一文运维zookeeper
文章目录
- 1. zookeeper生产环境的安装配置
- 1.1 软件配置
- 1.2 硬件配置
- 1.3 日志配置文件
- 1.4 配置三节点的zookeeper集群
- 2. zookeeper的监控方法
- 2.1 four letters命令
- 2.2 JMX 监控方式
- 3. 通过zookeeper observer实现跨地域部署
- 3.1 什么是observer
- 3.2 observer 提升 写性能
- 3.3 observer 实现跨数据中心部署
- 4. zookeeper 不中断服务的集群成员变更方法
- 5. zookeeper数据存储文件:事务文件和快照文件
- 6. 总结
关于分布式协调服务zookeeper,之前已经对整个框架以及基础使用场景和环境配置做个一个总体的介绍
一文入门zookeeper。
ps: 以下实验是在mac上进行的,有一些mac特有的配置会特别说明
本文中使用的zookeeper版本是3.5.8
本节将简单介绍zookeeper的基本运维操作,主要包括:
- zookeeper 生产环境的安装配置
- zookeeper 的监控方法
- 通过zookeeper observer 实现跨地域部署
- 通过动态配置实现不中断服务的集群成员变更
- 如何查看zookeeper的数据存储文件:事务文件和快照文件
通过熟悉以上运维操作,能够更进一步的了解整个zookeeper的架构和实现方式,从而更好得使用它。
1. zookeeper生产环境的安装配置
1.1 软件配置
ZooKeeper 的配置项在 zoo.cfg 配置文件中配置, 另外有些配置项可以通过 Java 系统属性来 进行配置。
- clientPort : ZooKeeper 和客户端通信的端口号。
- dataDir :来保存快照文件的目录。如果没有设置 dataLogDir ,事务日志文件也会保存到这
个目录。 - dataLogDir :用来保存事务日志文件的目录。因为 ZooKeeper 在提交一个事务之前,需要保 证事务日志记录的落盘,所以需要为 dataLogDir 分配一个独占的存储设备。
基本配置文件内容如下,这里是在mac本地进行演示,并没有增加dataLogDir,默认会和dataDir在一个目录,如果有足够的测试服务器可以为该配置分配独立的目录:
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/tmp/zookeeper
# the port at which the clients will connect
clientPort=2181
1.2 硬件配置
建议为zookeeper分配独立的服务器,同时要给zookeeper的事务日志(dataLogDir)分配独立的存储设备或者分区
- 内存:ZooKeeper 需要在内存中保存 data tree 。对于一般的 ZooKeeper 应用场景,8G 的内存足够了。
- CPU:ZooKeeper 对 CPU 的消耗不高,只要保证 ZooKeeper 能够有一个独占的 CPU 核 即可
- 存储:因为存储设备的写延迟会直接影响事务提交的效率,建议为 dataLogDir 分配一个独占的 SSD 盘
1.3 日志配置文件
日志配置文件默认在 conf/log4j
基本配置内容如下:
# 日志级别
zookeeper.root.logger=INFO, CONSOLE
# 对于appender来说,也是Info 或者比info 级别更严重的log会被打出来
zookeeper.console.threshold=INFOzookeeper.log.dir=.
zookeeper.log.file=zookeeper.log
zookeeper.log.threshold=INFO
zookeeper.log.maxfilesize=256MB
zookeeper.log.maxbackupindex=20zookeeper.tracelog.dir=${zookeeper.log.dir}
zookeeper.tracelog.file=zookeeper_trace.loglog4j.rootLogger=${zookeeper.root.logger}#
# console
# Add "console" to rootlogger above if you want to use this
#
# console appender 的实现类
log4j.appender.CONSOLE=org.apache.log4j.ConsoleAppender
log4j.appender.CONSOLE.Threshold=${zookeeper.console.threshold}
# console 日志输出的格式
log4j.appender.CONSOLE.layout=org.apache.log4j.PatternLayout
# 指定详细的日志格式
log4j.appender.CONSOLE.layout.ConversionPattern=%d{ISO8601} [myid:%X{myid}] - %-5p [%t:%C{1}@%L] - %m%n#
# Add ROLLINGFILE to rootLogger to get log file output
#
# 一般会使用appender.ROLLINGFILE作为日志追加方式
log4j.appender.ROLLINGFILE=org.apache.log4j.RollingFileAppender
log4j.appender.ROLLINGFILE.Threshold=${zookeeper.log.threshold}
log4j.appender.ROLLINGFILE.File=${zookeeper.log.dir}/${zookeeper.log.file}
log4j.appender.ROLLINGFILE.MaxFileSize=${zookeeper.log.maxfilesize}
log4j.appender.ROLLINGFILE.MaxBackupIndex=${zookeeper.log.maxbackupindex}
log4j.appender.ROLLINGFILE.layout=org.apache.log4j.PatternLayout
log4j.appender.ROLLINGFILE.layout.ConversionPattern=%d{ISO8601} [myid:%X{myid}] - %-5p [%t:%C{1}@%L] - %m%n
1.4 配置三节点的zookeeper集群
在服务器充足的情况下,每一个服务区基本的配置步骤如下:
- 申请 ZooKeeper 节点服务器。每个 ZooKeeper 节点有两个挂载盘。
- 每个节点安装 JDK 8 。
- 在每个节点为 dataDir 初始化一个独立的文件系统 /data ,编辑 myid,表示server的编号(每个 server代表一个数字,可以echo 1 > /data/myid 即可) 。
- 各个节点之间配置基于 public key 的 SSH 登录。
- 在一个节点上下载解压 apache-zookeeper-3.5.5-bin.tar.gz ,配置 zoo.cfg 。使用 rsync 把解压的目录同步到其他节点。
到此即完成基本的环境配置,我们只需要使用zookeeper提供的cli命令进行运维层面的配置即可。
因为我只有一个mac机器,那只能在一个mac机器中启动三个server进程来模拟zookeeper的集群,这里不需要执行第四步了,对应的第三步通过指定不同的配置目录即可。
模拟的三个节点的配置如下:
需要注意的是其中的server.配置,127.0.0.1表示节点ip或者主机(hostname)名称,7777表示后续zookeeper 集群的qurom通信端口号,7778表示leader选举的端口号。
同时需要打开选项4lw.commands.whitelist=*表示开启zookeeper提供的四字母监控命令的白名单。
- zoo-node1.cfg
tickTime=2000 initLimit=10 syncLimit=5 dataDir=/tmp/zookeeper1 clientPort=2181 server.1=127.0.0.1:7777:7778 server.2=127.0.0.1:6666:6667 server.3=127.0.0.1:5555:5556 4lw.commands.whitelist=* #开启监控命令的白名单,否则后续的监控命令无法使用 - zoo-node2.cfg
tickTime=2000 initLimit=10 syncLimit=5 dataDir=/tmp/zookeeper2 clientPort=2181 server.1=127.0.0.1:7777:7778 server.2=127.0.0.1:6666:6667 server.3=127.0.0.1:5555:5556 4lw.commands.whitelist=* - zoo-node3.cfg
tickTime=2000 initLimit=10 syncLimit=5 dataDir=/tmp/zookeeper3 # 如果使用服务器可以指定相同的目录 clientPort=2181 server.1=127.0.0.1:7777:7778 server.2=127.0.0.1:6666:6667 server.3=127.0.0.1:5555:5556 4lw.commands.whitelist=*
启动zookeeper集群:
zkServer.h start conf/zoo-node1.cfg
zkServer.h start conf/zoo-node2.cfg
zkServer.h start conf/zoo-node3.cfg
启动成功之后,检查集群状态是否有异常
echo srvr | nc localhost 2181, nc是ncat命令的缩写是一个网络工具,mac上可以通过brew install nmap安装,安装完成需要将/usr/local/Cellar目录导入$PATH,否则无法直接使用命令。
└> echo srvr | nc localhost 2181
Zookeeper version: 3.5.8-f439ca583e70862c3068a1f2a7d4d068eec33315, built on 11/15/2020 03:27 GMT
Latency min/avg/max: 0/0/0
Received: 7
Sent: 6
Connections: 1
Outstanding: 0
Zxid: 0x100000006
Mode: follower
Node count: 5
如果执行以上命令出现
srvr is not executed because it is not in the whitelist.问题,则需要修改cfg配置,加入4lw.commands.whitelist=* 配置,打开四个字母的白名单。记得修改完配置重启zkServer.sh ,配置才能生效。
2. zookeeper的监控方法
zookeeper 虽然仅仅提供分布式的协调服务,但是仍然有自己的监控系统(一组监控命令),来让自己的运维系统更加完善。
接下来主要描述两种zookeeper原生支持的监控方式,第一种是four letters命令;第二种是JMX方式,这种方式后面的演示在mac上会更方便一点。
2.1 four letters命令
其中four letters 命令由四个字母组成,可以通过 telnet 或 ncat 使用客户端端口向 ZooKeeper 发出命令。
- ruok , 向zookeeper 集群的一个节点询问are you ok?
echo ruok | nc localhost 2181,向指定节点的client通信端口发送信息
如果回复imok%,则该节点正常,否则返回失败。这个状态并不是代表集群状态,仅仅是集群的某一个节点状态。
- conf , 查看节点配置项
echo conf | nc localhost 2181,输出如下clientPort=2181 secureClientPort=-1 dataDir=/tmp/zookeeper1/version-2 dataDirSize=67109438 dataLogDir=/tmp/zookeeper1/version-2 dataLogSize=67109438 tickTime=2000 maxClientCnxns=60 minSessionTimeout=4000 maxSessionTimeout=40000 serverId=1 initLimit=10 syncLimit=5 electionAlg=3 electionPort=7778 quorumPort=7777 peerType=0 membership: server.1=127.0.0.1:7777:7778:participant server.2=127.0.0.1:6666:6667:participant server.3=127.0.0.1:5555:5556:participant - stat, 返回当前server节点和客户端链接信息
echo stat | nc localhost 2181Zookeeper version: 3.5.8-f439ca583e70862c3068a1f2a7d4d068eec33315, built on 11/15/2020 03:27 GMT Clients:/127.0.0.1:53629[0](queued=0,recved=1,sent=0)Latency min/avg/max: 0/0/0 Received: 3 Sent: 2 Connections: 1 Outstanding: 0 Zxid: 0x100000006 Mode: follower Node count: 5 - dump, 查看zookeeper 中临时节点的信息
echo dump | nc localhost 2181SessionTracker dump: Global Sessions(1): 0x100077484570000 30000ms ephemeral nodes dump: Sessions with Ephemerals (1): 0x100077484570000:/worker Connections dump: Connections Sets (3)/(2): 0 expire at Sat Dec 12 12:43:33 CST 2020: 1 expire at Sat Dec 12 12:43:43 CST 2020:ip: /127.0.0.1:54091 sessionId: 0x0 1 expire at Sat Dec 12 12:43:53 CST 2020:ip: /127.0.0.1:54021 sessionId: 0x100077484570000 - wchc, 查看 watch状态信息
└> echo wchc | nc localhost 2181 0x100077484570000/worker
更多的四字命令如下:
conf: 打印ZooKeeper的配置信息
cons: 列出所有的客户端会话链接
crst: 重置所有的客户端连接
dump: 打印集群的所有会话信息,包括ID,以及临时节点等信息。用在Leader节点上才有效果。
envi: 列出所有的环境参数
ruok: "谐音为Are you ok"。检查当前服务器是否正在运行。
stat: 获取ZooKeeper服务器运行时的状态信息,包括版本,运行时角色,集群节点个数等信息。
srst: 重置服务器统计信息
srvr: 和stat输出信息一样,只不过少了客户端连接信息。
wchs: 输出当前服务器上管理的Watcher概要信息
wchc: 输出当前服务器上管理的Watcher的详细信息,以session为单位进行归组
wchp: 和wchc非常相似,但是以节点路径进行归组
mntr: 输出比stat更为详细的服务器统计信息
2.2 JMX 监控方式
接下来说一下JMX,ZooKeeper 很好的支持了 JMX ,大量的监控和管理工作多可以通过 JMX 来做。
而且能够将zookeeper的JMX数据集成到Prometheus,利用其来进行zookeeper的监控。
安装了JDK环境之后,JMX默认已经安装,只需要在终端运行jconsole命令(mac)即可启动
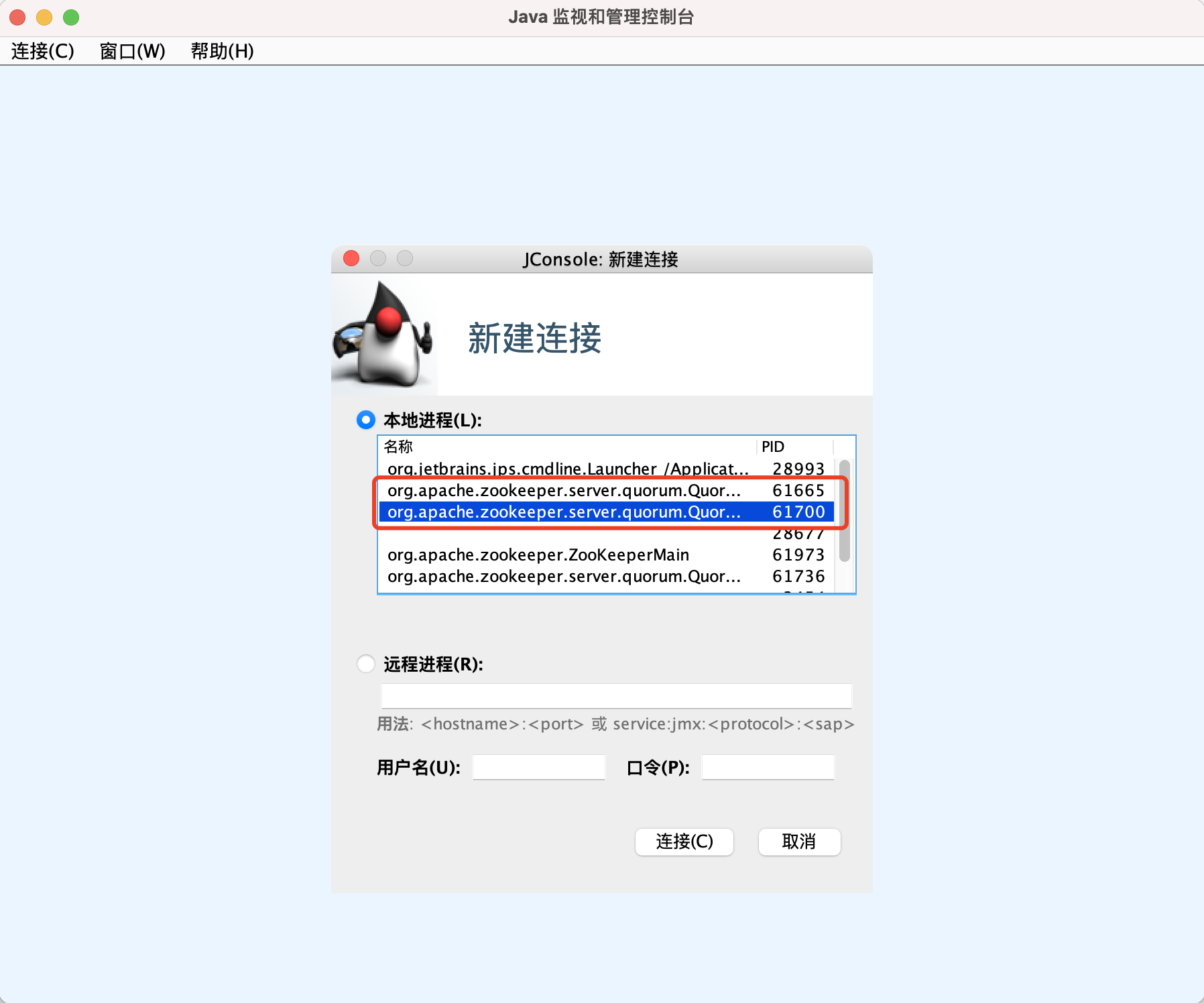
我的环境中已经有三个zkServer,所以会有三个server.quorum,任选一个即可。
直接点击连接,会弹出一个不安全连接的弹窗(因为我们并没有配置集群的ssl安全连接配置),所以这里直接选择 “不安全连接“即可
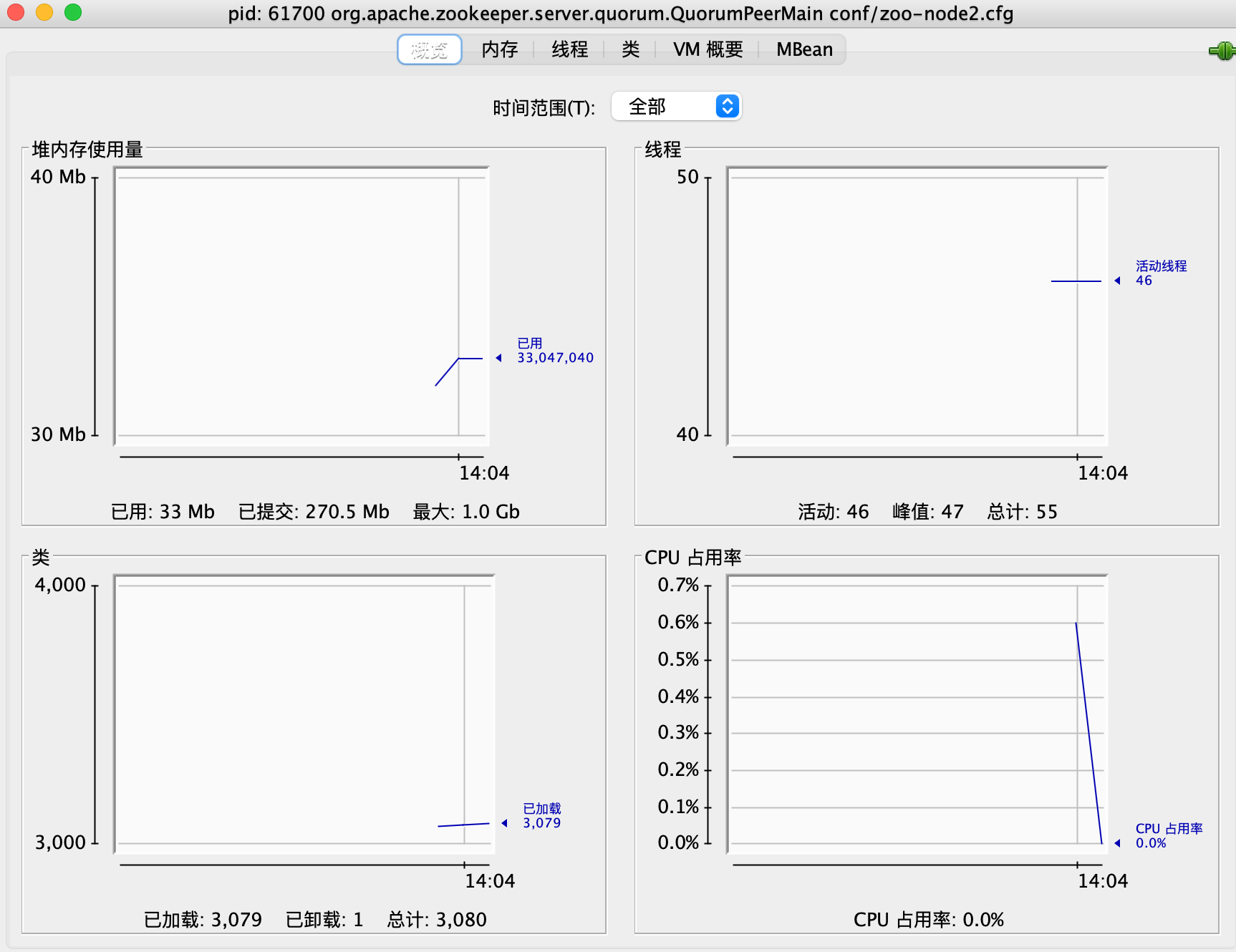
能够看到当前节点的 zookeeper server的资源消耗概览:
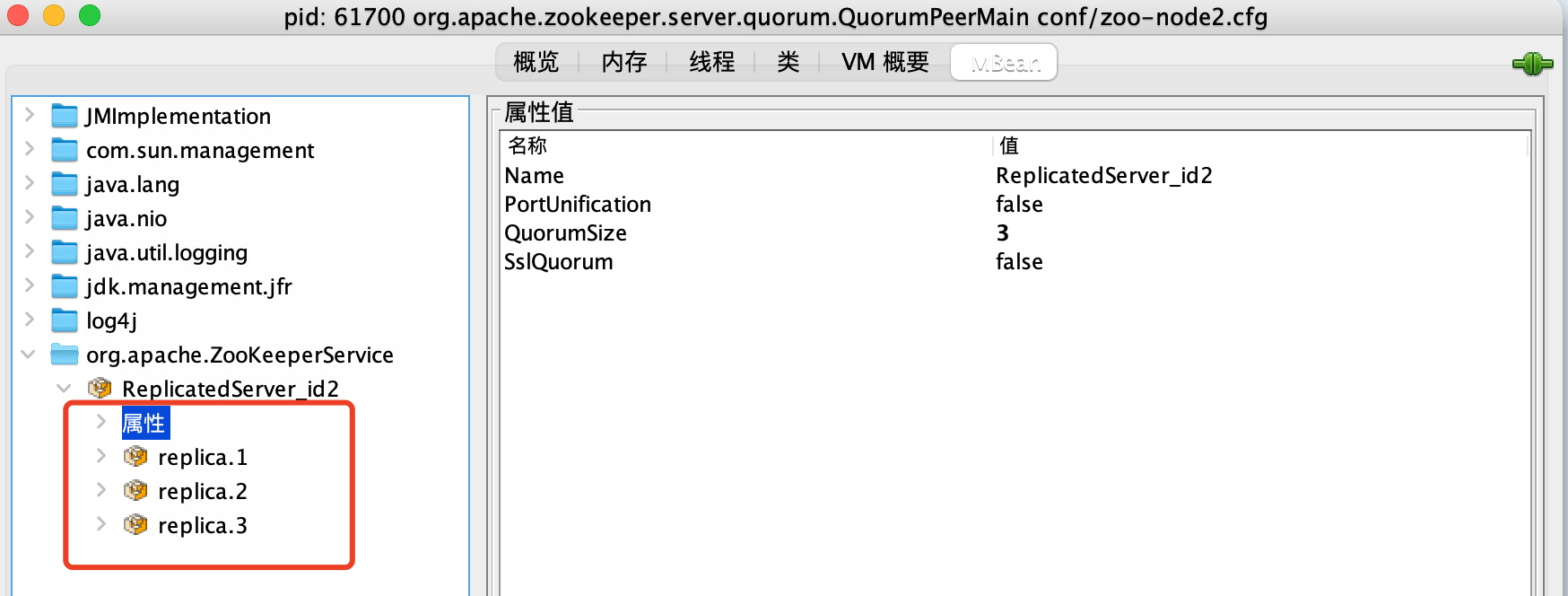
更加详细的节点细节数据可以通过进入MBean页面查看。
比如我使用zookeeper客户端做了如下操作:

原本在jconsole看到的节点个数的信息是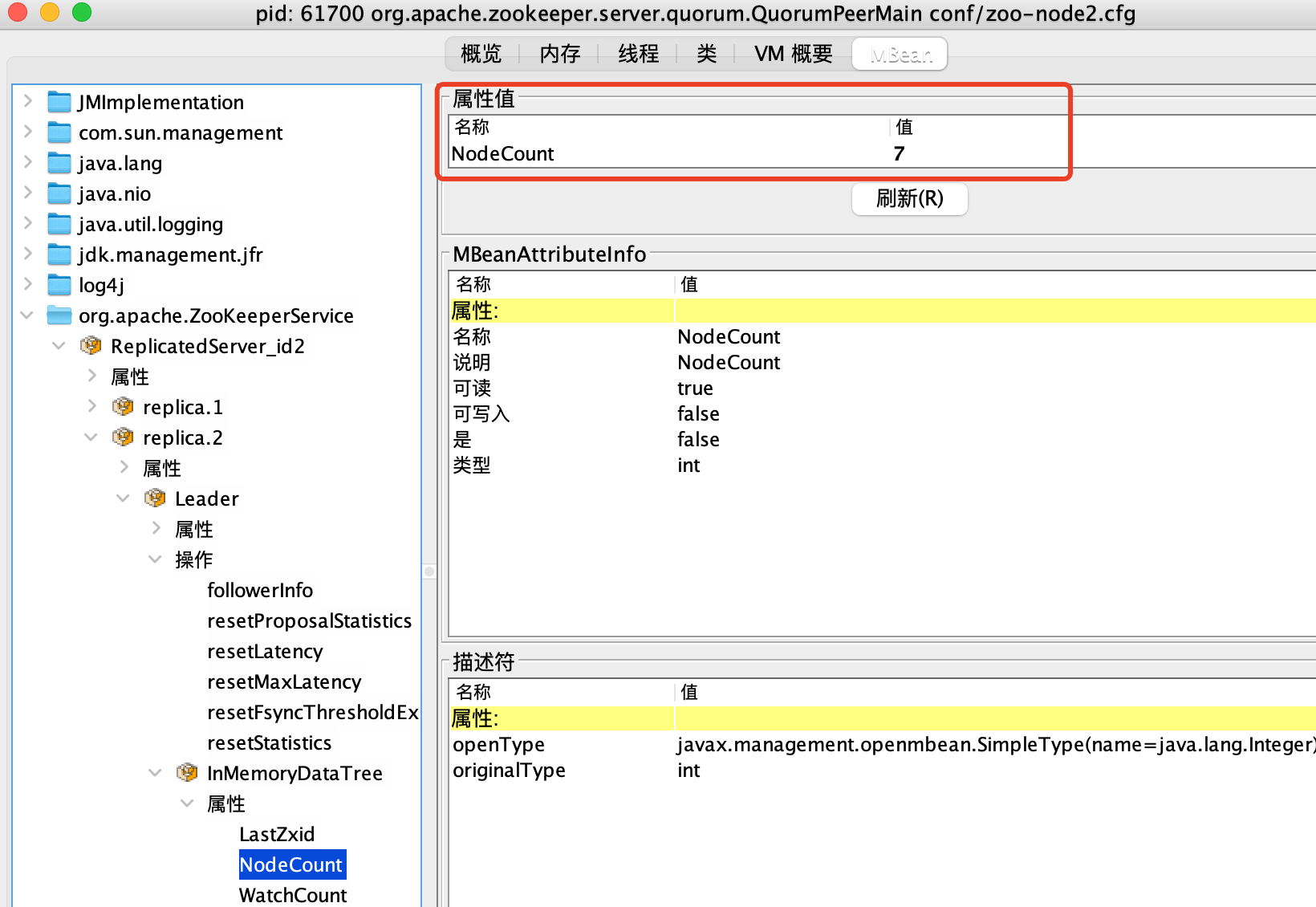
刷新后可以看到有变更:

以上的监控访问都是通过本地访问,现在jmx也能够支持远程访问,在被访问机器配置环境变量:
JMXPORT=8081
重启zookeeper server以及jconsole
然后在当前节点的jconsole连接窗口输入如下内容,仍然使用不安全的 连接方式即可访问远程节点的zookeeper数据。
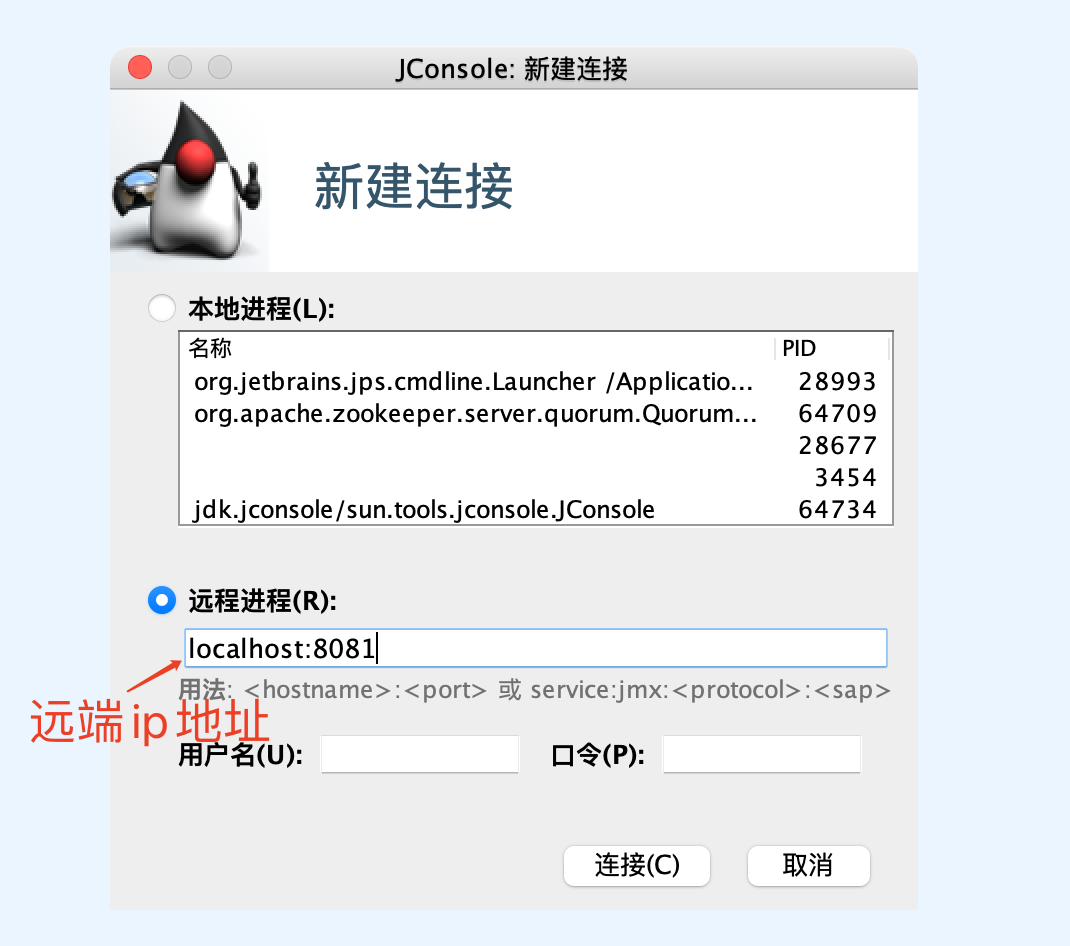
到此zookeeper的原生监控已经描述完毕,可以看到zookeeper的运维系统还是非常完善的,更加方便的监控就是结合jmx数据和premethus 完成更加完善全面的监控。
3. 通过zookeeper observer实现跨地域部署
3.1 什么是observer
就像是字面含义中所说的 观察者,不参与,不决策,万物皆可动,唯我心永恒。
它作为zookeeper集群中的一个角色而存在,和集群中其他节点的唯一交互就是接受来自leader的inform信息,更新到自己的本地存储,不参与集群中的事务提交,leader选举等过程。
下图为zookeeper写请求的时序图:
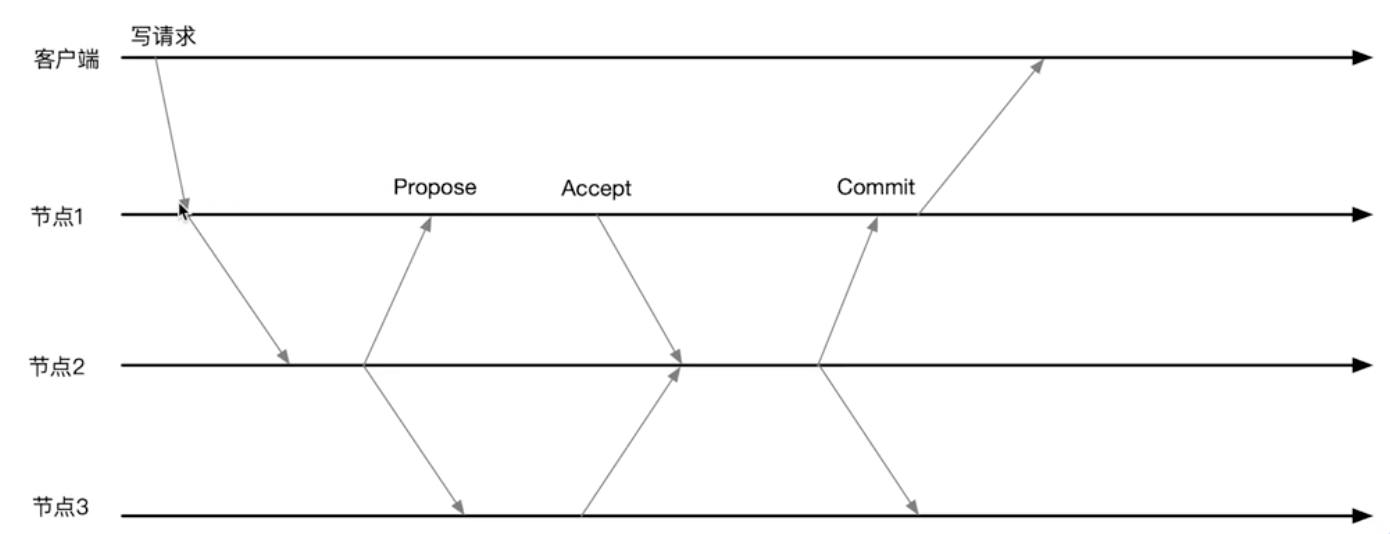
上图中:节点2: leader, 节点1和节点3都是follower
- 客户端提交写请求到其所连接的节点1
- 节点1 将请求转发给节点2(节点2是leader),只有leader可写
- 节点2 发送提案 给集群所有节点
- 节点2等待,只有有超过半数的节点回复,即可进行commit
- 节点1 收到commit消息,即可向客户端返回成功。
3.2 observer 提升 写性能
将节点1 设置为observer,这样能够减少网络rpc(一次propose和accept),减少磁盘I/O(只需要等待leader的通知返回客户端即可)
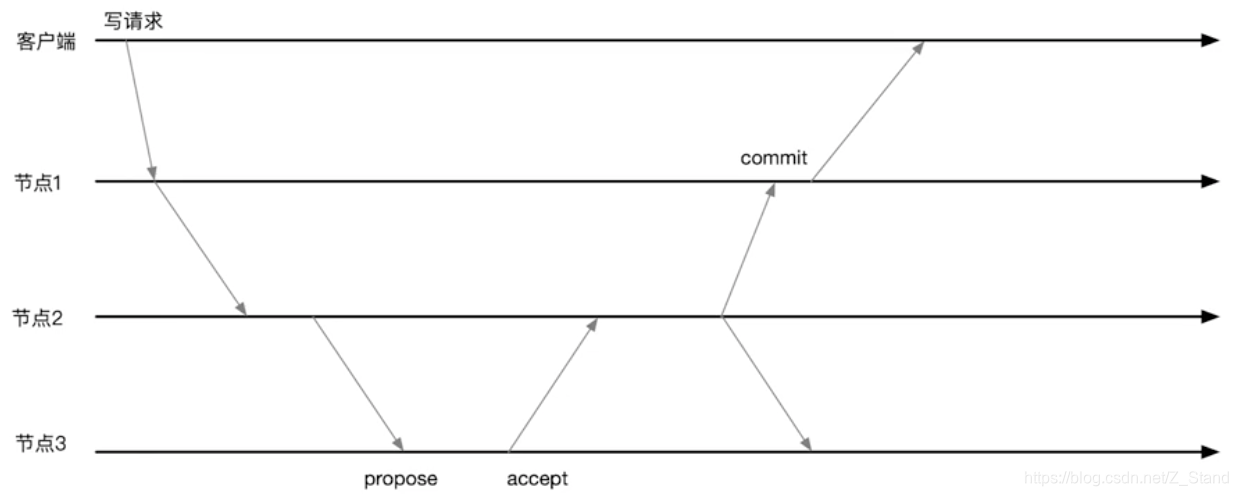
3.3 observer 实现跨数据中心部署
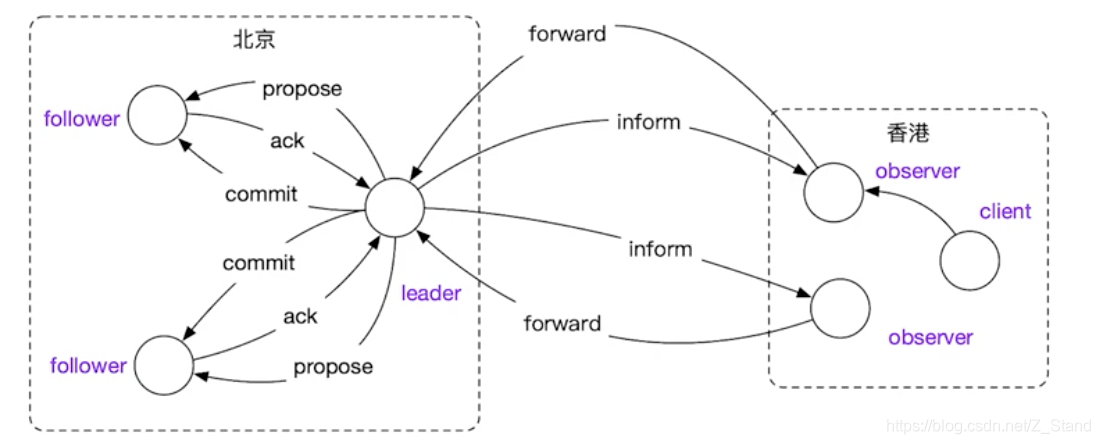
如上场景,整个集群包括leader节点在内有5个节点,其中北京有3个节点,香港有2个节点。
假如我们这5个节点的集群只有1个leader和其他4个follower,leader在北京,那么远在香港的两个follower每一次写请求都需要参与到整个集群的propose和accept,这两个rpc对于跨地域的集群部署来说代价非常大,会严重降低系统可用性和性能。
这个时候如上图,我们将香港的两个节点设置为observer,2个rpc就可以节省下来,observer只需要forward到leader 并接受leader的inform即可。
当然这样的集群部署模式在实际的场景还不如分成两个本地集群,从而降低网络分区对系统可用性的影响。
那么如何将一个节点部署成observer节点?
实际的部署配置可以 修改observer所在节点的zoo.cfg启动配置的集群选项配置如下:
server.1=127.0.0.1:7777:7778
server.2=127.0.0.1:6666:6667
server.3=127.0.0.1:5555:5556
server.4=127.0.0.1:3333:3334:observer #增加集群的配置选项,将当前节点指定为observer
4lw.commands.whitelist=*
启动第四个节点之后,通过echo srvr | nc $ip 2181 指定第四个ip的端口即可知道我们设置的角色是否成功(observer角色)。
4. zookeeper 不中断服务的集群成员变更方法
上文中我们也有关于调整集群成员的一些操作,总体步骤如下:
- 停止整个集群中所有的server
- 更改现有集群中所有server的cfg项中的server.n项(集群成员变更可能导致某一个节点已有数据被覆盖)
- 重新启动集群中所有的server
如果zookeeper集群达到一定规模,这一系列操作low且耗时,尤其是中断服务,降低系统可用性。
由于这种手动方式调整代价很高,所有zookeeper在3.5.0版本合入了 dynamic reconfiguration特性。
这个特性能够支持不停止zookeeper服务的前提下调整集群成员。
- 获取一个给super用的digest, 其中supper是zookeeper提供的认证机制。
运行代码即可生成一个digest认证package org.yao;import org.apache.zookeeper.server.auth.DigestAuthenticationProvider;/*** Generate digest for ZooKeeper super user authentication.*/ public class DigestGenerator {public static void main(String[] args) throws Exception {System.out.println(DigestAuthenticationProvider.generateDigest("super:z_stand"));} }xxx - 导入该认证到环境变量中
export SERVER_JVMFLAGS=-Dzookeeper.DigestAuthenticationProvider.superDigest=super:xxx - zookeeper配置文件
zoo-node2.cfg,将server.n相关配置放在了单独的配置文件中,因为后续动态修改的话是需要修改该文件的内容。
dyn.cfgtickTime=2000 initLimit=10 syncLimit=5 dataDir=/tmp/zookeeper2 clientPort=2181 4lw.commands.whitelist=* dynamicConfigFile=conf/dyn.cfgserver.1=127.0.0.1:7777:7778:participant;127.0.0.1:2181 server.2=127.0.0.1:6666:6667:participant;127.0.0.1:2181 server.3=127.0.0.1:5555:5556:participant;127.0.0.1:2181
所有节点的配置文件修改好之后可以将每个节点的server都启动起来。
- 开启客户端,这个客户端需要连接到我们第一步配置认证的那个节点上运行,当然这里是mac上模拟的,所以也就直接连接本地即可。
zkCli.sh -server localhost:2181 - 在客户端的交互命令行中 添加认证
addauth digest super:z_stand即可
接下来展示客户端交互命令如何动态配置节点情况config显示集群中的server配置reconfig -remove 3移除server.3config查看集群成员的变更情况reconfig -add server.4=127.0.0.1:3333:3334:participant;127.0.0.1:2181向集群中增加新的成员
到此集群成员的动态变更方式基本描述清楚了,感兴趣的同学可以尝试一下,需要注意的supper认证部分,zkCli.sh连接的server是需要完成认证的server节点。
5. zookeeper数据存储文件:事务文件和快照文件
zookeeper本地存储中的数据形态如下图:
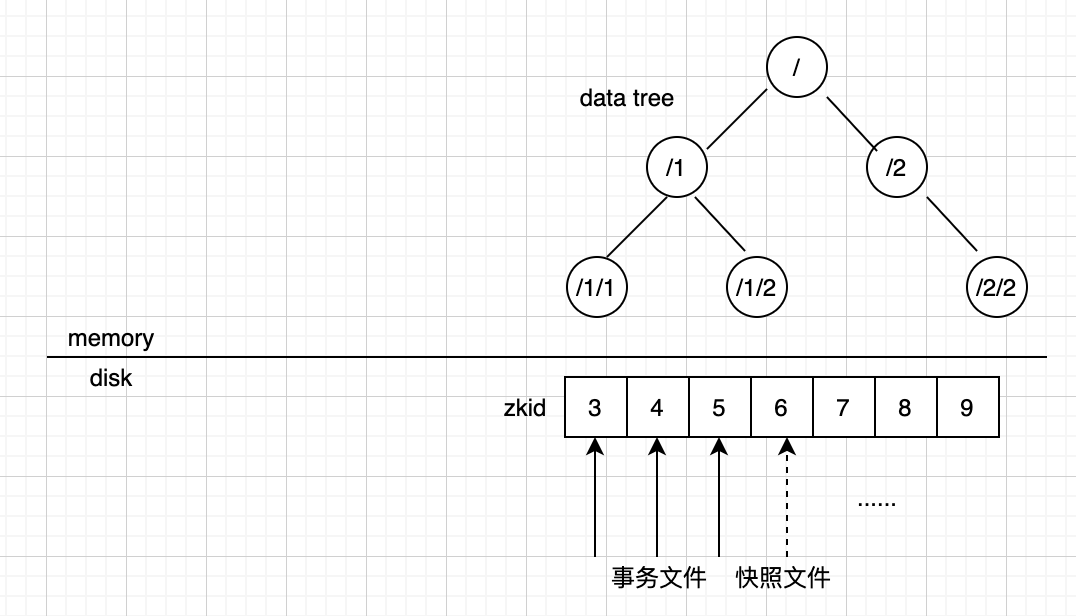
data tree 中的znode信息都是存放在内存中的
而磁盘上主要的是两种文件:事务文件和快照文件
事务文件中的entry是追加的,每一次有zookeeper集群的写入(创建znode,删除znode)都会作为事务更新到事务文件中。事务使用64位的整数zxid唯一标识,其中高四个字节是epoch,低四个字节是counter。
快照文件是当节点启动/重启时会创建一个文件
除此之外还会有两个文件:acceptedEpoch和currentEpoch分别保存当前集群的一些版本信息。
└> ls /tmp/zookeeper1/version-2
acceptedEpoch log.100000001 log.600000001 snapshot.0
currentEpoch log.400000001 log.a00000001 snapshot.600000001
zookeeper提供了工具能够查看其中的内容zkTxnLogToolkit.sh,可以看到如下信息
└> zkTxnLogToolkit.sh log.a00000001
/usr/bin/java
ZooKeeper Transactional Log File with dbid 0 txnlog format version 2
2020/12/12 CST 下午3:18:27 session 0x100080708e50000 cxid 0x0 zxid 0xa00000001 createSession 30000
2020/12/12 CST 下午3:37:55 session 0x100080708e50000 cxid 0x0 zxid 0xa00000002 closeSession
2020/12/12 CST 下午3:55:57 session 0x100080708e50001 cxid 0x0 zxid 0xa00000003 createSession 30000
EOF reached after 3 txns.
当对集群中的数据进行变更时这一些日志条目也会发生变更。
查看zookeeper的快照文件,这里zookeeper仅仅提供了一个类org.apache.server.SnapshotFormatter来查看,可以编写如下脚本snapshot.sh实现快照文件的查看:
#!/bin/bash
zkEnv.sh
export CLASSPATH="$CLASSPATH"
java org.apache.server.SnapshotFormatter "$@"
最后通过运行sh snapshot.sh /tmp/zookeeper3/version-2/snapshot.0来查看具体的快照文件内容。
ps: 只要zookeeper节点发生重启,或者启动 就会生成新的快照文件,记录当前状态下zookeeper的内存状态。
剩下的两个epoch文件acceptedEpoch和currentEpoch在单机模式下并不存在, 只有在集群模式下才会生成。
6. 总结
以上从zookeeper集群模式的搭建,到基本zookeeper监控,再到zookeeper实现跨地域部署的优缺点 以及 更加高级的 不中断服务的场景下实现集群成员变更。利用以上特性,我们能够很好的运维一个zookeeper集群。
对于更加底层的细节:zookeeper的读写流程 中如何保证集群写入的原子性(ZAB协议–multi paxos的一种变种),如何完成节点异常时的数据重放,这一些有趣的分布式细节会在后续讨论。
相关文章:
Java项目:电商书城平台系统设计和实现(java+springboot+mysql+spring+jsp)
源码获取:博客首页 "资源" 里下载! JAVA springboot 电商书城平台系统(已调试) 主要实现了书城网站的浏览、加入购物车操作、订单操作、支付操作、分类查看、搜索、以及后台上传图书信息以及订单管理和一些基本操作功能 主要功能截图如下&…

(周三赛)FATE
//题意 打怪的经验值 ,消耗忍耐度 看升级后还能保留的最大忍耐度 用 背包去做,不是很会啊 T T Description 最近xhd正在玩一款叫做FATE的游戏,为了得到极品装备,xhd在不停的杀怪做任务。久而久之xhd开始对杀怪产生的厌恶感&#…

ASP.NET MVC 3中ViewBag, ViewData和 TempData
ViewBag, ViewData十分类似,都可用于把数据从controller传递到view。 ViewBag是WebViewPage中的一个属性,它的类型是dynamic。dynamic类型可以理解为,编译器在编译到这种类型时,会跳过类型检查,而在运行时做这些事情。…

如何在指定文件夹下进入jupyter notebook
第一步: 打开 Anaconda Prompt 第二步: 查看文件夹所在路径 例如:你有个jupyterwork文件夹在 D:\ 路径下 第三步: 在Anaconda Prompt依次输入一下命令: d:cd jupyterworkjupyter notebook完成。转载于:https://www.cnb…

Go 分布式学习利器(16) -- go中可复用的package构建
通过本文,你将了解go 语言中如何将自己的package构建到项目中 以及如何将远程(github)的package构建到项目中。 1. 构建本地的package package 是可复用模块的基本单元,以首字母大写的函数实现来表明可被包外代码访问代码的pack…
JQuery UI
//拖拽插件 draggable <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns"http://www.w3.org/1999/xhtml"><head><title>拖曳…
Java项目:房屋租赁系统设计和实现(java+ssm+mysql+spring+jsp)
源码获取:博客首页 "资源" 里下载! 主要功能描述: 1.登录管理:主要有管理员登录和租客登录 2.房源列表以及添加房源功能: 3.租赁合同管理以及在租房源和已退租房源信息管理: 4.看房申请和退租申请管理&a…

学习网页制作中如何在正确选取和使用 CSS 单位
在 CSS 测量系统中,有好几种单位,如像素、百分比、英寸、厘米等等,Web 开发人员很难了解哪些单位在何处使用,如何使用。很多人习惯了总是使用同一种单位,但这一决定可能会严重限制你的设计的执行。 这里推荐的《Which …
SPOJ GSS3-Can you answer these queries III-分治+线段树区间合并
Can you answer these queries III SPOJ - GSS3 这道题和洛谷的小白逛公园一样的题目。 传送门: 洛谷 P4513 小白逛公园-区间最大子段和-分治线段树区间合并(单点更新、区间查询) 代码: 1 #include<bits/stdc.h>2 using namespace std;3 typedef long long l…

Zookeeper ZAB协议原理浅析
文章目录前言1. 基本角色和概念2. Leader Election3. Discovery4. Synchronization5. BroadCast后记前言 DTCC 要在下周一到周三要在北京举办,身边有不少人都去参加了,领略中国最为领先的一些公司的自研存储技术。 阿里自研polardb,polardb-…
Java项目:仓库管理系统设计和实现(java+ssm+springboot+layui)
源码获取:博客首页 "资源" 里下载! 主要功能模块 1.用户模块管理:用户登录、用户注册、用户的查询、添加、删除操作、 2.客户信息管理:.客户列表的展示、添加、修改、删除操作、 3.供应商管理:供应商详情…
Java Web 中的一些问题
http://localhost:8080/struts2demo/online/userLogin.jsp 请求模式 :// 主机名名称(或者服务器名称) : 端口 / Servlet容器的名称(通常为项目名称) / 自定义的网页文件夹名或者映射中的文件包名 / 网页名称及其后缀或者响应动作…

《零成本实现Web自动化测试--基于Selenium》第一章 自动化测试基础
第一篇 Selenium 和WebDriver工具篇 第一章 自动化测试基础 1.1 初识自动化测试 自动化测试有两种常见方式 1.1.1 代码驱动测试,又叫测试驱动开发(TDD) 1.1.2 图形用户接口测试: 测试框架产生用户接口事件(例如键盘敲击&#x…
第11章 AOF持久化
AOF持久化在硬盘上保存的是对Redis进行的逻辑操作,类似InnoDB中的bin log。说白了就是你对一个Redis输入了哪些语句,AOF文件都会原封不动的保存起来,等到需要回复Redis的时候再把这些语句执行一遍。 11.1 AOF持久化的实现 AOF简单的理解是把执…

Go 语言实现字符串匹配算法 -- BF(Brute Force) 和 RK(Rabin Karp)
今天介绍两种基础的字符串匹配算法,当然核心还是熟悉一下Go的语法,巩固一下基础知识 BF(Brute Force)RK(Rabin Karp) 源字符串:src, 目标字符串:dest; 确认dest是否是src 的一部分。 BF算法很简单暴力,维护两个下标…

Java项目:前后端分离网上手机商城平台系统设计和实现(java+vue+redis+springboot+mysql+ssm)
源码获取:博客首页 "资源" 里下载! 主要模块设计如下: 前后端主要技术:Java springboot springMVC mybatis mysql vue jquery node.js redis 1) 用户注册和登录功能:。 2) 用户信息的管理以及角色的…

利用AutoSPSourceBuilder和Autospinstaller自动安装SharePoint Server 2013图解教程——Part 1...
这是一篇对之前 《利用AutoSPSourceBuilder和Autospinstaller自动安装SharePoint Server 2013图解教程——Part 2》的补充。本篇博客将对AutoSPSourceBuilder的使用进行说明。 AutoSPSourceBuilder介绍 下载AutoSPSourceBuilder点击进入AutoSPSourceBuilder的官网,找…

Git 版本还原命令
转载:https://blog.csdn.net/yxlshk/article/details/79944535 1.需求场景: 在利用github实现多人协作开发项目的过程中,有时会出现错误提交的情况,此时我们希望能撤销提交操作,让当前版本回到提交前的样子或者某一个版…
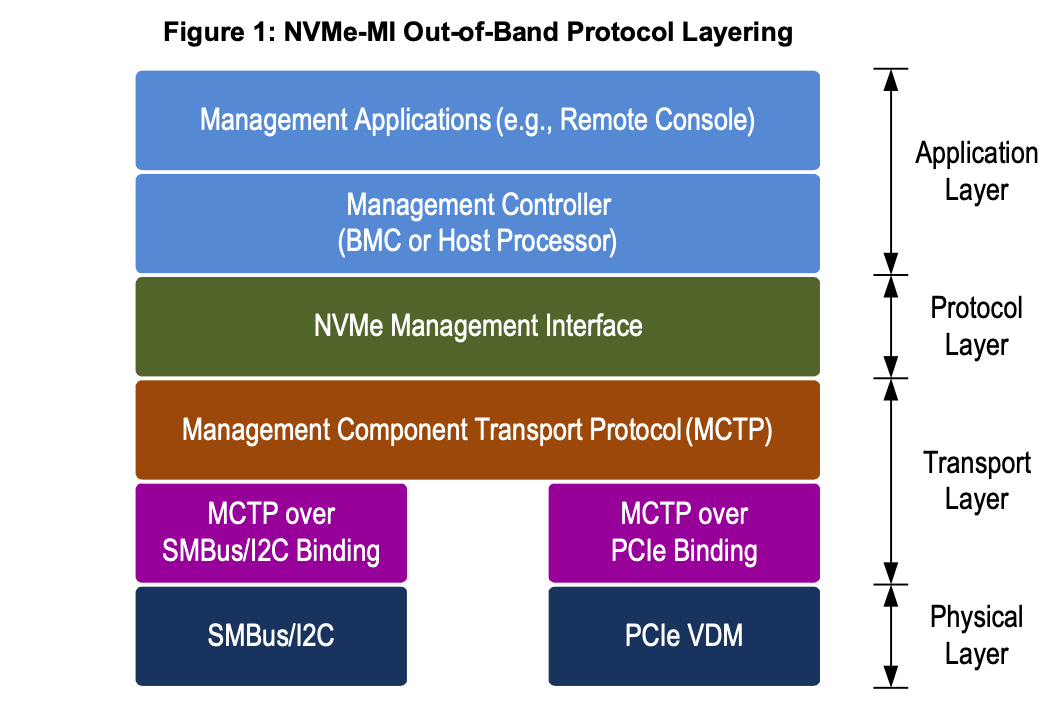
NVME CLI -- nvme 命令查看NVME设备内部状态
文章目录NVME 和 AHCI 性能比较NVME-CLI nvme工具使用1. 安装2. 命令综述3. 基本命令演示4. NVME 固件设备升级近期在做一些rocksdb on 新硬件的性能测试(flash ssd, nvme ssd , nvme optane ssd, optane persistent memory),由于底层一些设备…
Java项目:网上水果蔬菜项目系统设计和实现(java+springboot+mysql+ssm)
源码获取:博客首页 "资源" 里下载! 主主要技术:java springmvc springboot mybatis mysql jquery layui 等技术要模块设计如下: 用户角色的功能: 登录、注册、浏览商品、修改个人信息(上传…
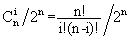
POJ 1189 记忆化搜索
钉子和小球Time Limit: 1000MS Memory Limit: 10000KTotal Submissions: 7218 Accepted: 2164Description 有一个三角形木板,竖直立放,上面钉着n(n1)/2颗钉子,还有(n1)个格子(当n5时如图1)。每颗钉子和周围的钉子的距离都等于d&am…
Android短信管家视频播放器代码备份
自己保留备份,增强记忆 这是video的类 public class VideoActivity extends Activity {/*** 解析网络页面*/private WebView wv;/*** 进度条类*/private ProgressDialog pd;/*** 异步处理消息*/private Handler handler;private static final int SHOW 0;private s…
Python常用函数--文档字符串DocStrings
Python 有一个甚是优美的功能称作python文档字符串(Documentation Strings),在称呼它时通常会使用另一个短一些的名字docstrings。DocStrings 是一款你应当使用的重要工具,它能够帮助你更好地记录程序并让其更加易于理解。令人惊叹…
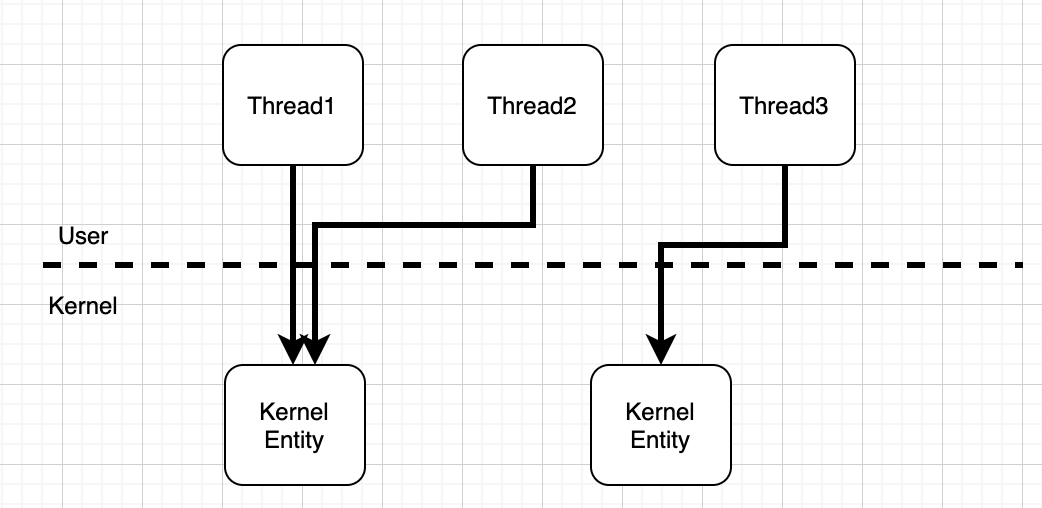
Go 分布式学习利器(17)-- Go并发编程之协程机制:Grountine 原理及使用
文章目录1. Thread VS Groutine2. Groutine 调度原理3. Groutine 示例代码关于Go的底层实现还需要后续持续研究,文中如有一些原理描述有误,欢迎指证。 1. Thread VS Groutine 这里主要介绍一下Go的并发协程相比于传统的线程 的不同点: 创建…
Java项目:美食菜谱分享平台系统设计和实现(java+springboot+mysql+ssm)
源码获取:博客首页 "资源" 里下载! 主要技术实现:spring、 springmvc、 springboot、mybatis 、session、 jquery 、 md5 、bootstarp.js tomcat、拦截器等。 具体主要功能模块如下: 1.用户模块管理:用户…
【leetcode】Roman to Integer
题目描述: Given a roman numeral, convert it to an integer. Input is guaranteed to be within the range from 1 to 3999. 解题思路: 首先我们要了解罗马数字怎么写的 个位数举例 I, 1 】II, 2】 III, 3】 IV, 4 】V, 5 】VI, 6】 VII, 7】 VIII,8 】…
Apache Traffic Server管理工具
Traffic Line是命令行程序,可以用来快速监视 Traffic Server 的性能和网络流量,也能配置 TS。Traffic Shell也是命令行工具,进入该 shell 后有自己一套语法,可代替 Traffic Line 完成监控、配置任务。通过 Traffic Line 和 Traffi…
npm使用记录
npm是一个 包管理工具。安装node之后就可以使用npm命令了,为了方便使用,通常我们还要装下 淘宝NPM镜像,之后就可以用cnpm命令了。 注意:以下提到的如-g --save等标签都可以放在 包名前面。 首先一个前端项目下载下来,需…
Go 分布式学习利器(18)-- Go并发编程之lock+WaitGroup实现线程安全
Go语言中通过Groutine 启动一个Go协程,不同协程之间是并发执行的,就像C/Java中线程之间线程安全是一个常见的问题。 如下Go 语言代码: func TestConcurrent(t *testing.T) {var counter int 0for i : 0;i < 5000; i {go func() { // 启动groutine 进…

Java项目:网上家具商城平台设计和实现(java+springboot+mysql+ssm)
源码获取:博客首页 "资源" 里下载! 主要技术:springmvc springboot mybatis mysql jquery layui 等技术 具体功能模块: (1) 用户注册和登录登录功能: ①用户的注册功能 : 访问网站的人根据网站的提示注册…