java并发读取相同的文件_高效读取大文件,再也不用担心 OOM 了!
最近阿粉接到一个需求,需要从文件读取数据,然后经过业务处理之后存储到数据库中。这个需求,说实话不是很难,阿粉很快完成了第一个版本。

内存读取
第一个版本,阿粉采用内存读取的方式,所有的数据首先读读取到内存中,程序代码如下:
Stopwatch stopwatch = Stopwatch.createStarted();
// 将全部行数读取的内存中
List lines = FileUtils.readLines(new File("temp/test.txt"), Charset.defaultCharset());
for(String line : lines) {
// pass
}
stopwatch.stop();
System.out.println("read all lines spend "+ stopwatch.elapsed(TimeUnit.SECONDS) +" s");
// 计算内存占用
logMemory();
logMemory方法如下:
MemoryMXBean memoryMXBean = ManagementFactory.getMemoryMXBean();
//堆内存使用情况
MemoryUsage memoryUsage = memoryMXBean.getHeapMemoryUsage();
//初始的总内存
long totalMemorySize = memoryUsage.getInit();
//已使用的内存
long usedMemorySize = memoryUsage.getUsed();
System.out.println("Total Memory: "+ totalMemorySize / (1024 * 1024) +" Mb");
System.out.println("Free Memory: "+ usedMemorySize / (1024 * 1024) +" Mb");
上述程序中,阿粉使用 Apache Common-Io 开源第三方库,FileUtils#readLines将会把文件中所有内容,全部读取到内存中。
这个程序简单测试并没有什么问题,但是等拿到真正的数据文件,运行程序,很快程序发生了 OOM。
之所以会发生 OOM,主要原因是因为这个数据文件太大。假设上面测试文件 test.txt总共有 200W 行数据,文件大小为:740MB。
通过上述程序读取到内存之后,在我的电脑上内存占用情况如下:
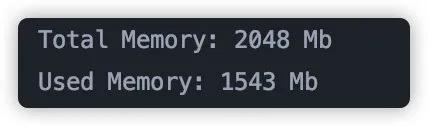
可以看到一个实际大小为 700 多 M 的文件,读到内存中占用内存量为 1.5G 之多。而我之前的程序,虚拟机设置内存大小只有 1G,所以程序发生了 OOM。
当然这里最简单的办法就是加内存呗,将虚拟机内存设置到 2G,甚至更多。不过机器内存始终有限,如果文件更大,还是没有办法全部都加载到内存。
不过仔细一想真的需要将全部数据一次性加载到内存中?
很显然,不需要!
在上述的场景中,我们将数据到加载内存中,最后不还是一条条处理数据。
所以下面我们将读取方式修改成逐行读取。
逐行读取
逐行读取的方式比较多,这里阿粉主要介绍两种方式:
BufferReader
Apache Commons IO
Java8 stream
BufferReader
我们可以使用 BufferReader#readLine 逐行读取数据。
try (BufferedReader fileBufferReader = new BufferedReader(new FileReader("temp/test.txt"))) {
String fileLineContent;
while ((fileLineContent = fileBufferReader.readLine()) != null) {
// process the line.
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
Apache Commons IOCommon-IO
中有一个方法 FileUtils#lineIterator可以实现逐行读取方式,使用代码如下:
Stopwatch stopwatch = Stopwatch.createStarted();
LineIterator fileContents = FileUtils.lineIterator(new File("temp/test.txt"), StandardCharsets.UTF_8.name());
while (fileContents.hasNext()) {
fileContents.nextLine();
// pass
}
logMemory();
fileContents.close();
stopwatch.stop();
System.out.println("read all lines spend "+ stopwatch.elapsed(TimeUnit.SECONDS) +" s");
这个方法返回一个迭代器,每次我们都可以获取的一行数据。
其实我们查看代码,其实可以发现 FileUtils#lineIterator,其实用的就是 BufferReader,感兴趣的同学可以自己查看一下源码。
由于公号内无法插入外链,关注『Java极客技术』,回复『20200610』 获取源码
Java8 stream
Java8 Files 类新增了一个 lines,可以返回 Stream我们可以逐行处理数据。
Stopwatch stopwatch = Stopwatch.createStarted();
// lines(Path path, Charset cs)
try (Stream inputStream = Files.lines(Paths.get("temp/test.txt"), StandardCharsets.UTF_8)) {
inputStream
.filter(str -> str.length() > 5)// 过滤数据
.forEach(o -> {
// pass do sample logic
});
}
logMemory();
stopwatch.stop();
System.out.println("read all lines spend "+ stopwatch.elapsed(TimeUnit.SECONDS) +" s");
使用这个方法有个好处在于,我们可以方便使用 Stream 链式操作,做一些过滤操作。
注意:这里我们使用 try-with-resources 方式,可以安全的确保读取结束,流可以被安全的关闭。
并发读取
逐行的读取的方式,解决我们 OOM 的问题。不过如果数据很多,我们这样一行行处理,需要花费很多时间。
上述的方式,只有一个线程在处理数据,那其实我们可以多来几个线程,增加并行度。
下面在上面的基础上,阿粉就抛砖引玉,介绍下阿粉自己比较常用两种并行处理方式。
逐行批次打包
第一种方式,先逐行读取数据,加载到内存中,等到积累一定数据之后,然后再交给线程池异步处理。
@SneakyThrows
publicstaticvoid readInApacheIOWithThreadPool() {
// 创建一个 最大线程数为 10,队列最大数为 100 的线程池
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(10, 10, 60l, TimeUnit.SECONDS, new LinkedBlockingDeque<>(100));
// 使用 Apache 的方式逐行读取数据
LineIterator fileContents = FileUtils.lineIterator(new File("temp/test.txt"), StandardCharsets.UTF_8.name());
List lines = Lists.newArrayList();
while (fileContents.hasNext()) {
String nextLine = fileContents.nextLine();
lines.add(nextLine);
// 读取到十万的时候
if (lines.size() == 100000) {
// 拆分成两个 50000 ,交给异步线程处理
List> partition = Lists.partition(lines, 50000);
List futureList = Lists.newArrayList();
for(List strings : partition) {
Future> future = threadPoolExecutor.submit(() -> {
processTask(strings);
});
futureList.add(future);
}
// 等待两个线程将任务执行结束之后,再次读取数据。这样的目的防止,任务过多,加载的数据过多,导致 OOM
for(Future future : futureList) {
// 等待执行结束
future.get();
}
// 清除内容
lines.clear();
}
}
// lines 若还有剩余,继续执行结束
if (!lines.isEmpty()) {
// 继续执行
processTask(lines);
}
threadPoolExecutor.shutdown();
}
private staticvoid processTask(List strings) {
for(String line : strings) {
// 模拟业务执行
try {
TimeUnit.MILLISECONDS.sleep(10L);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
上述方法,等到内存的数据到达 10000 的时候,拆封两个任务交给异步线程执行,每个任务分别处理 50000 行数据。
后续使用 future#get(),等待异步线程执行完成之后,主线程才能继续读取数据。
之所以这么做,主要原因是因为,线程池的任务过多,再次导致 OOM 的问题。
大文件拆分成小文件第二种方式,首先我们将一个大文件拆分成几个小文件,然后使用多个异步线程分别逐行处理数据。
publicstaticvoid splitFileAndRead() throws Exception {
// 先将大文件拆分成小文件
List fileList = splitLargeFile("temp/test.txt");
// 创建一个 最大线程数为 10,队列最大数为 100 的线程池
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(10, 10, 60l, TimeUnit.SECONDS, new LinkedBlockingDeque<>(100));
List futureList = Lists.newArrayList();
for(File file : fileList) {
Future> future = threadPoolExecutor.submit(() -> {
try (Stream inputStream = Files.lines(file.toPath(), StandardCharsets.UTF_8)) {
inputStream.forEach(o -> {
// 模拟执行业务
try {
TimeUnit.MILLISECONDS.sleep(10L);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
} catch (IOException e) {
e.printStackTrace();
}
});
futureList.add(future);
}
for(Future future : futureList) {
// 等待所有任务执行结束
future.get();
}
threadPoolExecutor.shutdown();
}
private staticList splitLargeFile(String largeFileName) throws IOException {
LineIterator fileContents = FileUtils.lineIterator(new File(largeFileName), StandardCharsets.UTF_8.name());
List lines = Lists.newArrayList();
// 文件序号
intnum = 1;
List files = Lists.newArrayList();
while (fileContents.hasNext()) {
String nextLine = fileContents.nextLine();
lines.add(nextLine);
// 每个文件 10w 行数据
if (lines.size() == 100000) {
createSmallFile(lines, num, files);
num++;
}
}
// lines 若还有剩余,继续执行结束
if (!lines.isEmpty()) {
// 继续执行
createSmallFile(lines, num, files);
}
returnfiles;
}
上述方法,首先将一个大文件拆分成多个保存 10W 行的数据的小文件,然后再将小文件交给线程池异步处理。
由于这里的异步线程每次都是逐行从小文件的读取数据,所以这种方式不用像上面方法一样担心 OOM 的问题。
另外,上述我们使用 Java 代码,将大文件拆分成小文件。这里阿粉还有一个简单的办法,我们可以直接使用下述命令,直接将大文件拆分成小文件:
# 将大文件拆分成 100000 的小文件
split -l 100000 test.txt
后续 Java 代码只需要直接读取小文件即可。
总结当我们从文件读取数据时,如果文件不是很大,我们可以考虑一次性读取到内存中,然后快速处理。
如果文件过大,我们就没办法一次性加载到内存中,所以我们需要考虑逐行读取,然后处理数据。但是单线程处理数据毕竟有限,所以我们考虑使用多线程,加快处理数据。
本篇文章我们只是简单介绍了下,数据从文件读取几种方式。数据读取之后,我们肯定还需要处理,然后最后会存储到数据库中或者输出到另一个文件中。
这个过程,说实话比较麻烦,因为我们的数据源文件,可能是 txt,也可能是 excel,这样我们就需要增加多种读取方法。同样的,当数据处理完成之后,也有同样的问题。
不过好在,上述的问题我们可以使用 Spring Batch 完美解决。
【编辑推荐】
【责任编辑:武晓燕 TEL:(010)68476606】
点赞 0
相关文章:

Cmake 实例学习 一
一. 第一个简单的例子 在一个目录下面实现一个简单的 hello world 程序 使用cmake进行构建的时候,每个目录下面都要有一个 CMakeLists.txt 的文件 如果是一个稍微大的工程,有多级目录,在上级目录中的 CMakeLists.txt 中会有定义要求编译子目…
ORA-19502: write error on file xxxxx, block number xxxx
错误现象: 在ORACLE 10g下为表空间IGNITE_EGVSQL01增加数据文件时,报如下错误: SQL> ALTER TABLESPACE IGNITE_EGVSQL01 ADD DATAFILE /oradata/ignt/ignite_egvsql01_d02.dbf SIZE 4096M AUTOEXTEND OFF; ERROR at line 1: O…

关于Jfinal的分享代码托管GitHub
为什么80%的码农都做不了架构师?>>> Blog中所有的代码已经托管到github. https://github.com/b1412 此blog中关于Jfinal的代码分享不再维护。有兴趣的朋友可以关注我的github。 大家都贡献和分享一点,让jfinal发展的更好~ 转载于:https:…
软件发布版本的业界规则?
文章:8天学通MongoDB——第一天 基础入门 今天看到一篇文章说:业界规则,偶数为“稳定版”(如:1.6.X,1.8.X),奇数为“开发版”(如:1.7.X,1.9.X)&am…
CMake学习资料
CMake 官方 FAQ https://gitlab.kitware.com/cmake/community/wikis/FAQ CMake 官方文档 https://cmake.org/cmake/help/cmake2.4docs.html CMake 视频教程 https://www.youtube.com/watch?vCLvZTyji_Uw CMake 维基教科书 https://zh.wikibooks.org/w/index.php?titleCMake_入…
MySQL rpm包 二进制区别_Linux环境下安装mysql5.6(二进制包不是rpm格式)
一.准备:1.CentOS release 6.82.mysql-5.6.31-linux-glibc2.5-x86_64.tar.gz3.Linux下MySQL5.6与MySQL5.7安装方法略有不同二.卸载原有的mysqlfind / -name mysqlrm -rf 上边查找到的路径,多个路径用空格隔开三.在安装包存放目录下执行命令解压文件tar -zxvf mysql-…
【心情】 轻装前行
为自己做一份总结吧,从毕业到现在~ 时间过得不快不慢,从毕业到现在挣扎着已经2年多了,2年多经历的了很多事情。 毕业回国不到一个礼拜,就跑到大连工作,一个造船厂,公司在长兴岛开发区,岛上几万人…
Android 马甲包制作流程
一、马甲包的制作流程 1.配置马甲包的applicationId以及应用名称 在app的build.gradle文件中添加马甲包的配置 android {signingConfigs {config {keyAlias ****keyPassword ****storeFile file(D:/qianming/****.jks)storePassword ****}}compileSdkVersion 25buildToolsVersi…
Cmake 交叉编译
转载自 http://zhixinliu.com/2016/02/01/2016-02-01-cmake-cross-compile/ CMake交叉编译 CMake的使用,以及如何将一个项目移植到Android。 CMake的用法 先让我们简单学习回顾一下cmake的基本知识: 基本流程 以linux平台为例,使用 CMak…
利用System.Uri转URL为绝对地址
在使用ASPOSE.Word生成Word文档时可以通过InsertHtml(html)来将图文信息写入Word文档(图片内嵌),但要求html里图片的src是绝对全路径,所以需要对html进行转化。 获取html可以来自数据库数据或者通过网络抓取,得到之后使用System.Uri来进行替换…

idea上java接口自动化_Java接口自动化之IDEA创建及运行maven项目
本文2564字阅读约需7分钟第195次推送Maven作为一个项目管理工具,是一组标准集合,一个项目的生命周期、一个依赖管理系统,以下主要介绍IDEA创建及运行maven项目。01创建maven项目①打开IDEA,顶部菜单栏依次选择File-->New-->…

.NET面向上下文、AOP架构模式(实现)
.NET面向上下文、AOP架构模式(实现) 1.上下文Context、面向切面编程AOP模型分析 在本人的.NET面向上下文、AOP架构模式(概述)一文中,我们大概了解了上下文如何辅助对象在运行时的管理。在很多时候我们急需在运行时能把…
英语之弱元音Schwa
IELTS Speaking - 学会英语Schwa弱元音,你的口语也将充满英伦味 https://baijiahao.baidu.com/s?id1596905156544848616&wfrspider&forpc http://blog.sina.com.cn/s/blog_95e5f8a601017jr4.html https://www.guokr.com/blog/440820/ 打傻方进 百家号04-05…
工厂方法模式和抽象工厂模式
工厂方法模式和抽象工厂模式工厂方法模式抽象工厂模式总结:工厂方法模式 #include <string> #include <iostream>// Abstract class Splitter { private:/* data */ public:Splitter(/* args */);virtual ~Splitter(); public:virtual void split() 0; };Splitte…
关于JQuery中的ajax请求或者post请求的回调方法中的操作执行或者变量修改没反映的问题...
前段时间做一个项目,而项目中所有的请求都要用jquery 中的ajax请求或者post请求,但是开始处理一些简单操作还好,但是自己写了一些验证就出现问题了,比如表单提交的时候,要验证帐号的唯一性,所以要在submit前…

下列关于Java多线程并发控制_下列关于Java多线程并发控制机制的叙述中,错误的是...
下列叙述成都望江楼的造景手法有()。竹文化景观应体现科学性与艺术性的和谐统一,关于既要满足植物的生态习性,又能体现美学价值。在中国传统的审美趣味、多线伦理道德上,竹在造园中被拟人化为( )的代表。程并错误下列不属于竹文化旅游的发展趋…
一.vtun源码学习笔记
1.守护进程 (1)守护进程简介 守护进程,也就是我们通常所说的Daemon进程。它是一个生存期较长的进程,它通常独立于控制终端并且周期性的执行某种任务或等待处理某些发生的事件。 它与普通进程相比有下面这些特殊性:守护进程最重要的…
获取data 数据
export function getData(el, name, val) {const prefix data-if (val) {return el.setAttribute(prefix name, val)}return el.getAttribute(prefix name) } 转载于:https://www.cnblogs.com/hss-blog/p/9781816.html
java jwks_Java SpringBoot 如何使用 IdentityServer4 作为验证服务器学习笔记
这边记录下如何使用IdentityServer4 作为 Java SpringBoot 的 认证服务器和令牌颁发服务器。本人也是新手,所以理解不足的地方请多多指教。另外由于真的很久没有写中文了,用词不太恰当的地方也欢迎新手大佬小伙伴指出,一起进步。另外这边令牌…
git 快速复制一个新项目
gitlab创建项目a及一个主分支master 本地整体复制已有项目b 本地克隆gitlab上新创建的项目a(git clone gitlab地址) 将本地克隆过来的a文件夹下的.git目录拷贝到b项目下(cp -r .git …/b,注意是两个点,不是三个点,写两…
微信公众平台消息接口星标功能
【微信公众平台星标功能接口被撤销】微信公众平台消息接口中的星标功能,被悄悄的去掉了。 原因应该是有的账号在程序中大量使用星标功能,造成微信服务器存储记录过于宠大。 现在要继续使用星标功能,只能在后台手工操作。 <xml> <ToU…

国庆双节长假旅游出行必装的手机软件
长假即将来临,如果打算出去溜达溜达,透透气的朋友,本文可千万别错过了。今天将介绍几款应用是旅途中绝对不能缺少的,这些应用都非常好用、功能全面,是出行必备的手机软件,希望可以伴你度过快乐的十一长假。…

Windbg双机调试环境配置(Windows7/Windows XP+VirtualBox/VMware+WDK7600)
简介:Windbg双机调试内核、驱动 下载软件: 下载Windbg(GRMWDK_EN_7600_1.ISO)下载VirtualBox 5.2/VMware 12一、安装WDK,这里要提一点的是Debugging Tools for Windows一定要打勾,因为我们后面就是要通过这个工具来进行双机调试的…
哈夫曼树的java实现_java实现哈夫曼树
哈夫曼译码,就是将输入的译码还原成对应的字符。 抽象的算法描述:将建立哈夫曼树、实现哈夫曼编码、哈夫曼译码都定义成 子函数的的形式, 然后在主函数中调用它们......数据结构课程设计设计题目: 哈夫曼树及其应用学 院:计算机科学与技术 专业:网络...用哈夫曼树实现图像压缩_…
on-my-zsh git 仓库下运行卡顿
在 oh-my-zsh 进入 包含 git 仓库目录时,执行 ls 时会比较卡顿 原因: oh-my-zsh 要获取 git 更新信息 解决办法: 设置 oh-my-zsh 不读取文件变化信息(在 git 项目目录执行下列命令) $ git config --add oh-my-zsh…
oracle, group by, having, where
选择列表中如果包含有列、表达式时,这个列、表达式必须包含在Group By子句中。另外,如果采用了表达式的话,则数据库管理员即使在选择列表中采用了别名,但是在Group By子句中仍然必须采用表达式的完整表达方式,而不能够…

[转载] CSS模块化【封装-继承-多态】
第一次听到“CSS模块化”这个词是在WebReBuild的第四届“重构人生”年会上,当时我还想,“哈,CSS也有模块化,我没听错吧?”事实上,我没听错,你也没看错,早就有CSS模块化这个概念了。之…

用jQuery写的一个翻页,并封装为插件,
用jQuery写的一个翻页,并封装为插件, 1 *{2 margin:0;3 padding: 0;4 list-style: none;5 text-decoration: none;6 }7 .page{8 width:500px;9 margin:100px auto; 10 color: #ccc; 11 } 12 .page a{ 13 display: inlin…
Ubuntu 将 /home 或 /var 目录挂载到新的分区
背景 在使用 docker 的过程中,docker 会将某些产物放到 /var/lib/docker/volumes 这会占用很大的跟目录磁盘空间,于是想办法将 /var 目录挂载到另一个一个单独的磁盘上面。 参考链接如下:Ubuntu将var目录挂载到新硬盘 步骤 1. 查看当前磁…
php 500 内部服务器错误,php 500 - 内部服务器错误的解决方法
php 500 - 内部服务器错误的解决方法发布时间:2020-11-04 09:55:31来源:亿速云阅读:71作者:小新小编给大家分享一下php 500 - 内部服务器错误的解决方法,相信大部分人都还不怎么了解,因此分享这篇文章给大家…