Rocksdb 的优秀代码(一) -- 工业级分桶算法实现分位数p50,p99,p9999
文章目录
- 基本概念
- 普通的分位数计算
- Rocksdb中的应用
- rocksdb中的分桶算法结果展示
- rocksdb 分桶算法实现
- 一些总结 和 相关论文
我们知道一个完整的监控系统必须存在p99/p999等分位数指标,作为系统可用性的评判标准之一。而像开源监控系统中做的很不错的grafana和prometheus一定需要工业级的分位数算法。
本文中涉及到的rocksdb源代码都是基于rocksdb 6.4.6版本
基本概念
所谓分位数(quantile),比如p99,表示percent of 99,即99% 的数据小于当前p99的指标。使用分位数来统计系统的长尾延时,也是系统可用性的一种衡量指标。
由分位数的基本描述中我们能够看到分位数的结果计算是需要有排序的过程,我们想要知道99%的指标小于某一个值,即需要针对当前数据集进行从小到大的排序,取到第99%的数据才能拿到p99的指标。
所谓工业级 ,由以上针对p99的计算过程我们知道这个过程需要排序,同时肯定也需要占用存储空间,当系统吞吐达到数十万级更高量级 ,分位数的精确度 和 其计算过程中的空间占用 trade off 也需要重点关注。那么一个高性能,节省空间,以及精确度较高的分位数实现算法就需要仔细揣摩。
普通的分位数计算
我们常见的分位数为p50,p99,p999,p9999 ,在计算不同分位数数值的过程一般分位三步:
- 将数据从小到大排列
- 确定p 分位数位置
- 确定p 分位数的具体数值
数据从小达到的排序就是我们正常的排序算法。
确定p分位数的位置,比如p99,则确定整个数组中99%的那个元素所处的位置,一般通过
pos = 1 + (n - 1) * p
为了保证得到的是第99%个元素,将计算时的元素位置前移 并 在最后的结果+1。
确定分位数的具体数值则通过如下公式:
在数据已经完成从小到大的排列之后,通过如下公式完成计算。
p分位数位置的值 = 位于p分位数取整后位置的值 + (位于p分位数取整下一位位置的值 - 位于p分位数取整后位置的值)*(p分位数位置 - p分位数位置取整)
Rocksdb中的应用
作为高性能单机引擎,rocksdb内部有数量庞大的metrics,也有对应的分位数。在单机引擎数十万的qps下,针对请求耗时的分位数计算 必须满足工业级需求。既需要较高的性能和精确度,又需要较少的空间占用。
如果按章上文普通方式的算法完成分位数的计算:
- 空间占用的消耗 :需要保存所有的指标数据,假如每秒钟产生20w的qps,那么就需要保存20w对应的uint64_t 的指标数据。而且,rocksdb中指标数十甚至上百个,每个指标 每秒都需要保存20w的指标数据,这对内存是一个巨大的消耗。
- 计算资源的消耗: 因为分位数的获取是由用户来指定时间的,也就是在用户指定获取分位数之前所有的指标都需要累加,如果这一段累计的时间较长,那么获取的时候进行数据全排的计算代价就非常大了。
接下来我们一起看看工业级的rocksdb是如何解决以上两方面的问题的。
rocksdb中的分桶算法结果展示
先简单展示一下rocksdb的一秒钟level0 读耗时的分位数统计结果指标:
** Level 0 read latency histogram (micros):
Count: 360578 Average: 2.8989 StdDev: 116.15
Min: 1 Median: 1.6243 Max: 38033
Percentiles: P50: 1.62 P75: 1.95 P99: 3.95 P99.9: 16.61 P99.99: 290.83
------------------------------------------------------
[ 0, 1 ] 6994 1.940% 1.940%
( 1, 2 ] 277573 76.980% 78.920% ###############
( 2, 3 ] 70608 19.582% 98.502% ####
( 3, 4 ] 1884 0.522% 99.024%
( 4, 6 ] 454 0.126% 99.150%
( 6, 10 ] 2110 0.585% 99.735%
( 10, 15 ] 507 0.141% 99.876%
( 15, 22 ] 380 0.105% 99.981%
( 22, 34 ] 20 0.006% 99.987%
( 34, 51 ] 6 0.002% 99.988%
( 110, 170 ] 4 0.001% 99.989%
( 170, 250 ] 1 0.000% 99.990%
( 250, 380 ] 3 0.001% 99.991%
( 380, 580 ] 2 0.001% 99.991%
( 580, 870 ] 4 0.001% 99.992%
( 870, 1300 ] 5 0.001% 99.994%
( 1300, 1900 ] 4 0.001% 99.995%
( 1900, 2900 ] 6 0.002% 99.996%
( 2900, 4400 ] 5 0.001% 99.998%
( 9900, 14000 ] 3 0.001% 99.999%
( 14000, 22000 ] 3 0.001% 99.999%
( 22000, 33000 ] 1 0.000% 100.000%
( 33000, 50000 ] 2 0.001% 100.000%
非常清晰得看到 各个层级的分位数指标,包括p50,p75,p99,p99.9,p99.99
在Percentiles之下 总共有四列(这里将做括号和右方括号算作一列,是一个hash桶)
- 第一列 : 看作一个hash桶,这个hash桶表示一个耗时区间,单位是us
- 第二列:一秒内产生的请求耗时命中当前耗时区间的有多少个
- 第三列:一秒内产生的请求耗时命中当前耗时区间的个数占总请求个数的百分比
- 第四列:累加之前所有请求的百分比
通过hash桶完整得展示了 耗时主体命中在了(1,2]us的耗时区间,占了整个耗时比例的78.9%。
以上仅仅是L0的一个分位数统计,rocksdb为每一层都维护了类似这样的耗时桶。同时实际测试过程中,累加每秒的耗时统计结果即上面的Count统计, 和实际的每秒的qps进行对比发现并没有太大的差异,也就是这里的耗时统计和实际的请求统计接近,且并没有太多的资源消耗。(打开opstions.statistics和关闭这个指标,系统CPU资源的消耗并没有太大的差异),也就是说单从rocksdb实现的分位数算法的计算资源消耗角度来看已经满足工业级的标准了。
rocksdb 分桶算法实现
按照我们之前描述的分位数计算的三步来看rocksdb的代码
- 将数据从小到达排列
- 确定p 分位数位置
- 计算p 分位数的值
第一步,数据从小到大进行排列。在rocksdb中,我们打开statistics选项之后相关的耗时指标会动态增加,也就是分位数计算的数据集是在不断增加且动态变化的。
rocksdb的数据集中元素的增加逻辑如下:
void HistogramStat::Add(uint64_t value) {// This function is designed to be lock free, as it's in the critical path// of any operation. Each individual value is atomic and the order of updates// by concurrent threads is tolerable.const size_t index = bucketMapper.IndexForValue(value); // 通过hash桶计算value所处的 耗时范围assert(index < num_buckets_);// index 所在的hash桶 bucket_[index]元素个数自增buckets_[index].store(buckets_[index].load(std::memory_order_relaxed) + 1,std::memory_order_relaxed);uint64_t old_min = min();if (value < old_min) {min_.store(value, std::memory_order_relaxed);}uint64_t old_max = max();if (value > old_max) {max_.store(value, std::memory_order_relaxed);}num_.store(num_.load(std::memory_order_relaxed) + 1,std::memory_order_relaxed);sum_.store(sum_.load(std::memory_order_relaxed) + value,std::memory_order_relaxed);sum_squares_.store(sum_squares_.load(std::memory_order_relaxed) + value * value,std::memory_order_relaxed);
}
以上添加的过程整体的逻辑如下几步
- 计算该value 代表的耗时 所处hash桶的范围。假如传入的是2.5us, 则该耗时处于上文中打印出来的耗时范围(2,3],返回该范围代表的索引号
[ 0, 1 ] 6994 1.940% 1.940% ( 1, 2 ] 277573 76.980% 78.920% ############### ( 2, 3 ] 70608 19.582% 98.502% #### ( 3, 4 ] 1884 0.522% 99.024% ( 4, 6 ] 454 0.126% 99.150% - 拿到索引号,更新该hash桶的元素个数。 即bucket_自增
- 更新当前层的当前读耗时其他指标:最小值,最大值,值的总和,值平方的总和
也就是整个添加过程并不会将新的value数据保存下来,而是维护该value所处的bucket_大小,这个bucket_一个std::atomic_uint_fast64_t的数组,初始化整个hash桶的过程就已经完成了整个hash桶耗时范围的映射。
其中计算索引的逻辑如下:
主要是通过变量valueIndexMap_来查找的,这个变量在HistogramBucketMapper构造函数中进行的初始化。是一个map类型,key-value代表的是一个个已经完成初始化的耗时区间。
在IndexForValue函数中拿着当前耗时数据value 在valueIndexMap_中查找到第一个小于等于(lower_bound)当前指标的索引位置。
size_t HistogramBucketMapper::IndexForValue(const uint64_t value) const {if (value >= maxBucketValue_) {return bucketValues_.size() - 1;} else if ( value >= minBucketValue_ ) {std::map<uint64_t, uint64_t>::const_iterator lowerBound =valueIndexMap_.lower_bound(value);if (lowerBound != valueIndexMap_.end()) {return static_cast<size_t>(lowerBound->second);} else {return 0;}} else {return 0;}
}
到此,类似于计数排序的方式,通过范围hash桶动态维护了一个个元素所处的bucket_ size,而非整个元素。
hash桶 以map方式实现,本事有序,key-value代表范围,保证相邻的桶的耗时区间不会重叠,从而达到统计的过程中在范围之间是有序的。
这个时候很多同学会有疑惑,返回之间有序,当分位数的某一个指标比如p20落在了一个拥有数万个元素的范围之间。按照当前的计算方式,其实已经无法精确计算p20这样的指标了。之前也说了,rocksdb实现的是工业级的分位数计算,也就是我们通过p99即更高的分位数指标作为系统可用性的评判标准,那当前的分桶算法实现的分位数计算也就能够理解了。
正如我们打印的分桶过程:
[ 0, 1 ] 9230 3.422% 3.422% #
( 1, 2 ] 174704 64.771% 68.193% #############
( 2, 3 ] 50114 18.580% 86.773% ####
( 3, 4 ] 13030 4.831% 91.604% #
( 4, 6 ] 8827 3.273% 94.877% #
( 6, 10 ] 9314 3.453% 98.330% #
( 10, 15 ] 1893 0.702% 99.032%
( 15, 22 ] 969 0.359% 99.391%
( 22, 34 ] 708 0.262% 99.653%
( 34, 51 ] 571 0.212% 99.865%
( 51, 76 ] 324 0.120% 99.985%
( 76, 110 ] 35 0.013% 99.998%
( 110, 170 ] 3 0.001% 99.999%
可以看到在更高层分桶区间内,命中的指标越来越少,也就是像p999,p9999这样的高分位数的统计将更加精确。
当然,也可以有完全精确的计算统计方法,那就是需要通过空间以及计算资源来换取精确度了,这个代价并不是一个很好的trade off方式。rocksdb的分桶同样可以控制精确度,我们可以手动调整初始化桶的精度,来让精度区间更小。
接下来我们看看后面两步:
- 确定p 分位数的位置
- 计算p 分位数的值
这两步的实现主要在如下函数中:
通过传入分位数指标50, 99,99.9,99.99等来进行对应的计算。
double HistogramStat::Percentile(double p) const {double threshold = num() * (p / 100.0); // 分位数所在总请求的位置uint64_t cumulative_sum = 0;for (unsigned int b = 0; b < num_buckets_; b++) {uint64_t bucket_value = bucket_at(b);cumulative_sum += bucket_value;if (cumulative_sum >= threshold) { // 持续累加bucket_请求数,直到达到分位数所在总请求个数的位置// Scale linearly within this bucketuint64_t left_point = (b == 0) ? 0 : bucketMapper.BucketLimit(b-1);uint64_t right_point = bucketMapper.BucketLimit(b);uint64_t left_sum = cumulative_sum - bucket_value;uint64_t right_sum = cumulative_sum;double pos = 0;uint64_t right_left_diff = right_sum - left_sum;if (right_left_diff != 0) {pos = (threshold - left_sum) / right_left_diff; // 计算p 分位数的位置}double r = left_point + (right_point - left_point) * pos; // 计算分位数的值uint64_t cur_min = min();uint64_t cur_max = max();if (r < cur_min) r = static_cast<double>(cur_min);if (r > cur_max) r = static_cast<double>(cur_max);return r;}}return static_cast<double>(max());
}
以上函数关于分位数位置和值的计算基本和下面公式接近:
p分位数位置的值 = 位于p分位数取整后位置的值 + (位于p分位数取整下一位位置的值 - 位于p分位数取整后位置的值)*(p分位数位置 - p分位数位置取整)
rocksdb的计算方式是通过取分位数所处总请求的位置,该请求所在的hash桶范围内取第pos个位置的指标,作为当前分位数的值。
通过这样图就比较清晰的展示计算threshold的精确percentile的值了。
- left_point hash桶区间左端点
- right_point 代表右端点
- threshold 代表分位数所处该区间的位置的比例(并不是一个精确的位置)
- left_sum 达到左端点的之前所有hash桶请求总个数
- right_sum 达到右端点的之前所有hash桶请求总个数
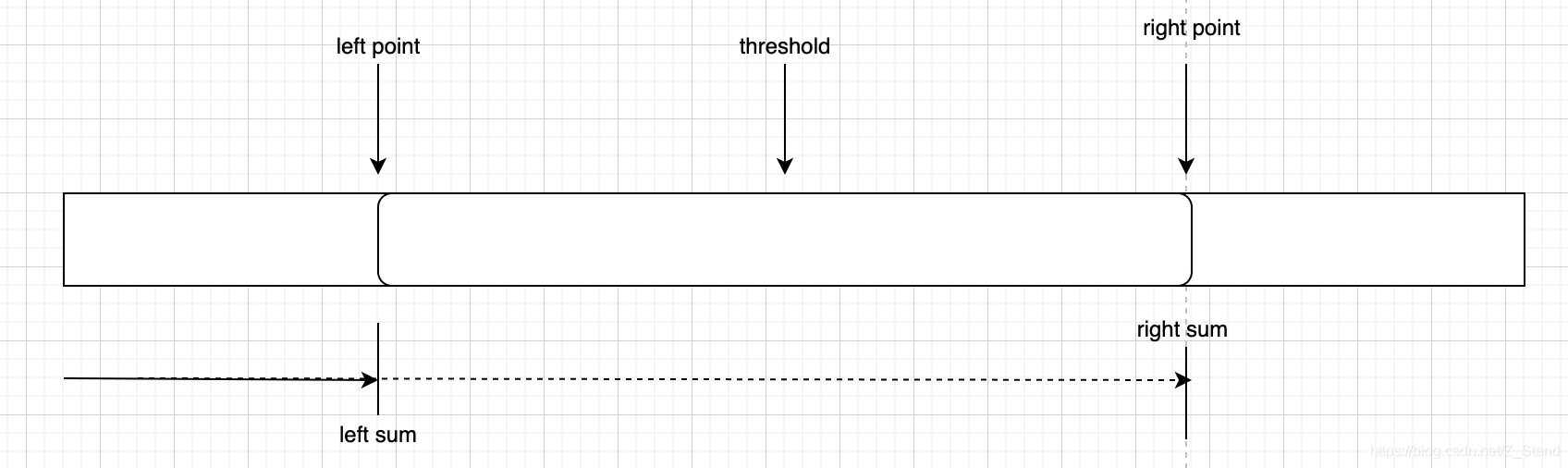
threshold所在的pos 计算如下:pos = (right_sum - threshold) / (right_sum - left sum)
整个pos代表的值的计算如下:r = left_point + pos * (right_point - left_point) ,即可得到当前hash桶所代表的耗时区间内分位数所处的精确位置,当前这里的精确肯定不是100%,也是一个概率性的数值。
一些总结 和 相关论文
工业界的实现总是在成本和收益之间进行取舍,最低的成本换来最大的收益。分位数的价值是说能够用最低的计算和存储成本换来系统可用性的评判,从而更有针对性的进行系统优化,从而产生更大的价值。
分位数的工业界算法实现有很多篇可以参考的论文:
1. 随机算法- Random Sampling with a Reservoir
2.静态分桶算法 - HdrHistogram
3.二叉树实现的静态分桶算法 - Medians and Beyond: New Aggregation Techniques
for Sensor Networks
4. 动态分桶 GK算法
欢迎感兴趣的同学一起讨论~
相关文章:

Java项目:前后端分离疫情防疫平台设计和实现(java+springmvc+VUE+node.js+mybatis+mysql+springboot+redis+jsp)
源码获取:博客首页 "资源" 里下载! 主要技术:Java、springmvc、VUE、node.js、mybatis、mysql、tomcat、jquery、layui、bootstarp、JavaScript、html、css、jsp、log4j等一些常见的基本技术。 主要模块功能有: 管理员…
js里的匿名函数 数组排序
// 匿名函数:其实就是函数的简写形式 var method function(){ alert("123"); } method(); // 匿名函数可以用于事件的处理 function func(){ alert("456"); } window.οnlοadfunc; window.οnlοadfunction(){ alert("加载完成࿰…

oracle监听器动态注册于静态注册的区别
2019独角兽企业重金招聘Python工程师标准>>> 1, oracle 10g 用netca方式建立的都默认为动态注册方式 2,如果想改为静态注册的方式则在listener.ora 中加入如下内容即可 SID_LIST_LISTENER (SID_LIST (SID_DESC (SID_NAME PLSExtProc) (ORACLE_HOME …

什么是Singleton?
Singleton:在Java中即指单例设计模式,它是软件开发中最常用的设计模式之一。 单:指唯一 例:指实例 单例设计模式,即某个类在整个系统中只能有一个实例对象可被获取和使用的代码模式。 要点: 一、单例类只能…
磁盘I:O 性能指标 以及 如何通过 fio 对nvme ssd,optane ssd, pmem 性能摸底
文章目录1. 磁盘I/O性能指标1.1 性能指标1.2 I/O 观测1.2.1 磁盘I/O 观测1.2.2 进程I/O观测2. Fio 性能测试2.1 环境准备2.2 测试维度选择2.3 测试2.3.1 optane ssd和nvme ssd性能测试2.3.2 aep性能测试(intel persistent memory)真正测试之前 我们需要清楚 评判磁盘I/O性能 是…
Java项目:旅游网站管理系统设计和实现(java+springboot+jsp+mysql+spring)
源码获取:博客首页 "资源" 里下载! 运行环境: java jdk 1.8 IDE环境: IDEA tomcat环境: Tomcat 7.x,8.x,9.x版本均可 主要功能说明: 管理员角色包含以下功能:管理员登录,用户管理,旅游路线管理,…
稀疏矩阵十字链表表示
类型定义 #include<stdio.h> #include<malloc.h> #include<stdlib.h> #define MAX 100 /*稀疏矩阵的十字链表表示:非零元素节点与表头节点公用一种类型 */ typedef struct matrixnode {int row,col;struct matrixnode *right,*down;union{int val…
thrift框架使用C++
2019独角兽企业重金招聘Python工程师标准>>> 1. 编写thrift接口文件student.thrift struct Student{1: i32 sno,2: string sname,3: bool ssex,4: i16 sage, } service Serv{i32 put(1: Student s), } 2. 用“thrift -r --gen cpp student.thrift”在gen-cpp文件夹中…
shell编程:实现shell字符串连接功能
功能:实现shell字符串连接功能 a0 s1test. s2.wav s3.mp3 s40 s500str"sox ./${s1}${a}${s2} ./${a}${s3}"./tts -c bcgirl.0.0.4.bin -b 1 -i input.txt -s 1.0 -speed 1.0 $str rm ./*.wav转载于:https://www.cnblogs.com/kay2018/p/10673110.html
一文运维zookeeper
文章目录1. zookeeper生产环境的安装配置1.1 软件配置1.2 硬件配置1.3 日志配置文件1.4 配置三节点的zookeeper集群2. zookeeper的监控方法2.1 four letters命令2.2 JMX 监控方式3. 通过zookeeper observer实现跨地域部署3.1 什么是observer3.2 observer 提升 写性能3.3 observ…
Java项目:电商书城平台系统设计和实现(java+springboot+mysql+spring+jsp)
源码获取:博客首页 "资源" 里下载! JAVA springboot 电商书城平台系统(已调试) 主要实现了书城网站的浏览、加入购物车操作、订单操作、支付操作、分类查看、搜索、以及后台上传图书信息以及订单管理和一些基本操作功能 主要功能截图如下&…

(周三赛)FATE
//题意 打怪的经验值 ,消耗忍耐度 看升级后还能保留的最大忍耐度 用 背包去做,不是很会啊 T T Description 最近xhd正在玩一款叫做FATE的游戏,为了得到极品装备,xhd在不停的杀怪做任务。久而久之xhd开始对杀怪产生的厌恶感&#…

ASP.NET MVC 3中ViewBag, ViewData和 TempData
ViewBag, ViewData十分类似,都可用于把数据从controller传递到view。 ViewBag是WebViewPage中的一个属性,它的类型是dynamic。dynamic类型可以理解为,编译器在编译到这种类型时,会跳过类型检查,而在运行时做这些事情。…
如何在指定文件夹下进入jupyter notebook
第一步: 打开 Anaconda Prompt 第二步: 查看文件夹所在路径 例如:你有个jupyterwork文件夹在 D:\ 路径下 第三步: 在Anaconda Prompt依次输入一下命令: d:cd jupyterworkjupyter notebook完成。转载于:https://www.cnb…

Go 分布式学习利器(16) -- go中可复用的package构建
通过本文,你将了解go 语言中如何将自己的package构建到项目中 以及如何将远程(github)的package构建到项目中。 1. 构建本地的package package 是可复用模块的基本单元,以首字母大写的函数实现来表明可被包外代码访问代码的pack…
JQuery UI
//拖拽插件 draggable <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns"http://www.w3.org/1999/xhtml"><head><title>拖曳…
Java项目:房屋租赁系统设计和实现(java+ssm+mysql+spring+jsp)
源码获取:博客首页 "资源" 里下载! 主要功能描述: 1.登录管理:主要有管理员登录和租客登录 2.房源列表以及添加房源功能: 3.租赁合同管理以及在租房源和已退租房源信息管理: 4.看房申请和退租申请管理&a…

学习网页制作中如何在正确选取和使用 CSS 单位
在 CSS 测量系统中,有好几种单位,如像素、百分比、英寸、厘米等等,Web 开发人员很难了解哪些单位在何处使用,如何使用。很多人习惯了总是使用同一种单位,但这一决定可能会严重限制你的设计的执行。 这里推荐的《Which …
SPOJ GSS3-Can you answer these queries III-分治+线段树区间合并
Can you answer these queries III SPOJ - GSS3 这道题和洛谷的小白逛公园一样的题目。 传送门: 洛谷 P4513 小白逛公园-区间最大子段和-分治线段树区间合并(单点更新、区间查询) 代码: 1 #include<bits/stdc.h>2 using namespace std;3 typedef long long l…

Zookeeper ZAB协议原理浅析
文章目录前言1. 基本角色和概念2. Leader Election3. Discovery4. Synchronization5. BroadCast后记前言 DTCC 要在下周一到周三要在北京举办,身边有不少人都去参加了,领略中国最为领先的一些公司的自研存储技术。 阿里自研polardb,polardb-…
Java项目:仓库管理系统设计和实现(java+ssm+springboot+layui)
源码获取:博客首页 "资源" 里下载! 主要功能模块 1.用户模块管理:用户登录、用户注册、用户的查询、添加、删除操作、 2.客户信息管理:.客户列表的展示、添加、修改、删除操作、 3.供应商管理:供应商详情…
Java Web 中的一些问题
http://localhost:8080/struts2demo/online/userLogin.jsp 请求模式 :// 主机名名称(或者服务器名称) : 端口 / Servlet容器的名称(通常为项目名称) / 自定义的网页文件夹名或者映射中的文件包名 / 网页名称及其后缀或者响应动作…

《零成本实现Web自动化测试--基于Selenium》第一章 自动化测试基础
第一篇 Selenium 和WebDriver工具篇 第一章 自动化测试基础 1.1 初识自动化测试 自动化测试有两种常见方式 1.1.1 代码驱动测试,又叫测试驱动开发(TDD) 1.1.2 图形用户接口测试: 测试框架产生用户接口事件(例如键盘敲击&#x…
第11章 AOF持久化
AOF持久化在硬盘上保存的是对Redis进行的逻辑操作,类似InnoDB中的bin log。说白了就是你对一个Redis输入了哪些语句,AOF文件都会原封不动的保存起来,等到需要回复Redis的时候再把这些语句执行一遍。 11.1 AOF持久化的实现 AOF简单的理解是把执…

Go 语言实现字符串匹配算法 -- BF(Brute Force) 和 RK(Rabin Karp)
今天介绍两种基础的字符串匹配算法,当然核心还是熟悉一下Go的语法,巩固一下基础知识 BF(Brute Force)RK(Rabin Karp) 源字符串:src, 目标字符串:dest; 确认dest是否是src 的一部分。 BF算法很简单暴力,维护两个下标…

Java项目:前后端分离网上手机商城平台系统设计和实现(java+vue+redis+springboot+mysql+ssm)
源码获取:博客首页 "资源" 里下载! 主要模块设计如下: 前后端主要技术:Java springboot springMVC mybatis mysql vue jquery node.js redis 1) 用户注册和登录功能:。 2) 用户信息的管理以及角色的…

利用AutoSPSourceBuilder和Autospinstaller自动安装SharePoint Server 2013图解教程——Part 1...
这是一篇对之前 《利用AutoSPSourceBuilder和Autospinstaller自动安装SharePoint Server 2013图解教程——Part 2》的补充。本篇博客将对AutoSPSourceBuilder的使用进行说明。 AutoSPSourceBuilder介绍 下载AutoSPSourceBuilder点击进入AutoSPSourceBuilder的官网,找…

Git 版本还原命令
转载:https://blog.csdn.net/yxlshk/article/details/79944535 1.需求场景: 在利用github实现多人协作开发项目的过程中,有时会出现错误提交的情况,此时我们希望能撤销提交操作,让当前版本回到提交前的样子或者某一个版…
NVME CLI -- nvme 命令查看NVME设备内部状态
文章目录NVME 和 AHCI 性能比较NVME-CLI nvme工具使用1. 安装2. 命令综述3. 基本命令演示4. NVME 固件设备升级近期在做一些rocksdb on 新硬件的性能测试(flash ssd, nvme ssd , nvme optane ssd, optane persistent memory),由于底层一些设备…
Java项目:网上水果蔬菜项目系统设计和实现(java+springboot+mysql+ssm)
源码获取:博客首页 "资源" 里下载! 主主要技术:java springmvc springboot mybatis mysql jquery layui 等技术要模块设计如下: 用户角色的功能: 登录、注册、浏览商品、修改个人信息(上传…