一文搞懂深度信念网络!DBN概念介绍与Pytorch实战
本文深入探讨了深度信念网络DBN的核心概念、结构、Pytorch实战,分析其在深度学习网络中的定位、潜力与应用场景。
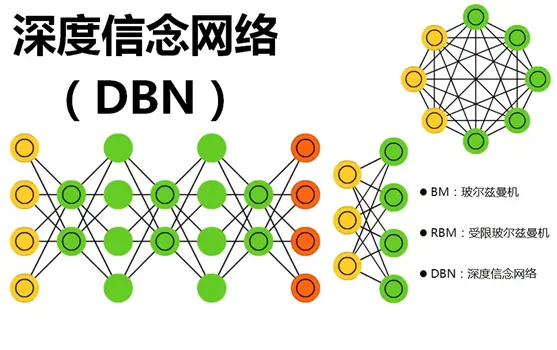
一、概述
1.1 深度信念网络的概述
深度信念网络(Deep Belief Networks, DBNs)是一种深度学习模型,代表了一种重要的技术创新,具有几个关键特点和突出能力。
首先,DBNs是由多层受限玻尔兹曼机(Restricted Boltzmann Machines, RBMs)堆叠而成的生成模型。这种多层结构使得DBNs能够捕获数据中的高层次抽象特征,对于复杂的数据结构具有强大的表征能力。
其次,DBNs采用无监督预训练的方式逐层训练模型。与传统的深度学习模型不同,这种逐层学习策略使DBNs在训练时更为稳定和高效,尤其适合处理高维数据和未标记数据。
此外,DBNs具有出色的生成学习能力。它不仅可以学习和理解数据的分布,还能够基于学习到的模型生成新的数据样本。这种生成能力在图像合成、文本生成等任务上有着广泛的应用前景。
最后,DBNs的训练和优化涉及到一些先进的算法和技术,如对比散度(Contrastive Divergence, CD)算法等。这些算法的应用和改进,使DBNs在许多实际问题上表现卓越,但同时也带来了一些挑战,如参数调优的复杂性等。
总的来说,深度信念网络通过其独特的结构和生成学习的能力,展示了深度学习的新方向和潜力。它的关键技术创新和突出能力使其在诸多领域成为一种有力的工具,为人工智能的发展和应用提供了新的机遇。
1.2 深度信念网络与其他深度学习模型的比较
深度信念网络(DBNs)作为深度学习领域的一种重要模型,与其他深度学习模型有着许多共同点,但也有着鲜明的特色。以下我们从不同的角度来比较DBNs与其他主要深度学习模型。
结构层次
DBNs: 由多层受限玻尔兹曼机堆叠而成,每一层都对上一层的表示进行进一步抽象。采用无监督预训练,逐层构建复杂模型。
卷积神经网络(CNNs): 采用卷积层、池化层等特殊结构,适合空间数据如图像。
循环神经网络(RNNs): 通过时间递归结构,适合处理序列数据如文本。
学习方式
DBNs: 具有生成学习能力,可以生成新的数据样本,适用于无监督学习和半监督学习场景。
CNNs、RNNs: 主要进行判别学习,通过监督学习进行分类或回归等任务。
训练和优化
DBNs: 使用对比散度等复杂优化算法,参数调优相对困难。
CNNs、RNNs: 可以使用梯度下降等常见优化方法,训练过程相对更为直观和容易。
应用领域
DBNs: 由于其生成学习和多层结构特性,特别适合处理高维数据、缺失数据等复杂场景。
CNNs: 在图像处理领域有着广泛的应用。
RNNs: 在自然语言处理和时间序列分析等领域有优势。
1.3 应用领域
深度信念网络(DBNs)作为一种强大的深度学习模型,已广泛应用于多个领域。其能够捕捉复杂数据结构的特性,让DBNs在以下应用领域中表现出卓越的能力。
图像识别与处理
DBNs可以用于图像分类、物体检测和人脸识别等任务。其深层结构可以捕获图像中的复杂特征,比如纹理、形状和颜色等。在医学图像分析方面,DBNs也展现出强大的潜力,如用于疾病检测和组织分割等。
自然语言处理
通过与其他神经网络结构的组合,DBNs可以处理文本分类、情感分析和机器翻译等任务。其能够理解和生成语言的能力为处理复杂文本提供了强有力的工具。
推荐系统
DBNs的生成模型特性使其在推荐系统中也有广泛应用。通过学习用户和物品之间的潜在关系,DBNs能够生成个性化的推荐列表,从而提高推荐的准确性和用户满意度。
语音识别
在语音识别领域,DBNs可以用于提取声音信号的特征,并结合其他模型如隐马尔可夫模型(HMM)进行语音识别。其在复杂声音环境下的鲁棒性使其在这一领域有着显著优势。
无监督学习与异常检测
DBNs的无监督学习能力也使其在无监督聚类和异常检测等任务上表现出色。特别是在数据标签缺失或稀缺的场景下,DBNs可以提取有用的信息,用于发现数据中的潜在结构或异常模式。
药物发现与生物信息学
在药物发现和生物信息学方面,DBNs可以用于预测药物的生物活性、发现新的药物靶点等。其对高维数据的处理能力为解析复杂生物系统提供了有效手段。
二、结构
2.1 受限玻尔兹曼机(RBM)
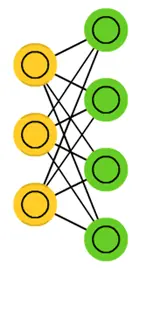
受限玻尔兹曼机(Restricted Boltzmann Machine, RBM)是深度信念网络的基本构建块。以下将详细介绍RBM的关键组成、工作原理和学习算法。
结构与组成
RBM是一种生成随机神经网络,由两层完全连接的神经元组成:可见层和隐藏层。
可见层(Visible Layer): 包括对数据直接进行编码的神经元。
隐藏层(Hidden Layer): 包括从可见层学习特征的神经元。
RBM中的连接是无向的,即连接是对称的。同一层中的神经元之间没有连接。
工作原理
RBM的工作原理基于能量函数,该函数定义了网络状态的能量。
能量函数: RBM通过一个称为能量函数的数学公式来表示不同状态之间的关系。
联合概率分布: RBM的能量与其状态的联合概率分布有关,其中较低的能量对应较高的概率。
学习算法
RBM的学习算法包括以下主要步骤:
前向传播: 从可见层到隐藏层的激活。
后向传播: 从隐藏层到可见层的重构。
梯度计算: 通过对比散度(Contrastive Divergence, CD)计算权重更新的梯度。
权重更新: 通过学习率更新权重。
应用
RBM被广泛用于特征学习、降维、分类等任务。作为深度信念网络的基本组成部分,RBM的应用也直接扩展到更复杂的数据建模任务中。
2.2 DBN的结构和组成
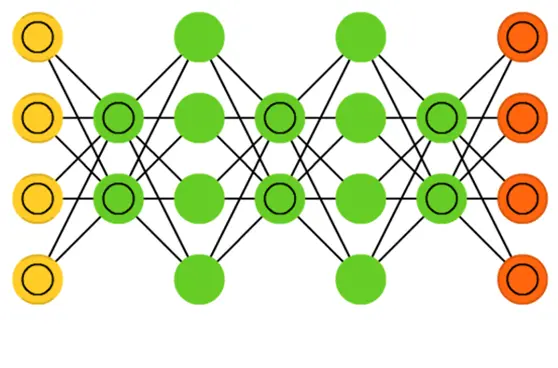
深度信念网络(Deep Belief Network,DBN)是一种深度学习模型,可以捕捉数据中的复杂层次结构。下面详细介绍DBN的结构和组成部分。
层次结构
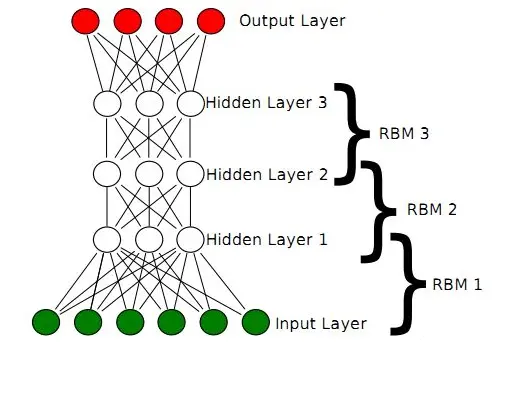
DBN的结构由多个层组成,通常包括多个受限玻尔兹曼机(RBM)层和一个顶层。每一层由一组神经元组成,通过双向连接与相邻层的神经元相连。
输入层: 对应数据的可见表示。
隐藏层: 包括多个RBM层,每一层对应数据的更高层次抽象。
顶层: 通常由一个RBM或其他模型组成,负责最终特征的提取和表示。
网络连接
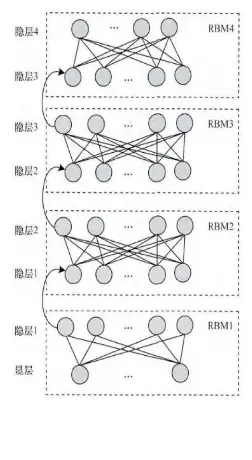
DBN的连接结构遵循以下规则:
同一层的神经元之间没有连接。
每一层的神经元与上下层的所有神经元都有连接。
连接是无向的(对于前几层的RBM)或有向的(对于顶层)。
训练过程
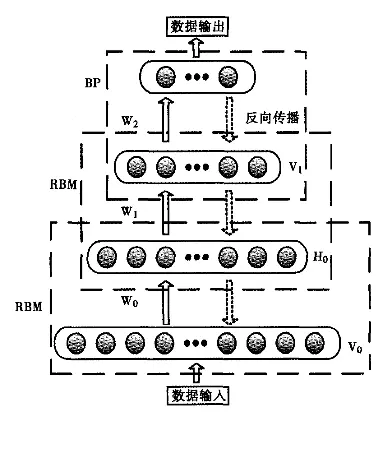
DBN的训练过程分为两个主要阶段:
预训练阶段: 每个RBM层按照从底到顶的顺序进行贪婪逐层训练。
微调阶段: 使用监督学习方法(如反向传播)对整个网络进行微调。
应用领域
DBN的结构和训练策略使其适用于许多复杂的建模任务,包括:
特征学习: 学习输入数据的多层次抽象表示。
分类: 基于学习的特征执行分类任务。
生成建模: 生成与训练数据相似的新样本。
2.3 训练和学习算法
深度信念网络的训练是一个复杂且重要的过程。这一节将详细介绍DBN的训练和学习算法。
预训练
预训练是DBN训练的第一阶段,主要目的是初始化网络权重。
逐层训练: DBN的每个RBM层单独训练,自底向上逐层进行。
无监督学习: 使用无监督学习算法(如对比散度)训练RBM。
生成权重: 每一层训练后,其权重用于下一层的输入。
微调
微调是DBN训练的第二阶段,调整预训练后的权重以改善性能。
反向传播算法: 通常使用反向传播算法进行监督学习。
误差最小化: 微调过程旨在通过调整权重最小化训练数据的预测误差。
早停法: 通过在验证集上监控性能来防止过拟合。
优化方法
深度信念网络的训练通常涉及许多优化技术。
学习率调整: 动态调整学习率可以加速训练并提高性能。
正则化: 如L1和L2正则化有助于防止过拟合。
动量优化: 动量可以帮助优化算法更快地收敛到最优解。
评估和验证
训练过程还包括对模型的评估和验证。
交叉验证: 使用交叉验证来评估模型的泛化能力。
性能指标: 使用如准确率、召回率等指标来评估模型性能。
三、实战
3.1 DBN模型的构建
深度信念网络是一种由多个受限玻尔兹曼机(RBM)层堆叠而成的生成模型。下面是构建DBN模型的具体步骤。
定义RBM层
RBM是DBN的基本构建块。它包括可见层和隐藏层,并通过权重矩阵连接。
class RBM(nn.Module):
def __init__(self, visible_units, hidden_units):
super(RBM, self).__init__()
self.W = nn.Parameter(torch.randn(hidden_units, visible_units) * 0.1)
self.h_bias = nn.Parameter(torch.zeros(hidden_units))
self.v_bias = nn.Parameter(torch.zeros(visible_units))
def forward(self, v):
# 定义前向传播
# 省略其他代码...权重初始化: 权重矩阵的初始化非常重要,通常使用较小的随机值。
偏置项: 可见层和隐藏层都有偏置项,通常初始化为零。
构建DBN模型
DBN模型由多个RBM层组成,每一层的隐藏单元与下一层的可见单元相连。
class DBN(nn.Module):
def __init__(self, layers):
super(DBN, self).__init__()
self.rbms = nn.ModuleList([RBM(layers[i], layers[i + 1]) for i in range(len(layers) - 1)])
def forward(self, v):
h = v
for rbm in self.rbms:
h = rbm(h)
return h逐层连接: 每个RBM层的输出成为下一个RBM层的输入。
模块列表: 使用
nn.ModuleList来存储RBM层,确保它们都被正确注册。
定义DBN的超参数
DBN的构建也涉及到选择合适的超参数,例如每个RBM层的可见和隐藏单元的数量。
# 定义DBN的层大小
layers = [784, 500, 200, 100]
# 创建DBN模型
dbn = DBN(layers)3.2 预训练
预训练是DBN训练过程中的一个关键阶段,通过逐层训练RBM来完成。以下是具体的预训练步骤。
RBM的逐层训练
DBN的每个RBM层都分别进行训练。训练一个RBM层的目的是找到可以重构输入数据的权重。
# 预训练每个RBM层
for index, rbm in enumerate(dbn.rbms):
for epoch in range(epochs):
# 使用对比散度训练RBM
# 省略具体代码...
print(f"RBM {index} trained.")逐层训练: 每个RBM层都独立训练,并使用上一层的输出作为下一层的输入。
对比散度(CD)算法
对比散度是训练RBM的常用方法。它通过对可见层和隐藏层的样本进行采样来更新权重。
# 对比散度训练
def contrastive_divergence(rbm, data, learning_rate):
v0 = data
h0_prob, h0_sample = rbm.sample_h(v0)
v1_prob, _ = rbm.sample_v(h0_sample)
h1_prob, _ = rbm.sample_h(v1_prob)
positive_grad = torch.matmul(h0_prob.T, v0)
negative_grad = torch.matmul(h1_prob.T, v1_prob)
rbm.W += learning_rate * (positive_grad - negative_grad) / data.size(0)
rbm.v_bias += learning_rate * torch.mean(v0 - v1_prob, dim=0)
rbm.h_bias += learning_rate * torch.mean(h0_prob - h1_prob, dim=0)正相位和负相位: 正相位与数据分布有关,而负相位与模型分布有关。
梯度更新: 权重更新基于正相位和负相位之间的差异。
3.3 微调
微调阶段是DBN训练流程中的最后部分,其目的是对网络进行精细调整以优化特定任务的性能。
监督训练
在微调阶段,DBN与一个或多个额外的监督层(例如全连接层)结合,以便进行有监督的训练。
# 在DBN上添加监督层
class SupervisedDBN(nn.Module):
def __init__(self, dbn, output_size):
super(SupervisedDBN, self).__init__()
self.dbn = dbn
self.classifier = nn.Linear(dbn.rbms[-1].hidden_units, output_size)
def forward(self, x):
h = self.dbn(x)
return self.classifier(h)额外的监督层: 可以添加全连接层进行分类或回归任务。
微调训练
微调训练使用标准的反向传播算法,并可以采用任何常见的优化器和损失函数。
# 定义优化器和损失函数
optimizer = torch.optim.Adam(supervised_dbn.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
# 微调训练
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = supervised_dbn(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()优化器: 如Adam或SGD等。
损失函数: 取决于任务,例如交叉熵损失用于分类任务。
模型验证和测试
微调阶段还涉及在验证和测试数据集上评估模型的性能。
# 模型验证和测试
def evaluate(model, data_loader):
correct = 0
with torch.no_grad():
for data, target in data_loader:
output = model(data)
pred = output.argmax(dim=1)
correct += (pred == target).sum().item()
accuracy = correct / len(data_loader.dataset)
return accuracy3.4 应用
分类或回归任务
例如,DBN可用于图像分类、股价预测等。
特征学习
DBN可用于无监督的特征学习,以捕捉输入数据的有用表示。
转移学习
训练有素的DBN可以用作预训练的特征提取器,以便在相关任务上进行迁移学习。
在线应用
DBN可以集成到在线系统中,实时进行预测。
# 实时预测示例
def real_time_prediction(model, new_data):
with torch.no_grad():
prediction = model(new_data)
return prediction四、总结
深度信念网络(DBN)作为一种强大的生成模型,近年来在许多机器学习和深度学习任务中取得了成功。在这篇文章中,我们详细探讨了DBN的基础结构、训练过程以及评估和应用。以下是一些关键要点的总结:
结构和组成: DBN是由多个受限玻尔兹曼机(RBM)堆叠而成的,每个RBM层负责捕获数据的特定特征。
训练和学习算法: 训练过程包括预训练和微调两个阶段。预训练负责初始化权重,而微调则使用监督学习来优化模型的特定任务性能。
应用: 分类、回归、特征学习、转移学习等。
工具和实现: 使用PyTorch等深度学习框架,可以方便地实现DBN。文章提供了清晰的代码示例,帮助读者理解并实现这一复杂的模型。
文章转载自:techlead_krischang
相关文章:

Yolov11-detect训练自己的数据集
至此,整个YOLOv11的训练预测阶段完成,与YOLOv8差不多。欢迎各位批评指正。

YOLOv10训练自己的数据集
至此,整个YOLOv10的训练预测阶段完成,与YOLOv8差不多。欢迎各位批评指正。
YOLOv10环境搭建、模型预测和ONNX推理
运行后会在文件yolov10s.pt存放路径下生成一个的yolov10s.onnxONNX模型文件。安装完成之后,我们简单执行下推理命令测试下效果,默认读取。终端,进入base环境,创建新环境。(1)onnx模型转换。
TCP协议-TCP连接管理
TCP协议是 TCP/IP 协议族中一个非常重要的协议。它是一种面向连接、提供可靠服务、面向字节流的传输层通信协议。TCP(Transmission Control Protocol,传输控制协议)。

计算机网络TCP/IP协议-从双绞线到TCP
消息响应也是同理,这种带端口的消息发送方式,其实就是UDP协议,UDP简单粗暴,但是UDP存在很多问题,所以我们需要设计一个稳定可靠的协议,TCP协议,首先,网络是不稳定的,我们发送的消息很有可能会在中途丢失,所以需要设置重试机制,当消息发送失败时重新发送,为了判断是否成功,还需要要求接收方收到消息后,必须发送确认消息,这样就可以保证消息必达,另外大段的内容发送,很容易造成部分丢失,导致全部内容都要重新发送,于是我们可以将数据分包,分成多个包发送。到这,也行你会发现了,演示中的IP地址是怎么设置的呢?

YOLOv7-Pose 姿态估计-环境搭建和推理
终端,进入base环境,创建新环境,我这里创建的是p38t17(python3.8,pytorch1.7)安装pytorch:(网络环境比较差时,耗时会比较长)下载好后打开yolov7-pose源码包。imgpath:需要预测的图片的存放路径。modelpath:模型的存放路径。Yolov7-pose权重下载。打开工程后,进入设置。
Java之网络通信框架mina
mina是一个基于java nio的网络通信框架。主要屏蔽了网络通信的一些细节,对Socket进行封装,并且是NIO的一个实现架构,可以帮助我们快速的开发网络通信,常用于游戏的开发、中间件服务端的程序中。Apache的Mina(Multipurpose Infrastructure Networked Applications)是一个网络应用框架,可以帮助用户开发高性能和高扩展性的网络应用程序;它提供了一个抽象的、事件驱动的异步API,使。
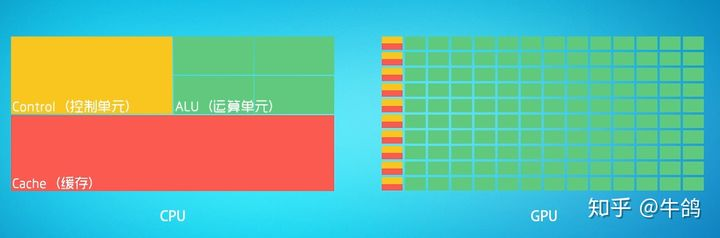
深度学习硬件基础:CPU与GPU
CPU:叫做中央处理器(central processing unit)作为计算机系统的运算和控制核心,是信息处理、程序运行的最终执行单元。[^3]可以形象的理解为有25%的ALU(运算单元)、有25%的Control(控制单元)、50%的Cache(缓存单元)GPU:叫做图形处理器。

YOLOv8-Detect训练CoCo数据集+自己的数据集
至此,整个训练预测阶段完成。此过程同样可以在linux系统上进行,在数据准备过程中需要仔细,保证最后得到的数据准确,最好是用显卡进行训练。有问题评论区见!

CSS局限属性contain:优化渲染性能的利器
在网页开发中,优化渲染性能是一个重要的目标。CSS局限属性contain是一个强大的工具,可以帮助我们提高网页的渲染性能。本文将介绍contain属性的基本概念、用法和优势,以及如何使用它来优化网页的渲染过程。
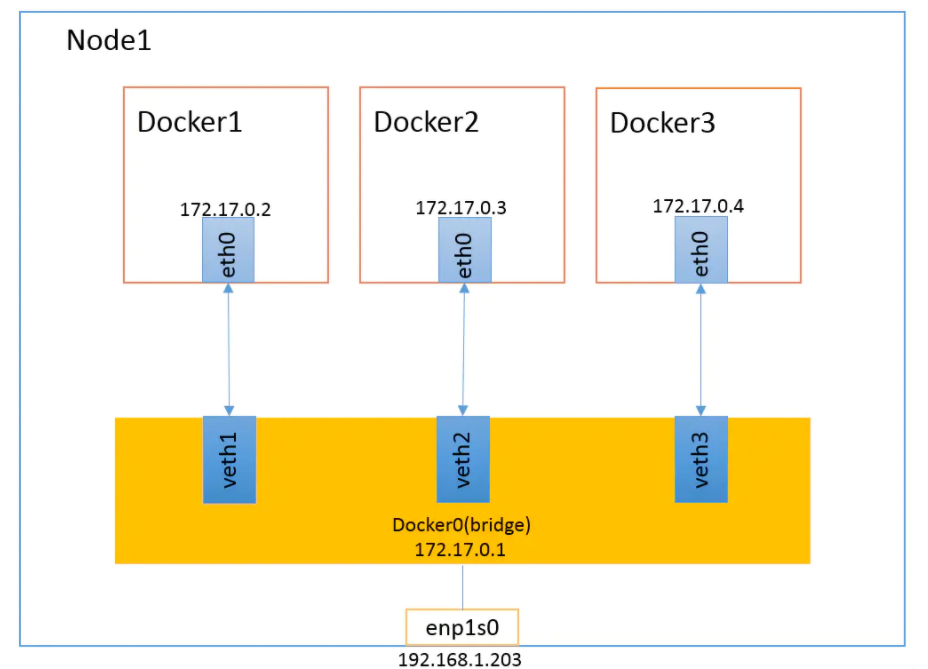
Docker网络详解
如何自定义一个网络?查看新创键的mynet详细信息:# 创建两个使用相同自定义网络的容器# 测试容器互连^C^C。

DNS轮询解析是什么?
在其最简单的实现中,轮回DNS的工作方式是,不仅用一个潜在的IP地址来响应DNS请求,而且用一个潜在的IP地址列表来响应承载相同服务的几个服务器。传统的负载均衡技术通常需要专门的硬件或软件,但DNS轮询解析是一种负载分配、负载平衡或容错技术,通过管理域名系统(DNS)对来自客户计算机的地址请求的响应,按照适当的统计模型,提供多个冗余的互联网协议服务主机,将流量分散到多个服务器上。因此,虽然轮询DNS是一种简单有效的负载平衡方法,但它也存在一些限制和潜在的问题,需要根据实际情况进行选择和使用。
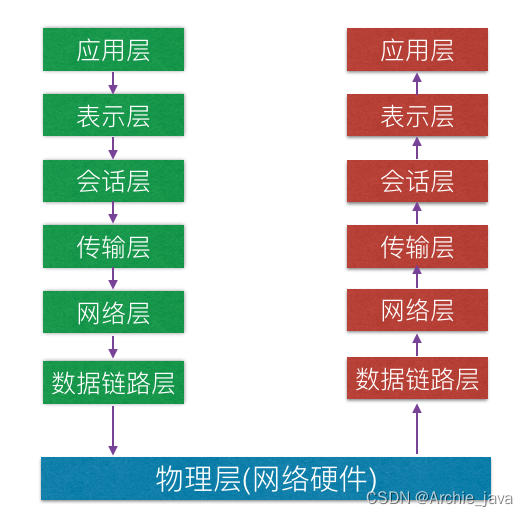
一文搞懂网络OSI网络模型
在互联网技术里,有两件事最为重要,一个是TCP/IP协议,它是万物互联的事实标准;另一个是Linux操作系统,它是推动互联网技术走向繁荣的基石。在网络编程中最重要的模型便是OSI七层网络模型和TCP/IP四层网络模型七层模型,也称为OSI(Open System Interconnection)参考模型,是国际标准化(ISO)指定的一个用于计算机或通信系统间互联的标准体系。建立七层模型的主要目的是为解决各种网络互联时遇到的兼容性问题。
常见的几种网络抓包及协议分析工具
网络工程师必备技能-抓取网络数据。在本篇博客中,我们将集中记下几个问题进行探讨:Wireshark 是免费的抓取数据包、分析数据包的工具,兼容 Windows、Linux、Mac等主流平台。使用 wireshark 抓包需要的工具是:安装了 wireshark 的 PC。wireshark 抓包的范围是:抓取安装了 wireshark 的 PC 本机的网卡上流经的数据包。其中,网卡指的是 PC 上网使用的模块,常见的包括:以太网网卡、wifi 无线网卡,PC 分别使用它们用于连接以太网、wifi 无线网络。
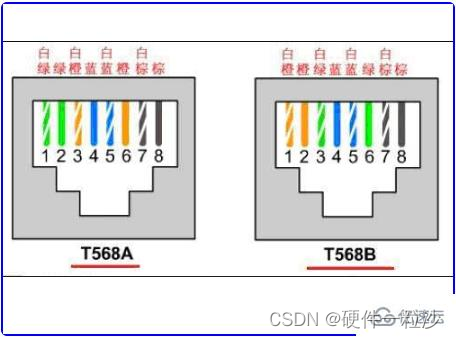
为什么网线接法要分交叉连接和直连连接两种方式
水晶头有两种连接方式T568A和T568B。网线的两头都使用同一标准连接就是直连线,两头使用不同的标准就是交叉线。
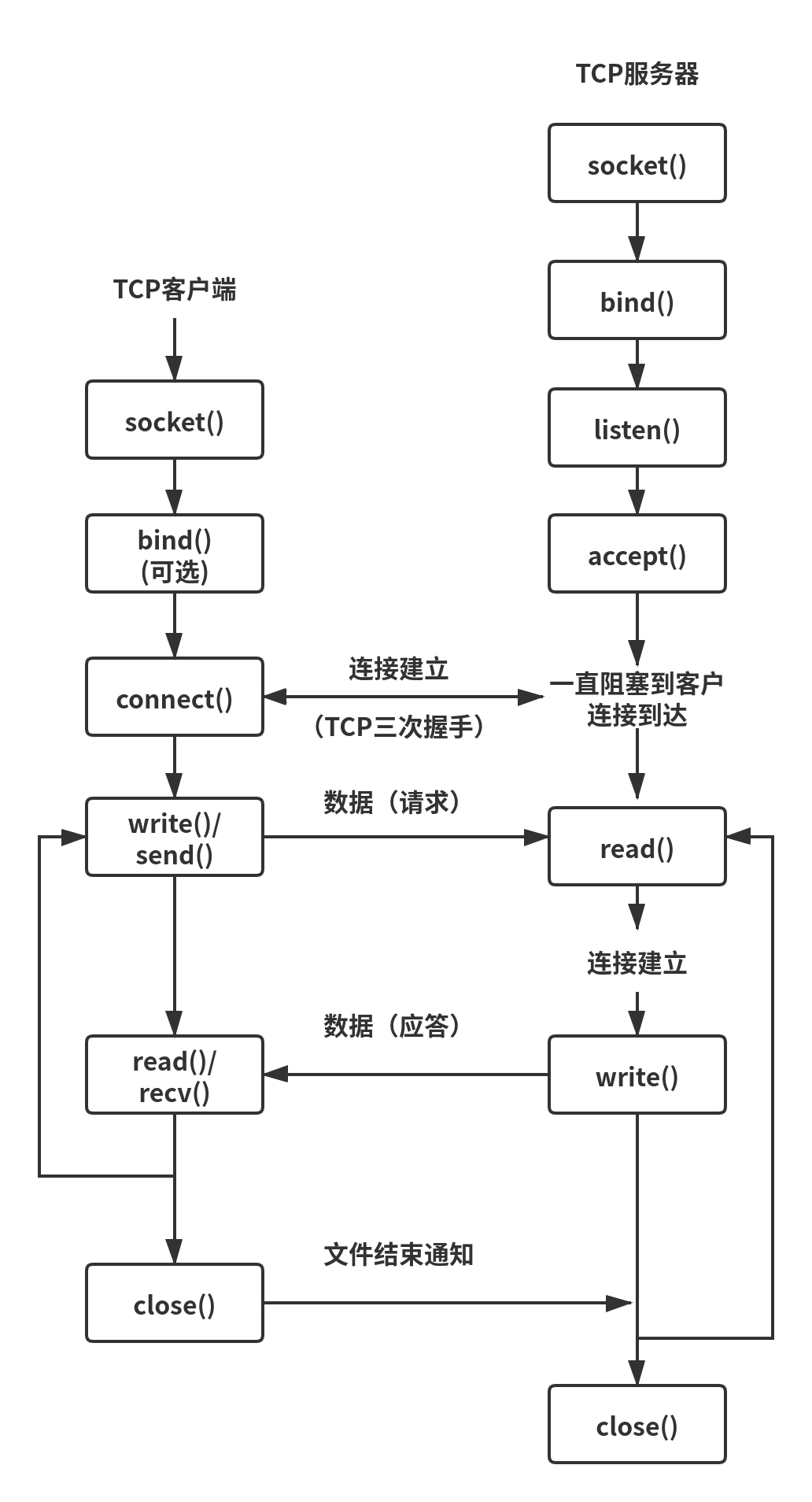
TCP服务器最多支持多少客户端连接
本文从理论和实际两个方面介绍了一个 TCP 服务器支持的最大连接数
websocket服务端本地部署
即登录cpolar官网后,点击预留,保留一个固定tcp端口地址,然后将其配置到相应的隧道中即可。这里我们用cpolar内网穿透来映射内网端口,它支持http/https/tcp协议,不限制流量,无需公网ip,也不用设置路由器,操作简单。注意:该隧道选择的是临时tcp地址和端口,24小时内会变化,如需固定tcp地址,可升级为专业套餐做tcp地址固定!cpolar安装成功后,默认会配置两个默认隧道:一个ssh隧道和一个website隧道,可自行删减或者修改。,可以查看到token码,复制并执行命令进行认证。
微信小程序之WXSS模板样式、页面配置(.json)和网络数据请求
一、WXSS 模板样式1、什么是 WXSS2、WXSS 和 CSS 的关系二、WXSS 模板样式 - rpx1、什么是 rpx 尺寸单位2、rpx 的实现原理3、rpx 与 px 之间的单位换算*三 、WXSS 模板样式 - 样式导入1、什么是样式导入2、@import 的语法格式四、WXSS 模板样式 - 全局样式和局部样式1、全局样式2、局部样式五、页面配置1、页面配置文件的作用2、页面配置和全局配置的关系3、页面配置中常用的配置项。

python基础小知识:引用和赋值的区别
通过引用,就可以在程序范围内任何地方传递大型对象而不必在途中进行开销巨大的赋值操作。不过需要注意的是,这种赋值仅能做到顶层赋值,如果出现嵌套的情况下仍不能进行深层赋值。赋值与引用不同,复制后会产生一个新的对象,原对象修改后不会影响到新的对象。如果在原位置修改这个可变对象时,可能会影响程序其他位置对这个对象的引用

基于深度学习的细胞感染性识别与判定
通过引入深度学习技术,我们能够更精准地识别细胞是否受到感染,为医生提供更及时的信息,有助于制定更有效的治疗方案。基于深度学习的方法通过学习大量样本,能够自动提取特征并进行准确的感染性判定,为医学研究提供了更高效和可靠的手段。通过引入先进的深度学习技术,我们能够实现更快速、准确的感染性判定,为医学研究和临床实践提供更为可靠的工具。其准确性和效率将为医学研究带来新的突破,为疾病的早期诊断和治疗提供更可靠的支持。通过大规模的训练,模型能够学到细胞感染的特征,并在未知数据上做出准确的预测。
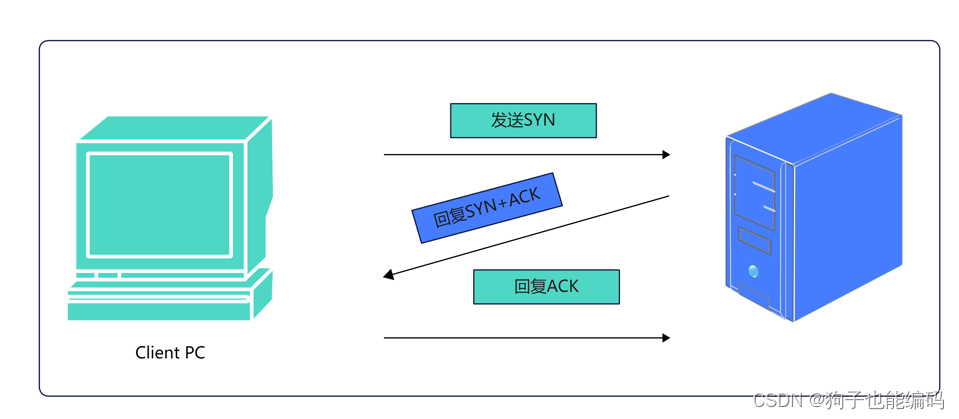
TCP三次握手和四次挥手
看了大量的文章都不知道ack包,fin包,syn包是干嘛的?我搜了一些概念以及总结道一起是不是更容易理解一些方便后续面试使用
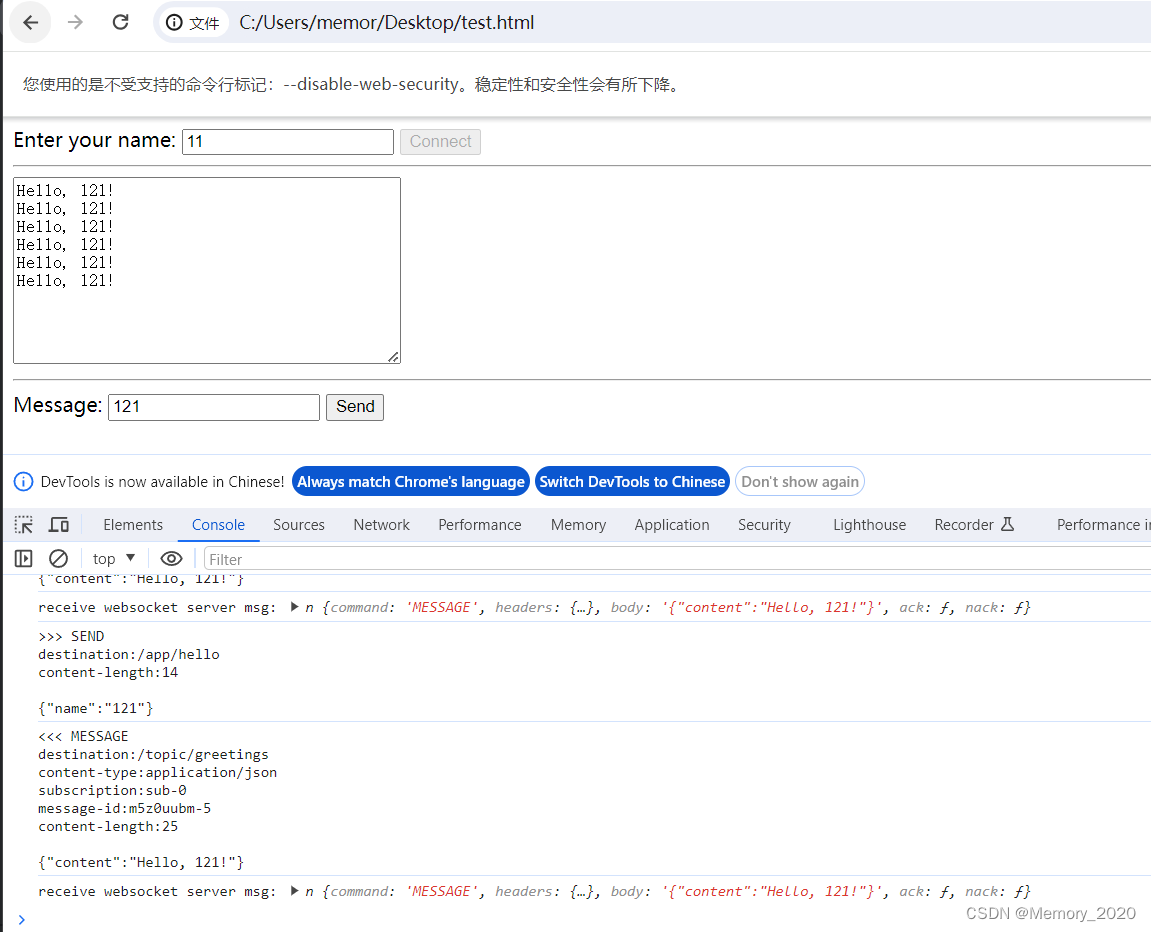
WebSocket 入门实战
这个简单示例演示了如何使用 Spring Boot 和 Spring WebSocket 创建一个基本的 WebSocket 服务。通过这个例子,可以了解 WebSocket 在实时通信中的应用,如果大家在平时工作当中有遇到需要实时推送的场景,比如大屏实时展示数据变化,就可以用这种发放时。

Docker网络配置&网络模式
网络相关概念,子网掩码、网关、规则的介绍及网络模式bridge、host详解,Dockers自定义网络配置
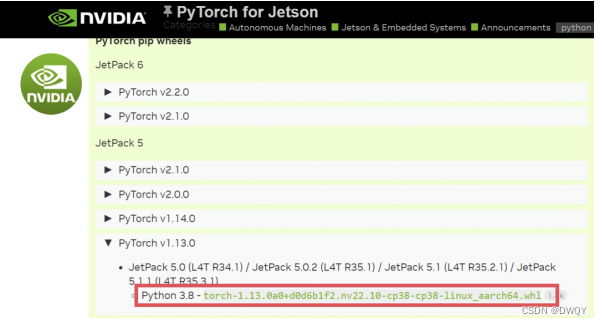
Jetson AGX Orin安装archiconda、Pytorch
Jetson AGX Orin安装archiconda、Pytorch

TCP怎么保证传输过程的可靠性?
校验和发送方在发送数据之前计算校验和,接收方收到数据后同样计算,如果不一致,那么传输有误确认应答,序列号TCP进行传输时数据都进行了编号,每次接收方返回ACK都有确认序列号。超时重试这里是引用连接管理流量控制阻塞控制..._tcp传输过程可靠性

windows安装conda环境,开发openai应用准备,运行第一个ai程序
作者开发第一个openai应用的环境准备、第一个openai程序调用成功,做个记录,希望帮助新来的你。第一次能成功运行的openai程序,狠开心。
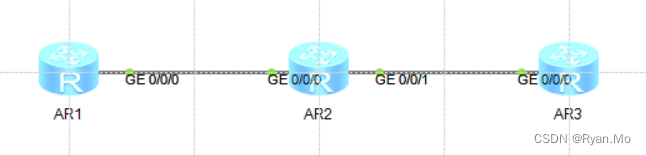
华为路由器OSPF动态链路路由协议配置
【代码】华为路由器OSPF动态链路路由协议配置。
揭秘代理IP:原理、类型及其在大数据抓取中的作用
代理IP的原理:代理服务器作为客户端与目标网站之间的中介,当请求数据时,不是直接由用户的原始IP地址发送到目标网站,而是先发送到代理服务器。- 提升抓取效率:利用多个代理IP实现并发抓取,可以分散请求负载,提高数据采集速度,尤其是在需要大量数据或高频率访问时尤为关键。- 地域定位:某些代理IP能够提供特定地区的IP地址,这使得爬虫能够抓取特定区域的内容,比如针对不同国家或地区的本地化信息。- 绕过反爬机制:通过不断更换代理IP,爬虫可以避免因频繁访问而触发目标网站的反爬策略,从而继续高效地抓取数据。
你了解计算机网络的发展历史吗?
计算机网络是指将一群具有独立功能的计算机通过被互联起来的,在通信软件的支持下,实现的系统。计算机网络是计算机技术与通信技术紧密结合的产物,两者的迅速发展渗透形成了计算机网络技术。简而言之呢,计算机网络就是实现两台计算机相互沟通的介质。
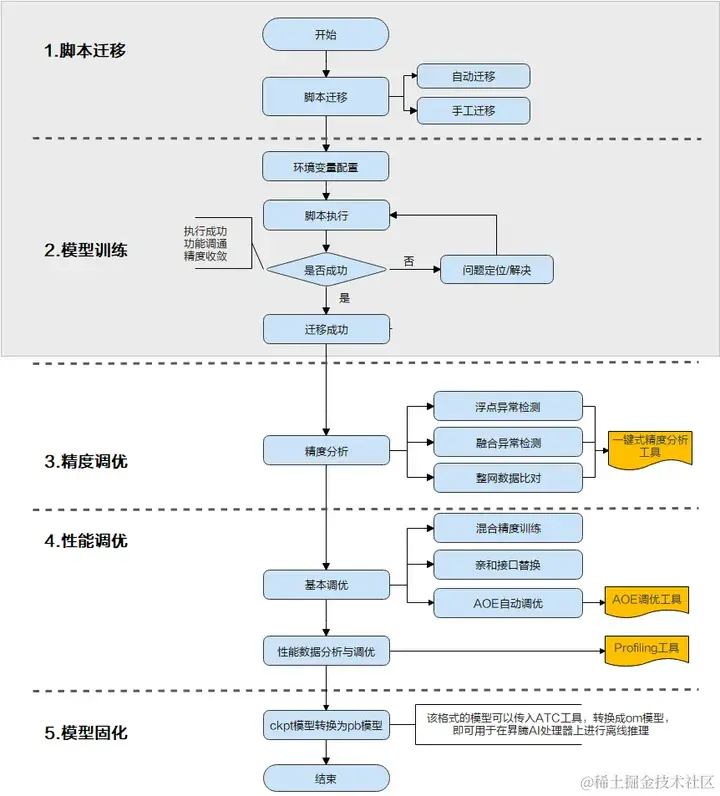
一文详解TensorFlow模型迁移及模型训练实操步骤
当前业界很多训练脚本是基于TensorFlow的Python API进行开发的,默认运行在CPU/GPU/TPU上,为了使这些脚本能够利用昇腾AI处理器的强大算力执行训练,需要对TensorFlow的训练脚本进行迁移。