boolean、Number、String 转载于:https://www.cnblogs.com/songchunmin/p/7789582.html
Node.js express 之mongoose 从异步回调函数返回值,类似于同步
http://my.oschina.net/antianlu/blog/187023转载于:https://www.cnblogs.com/cylblogs/p/5192314.html
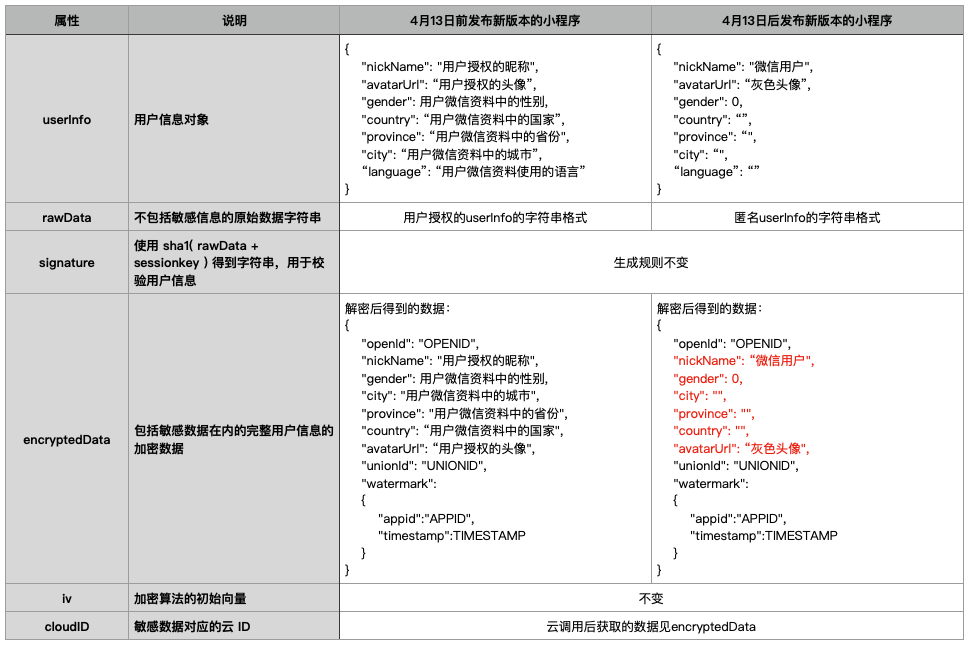
小程序登录、用户信息相关接口调整说明
为优化用户的使用体验,平台将进行以下调整: 2021年2月23日起,若小程序已在微信开放平台进行绑定,则通过wx.login接口获取的登录凭证可直接换取unionID2021年4月13日后发布的小程序新版本,无法通过wx.getU…
小程序 reduce_使用Reduce制作的10个JavaScript实用程序功能
小程序 reduceThe multi-tool strikes again. 多功能工具再次触击。 In my last article I offered you a challenge to recreate well-known functions using reduce. This article will show you how some of them can be implemented, along with some extras! 在上一篇文章…
流媒体,hls
所谓流媒体是指采用流式传输的方式在Internet播放的媒体格式。流媒体又叫流式媒体,它是指商家用一个视频传送服务器把节目当成数据包发出,传送到网络上。用户通过解压设备对这些数据进行解压后,节目就会像发送前那样显示出来。流媒体…
uniapp实现页面左右滑动,上下滑动事件
实现代码: <view class"" touchstart"touchstart" touchend"touchend"> </view> data() {return {touchData: {}, //滑动事件数据} } methods: {touchstart(e) {this.touchData.clientX e.changedTouches[0].clientX;…
android逆向分析概述_Android存储概述
android逆向分析概述Storage is this thing we are all aware of, but always take for granted. Not long ago, every leap in storage capacity was incremental and appeared to be impossible. Nowadays, we don’t give a second thought when contemplating how much of …