Rocksdb 与 TitanDb 原理分析 及 性能对比测试
文章目录
- 前言
- Rocksdb的compaction机制
- compaction作用
- compaction分类
- level style compaction(rocksdb 默认进行的compaction策略)
- level 的文件存储结构
- compaction过程
- compaction中的level target size
- universal style compaction
- fifo style compaction
- Titan相比于rocksdb的核心优化
- key-value 存储优化
- key-value 区分逻辑
- 版本控制
- GC垃圾回收机制
- 编译和安装
- Rocksdb
- TitanDb
- 测试
- 使用rocksdb提供的接口编写测试代码
- 编译链接rocksdb和titandb 各自动态库,生成二进制文件
- 测试
- 参考资料
前言
本文主要针对非关系型数据库rocksdb以及在rocksdb基础上所做的一些优化的titandb做一个整体的介绍。
从他们编译,安装,测试以及titanDb相比于rocksdb优化的方面进行一个整体归纳总结。

Rocksdb的compaction机制
compaction作用
compaction作为rocksdb使用LSM tree管理核心key-value数据的一种合并策略,主要是为了保证LSM tree的c0,c1…cn tree不过于冗余,影响读性能。
关于LSM tree的介绍可以参考论文《The Log-Structured Merge-Tree (LSM-Tree)》
compaction分类
- level style compaction 按层级进行合并
- universal style compaction
- fifo style compaction
- none compaction
level style compaction(rocksdb 默认进行的compaction策略)
核心是 将数据分成互不重叠的一系列固定大小(例如 2 MB)的SSTable文件,再将其分层(level)管理。
level 的文件存储结构
- 数据通过内存写到作为buffer的L0中,再持久化到底层的L1-Ln
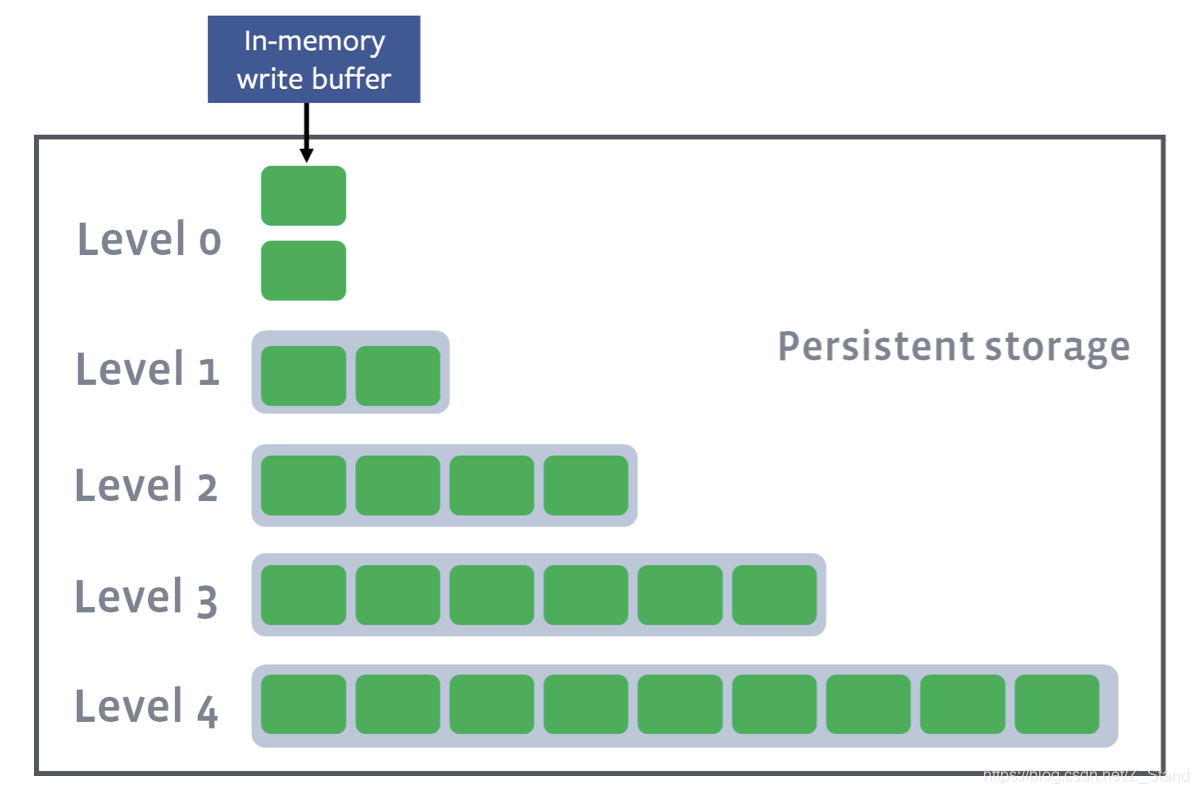
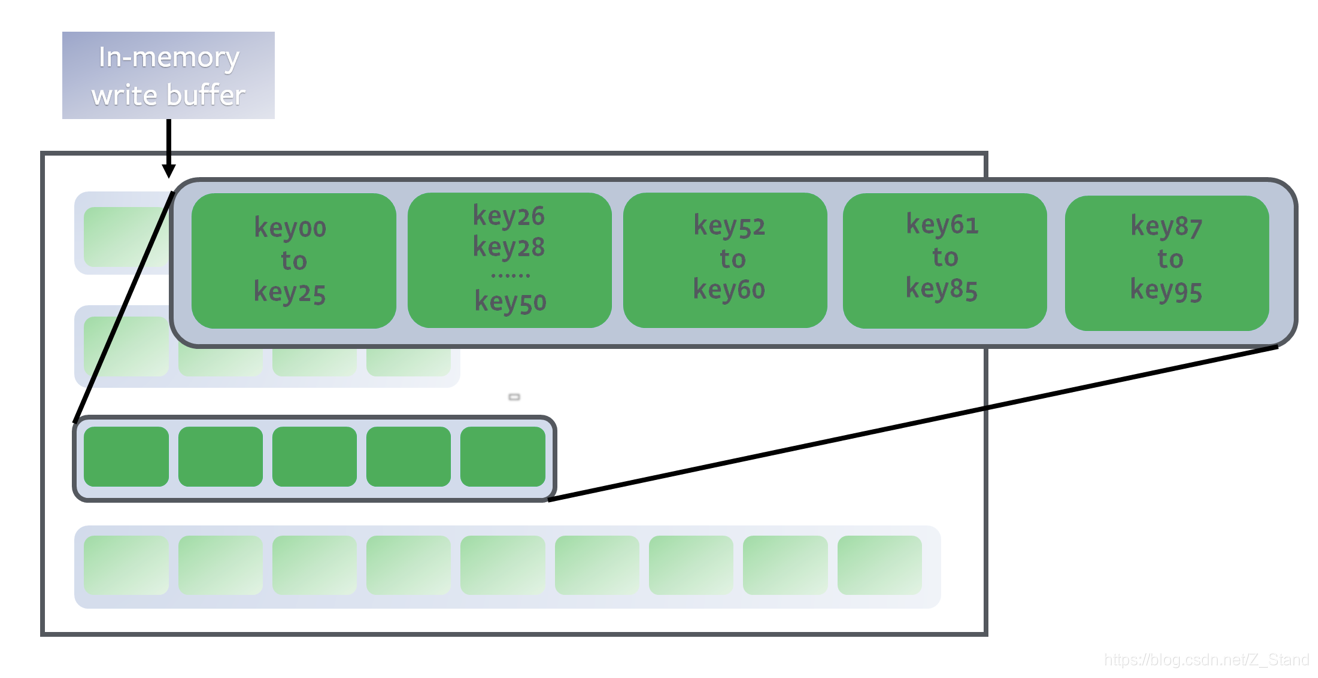
- 当需要确认key的位置时,通过二分查找确认key所处的文件,再去具体文件中查找。
该过程会遍历整个level集合
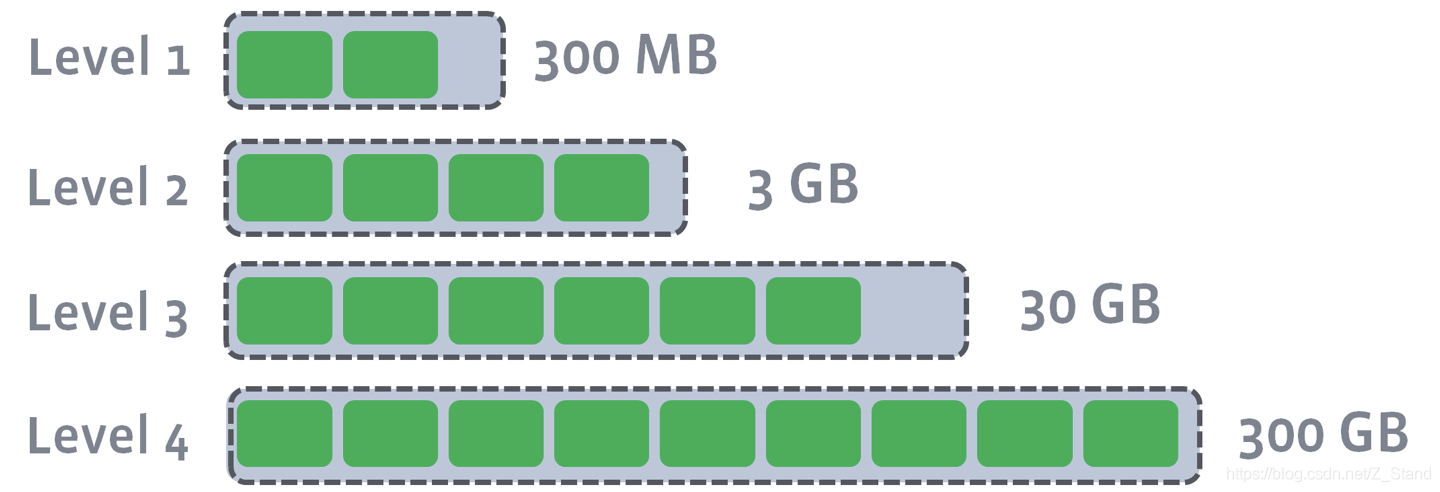
- 每一层level都有target size,compaction的目的是为了限制每一层数据,且每一层target的增加都是成倍增加
compaction过程
- 当level0的数据到达时,则会触发compaction(
level0_file_num_compaction_trigger表示L0的SST文件个数达到了触发参数)到L1。操作过程会将L0中的file pick出来,以防重叠
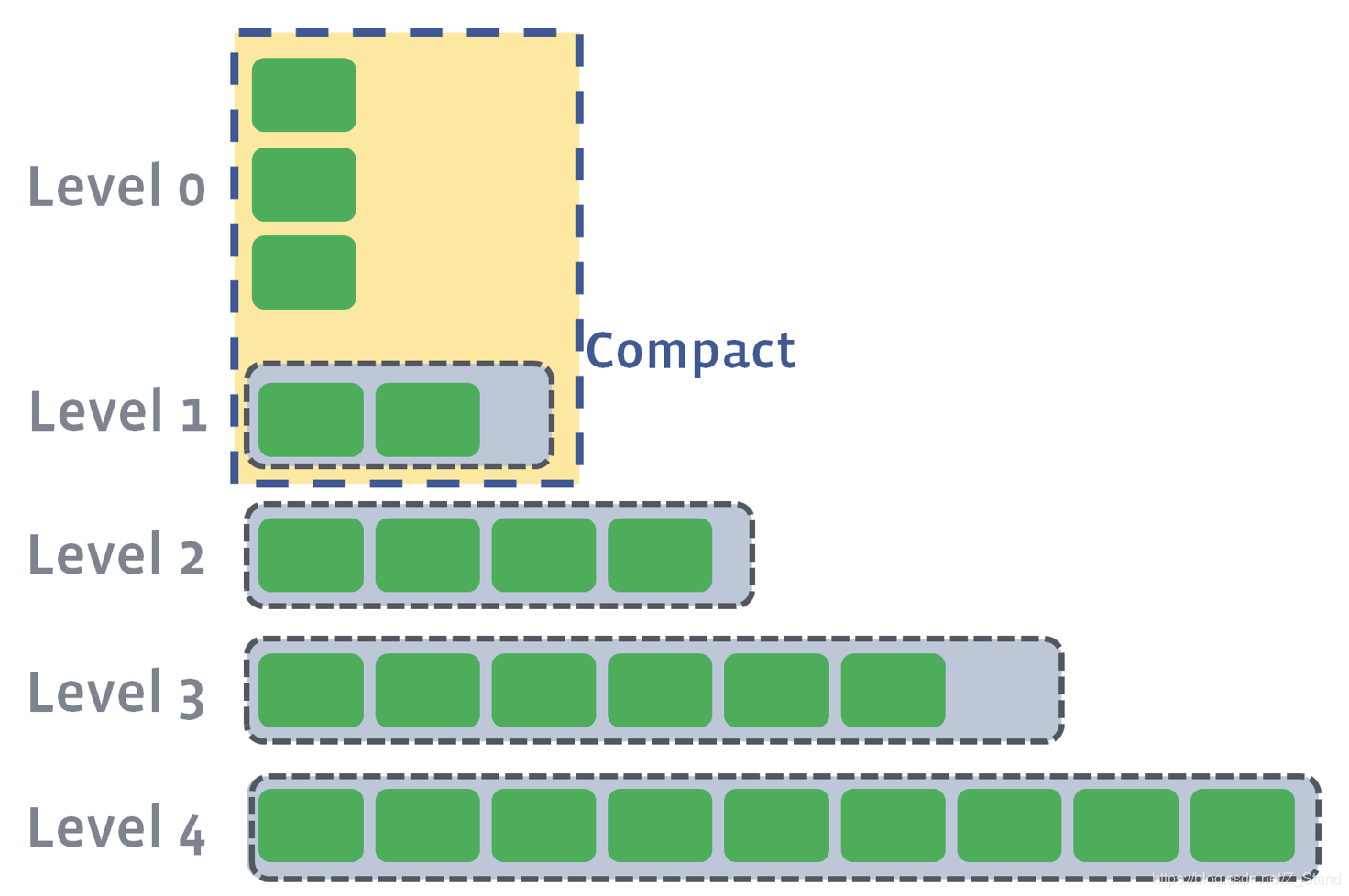
- 当持续从L0 compaction到L1时,L1可能会达到target size。此时会从L1中挑选至少1个file,并与L2中的file进行合并,重新写入L2中
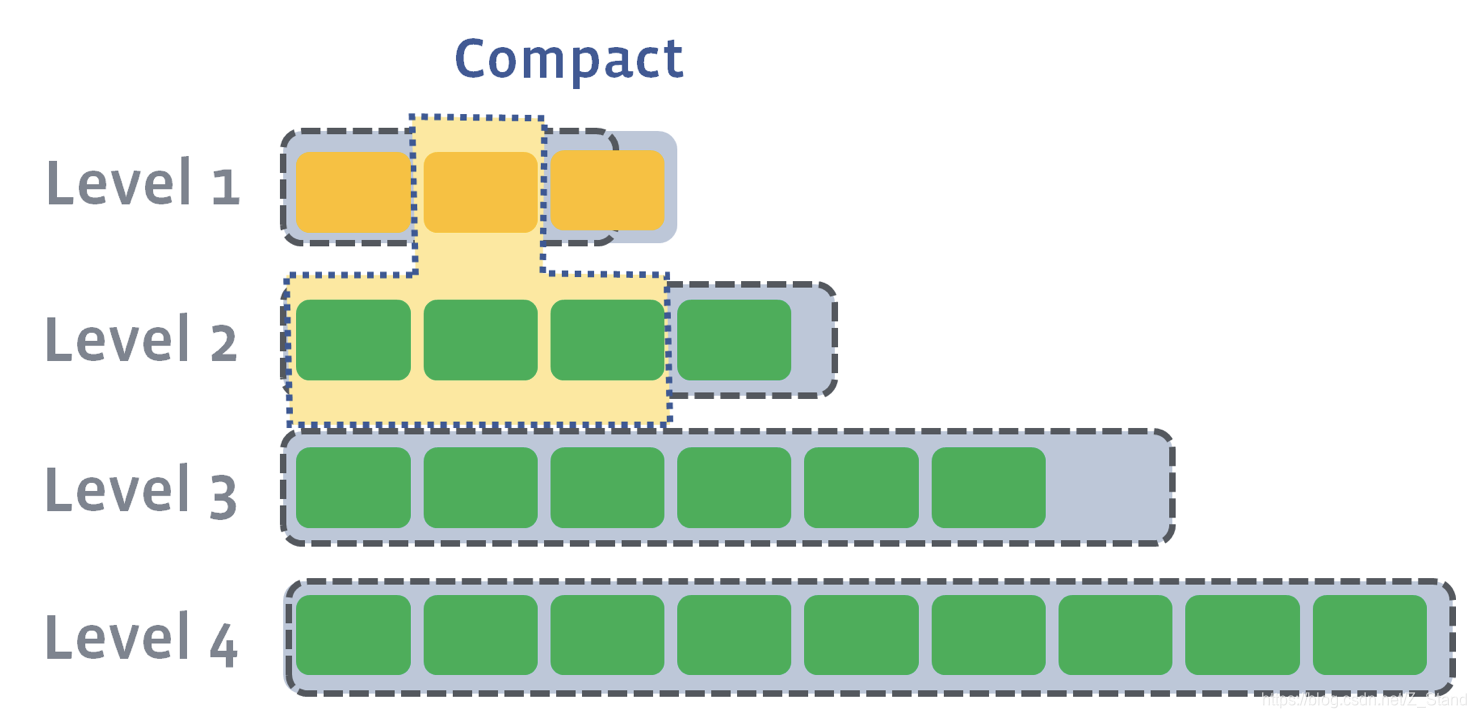
- 当L2也达到了 target size,则和之前一样进行file的合并,写入到L3
- 并发compaction,通过
max_background_compactions控制可以进行并发compaction的个数
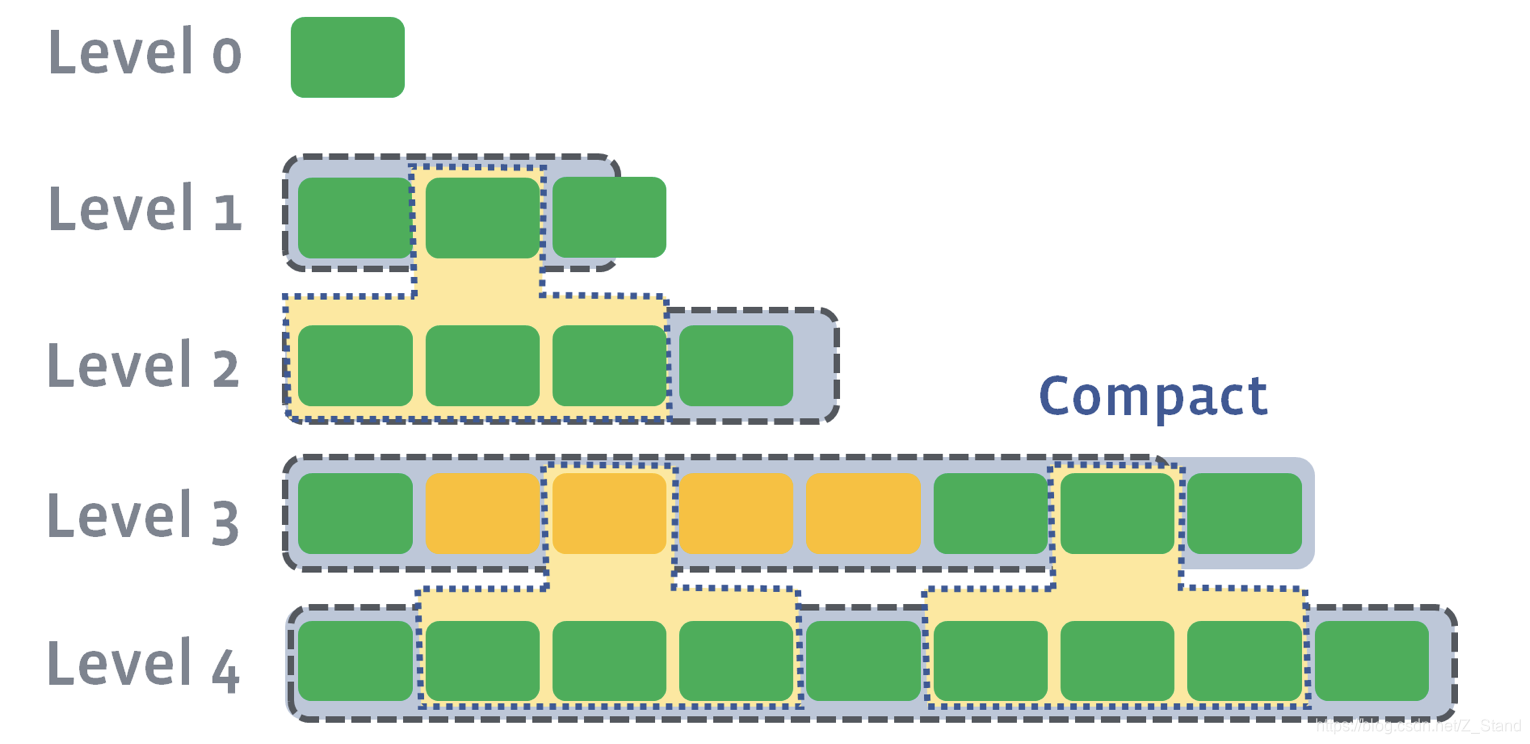
- L0 – L1 在并发compaction的层中,该问题可能会是compaction的性能瓶颈。
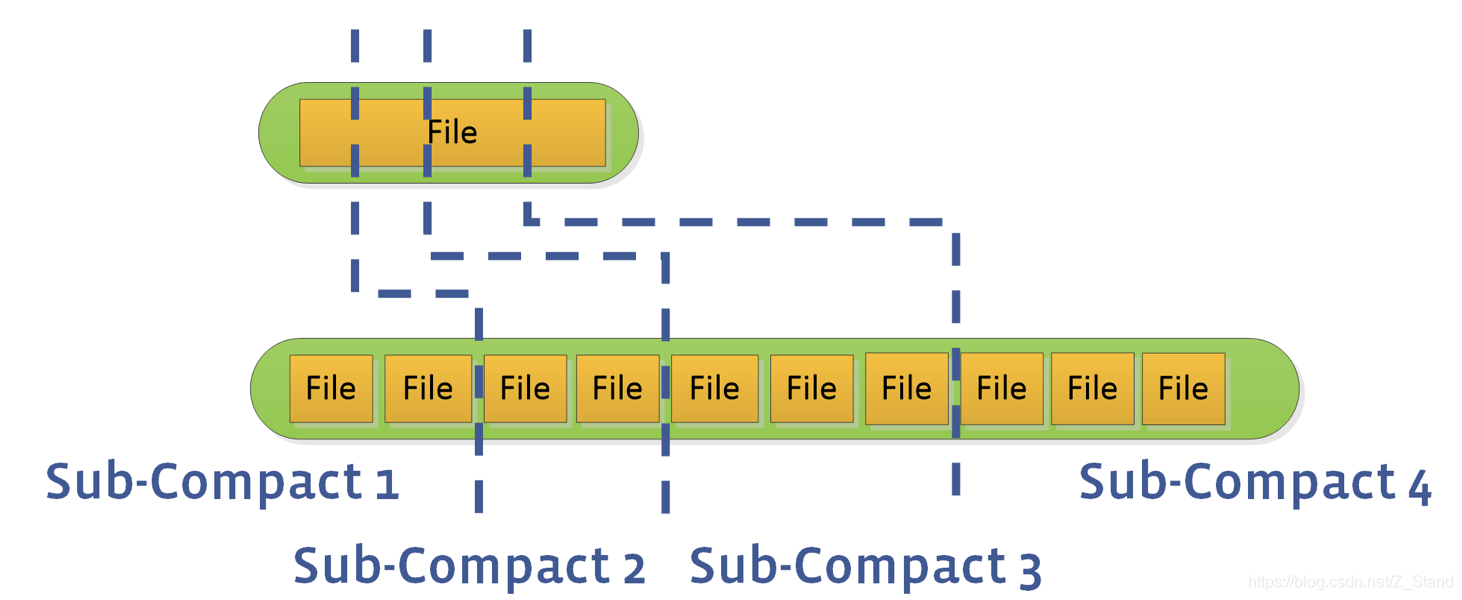
优化方式:通过设置max_subcompactions参数,来使用多线程方式分割 file range 进行并发compaction
compaction中的level target size
level_compaction_dynamic_level_bytes 来控制level target size的是固定还是可以动态进行调整的
level_compaction_dynamic_level_bytes = false则表示当rocksdb开始加载时,每一层的大小都一定固定了,且运行过程中不会发生变化。
eg: rocksdb初始化参数如下max_bytes_for_level_base = 268435456 level_compaction_dynamic_level_bytes = false max_bytes_for_level_multiplier = 10 num_levels = 3则最终的rocksdb每一层的大小为
以上配置下的各个层级targe size 为:
L1: 268435456
L2: 2684354560
L3: 26843545600level_compaction_dynamic_level_bytes = true则表示rocksdb每一层的level大小并不是固定的,而是可以动态进行变化的。
当前模式下每一层的level size的动态调整同样是基于QOS的思想,我们通过以上compaction的实现可以发现IO一定是通过level0 flush到底层的L1-LN,那么如果IO密集型业务下短时间内L0增长的sst文件急剧增加且远大于L1的大小,这个时候如果L1-LN的大小还是固定的,那么IO肯定就阻塞在了从L0-L1之间。
此时可以通过该参数让系统内部自动进行每一层的target size的调整:eg: 原来的L1 - L3: 1G,10G,100G
此时L0短时间内的SST文件及占用容量达到了3G,超过了L1 的1G,那么进行动态调整后(修改Level的相关配置参数)的L1-L3的大小变成了:3G,18G,108G
universal style compaction
核心实现同样是通过 读放大和空间放大 来降低写放大,universal comapction
- 每当某个尺寸的SSTable数量达到既定个数时,合并成一个大的SSTable
- 通过读放大和空间放大(合并时的临时数据结构占用空间较大)来最小化写放大
这种方式的读放大和空间放大较为严重,虽然写放大在一定程度上得到了缓解(同一个sst文件并不会产生多次写入),但这并不是一个可以代替level方式的策略。
fifo style compaction
fifo style compaction当文件过时时,优先压缩最老的文件,有点像cahce中数据的过滤。
所有的SST文件 都先存储在L0中,当L0中的文件总大小超过了CompactionOptionsFIFO::max_table_files_size,则会选择最老的文件进行删除,所以它的key-value的数据从来不会复写,也就是写放大系数一直都是1。
当然这种方式有一个非常严重的问题是:核心key-value数据的删除不会告知给用户!!
这可严重影响系统 的可靠性啊。
Titan相比于rocksdb的核心优化
通过对Rocksdb的compaction过程的分析,我们发现rocksdb默认使用的level 策略存在写放大的情况,且在正常IO的时候compaction是在后台进行的,这个时候显然compaction和上层IO产生竞争,从而影响整体的rocksdb写性能。
此时Titan借助论文wisckey提出的key-value分离存储的思想进行了一系列相关的优化。
具体的优化方面如下几个方面:
key-value 存储优化
如下图为titan中写请求阐述的数据存放方式
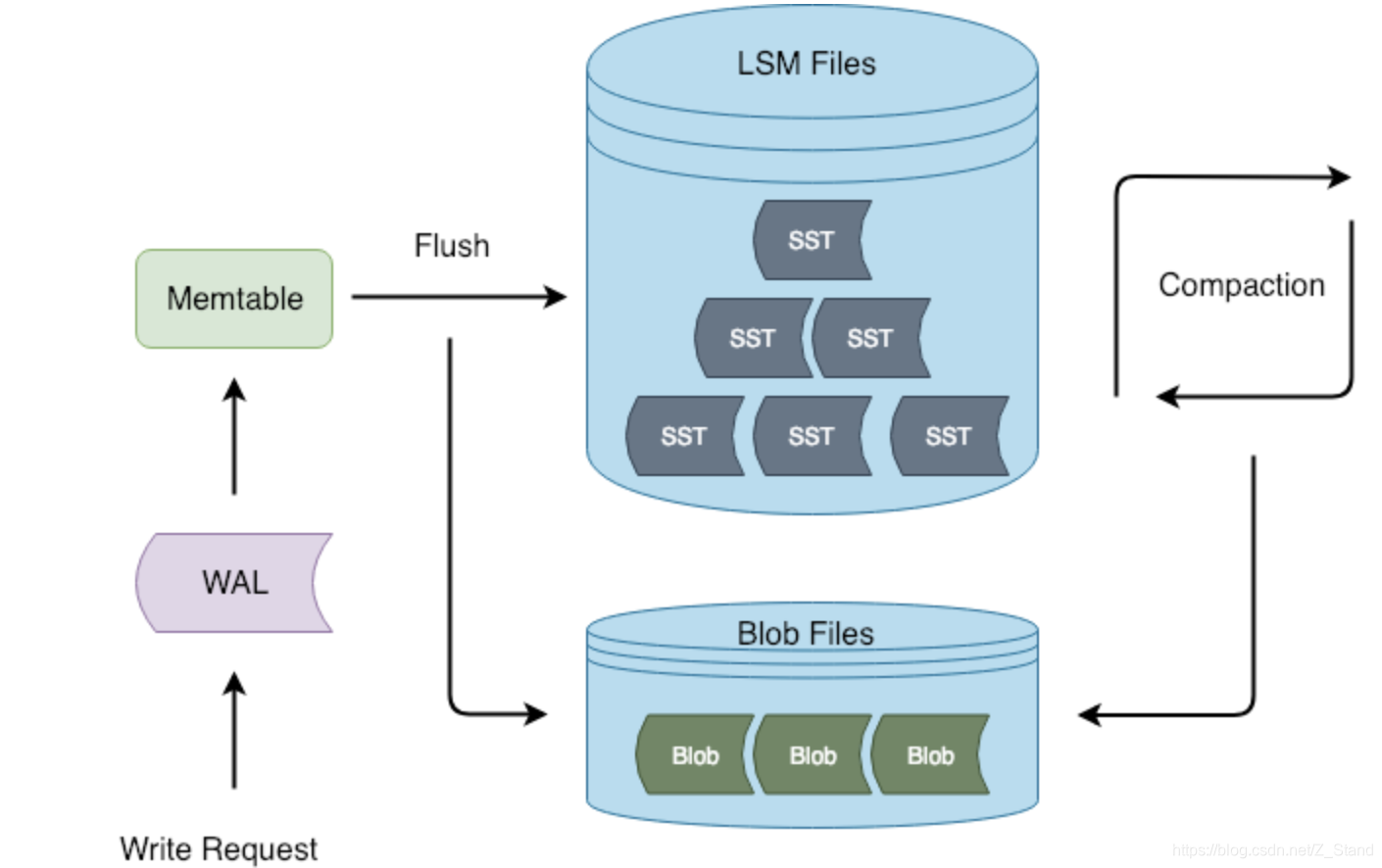
在LSM管理的SST文件之下多了一种blob结构,用来存储value数据,具体的blobfile结构如下

其中:
- blob record 有序得保存了key-value的键值对,且key是从sst中进行的一份拷贝,用来和保存和value的映射,方便后续进行过时key的垃圾回收, 所以这里的存储存在一些写放大。不过,key本身数据量比较小,并不会有太激烈的IO资源竞争。
- meta block主要是为了可扩展性,来存储了当前blobfile的一些属性信息。
- meta index则主要是记录metablock的索引信息,方便快速查找meta block。
key-value 区分逻辑
传统的rocksdb在进行创建sorted string table(SST)文件的时候也是通过工厂函数模式进行table文件的实例化,这里titan也是借用该设计模式进行 key-value的分离实现,逻辑实现如下:
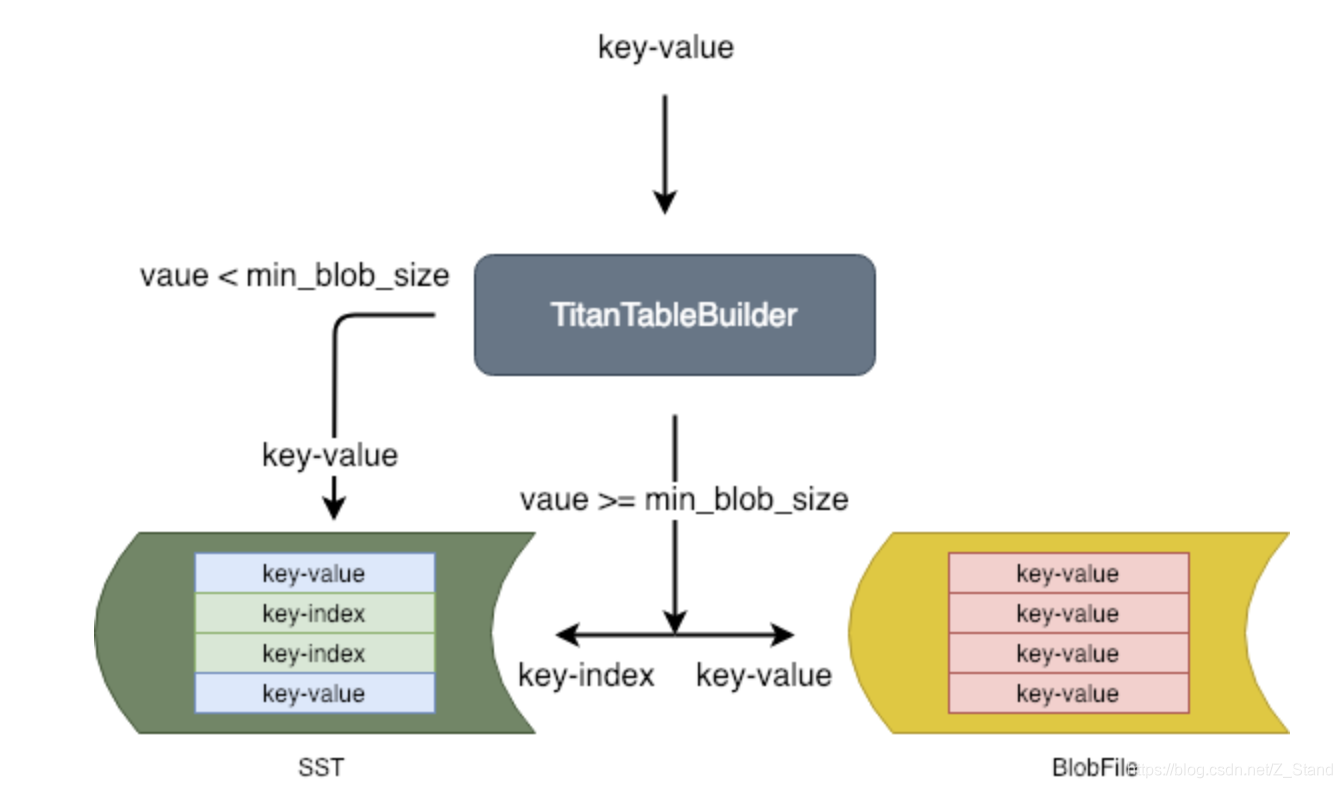
- 当value-size >= min_blob_size的时候,将整个key-value存放在blobfile之中,同时创建一个key-index的结构,存放在SST中,用来索引该key-value
- 反之,将整个key-value 存放在SST文件中
版本控制
因为多了一种数据结构,那么在分布式存储系统中,即要保证在上层应用并发add或者delete的时候仍然能够对外提供一致性的访问服务。此时,blob file也要加入到系统的版本控制中,这里主要用的是Multi-version Concurrency Control (MVCC)多版本控制的思想。

通过头尾相对的双向链表进行版本文件的管理,同时设置一个versionSet的数据结构来管理所有的文件,同时增加一个current指针,一直指向最新的version版本。通过这种版本控制的方式,达到不需要对文件加锁,即可在并发add/delete的时候对外提供一致性服务。
GC垃圾回收机制
titan的GC机制主要有两个功能进行协助:
- BlobFileSizeCollector
这是一种属性收集器,用来从对应的SST文件中SST属性信息,最后收集到的属性集叫做BlobFileSizeProperties。
收集前的表格和收集后的BlobFileSizeProperties表格如下:
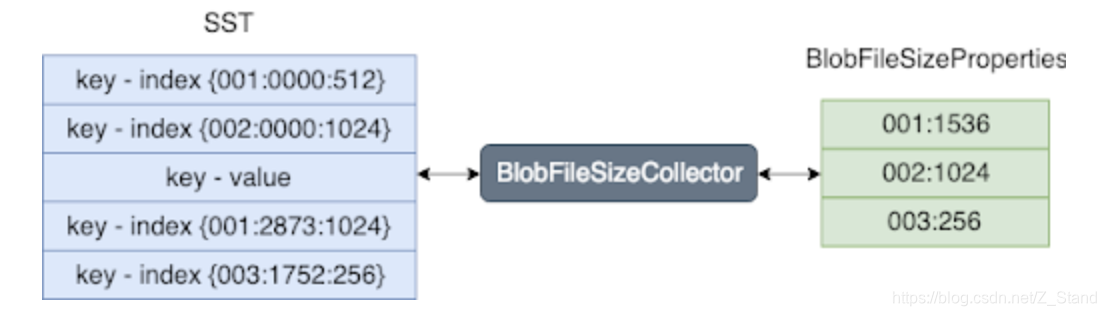
对于SST的表格内容(大括号里面的内容):第一列表示blob file ID ,第二列表示blob record在blob file中的偏移地址,第三列表示blob record的大小。
对于BlobFileSizeProperties表格内容如下:第一列表示blob fileID,第二列表示数据的大小。 - EventListener
在compaction的时候,rocksdb本身会丢掉一部分旧数据来释放空间。同样,在titandb中,compaction之后,titan中的部分blobfile存储的数据可能已经过时。此时,titan通过监控compaction的事件来触发自身的GC机制。
这里GC做的内容是,通过对比compaction输入,输出前后的BlobFileSizeProperties表格内容变化的情况,来决定哪一些数据可以进行丢弃。过程如下:
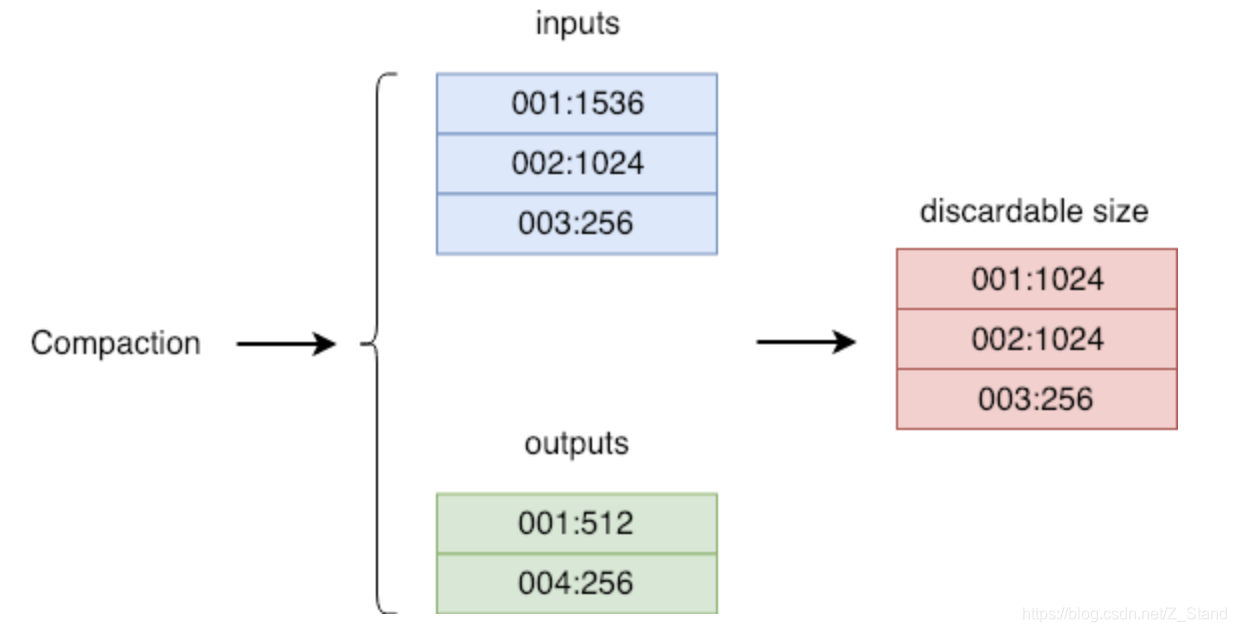
可以发现输入输出前后:
blobfile 1: 从size-1536变为了size:512,那么表示blobfile1可以丢弃1024大小的内容
blobfile 2: 从size-1024 变成了没有输出,那么表示blobfile2可以完全丢弃
blobfile 3: 同blobfile2,也可以完全丢弃
对于每一个有效的blobfile,titan会在内存中维护一个有效的变量来记录当前blob file可丢弃的大小。当进行compaction的时候,变量会随着相应的blobfile的变化进行累加(以上event listener)。当GC开始的时候,会从累计的blobfile可丢弃的变量中挑选一个最大的blobfile最为可丢弃的候选人。
为了降低写放大,titan尽可能减少GC所造成的IO,使用可控的配置来控制GC的写放大,当blobfile挑选出来作为可丢弃的候选者的时候需要满足一定的大小才能够真正被丢弃。
这里使用的GC实现算法入下:
- 从blobfile中随机选取一部分数据A,起其size 为a
- 遍历A中所有的key, 使用d 来累加所有过时的key所代表的blob record(我们上面说过blobfile的结构,blob reocord代表的是key 对应的data的大小)
- 计算比例 r = d / a,如果r >= discardable_ratio,即认为当前过时的key已经超过了一定的比例,那么就在对应的blobfile上进行GC,否则不进行GC。
综上为titanDb在rocksdb基础之上所做的一些优化以及优化产生的周边开发。显然,key-value的分离存储和管理是核心优化点,解决了rocksdb 原生compaction带来的大量的value写放大问题。
且通过后续对应的测试,也确实发现了big value场景下,写性能确实有2-3倍的优化提升。
后续将深入titan的核心实现,详细分析研究titan的实现逻辑,从而应用到现有的业务上。
编译和安装
Rocksdb
基本变异过程可以参考官方给的安装步骤,不过坑比较多,可以将一下步骤和官方给的步骤结合起来看。
- 确认系统编译器版本
gcc -v,建议版本在gcc 4.8.5以上,否则变异出来最新的代码会缺少一些glibc的属性信息。
这里如果发现系统gcc版本确实比较低,可以下载gcc较高版本编译安装一下,我这里选择的是gcc 5.3,详细可以参考gcc编译安装这里需要注意:
- 如果个人不想安装的gcc在系统默认的目录下,且gcc版本变更为可配置的,可以在gcc源码生成makefile的那一步进行安装的路径指定(否则系统默认会安装到/usr/local下):
./configure --prefix=/xxxx - 当GCC 编译安装在指定的目录之后可以可以通过系统变量加载glibc库和我们编译好的gcc版本
修改当前用户的.bashrc文件(root用户的在/etc/.bashrc,个人用户直接编辑~/.bashrc)
增加如下内容:
export CC=/xxx/gcc-5.3/bin/gcc#makefile中的gcc的路径
export CXX=/xxx/gcc-5.3/bin/g++#makefile中的g++路径
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/xxx/gcc-5.3/lib64#指定glibc的库,使用当前版本编译器的库
- 如果个人不想安装的gcc在系统默认的目录下,且gcc版本变更为可配置的,可以在gcc源码生成makefile的那一步进行安装的路径指定(否则系统默认会安装到/usr/local下):
gflags安装,gflags是谷歌提供的一些第三方库,这里rocksdb部分功能需要使用到。
该步骤的安装可以参考:gflags安装a. git clone https://github.com/gflags/gflags.git b. cd gflags c. mkdir build && cd build#以下DCMAKE_INSTALL_PREFIX 之后的路径为自己想要安装的路径,如果有root权限且可以安装到系统目录下,那么可以不用指定prefix选项 d. cmake .. -DCMAKE_INSTALL_PREFIX=/xxx -DCMAKE_BUILD_TYPE=Release e. make && make install #增加gflags的include 和 lib库的路径到系统库下面,如上面未指定路径,则系统默认安装在 #/usr/local/gflags f. 编辑当前用户下的bashrc,添加如下内容: export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/xxx/gcc-5.3/lib64:/xxx/gflags/lib export LIBRARY_PATH=$LIBRARY_PATH:/xxx/gflags/include- 安装
snappy
sudo yum install snappy snappy-devel - 安装
zlib
yum install zlib zlib-devel - 安装
bzip2
yum install bzip2 bzip2-devel - 安装
lz4
yum install lz4-devel - 安装
zstardard
以上已经将wget https://github.com/facebook/zstd/archive/v1.1.3.tar.gz mv v1.1.3.tar.gz zstd-1.1.3.tar.gz tar zxvf zstd-1.1.3.tar.gz cd zstd-1.1.3 make && sudo make installrocksdb以及titandb所需要的一些系统库安装完成,接下进行rocksdb的安装 - rocksdb源码下载:
git clone https://github.com/facebook/rocksdb.git
或者直接在以上github链接中下载对应的源码包即可
安装,可以参考官方给的安装过程rocksdb官网安装过程
此时成功之后,可以看到expample下生成了官方所给出的一些rocksdb的测试样例。cd rocksdb make static_lib #编译rocksdb的静态库 cd example && make all
TitanDb
以上rocksdb的一些插件都安装完成且成功之后,记录下gflags是安装路径,接下来进行TitanDbb的安装。Titan的官方安装过程如下titan安装
#titanDb属于rocksdb 6.4版本基础上的一个插件,所以编译时仍然需要rocksdb对应代码的支持
#下载rocksdb对应版本的代码
git clone https://github.com/tikv/rocksdb pingcap_rocksdbgit clone https://github.com/tikv/titan.git
cd titan && mkdir build && cd build#编译时需制定我们刚才下载好的titan使用的rocksdb版本代码,在pingcap_rocksdb目录下
#(不能使用最新的rocksdb代码,否则部分文件会缺失
#同时还要指定我们编译好的glfags 安装的路径
cmake .. -DROCKSDB_DIR=../pingcap_rocksdb -DCMAKE_PREFIX_PATH=/xxx/gflags -DCMAKE_BUILD_TYPE=Releasemake -j #编译
测试
使用rocksdb提供的接口编写测试代码
目标:测试rocksdb的写性能。
需求子功能如下:
- 可以指定写请求的输入
- key的选择范围 可以输入(测试热点读的性能),默认(2^64)范围内,key的生成在指定的范围内是随机的
- value的size可以输入,可以测试不同大小的value场景下写的性能
- compaction线程数目可以指定
编写测试代码如下 rocksdb_titan_test.h:
#include <ctime>
#include <cstdio>
#include <cstdlib>
#include <cassert>#include <sys/time.h>
#include <unistd.h>
#include <signal.h>#include <iostream>
#include <string>
#include <vector>#include "rocksdb/db.h"using namespace std;static long db_count = 3; //生成三个db数据库,使用三个字进程分别向三个db数据库压测数据
static long test_count;
static long key_range;static long compaction_num = 32; //指定compaction的线程数,默认是32个
static long value_size = 100; //指定value_size的大小,默认是100KBstatic long db_no = -1;static long parse_long(const char *s)
{char *end_ptr = nullptr;long v = strtol(s, &end_ptr, 10);assert(*s != '\0' && *end_ptr == '\0');return v;
}static double now()
{struct timeval t;gettimeofday(&t, NULL);return t.tv_sec + t.tv_usec / 1e6;
}static string long_to_str(long n)
{char s[30];sprintf(s, "%ld", n);return string(s);
}/*初始化各个参数 以及 生成子进程来负责分别向各自的数据库进行压测*/
static void init(int argc, char *argv[])
{assert(argc == 5);test_count = parse_long(argv[1]);key_range = parse_long(argv[2]);value_size = parse_long(argv[3]);compaction_num = parse_long(argv[4]);/*如果key输入为0,那么key的范围为2^62次方,即完全的随机key写 */if (key_range == 0){key_range = 1L << 62;}assert(db_count > 0 && db_count <= 20 && test_count > 0 && key_range > 0 && value_size > 0 && compaction_num >= 0);for (long i = 0; i < db_count; ++ i){pid_t pid = fork();assert(pid >= 0);if (pid == 0){//childsignal(SIGHUP, SIG_IGN); //接收到两个终止信号,则子进程终止运行db_no = i;break;}}if (db_no < 0){//parentsleep(1);exit(0);}srand((long)(now() * 1e6) % 100000000);
}/*在给定的key的范围内,随机生成key*/
static string rand_key()
{char s[30];unsigned long long n = 1;for (int i = 0; i < 4; ++ i){n *= (unsigned long long)rand();}sprintf(s, "%llu", n % (unsigned long long)key_range);string k(s);return k;
}/*使用模版函数来实例化Rocksdb和titanDb*/
template <class DB, class OPT>
static void do_test(const string &db_name)
{OPT options;options.create_if_missing = true;options.stats_dump_period_sec = 30;Options.use_fsync=true; //初始化db时使用SYNC写,否则数据会通过文件系统写入到pagecache中就返回了。if(compaction_num == 0) {options.compaction_style = kCompactionStyleNone;// 如设置的compaction线程数为0,则需制定None参数来禁止compaction} else {Options.max_background_compactions = compaction_num; //否则设置具体线程数}string db_full_name = db_name + "_" + long_to_str(db_no); //组合各个子db数据库的名称printf("%s: db_count=%ld, test_count=%ld, key_range=%ld\n", db_full_name.c_str(), db_count, test_count, key_range);/*rocksdb自身的open函数,打开./db/rocksdb_1 或者 ./db/titan_1作为db目录*/DB *db;rocksdb::Status status = DB::Open(options, string("./db/") + db_full_name, &db);if (!status.ok()){cerr << "open db failed: " << status.ToString() << endl;exit(1);}const size_t long_value_len = 5 * 1024 * 1024;string long_value(long_value_len, 'x');assert(long_value.size() == long_value_len);for (size_t i = 0; i < long_value_len; ++ i){long_value[i] = (unsigned char)(rand() % 255 + 1);}double ts = now();const size_t value_slice_len = value_size * 1024; //每一个value的分片大小for (long i = 1; i <= test_count; ++ i){rocksdb::Slice rand_value(long_value.data() + rand() % (long_value_len - value_slice_len), value_slice_len);/*Put请求*/rocksdb::Status s = db->Put(rocksdb::WriteOptions(), rand_key(), rand_value);if (!s.ok()){cerr << "Put failed: " << s.ToString() << endl;exit(1);}/*每写10000 key-value到数据库,计算耗时和写入性能*/if (i % 10000 == 0){double tm = now() - ts;printf("%s: time=%.2f, count=%ld, speed=%.2f\n", db_full_name.c_str(), tm, i, i / tm); fflush(stdout);}}printf("\n");sleep(30); //等待最后的stat dump输出delete db;
}
rocksdb_test.cpp
#include "rocksdb_titan_test.h"int main(int argc, char *argv[])
{init(argc, argv);do_test<rocksdb::DB, rocksdb::Options>("rocksdb");
}
titan_test.cpp
#include "titan/db.h"
#include "rocksdb_titan_test.h"int main(int argc, char *argv[])
{init(argc, argv);do_test<rocksdb::titandb::TitanDB, rocksdb::titandb::TitanOptions>("titan");
}
编译链接rocksdb和titandb 各自动态库,生成二进制文件
将以上三个文件放在同一目录下db_code,且在当前目录下编写用于编译链接库的Makefile
PS:makefile中的一些路径(g++/gflags)需要和之前编译rocksdb/titandb时的路径一致
#高版本g++所在路径
CC = /xxx/gcc-5.3/bin/gcc#指定编译时所需要的库
CFLAGS = -std=gnu++11 -Wall -O2 -fno-strict-aliasing -fPIC -pthread -rdynamic#指定rocksdb和titandb 运行时需要依赖的库
LDFLAGS = -lz -lbz2 -ldl -lrt -llz4 -lsnappyROCKSDB_DIR = /home/xxx/rocksdb_vs_titan/rocksdb
ROCKSDB_INCLUDE_FLAGS = -I$(ROCKSDB_DIR)/include
ROCKSDB_LIB = $(ROCKSDB_DIR)/librocksdb.arocksdb:$(CC) $(CFLAGS) $(R_INCLUDE_FLAGS) -o rocksdb_test rocksdb_test.cpp $(R_LIB) $(LDFLAGS)TITANR_DIR = /home/xxx/rocksdb_vs_titan/rocksdb_vs_titan/pingcap_rocksdb
TITAN_DIR = /home/xxx/rocksdb_vs_titan/rocksdb_vs_titan/titan
TITAN_INCLUDE_FLAGS = -I$(TITAN_DIR)/include -I$(TITANR_DIR)/include -I$(TITANR_DIR)
TITAN_LIB = $(TITAN_DIR)/build/libtitan.a $(TITAN_DIR)/build/rocksdb/librocksdb.atitan:$(CC) $(CFLAGS) $(T_INCLUDE_FLAGS) -o titan_test titan_test.cpp $(T_LIB) $(LDFLAGS)all: rocksdb titan
编译:
在当前目录下db_code执行:
make rocksdb_test 来生成rocksdb的测试二进制文件 rocksdb_test
在当前目录下db_code执行:
make titan_test 生成titandb的测试二进制文件 titan_test
或者执行make all生成两个测试的二进制文件
测试
- 寻找一块磁盘(建议ssd),格式化成文件系统
mkfs.xfs /dev/sdd - 挂载进入到文件系统
mount /dev/sdd /db_test && cd /db_test - 拷贝我们编译好的两个二进制文件到当前目录,创建db文件夹
- 运行方式如下:
./rocksdb_test 500000 0 8 32
测试五十万value大小为8KB随机key写性能,后台设置compaction线程个数为32
输出如下:
Thu May 14 23:03:14 2020
rocksdb_1: db_count=3, test_count=500000, key_range=4611686018427387904
Thu May 14 23:03:14 2020
rocksdb_2: db_count=3, test_count=500000, key_range=4611686018427387904
Thu May 14 23:03:14 2020
rocksdb_0: db_count=3, test_count=500000, key_range=4611686018427387904
Thu May 14 23:03:14 2020rocksdb_3: time=275.50, count=30000, speed=108.89
Thu May 14 23:03:14 2020rocksdb_2: time=277.97, count=30000, speed=107.92
Thu May 14 23:03:14 2020rocksdb_0: time=280.40, count=30000, speed=106.99
Thu May 14 23:03:14 2020rocksdb_3: time=282.53, count=30000, speed=106.18
Thu May 14 23:03:14 2020rocksdb_2: time=358.02, count=40000, speed=111.73
同时在当前目录的db目录下可以看到对应的rocksdb数据库相关文件已经生成
#查看当前目录下的db目录
ls db/
rocksdb_0 rocksdb_1 rocksdb_2#查看rocksdb_0目录可以看到已经生成的sst和manifest文件
ls rocksdb_0
001303.sst
001304.log
001305.sst
CURRENT
IDENTITY
LOCK
LOG
MANIFEST-000009
OPTIONS-000005
可以通过LOG文件,分析rocksdb的写过程 + compaction过程以及产生的写放大的详细情况。
通过以上方式分别在不同value size 和compaction线程数的情况下对rocksdb和titan Db的性能进行测试。目前仅仅测试了写,发现titanDb的随机key以及big value情况下的写性能优于rocksdb 2-3倍。
具体原因可以参考以上titanDB相对于rocksdb的核心优化点。
参考资料
wisckey论文:https://www.usenix.org/system/files/conference/fast16/fast16-papers-lu.pdf
titanDb设计: https://pingcap.com/blog/titan-storage-engine-design-and-implementation/
titanDb代码: https://github.com/tikv/titan
rocksdb设计: https://github.com/facebook/rocksdb/wiki
rocksdb代码: https://github.com/facebook/rocksdb
相关文章:

经典SQL练习题
题目地址:http://blog.csdn.net/qaz13177_58_/article/details/5575711 1、 查询Student表中的所有记录的Sname、Ssex和Class列。select sname,ssex,class from STUDENT2、 查询教师所有的单位即不重复的Depart列。select depart from TEACHER group by departselec…

php url模式在哪修改,php如何修改url
php如何修改url2020-07-03 12:15:40php修改url的方法:1、通过配置文件修改URL规则;2、设置URL伪静态,即限制伪静态的后缀;3、在配置文件中开启路由支持,并配置路由;4、将URL进行重写即可。PHP对URL设置一、…

国外十大最流行PHP框架排名
以下为十个目前最流行的基于MVC设计模式的PHP框架。1. YiiYii是一个基于组件的高性能的PHP的框架,用于开发大规模Web应用。Yii采用严格的OOP编写,并有着完善的库引用以及全面的教程。从MVC,DAO/ActiveRecord,widgets,c…
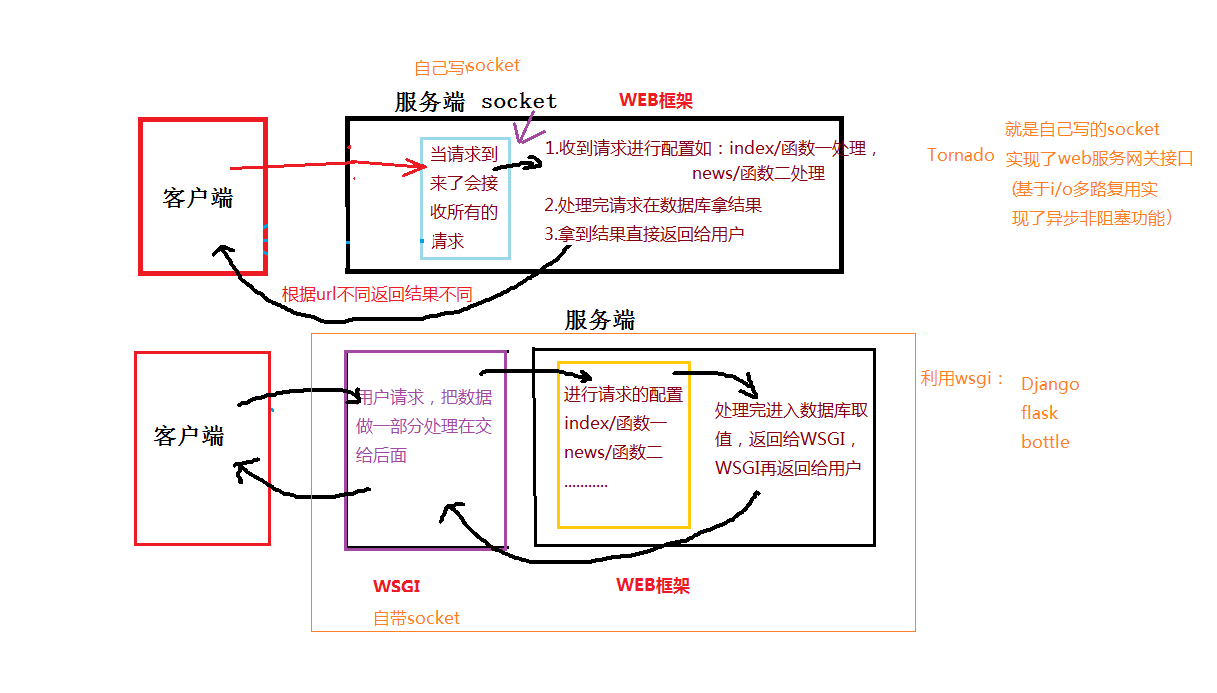
python_web框架
一、web框架 web框架: 自己完成socket的web框架:如,Tornado等由WSGI完成socket的web框架:如,Django、flash等两种实现过程: 第二种WSGI方式的,由于自带socket所以可直接写后端代码。 python标准…
g-gdb 调试多线程
代码调试工具gdb是一个能够让我们在工作中高效排查代码异常根源的利器。 在此将gdb针对多线程的调试方式做一个笔记,也方便后续回顾以及分享大家。 本文采用的是一个简单的多线程代码示例,同时调试是在mac上进行的 mac安装gdb brew install gdb即可 基…

php数据库html文本,关于php,mysql,html的数字分页和文本_php
请勿盗版,转载请加上出处http://blog.csdn.net/yanlintao1请勿盗版,转载请加上出处http://blog.csdn.net/yanlintao1首先进行样式展示希望对大家有所帮助,也希望大家给出意见和建议:第一种:数字分页第二种:…
WinDbg加载不同版本CLR
WinDbg调试.net2.0和.net4.0程序有所不同,因为.net4.0使用新版本的CLR。例如: mscoree.dll 变为 mscoree.dll 和 mscoreei.dll, mscorwks.dll 变为 clr.dll, mscorjit.dll 变为 clrjit.dll。 因此,在.net2.0加载mscorj…
交换机***工具——Yersinia
Yersinia是国外一款专门针对交换机执行第二层***的***工具。目前的版本是0.7.1。目前支持的操作系统及版本号如表1所示。表1 Yerdinia支持的操作系统操作系统名称版本号OpenBSD3.4 (pcap库版本至少0.7.2以上)Linux2.4.x和2.6.xSolaris5.8 64bits SPARCMac OSX10.4 Tiger (Intel…
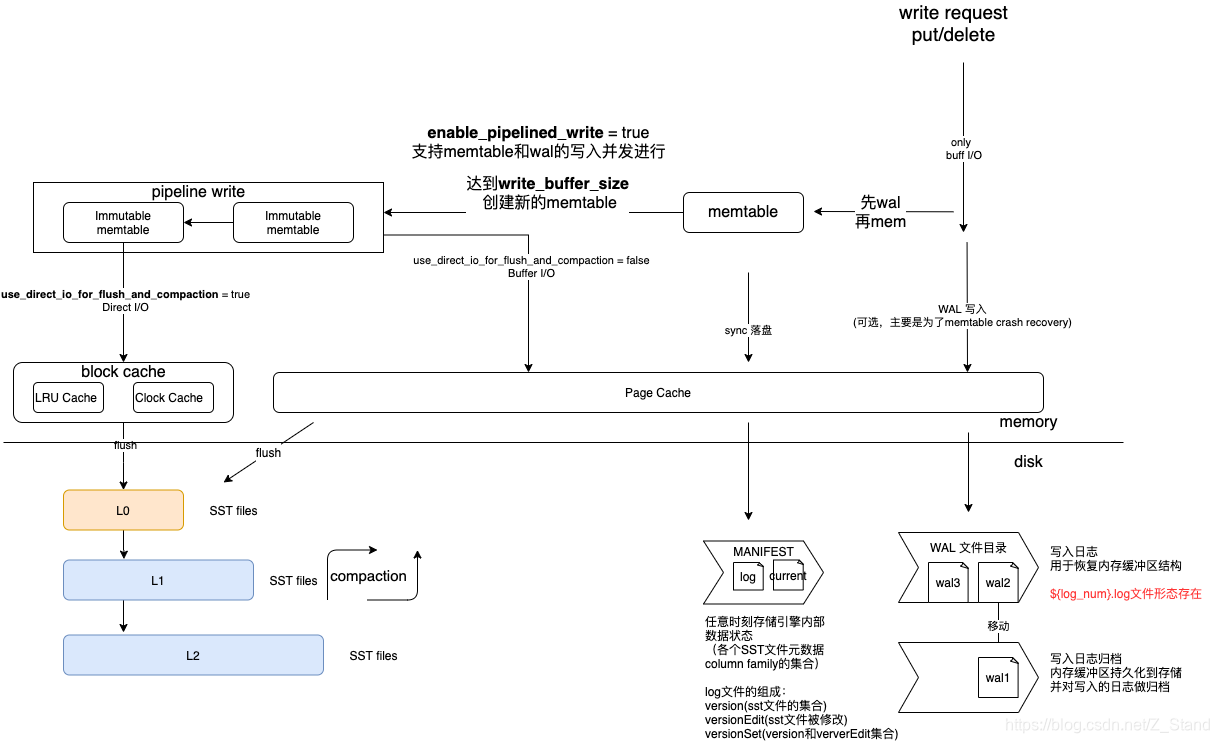
Rocksdb 写流程,读流程,WAL文件,MANIFEST文件,ColumnFamily,Memtable,SST文件原理详解
文章目录前言Rocksdb写流程图WAL 原理分析概述文件格式查看WAL的工具创建WAL清理WALMANIFEST原理分析概述查看MANIFEST的工具创建 及 清除 MANIFEST文件内容CcolumnFamily 详解概述API介绍核心数据结构创建以及删除MEMTABLE 实现概述实现Rocksdb写入逻辑概述实现总结关于写的一…
react 入门
首先安装node.js环境 下载地址 https://nodejs.org/en/download/检查安装版本 进入命令行npm -v~~3. 安装react命令环境 npm install - g react-native-cli ~~~ 初始化项目 FirstAppreact-native init FirstApp 转载于:https://www.cnblogs.com/liu-ya/p/10511537.html
将字符串打乱输出
将字符串打乱输出 Dim i,mm,Str,StrPosition,NewStrStr "1234567890"For i1 To Len(Str) StrPosition GetRandomMath(1,Len(Replace(Str,mm,""))) Str Replace(Str,mm,"") mm Mid(str,StrPosition,1) …
php帝国系统调出图片内空,帝国CMS图集字段的大图,小图,说明的调用方法
本文实例讲述了帝国CMS图集字段的大图,小图,说明的调用方法。分享给大家供大家参考。具体方法如下:复制代码代码如下:$arr array();$arr $navinfor[morepic];$newarr explode(egetzy(rn),$arr);$count count(explode(egetzy(rn),$navinfor[morepic]));//图集的图…
static和global的区别
1.global在整个页面起作用。2.static只在function和class内起作用。global和$GLOBALS使用基本相同,但在实际开发中大不相同。global在函数产生一个指向函数外部变量的别名变量,而不是真正的函数外部变量,一但改变了别名变量的指向地址&#x…
vue 之 nextTick 与$nextTick
VUE中Vue.nextTick()和this.$nextTick()怎么使用? 官方文档是这样解释的: 在下次 DOM 更新循环结束之后执行延迟回调。在修改数据之后立即使用这个方法,获取更新后的 DOM。 虽然 Vue.js 通常鼓励开发人员沿着“数据驱动”的方式思考ÿ…
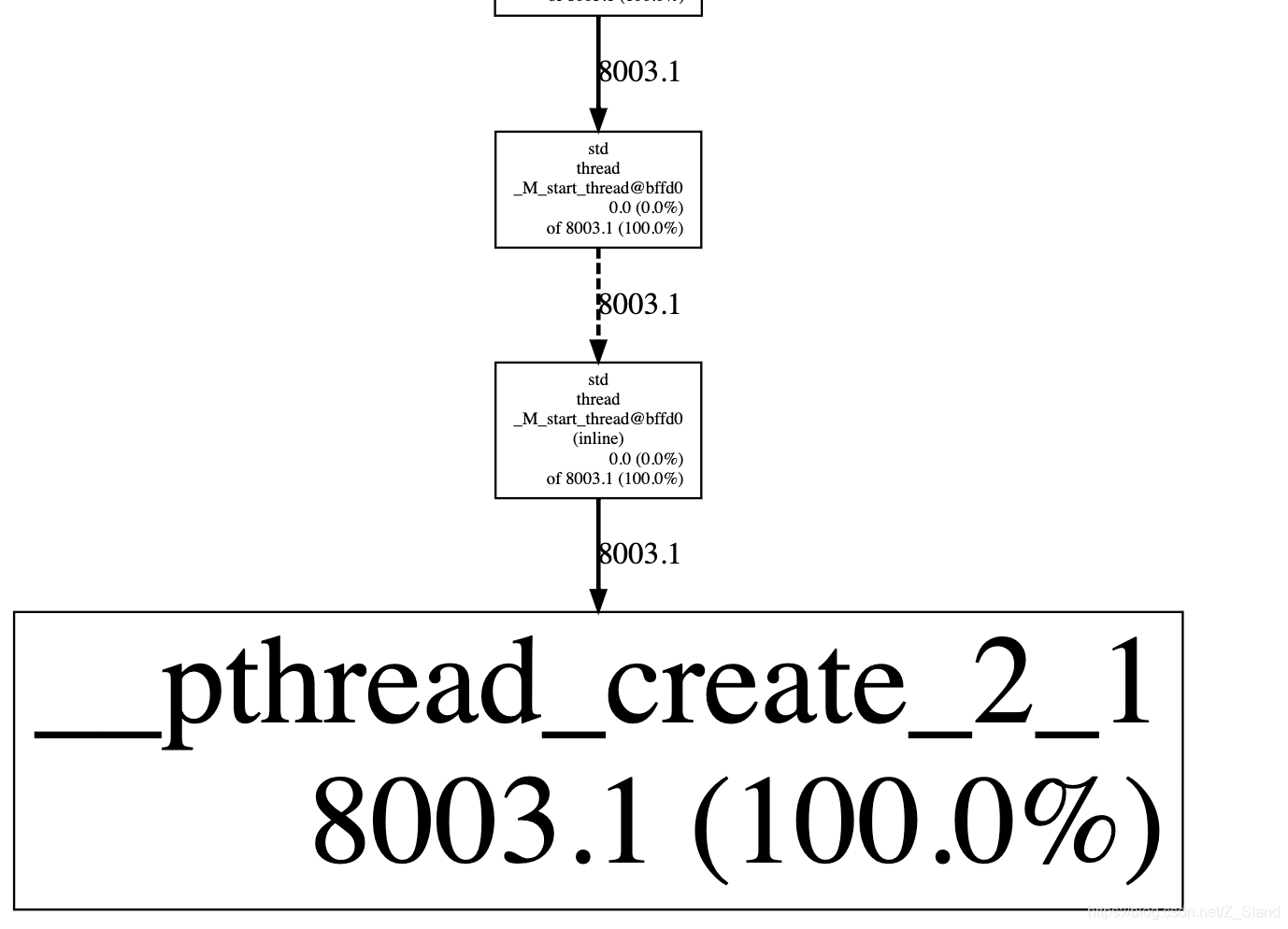
Linux创建线程时 内存分配的那些事
文章目录问题描述问题分析针对问题1 的猜测:针对问题2 的猜测:原理追踪总结问题描述 事情开始于一段内存问题,通过gperf工具抓取进程运行过程中的内存占用情况。 分析结果时发现一个有趣的事情,top看到的实际物理内存只有几兆,但是pprof统计…
mysql plsql循环语句吗,Oracle PLSQL 在游标中用while循环实例程序
Oracle PLSQL 在游标中用while循环实例程序Oracle PLSQL 在游标中用while循环实例程序Oracle PLSQL 在游标中用while循环实例程序declarecursor emp_cur is select * from emp;v_emp emp%rowType;beginopen emp_cur;while emp_cur%notfound --while肯定要跟loop一起用的 且是控…
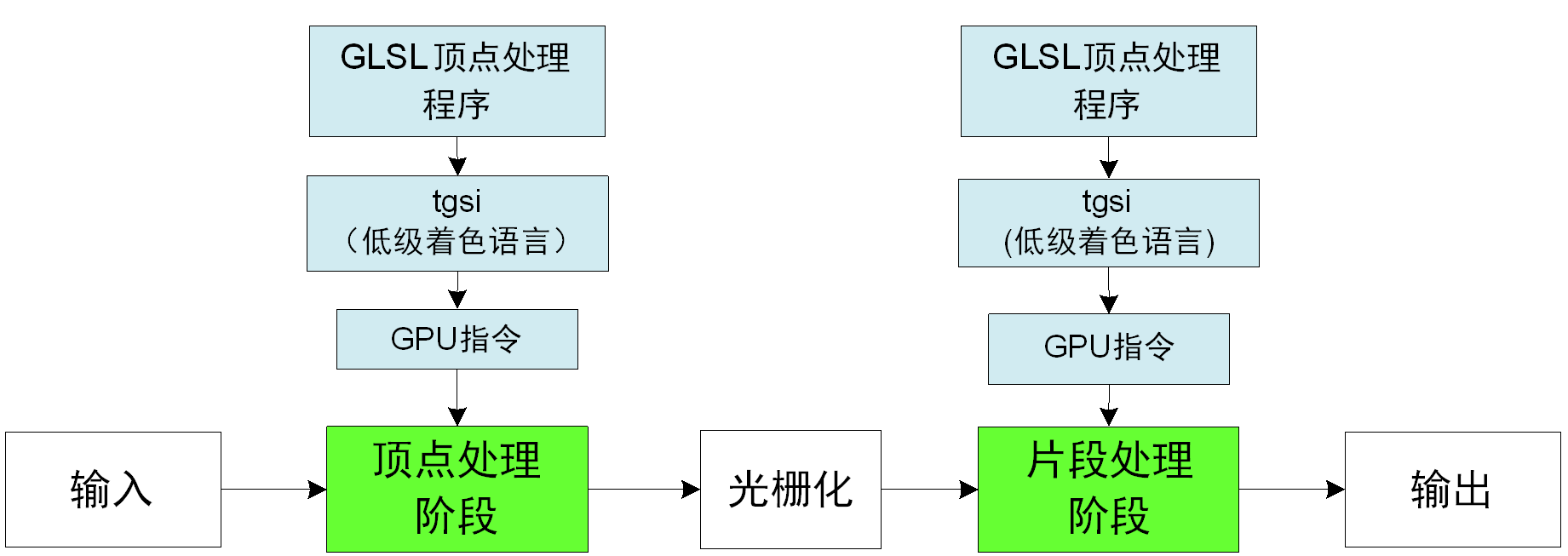
【原创】Linux环境下的图形系统和AMD R600显卡编程(11)——R600指令集
1 低级着色语言tgsi OpenGL程序使用GLSL语言对可编程图形处理器进行编程,GLSL语言(以下高级着色语言就是指GLSL)是语法类似C的高级语言,在GLSL规范中,GLSL语言被先翻译成教低级的类汇编语言,然后被翻译成硬…
VBScript中InStr函数的用法
InStr([start, ]str1, str2[, compare]) [用途]:返回str2在str1中的位置。匹配成功时,返回值最小值为1,未匹配到时返回0。 [参数说明]: start:在str1中开始匹配的位置,1表示从头开始,不能为0或更小值。 可选…
洛谷P3122 [USACO15FEB]圈住牛Fencing the Herd(计算几何+CDQ分治)
题面 传送门 题解 题目转化一下就是所有点都在直线\(AxBy-C0\)的同一侧,也就可以看做所有点代入\(AxBy-C\)之后的值符号相同,我们只要维护每一个点代入直线之后的最大值和最小值,看看每条直线的最大最小值符号是否相同就好了 以最大值为例&am…

skiplist跳表的 实现
文章目录前言跳表结构时间复杂度空间复杂度高效的动态插入和删除跳表索引的动态更新总结详细实现前言 rocksdb 的memtable中默认使用跳表数据结构对有序数据进行的管理,为什么呢? 同时redis 也用跳表作为管理自己有序集合的数据结构,为什么…

php的反射作用是什么意思,php反射的作用是什么
反射是在PHP运行状态中,扩展分析PHP程序,导出或提取出关于类、方法、属性、参数等的详细信息,包括注释。这种动态获取的信息以及动态调用对象的方法的功能称为反射API。反射是操纵面向对象范型中元模型的API,其功能十分强大&#…
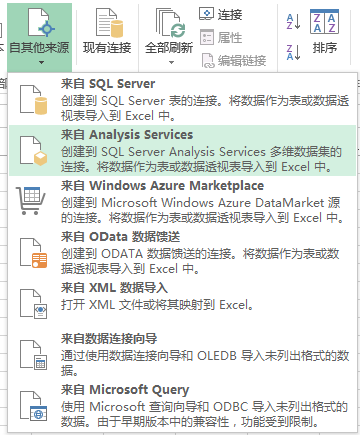
《BI项目笔记》用Excel2013连接和浏览OLAP多维数据集
《BI项目笔记》用Excel2013连接和浏览OLAP多维数据集 原文:《BI项目笔记》用Excel2013连接和浏览OLAP多维数据集用Excel2013连接和浏览OLAP多维数据集 posted on 2014-12-02 08:58 NET未来之路 阅读(...) 评论(...) 编辑 收藏 转载于:https://www.cnblogs.com/lonelyxmas/p/413…
mac 拷贝文件时报错 8060 解决方案
解决如下: 即某文件夹下出现多重子目录,级数很多,删除多余的子文件夹即可。 至于如何产生的,有人说是xcode升级导致,不过没有见证 。我的不属于这类情况的。 (参见:http://macosx.com/forums/ma…
C#连接数据库
VScode 配置C#环境 https://blog.csdn.net/qq_40346899/article/details/80955788VScode 配置C#开发环境 using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks;using System.Data; using System.Data.SqlCli…
C++ 中emplace_back和push_back差异
前言 最近看rocskdb源码,发现了大量的设计模式和C高级特性,特此补充一下,巩固基础。 问题描述 其中关于动态数组的元素添加,代码中基本将push_back抛弃掉了,全部替换为emplace_back进行元素的添加。 看了一下官网描…
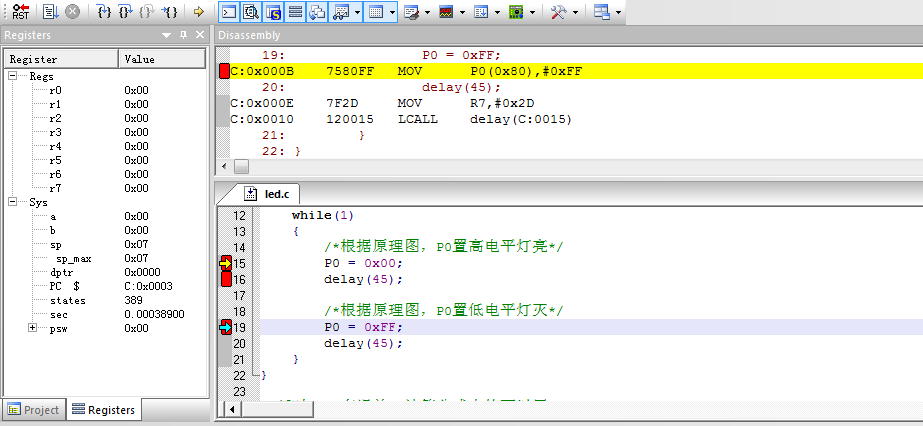
[51单片机学习笔记ONE]-----LED灯的多种使用方法
一.交替闪烁8个LED灯,时间间隔为1s 1 /******************************************************2 实验名称: 交替闪烁8个LED灯,时间间隔1s3 实验时间: 2014年12月2日4 ******************************************************/…
php 伪协议 lfi,php://伪协议(I/O)总能给你惊喜——Bugku CTF-welcome to bugkuctf
今天一大早BugkuCTF 的welcome to bugkuctf 就给了我一发暴击:完全不会啊。。。光看源码就发现不知道怎么处理了,于是转向writeup求助。结果发现这是一道非常有营养的题目,赶紧记录一下。题目链接:http://123.206.87.240:8006/tes…
Pascal's Triangle
帕斯卡三角形,主要考察vector的用法。 vector<vector<int> > generate(int numRows){vector<vector<int> > result;vector<int> tmp;result.clear();tmp.clear();int i,j;if(numRows 0)return result;else if(numRows 1){tmp.push_…
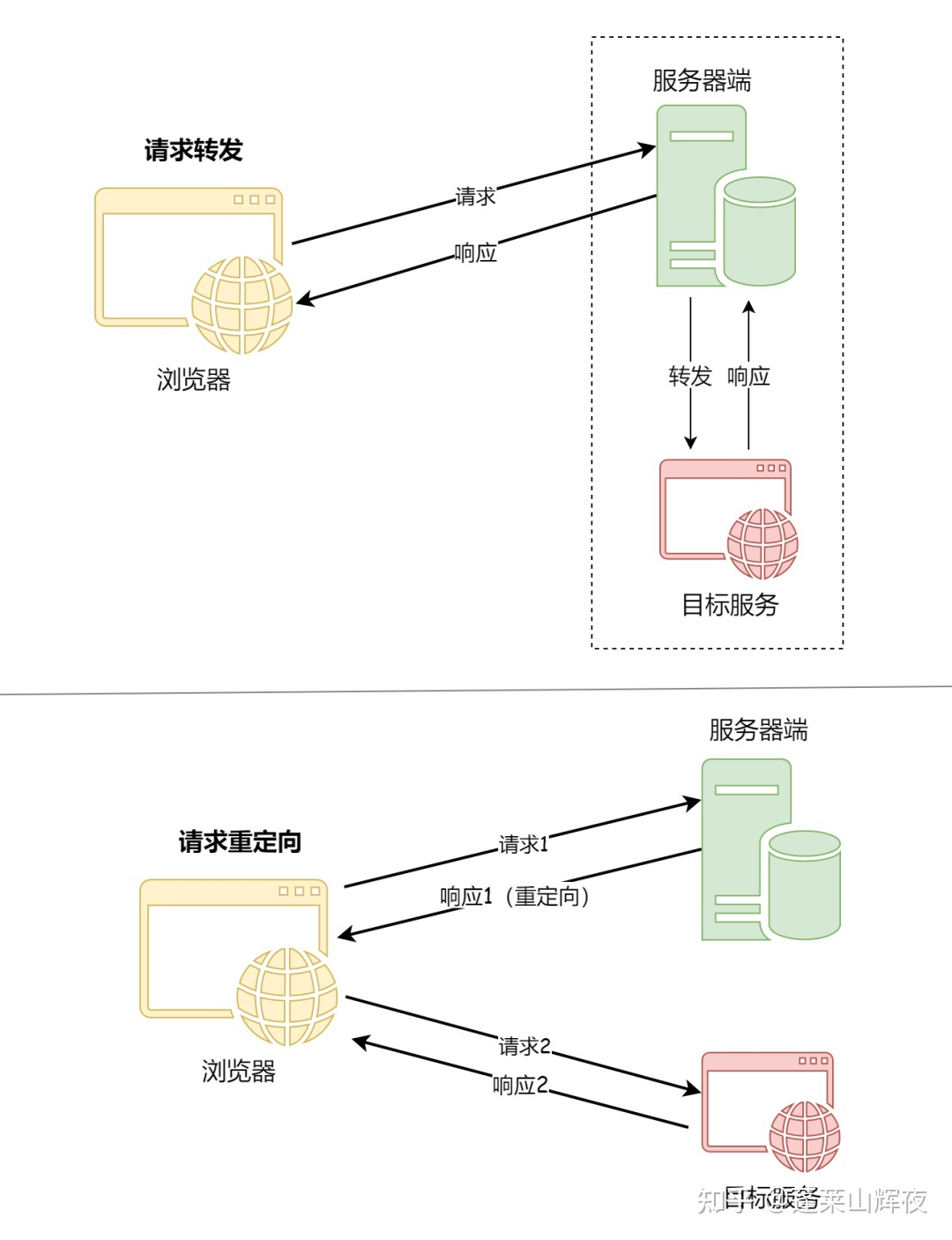
SpringBoot请求转发与重定向
但是可能由于B网址相对于A网址过于复杂,这样搜索引擎就会觉得网址A对用户更加友好,因而在重定向之后任然显示旧的网址A,但是显示网址B的内容。在平常使用手机的过程当中,有时候会发现网页上会有浮动的窗口,或者访问的页面不是正常的页面,这就可能是运营商通过某种方式篡改了用户正常访问的页面。重定向,是指在Nginx中,重定向是指通过修改URL地址,将客户端的请求重定向到另一个URL地址的过程,Nginx中实现重定向的方式有多种,比如使用rewrite模块、return指令等。使用场景:在返回视图的前面加上。
SSO 单点登录和 OAuth2.0 有何区别?
此方法的缺点是它依赖于浏览器和会话状态,对于分布式或者微服务系统而言,可能需要在服务端做会话共享,但是服务端会话共享效率比较低,这不是一个好的方案。在单点登录的上下文中,OAuth 可以用作一个中介,用户在一个“授权服务器”上登录,并获得一个访问令牌,该令牌可以用于访问其他“资源服务器”上的资源。首先,SSO 主要关注用户在多个应用程序和服务之间的无缝切换和保持登录状态的问题。这种方法通过将登录认证和业务系统分离,使用独立的登录中心,实现了在登录中心登录后,所有相关的业务系统都能免登录访问资源。