pytorch 测试每一类_DeepFM全方面解析(附pytorch源码)
写在前面
最近看了DeepFM这个模型。把我学习的思路和总结放上来给大家和未来的自己做个参考和借鉴。文章主要希望能串起学习DeepFM的各个环节,梳理整个学习思路。以“我”的角度浅谈一下DeepFM基础知识+看过的一些有用文献+最后附上可实现的pytorch代码,用具体的Kaggle竞赛案例来梳理DeepFM项目的流程。(文章语言尽量通俗易懂,所以背后的逻辑推导尽可能罗列在附带的参考文献里)
DeepFm的学习路线
DeepFM的paper → 网上的解析文章 →源码复现
我一开始是看了一遍原文的paper,缺点是很多概念都比较模糊,比如我看DeepFM的时候根据不知道FM是什么,前面的基础没有,看这些衍生概念就很困惑。优点是我能知道文章想体现一些重点以及一些概念名词,比如说我虽然不知道FM是什么,但是我知道DeepFM是将FM做了一个新的拓展,那我知道了FM这个名词之后,我后面补充基础知识的时候就会有针对性。paper很困惑的点,可以给自己留下一些印象和问题,让你后面再去接触、弄懂这些知识的时候就会有一个似曾相识 → 恍然大悟的感觉。随后的内容是在我看过一遍原文的基础上做的补充。
DeepFM基础知识(来由与作用)
我们大家基本都了解过线性回归方程,也就是
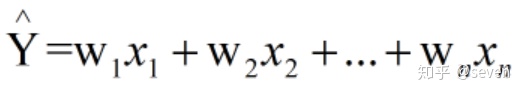
但是线性回归有一个不好的地方在于它直接估计2阶或者高阶特征变量的时候,难以直接估计出特征前面的权重(也称系数)。那么就衍生出了一个叫做FM的算法来解决这个问题。这里背后的逻辑重点看一下这篇文章,把FM诞生的来由及理论讲述得很是到位:
https://blog.csdn.net/itplus/article/details/40534923blog.csdn.netDeepFM是深度学习版的FM(DeepLearning+FM=DeepFM嘛),直接上图:
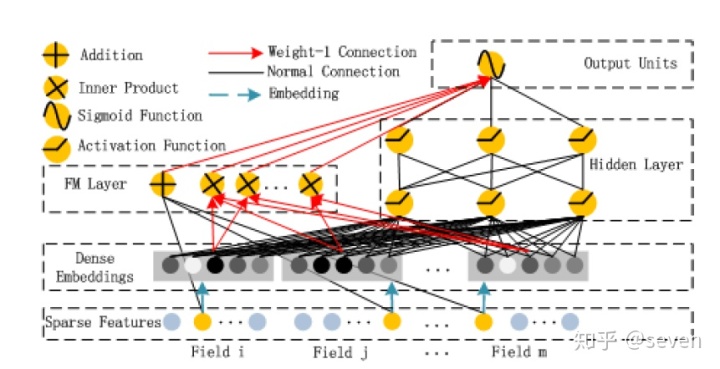
这个图来源于paper原文,看起来比较复杂。那看一下网友的简略图:
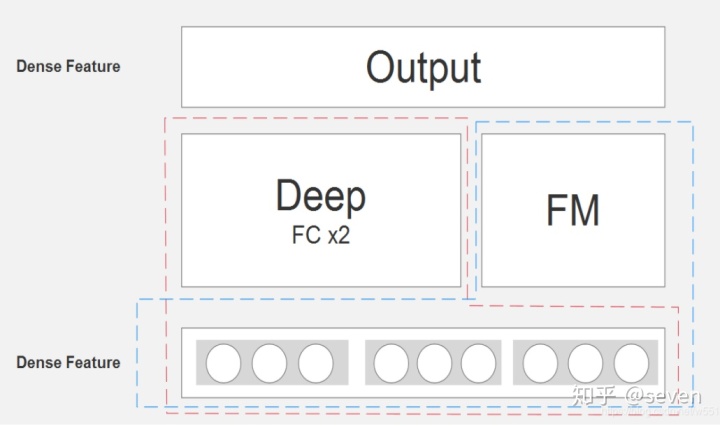
这样看就清晰多了:FM和Deep两个结构共同在提取特征,最后再把两者提取的特征做一个结合作为整个模型提取的特征。而这些特征都来源于前面的Dense Feature,这个就是模型的亮点之一 —— 权值共享,这些概念比较迷糊。可以看到就是在FM的直接上融入了一些深度学习的知识(主要是帮助映射至数学空间以及高维空间来更好的提取特征)
那说白了,DeepFM也是在处理类似FM,类似线性回归这一类的问题。但它能处理得更好,因为融入了DeepLearning的知识。那既然如此,我们用DeepFM来处理的数据就可以像是很普通的一个矩阵,每一行有多个x(这里是k个,代表k个特征变量,自变量),对应一个y(代表标签,因变量),有n行,代表n行数据:

也可以是稍微复杂点的数据,这里举例Kaggle的一个竞赛数据集:Criteo's Kaggle display advertising challenge。稍后的 pytorch 源码也是用的这个竞赛的数据集,数据视图如下:

这里截了前13行数据举例,画蓝框的就是我们所谓的标签y,绿框的就是我们的特征变量x。可以看到大体框架跟我们前面的是一样的,所以道理是类似的。但是详细地看绿框中的变量可以看到有一些是非数值型变量,这里在做数据处理的时候当然需要对非数值化数据进行数值化处理,但其实也不难。概念就是将这些值映射到数字空间的意思。这个工作具体会由DeepFM模型的第一层(embedding层或者dense层来解决)。这么看下来,我们整体的逻辑结构还是比较清晰的。
Pytorch源码
基础知识看下来难免会有似懂非懂的感觉,解决心中的疑惑最直接的方式就是看项目源码。找一个具体的应用场景,看项目整体的处理流程,以及相应的处理步骤。
pytorch源码出自:
chenxijun1029/DeepFM_with_PyTorchgithub.com
但是这份代码完成度只完成了70%,看issue里面的许多人都卡在了最后30%。这里我在尽量不违背作者原意的情况下把剩下的30%补齐给大家做一个分享。
运行环境
- 电脑:联想小新Air 13 pro
- CPU:i5 ,4G运行内存
- 显卡:NVIDIA GeForce 940MX,2G显存
- 系统:windows10 64位系统
- 软件:Anaconda 5.3.0 python 3.6.6 Pytorch1.0
数据来源
数据来源于kaggle的一个竞赛:
Display Advertising Challenge | Kagglewww.kaggle.com数据集可以从里面下到,注册、登录kaggle账号就可以了。数据压缩包大概4个G。这里我只是为了测试模型,就只拿了前1000行数据作为demo dataset,后面一同放上github。Display Advertising Challenge | Kaggle数据集可以从里面下到,注册、登录kaggle账号就可以了。数据压缩包大概4个G。这里我只是为了测试模型,就只拿了前1000行数据作为demo dataset,后面一同放上github。
这个数据竞赛是为了预测CTR。
CTR(Click-Through-Rate)
点击通过率,是互联网广告常用的术语,指网络广告(图片广告/文字广告/关键词广告/排名广告/视频广告等)的点击到达率,即该广告的实际点击次数(严格的来说,可以是到达目标页面的数量)除以广告的展现量(Show content)。
数据视图以及数据情况
这个图前面也展示过,第1列就是标签(点击与否用0/1表示,1为点击,0为没点击)。后面的2-40列数据(共39列)是我们的特征变量(指标),也就是原文paper里面提到的“n-field”的概念,这里的n是39。然后数据内又分了前13列是连续型变量,后26列是类别型变量。
项目源码流程
- 将原始数据(raw data)处理成模型的输入数据 —— datapreprocess.py
- 将处理好的数据批量输入DeepFM模型训练 —— main.py(调用了DeepFM.py dataset.py)
项目源码中一些重点提及
datapreprocess.py
主要在做的事情是将我们的数据处理成embedding层可输入的形式,这里embedding层的基础概念就不赘述了,需要大家自己了解一下。大体思路就是:我们是将39列的每一列做为独立的输入之后再合并,所以根据每一列建立索引字典。建立好之后根据索引字典将raw data(上面的数据视图呈现那样)映射到数字空间,即每个值都代表着索引字典里面的索引,可以根据索引找到原来的值。
那我们对连续型特征变量和分类型特征变量作相应的处理(对应着datapreprocess.py 中的类ContinuousFeatureGenerator 和 CategoryDictGenerator)
我们的raw data数据是有存在一些缺少值的,我们对缺失值采取的手段是填0处理,对应着两个类下边的gen函数:
def gen(self, idx, key):if key not in self.dicts[idx]:res = self.dicts[idx]['<unk>']else:res = self.dicts[idx][key]return resdef gen(self, idx, val):if val == '':return 0.0val = float(val)return val在类别型变量处理时,因为把出现频率太低的数据也加进索引字典的话,会导致模型学习的效果下降,所以在建立索引字典的时候我们会将词频太低的数据过滤,词频可以通过 cutoff 设置,具体的代码块见:
def build(self, datafile, categorial_features, cutoff=0):with open(datafile, 'r') as f:for line in f:features = line.rstrip('n').split('t')for i in range(0, self.num_feature):if features[categorial_features[i]] != '':self.dicts[i][features[categorial_features[i]]] += 1for i in range(0, self.num_feature):self.dicts[i] = filter(lambda x: x[1] >= cutoff,self.dicts[i].items())self.dicts[i] = sorted(self.dicts[i], key=lambda x: (-x[1], x[0]))vocabs, _ = list(zip(*self.dicts[i]))self.dicts[i] = dict(zip(vocabs, range(1, len(vocabs) + 1)))self.dicts[i]['<unk>'] = 0这里过滤的命令就是用的 filter,语法格式就是过滤的条件+对象。
那分类型变量处理整体的思路再强调一下就是词频太低的不加进索引字典中,没有在索引字典出现的类别最后都会填为0,意思就是不只是缺失值会被填为0,一些词频较低的也会填充为0。
将整个 datapreprocess.py 运行下来就会在".data"路径生成处理好的训练数据"train.txt"、测试数据"test.txt"以及特征表"feature_size.txt"。feature_size的后26列是根据索引字典得到的,这个地方涉及到embedding的原始知识。我们在使用embedding layer的时候切记三步走,一是建立索引字典,二是根据索引字典映射原始数据。三是根据索引字典得到feature_size之后才建立embedding layer。
这份源码就是在映射数据和建立feature_size的时候出现了问题,导致后面模型建立的时候,embedding layer 的feature size太小,对应不上,就会报错:

github上大家也是遇到同样的问题:RuntimeError: index out of range at /pytorch/aten/src/TH/generic/THTensorEvenMoreMath.cpp:191
这里就需要我们做好前面提到的那三个步骤,这是模型建立的前提。
DeepFM.py
DeepFM模型方面整体分为了四大部分:
第一个:一开始的数据处理部分——embedding layer 以及dense layer(词嵌入层)
这里主要提醒的就是数据格式问题,因为我们的前13行数据是连续型数据,是float型的。这种数据想进入embedding layer需要做离散化处理,这里我延续了它连续性变量的本质,前13列数据使用的是dense layer的概念(也就是全连接神经网络层),这个层在keras建立使用的是 Dense(),在pytorch是 nn.Linear()
在源码中具体的地方为:
fm_first_order_Linears = nn.ModuleList([nn.Linear(feature_size, self.embedding_size) for feature_size in self.feature_sizes[:13]])fm_first_order_embeddings = nn.ModuleList([nn.Embedding(feature_size, self.embedding_size) for feature_size in self.feature_sizes[13:40]])self.fm_first_order_models = fm_first_order_Linears.extend(fm_first_order_embeddings)fm_second_order_Linears = nn.ModuleList([nn.Linear(feature_size, self.embedding_size) for feature_size in self.feature_sizes[:13]])fm_second_order_embeddings = nn.ModuleList([nn.Embedding(feature_size, self.embedding_size) for feature_size in self.feature_sizes[13:40]])self.fm_second_order_models = fm_second_order_Linears.extend(fm_second_order_embeddings)所以步骤大的方向是将数据分列(这里是39列)输入对应的层,最后再来做合并。
第二个:FM 部分(主要提取1阶和2阶特征)
这里想提到的就是2阶特征怎么提取。简略版公式就是:
这里详细推导还是请大家看回上面提到的 这篇资料:
那这里对应到的源码就是:
fm_sum_second_order_emb = sum(fm_second_order_emb_arr)fm_sum_second_order_emb_square = fm_sum_second_order_emb * fm_sum_second_order_emb # (x+y)^2fm_second_order_emb_square = [item*item for item in fm_second_order_emb_arr]fm_second_order_emb_square_sum = sum(fm_second_order_emb_square) # x^2+y^2fm_second_order = (fm_sum_second_order_emb_square -fm_second_order_emb_square_sum) * 0.5如果在这个地方存疑,大家可以接着看一下:
deepFM in pytorchblog.csdn.net第三个:Deep部分
这里对应着源码的:
all_dims = [self.field_size * self.embedding_size] + self.hidden_dims + [self.num_classes]for i in range(1, len(hidden_dims) + 1):setattr(self, 'linear_'+str(i),nn.Linear(all_dims[i-1], all_dims[i]))# nn.init.kaiming_normal_(self.fc1.weight)setattr(self, 'batchNorm_' + str(i),nn.BatchNorm1d(all_dims[i]))setattr(self, 'dropout_'+str(i),nn.Dropout(dropout[i-1]))其实就是两个带着BatchNorm和Dropout的全连接层,setattr就是让这两个层跟在了前面的模型后边。
deep结构这里的拓展空间还是比较大的,因为这里只是用了两个全连接层 而已。剩下的由大家自由发挥了。
第四个:整合部分
整合部分就是将前面的几大部分特征作为一个整合来作为模型的输出,方便后面跟 label 比对进行学习。
对应源码的
bias = torch.nn.Parameter(torch.randn(Xi.size(0)))total_sum = torch.sum(fm_first_order, 1) + torch.sum(fm_second_order, 1) + torch.sum(deep_out, 1) + bias最后附上修改好的pytorch源码以供参考:
Hyfred/Pytorch_DeepFMgithub.com
当然这里还是得感谢致敬原作者所做的工作
总结
个人认为这篇文章的学习路线对小白来说还是比较适用的,但是相对的这样的学习时长可能就稍微长一些。但是积累多了,后期的学习策略和方式有相应的调整及改变之后,就会比较快了。
算法和模型方面的感悟就是,其背后真的蕴藏挺多数学原理的。要从0-1推出一套算法是很不容易的。
源码方面的感觉就是得学会调试项目源码,就跟我之前看过的一个方法一样,不断地在源码中插入断点先定位问题,之后再定义问题,然后才是想一下针对性的办法。这个过程比较繁琐,要不断试错。找到问题关键之后,查资料跟别人讨论,为问题量身定做针对的解决方案。才可以慢慢处理好。
相关文章:

超简单的网页选项卡---jQuery
<!DOCTYPE html><html lang"en"><head> <meta charset"UTF-8"> <title>网页选项卡</title> <script src"jquery-1.4.2.js"></script> <script type"text/javascript"> $(funct…

一篇文章让你了解区块链技术的发展阶段
链客,专为开发者而生,有问必答! 此文章来自区块链技术社区,未经允许拒绝转载。 区块链是由一系列技术实现的全新去中心化经济组织模式,2009年诞生于比特币系统的构建,2017年成为全球经济热点,但…
301 Remove Invalid Parentheses 删除无效的括号
删除最小数目的无效括号,使输入的字符串有效,返回所有可能的结果。注意: 输入可能包含了除 ( 和 ) 以外的元素。示例 :"()())()" -> ["()()()", "(())()"]"(a)())()" -> ["(a)()()", "(a(…

python3 列表转字节_Python 3.9!10大新特性值得关注
选自towardsdatascience作者:Farhad Malik机器之心编译编辑:陈萍近日,Python 3.9 发布,并开发了一些新特性,包括字典合并与更新、新的解析器、新的字符串函数等。Python 3.9 已于 10 月 5 日发布,新版本的特…
HDU4080 Stammering Aliens(二分 + 后缀数组)
题目 Source http://acm.hdu.edu.cn/showproblem.php?pid4080 Description Dr. Ellie Arroway has established contact with an extraterrestrial civilization. However, all efforts to decode their messages have failed so far because, as luck would have it, they ha…

共识机制:区块链技术的根基
链客,专为开发者而生,有问必答! 此文章来自区块链技术社区,未经允许拒绝转载。 Chapter-1:什么是共识机制? 技术定义是:共识机制是一个群体决策的流程,群体中的个体会执…

Web App、Hybrid App与Native App的设计差异
目前主流应用程序大体分为三类:Web App、Hybrid App、 Native App。 一、Web App、Hybrid App、Native App 纵向对比 首先,我们来看看什么是 Web App、Hybrid App、 Native App。 1. Web APP Web App 指采用Html5语言写出的App,不需要下载安装…
输入重定向,输出重定向,管道相关内容及实现方法
近期,通过实现shell了解了输入重定向,输出重定向,管道- 用自己的话总结定义: 输入重定向:把<右边的文件的内容输入到<左边的命令中。 输出重定向:把运行>左边命令得出的结果输入到>右边的文件中…

appium+python自动化测试教程_Python+Appium实现自动化测试
一、环境准备 1.脚本语言:Python3.x IDE:安装Pycharm 2.安装Java JDK 、Android SDK 3.adb环境,path添加E:\Software\Android_SDK\platform-tools 4.安装Appium for windows,官网地址 http://appium.io/点击下载按钮会到GitHub的下…

区块链热度飙升 BAT抢先布局话语权争夺战开打
链客,专为开发者而生,有问必答! 此文章来自区块链技术社区,未经允许拒绝转载。 今年以来,在互联网金融相对沉寂之后,区块链已当仁不让成为科技领域的主角。区块链作为一项突破性的新技术,如同当…

【CV知识学习】early stop、regularation、fine-tuning and some other trick to be known
深度学习有不少的trick,而且这些trick有时还挺管用的,所以,了解一些trick还是必要的。上篇说的normalization、initialization就是trick的一种,下面再总结一下自己看Deep Learning Summer School, Montreal 2016 总结的一些trick。…

etw系统provider事件较多_【Flutter 实战】文件系统目录
老孟导读:Flutter 中获取文件路径,我们都知道使用 path_provider,但对其目录对含义不是很清楚,此文介绍 Android、iOS 系统的文件目录,不同场景下建议使用的目录。 不同的平台对应的文件系统是不同的,比如文…
BZOJ4491: 我也不知道题目名字是什么
【传送门:BZOJ4491】 简要题意: 给出一个长度为n的序列,m个操作,每个操作输入x,y,求出第x个数到第y个数的最长子串,保证这个最长子串是不上升或不下降子串 题解: 线段树 因为不上升或…

区块链挖矿的钱从哪来 区块链挖矿怎么挣钱
链客,专为开发者而生,有问必答! 此文章来自区块链技术社区,未经允许拒绝转载。 进入2018年以来,区块链在资本市场的风口上依然热度不减,已成为当下最热的投资领域。而普通投资者想通过区块链投资赚钱最简单…

Linux-TCP/IP TIME_WAIT状态原理
TIME_WAIT状态原理----------------------------通信双方建立TCP连接后,主动关闭连接的一方就会进入TIME_WAIT状态。客户端主动关闭连接时,会发送最后一个ack后,然后会进入TIME_WAIT状态,再停留2个MSL时间(后有MSL的解释)…

python如何实现找图_利用OpenCV和Python实现查找图片差异
使用OpenCV和Python查找图片差异 flyfish 方法1 均方误差的算法(Mean Squared Error , MSE)下面的一些表达与《TensorFlow - 协方差矩阵》式子表达式一样的拟合 误差平方和( sum of squared errors) residual sum of squares (RSS…

区块链还能赚钱吗 区块链挖矿赚钱吗
链客,专为开发者而生,有问必答! 此文章来自区块链技术社区,未经允许拒绝转载。 区块链有多火,连我母上都知道这个词,身边很多人也都向笔者咨询这个东西。 其实他们真实的想法是,想知道这东西到…
pythonfor循环遍历list_为什么for循环可以遍历list:Python中迭代器与生成器
1 引言 只要你学了Python语言,就不会不知道for循环,也肯定用for循环来遍历一个列表(list),那为什么for循环可以遍历list,而不能遍历int类型对象呢?怎么让一个自定义的对象可遍历? 这篇博客中&am…
Linux下查看和添加环境变量
转自:http://blog.sina.com.cn/s/blog_688077cf01013qrk.html $PATH:决定了shell将到哪些目录中寻找命令或程序,PATH的值是一系列目录,当您运行一个程序时,Linux在这些目录下进行搜寻编译链接。 编辑你的 PATH 声明&am…

iis7下站点日志默认位置
iis7下站点日志默认位置 原文:iis7下站点日志默认位置iis7下站点日志默认位置在iis6时,通过iis管理器的日志配置可以找到站点日志存储的位置。但是在iis7下,iis管理器下的日志配置只能找到iis日志配置的主目录,但到底在哪个子目录,…

go语言有哪些优势
链客,专为开发者而生,有问必答! 此文章来自区块链技术社区,未经允许拒绝转载。 1、学习曲线容易 Go语言语法简单,包含了类C语法。因为Go语言容易学习,所以一个普通的大学生花几个星期就能写出来可以上手的…
重定向后,如何通过浏览器返回定向之前的页面?
js实现页面跳转重定向的几种方式 第一种: 代码如下: <script language"javascript"type"text/javascript">window.location.href"http://shanghepinpai.com";</script> 第二种: 代码如下: <script languag…
金蝶中间件部署报栈溢出_京东618压测时自研中间件暴露出的问题,压测级别数十万/秒...
618大促演练进行了全链路压测,在此之前刚好我的热key探测框架也已经上线灰度一周了,小范围上线了几千台服务器,每秒大概接收几千个key探测,每天大概几亿左右,因为量很小,所以框架表现稳定。借着这次压测&am…
利用box-shadow绘图
上篇博客提到过,box-shadow属性的本质是对形状的复制,那么如果我设置一个1*1px的i标签,利用box-shadow可以叠加的特性,给每一个1*1px的阴影赋上颜色,那么最后不就是一幅图片了么。 html代码很简单: <!do…

为什么要使用Go语言?Go语言的优势在哪里?
链客,专为开发者而生,有问必答! 此文章来自区块链技术社区,未经允许拒绝转载。 Go语言之所有越来越受到开发者的欢迎,我认为与其超高的实用价值密不可分。要知道Go语言是为了解决现实问题而设计的,而不是为…

BI之SSAS完整实战教程3 -- 创建第一个多维数据集
上一篇我们已经完成了数据源的准备工作,现在我们就开始动手,创建第一个多维数据集(Cube)。 文章提纲 使用多维数据集向导创建多维数据集 总结Cube设计器简介 维度细化 总结 一、使用向导创建多维数据集 在Analysis Services中,可以通过3种…
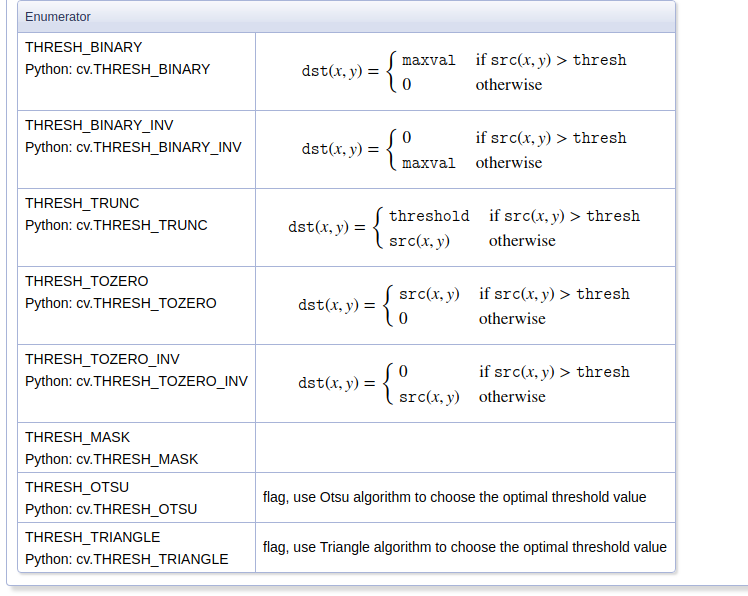
python opencv local_threshold_Python-OpenCV中的cv2.threshold
主要记录Python-OpenCV中的cv2,threshold()方法;官方文档 cv2.threshold() def threshold(src, thresh, maxval, type, dstNone): """ 设置固定级别的阈值应用于多通道矩阵 例如,将灰度图像变换二值图像,或去除指定级别的噪声…
java中decimalFormat格式化数值
介绍 我们经常要对数字进行格式化,比如取小数点后两位小数,或者加个百分比符号等,Java提供了DecimalFormat这个类0 和 # 的区别 "#"可以理解为在正常的数字显示中,如果前缀与后缀出现不必要的多余的0,则将其…

GO语言有哪些优势?怎样入门?
链客,专为开发者而生,有问必答! 此文章来自区块链技术社区,未经允许拒绝转载。 1、学习曲线 它包含了类C语法、GC内置和工程工具。这一点非常重要,因为Go语言容易学习,所以一个普通的大学生花一个星期就能…
POJ-2955 Brackets
题目大意: 给你一个只由(、)、[、]组成的字符串,问你这个字符串的子串能够匹配的最长长度是多少。 能够匹配的意思是这样的: 1.如果s是个空串,那么它是匹配的。 2.如果子串是(s)或者[s],那么它也是匹配的,其…