Rocksdb的事务(二):完整事务体系的 详细实现
文章目录
- 1. 基本事务操作
- 1.1 TransactionDB -- Pessimistic
- 1.2 OptimisticTransactionDB
- 1.3 Read Uncommitted
- 1.4 SavePoint 回滚部分事务操作
- 1.5 SetSnapshot
- 1.6 GetForUpdate
- 1.7 RepeatableRead
- 2. 实现
- 2.1 WBWI(write batch with index) & WB(write batch)
- 2.2 PessimisticTransaction 实现
- 2.3 LockManager 以及 DeadLock detect 实现
- 2.3.1 LockManager 加锁实现
- 2.3.2 DeadLock 检测实现
- 2.4 OptimisticTransaction
- 2.4.1 kValidateSerial occ
- 2.4.2 kValidateParallel occ
- 3. 总结
很久之前简单介绍了Rocksdb 事务的基本隔离性的应用以及简单实现的描述 Rocksdb 事务: 隔离性的实现(一),其实里面有一些问题描述的非常模糊,对底层事务的实现细节讲解得也不够精确且也没有形成递进体系,所以今年年尾的最后一篇博客希望能够将 Rocksdb 的事务体系描述清楚,能够有效帮助做数据库的同学了解事务的基本实现(基本的隔离级别的实现 rc、ru、si,分布式事务保证原子性的2PC 以及 事务周边的rollback,死锁检测/死锁避免 等都是如何做到的 ),更重要的是能够看到大规模工业应用之后的事务所暴露出来的问题 和 这一些问题对应的优质解决方案,从而能够让我们将这一些思想灵活得借鉴到大规模的工业分布式环境之中。
接下来将详细展开,以及在LSM-tree 模型下实现事务过程中存在的一些问题和对应的优化策略。
因为LSM-tree的 append模型,天然支持多版本,而且拥有WriteBatch 可以将多个版本的请求都缓存在内存中,从而更有利得解决并发事务下的读写冲突和写写冲突问题。
本文涉及到的源代码对应的 rocksdb 版本是 6.25
1. 基本事务操作
Rocksdb 的事务实现 主要是通过TransactionDB 默认是(Pessimistic) 和 OptimisticTransactionDB 来提供事务操作。
1.1 TransactionDB – Pessimistic
使用 TransactionDB 进行事务操作,默认是 PessimisticTransactionDB,每次事务更新操作都会进行加锁,会去检测是否和其他事务有冲突。即 txn1 更新一个key1时会对当前key加锁,事务txn2 在 txn1 提交前尝试更新这个key1 则会失败。
TransactionDB* txn_db;
TransactionDBOptions txndb_opts;
TransactionOptions txn_opts;Options opts;
std::string value;opts.create_if_missing = true;
opts.compression = kNoCompression;Status s = TransactionDB::Open(opts, txndb_opts, "./txn_db", &txn_db);
PrintStatus("TransactionDB::Open", s);// 开启事务
Transaction* txn = txn_db->BeginTransaction(WriteOptions(), txn_opts);
assert(txn != nullptr);PrintStatus("txn->Put", txn->Put("key1", "value1"));
/// 其他事务尝试更新这个key1,则更新失败,会有锁超时问题
PrintStatus("txn_db->Put", txn_db->Put(WriteOptions(), "key1", "value2"));
// 最终的事务提交
PrintStatus("txn->Commit", txn->Commit());
1.2 OptimisticTransactionDB
在乐观事务下,不同事务之间的冲突检测不会在每次更新操作时候进行检测,而是在事务提交的时候进行。
/*OptimisticTransactionDB test*/
OptimisticTransactionDB* optimize_txn_db;
OptimisticTransactionOptions opti_txn_opts;
OptimisticTransactionDBOptions opti_txn_db_opts;PrintStatus("OptimisticTransactionDB::Open",OptimisticTransactionDB::Open(opts, "./opti_txn_db", &optimize_txn_db));// 开启乐观事务
Transaction* opti_txn = optimize_txn_db->BeginTransaction(WriteOptions(), opti_txn_opts);
assert(opti_txn != nullptr);// 当前事务更新 key1
PrintStatus("opti_txn->Put", opti_txn->Put("key1", "value1"));
// 外部事务在当前事务期间更新了 同样的 key1 ,这里会成功
PrintStatus("optimize_txn_db->Put", optimize_txn_db->Put(WriteOptions(), "key1", "value2"));
// commit 失败
PrintStatus("opti_txn->Commit", opti_txn->Commit());
悲观事务 和 乐观事务主要就是冲突检测的位置不同,所以悲观事务 在事务冲突概率较高的场景下能够保证提前发现冲突而更早的触发冲突事务的回滚。在冲突概率不高的情况下,悲观事务每一个更新(Put,Delete,Merge,GetForUpdate)都会做冲突检测,会引入较多的竞争开销,从而降低性能,所以冲突概率不高的场景可以尝试乐观事务DB。
1.3 Read Uncommitted
这个不是 rocksdb支持的隔离级别,rocksdb 默认只支持 RC 和 Repeatable Read
不同的事务之间只能读到事务已经提交的数据,同一个事务内部,能够读到未提交的数据。
// 事务写入key1
PrintStatus("txn->Put", txn->Put("key1", "value1"));
// 读到key1 的结果是 value1
PrintStatus("txn->Get", txn->Get(ReadOptions(), "key1", &value));
PrintStatus("txn->Delete", txn->Delete("key1"));
// Notfound
PrintStatus("txn->Get", txn->Get(ReadOptions(), "key1", &value));
因为未提交的事务都会在一个WriteBatch中,这样当前事务内部按照操作顺序能够看到当前操作之前的所有操作。
1.4 SavePoint 回滚部分事务操作
Transaction 提供了回滚当前事务部分操作的能力,在事务中间的某一个位置设置一个 SavePoint,后面能会滚到这个位置。
// 当前事务写入
PrintStatus("txn->Put", txn->Put("key1", "value1"));
// 设置回滚点
txn->SetSavePoint();
// 删除
PrintStatus("txn->Delete", txn->Delete("key1"));
// 尝试读,读不到,已经被删除了
PrintStatus("txn->Get", txn->Get(ReadOptions(), "key1", &value));
// 回滚
txn->RollbackToSavePoint();
// 此时能够读到
PrintStatus("txn->Get", txn->Get(ReadOptions(), "key1", &value));
1.5 SetSnapshot
之前有描述,事务DB 会对每一个更新的key 进行加锁,保证后续其他事务对 相同key的更新是失败的。如果用户想要在事务一开始的时候就标识 后续所有写入的key 都要进行独占,那可以通过 开启事务之后设置一个 SetSnapshot 来进行后续当前事务 会独占所有标识的key,减少一部分的冲突检测逻辑。
SetSnapshot 之前 我们下面的逻辑是正常的:
Transaction* txn = txn_db->BeginTransaction(WriteOptions(), txn_opts);
assert(txn != nullptr);
// 即使外部的事务操作成功,因为是在当前事务更新之前更新的,并没有冲突
PrintStatus("txn_db->Put", txn_db->Put(WriteOptions(), "key1", "value3"));
PrintStatus("txn->Put", txn->Put("key1", "value1"));PrintStatus("txn->Commit", txn->Commit());
通过 SetSnapshot 标识 之后所有的更新都被当前事务独占,上面的外部事务更新就会失败。
Transaction* txn = txn_db->BeginTransaction(WriteOptions(), txn_opts);
assert(txn != nullptr);
txn->SetSnapshot();
// 即使外部的事务操作是在当前事务操作之前进行更新,这里也会失败(对setsnapshot 之后所有的操作,当前txn都会独占)
PrintStatus("txn_db->Put", txn_db->Put(WriteOptions(), "key1", "value3"));
PrintStatus("txn->Put", txn->Put("key1", "value1"));
// 乐观事务 会在 Commit 的时候失败
PrintStatus("txn->Commit", txn->Commit());
悲观事务 DB 和乐观 事务DB的差异是 悲观事务DB的 在设置了snapshot之后的check 会在有操作的时候报出来;乐观事务DB 则会在 commit 的时候报出来。
1.6 GetForUpdate
有的时候我们 一个事务内部 需要对某一个key 做RMW操作 即 读改写,并且保证这个操作是原子的。也就是不能仅仅在写的时候才独占这个key,应该在读的时候就需要独占,才能保证后续当前事务的写是原子的。 即读写冲突的检测,Rocksdb 目前仅能通过 GetForUpdate 来进行读写冲突的检测。
这个时候,就需要 GetForUpdate 接口,保证读的时候就独占这个key
txn = txn_db->BeginTransaction(write_options);// 当前事务 独占key1
Status s = txn->GetForUpdate(read_options, “key1”, &value);// 外部事务 更新 会失败
s = db->Put(write_options, “key1”, “value0”);
当然,对于 悲观事务DB 来说 也是提交前就进行冲突检测,乐观事务DB则在 Commit的时候进行冲突检测。
1.7 RepeatableRead
可重复读 的隔离级别 是一个比较重要的操作,用户希望能一直读到一个版本之前的数据 而不用担心这个版本之后的更新产生对结果的影响。
TransactionOptions txn_opts;
ReadOptions rops;Transaction* txn = txn_db->BeginTransaction(WriteOptions(), txn_opts);
assert(txn != nullptr);
PrintStatus("txn->put", txn->Put("key1", "value2"));
PrintStatus("txn->Commit", txn->Commit());// 开启设置snapshot,标识后续该事务 对所有自己更新的key都是独占的
txn_opts.set_snapshot = true;
txn = txn_db->BeginTransaction(WriteOptions(), txn_opts);
assert(txn != nullptr);// 在其他事务更新之前设置一个snapshot
const Snapshot* snapshot = txn->GetSnapshot();
PrintStatus("txn_db->Put", txn_db->Put(WriteOptions(), "key1", "value3"));// 普通的读,能够读到value3
PrintStatus("txn->Get", txn->Get(rops, "key1", &value));// snapshot 读,读到的是value2
rops.snapshot = snapshot;
PrintStatus("txn->Get", txn->Get(rops, "key1", &value));
2. 实现
2.1 WBWI(write batch with index) & WB(write batch)
在看具体事务实现之前需要先整体了解一下 WB 以及 WBWI,也就是write batch 和 write batch with index 这两个为 引擎的更新操作提供的组件。
WB 这里不用说太多,使用基础DB 的时候经常能够用到,Put 这样的更新接口被调用后会组织成一个WriteBatch 数据结构,将多个更新操作合并成一个请求,从而能够进行原子提交。
事务DB中,我们使用常见好的事务DB 直接Put (默认是PermisticDB,也会先构造WriteBatch,在commit 的时候进行原子提交)。
这里的WB 数据结构形态大概如下:
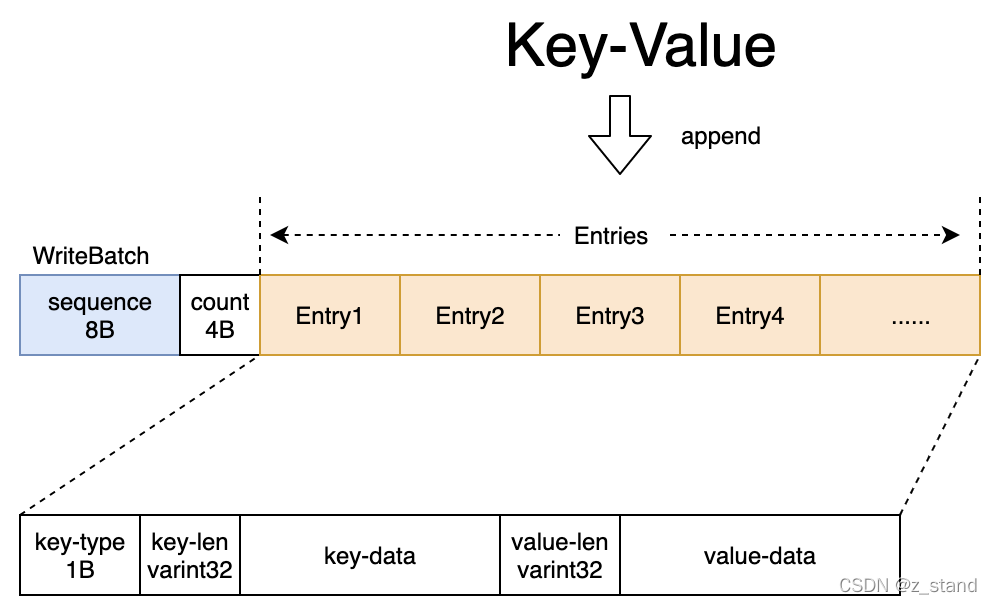
整体是一个string-buf,将一个一个k/v请求拼接进去,比较简单,这里就不过多介绍了。
主要介绍的是 为事务功能提供的 WBWI,wirte batch with index。其在WriteBatch 基本结构的基础上构造了一个skiplist,用来提供 事务操作过程中的 read-your-write 以及 savepoint/rollback 等这样的基本功能。
事务如果没有提交,所有的数据都还没有写入到memtable,都被缓存在WBWI之中。txn->Put 的时候 TryLock 完成之后会去更新WBWI,除了append write-batch 的 string-buffer 之外,会将这个请求在 wb中的offset/cf/key-offset/key-size 这样的信息形成一个 writeIndexEntry 插入到单独维护的跳表之中。这个时候,后续的 txn->Get 就能够有效得读到之前写入但是还没有提交的请求,其体结构如下:
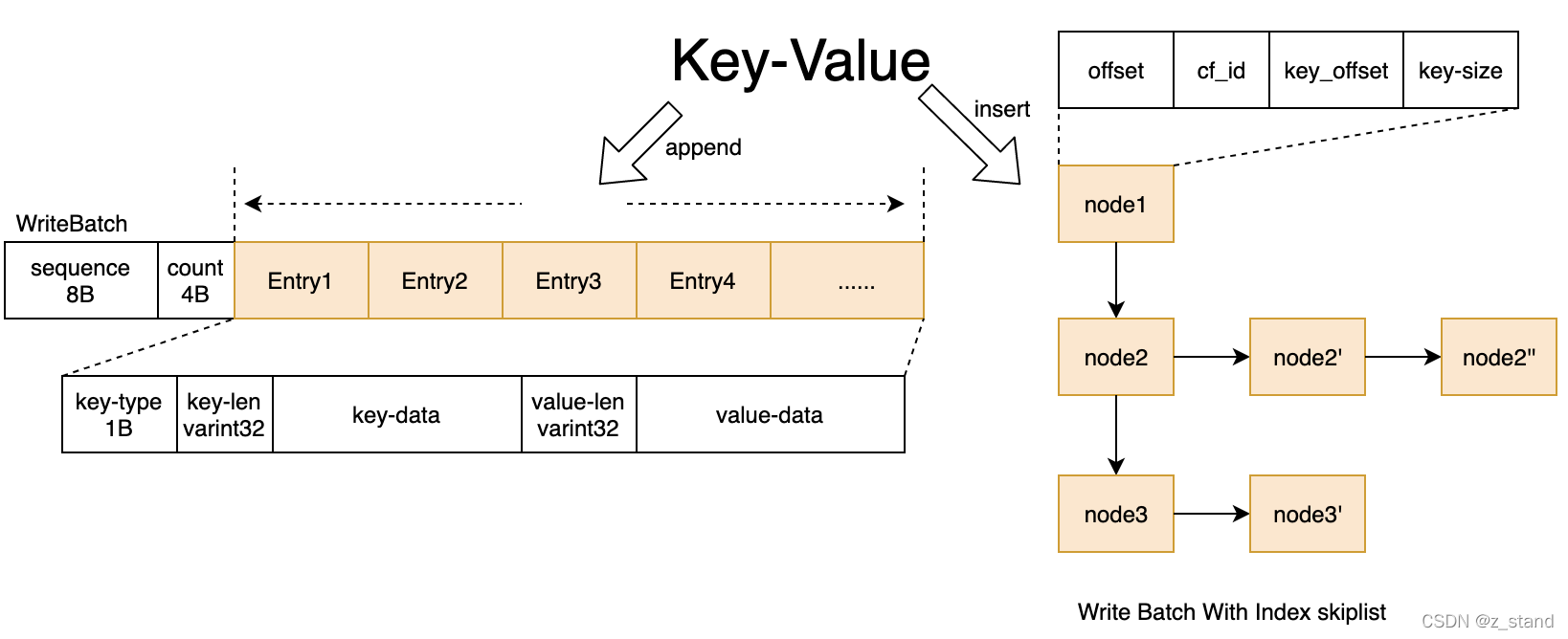
我们的 txn->SetSavePoint 函数会将 当前 WriteBatchWithIndex 中的信息保存到一个 std::stack<SavePoint, autovector<SavePoint>> stack;,当前事务经过若干操作之后 后续的 txn->RollbackToSavePoint() 会进行弹栈,并将之前保存的状态信息更新到现在的WBWI 之中,从而达到事务的回滚的目的。
SetSavePoint 和 RollbackToSavePoint 函数的逻辑分别在:void WriteBatch::SetSavePoint() ,WriteBatch::RollbackToSavePoint 之中。
因为WBWI 是在BeginTransaction 的时候构造的,所以每一个事务会有一个自己独立的WBWI,其内部的数据结构不需要考虑同步问题。
2.2 PessimisticTransaction 实现
从之前的API 接口测试中,我们能够知道 PessimisticTransaction 和 OptimisticTransaction 的主要差异是在事务冲突检测的时机上,PessimisticTransaction 在事务有更新操作 或者 GetForUpdatae 的时候就会尝试进行Key 的独占,并进行相应的冲突检测。
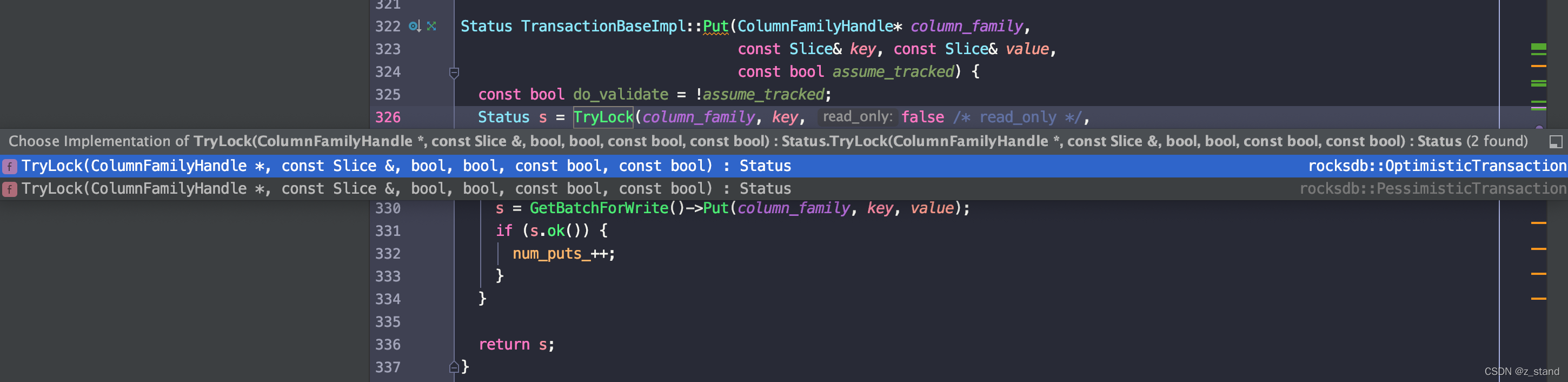
可看到在 Transaction::Put 的时候会根据上层配置的transactionDb类型来标识应该选择哪一种 TryLock机制,默认是 PessimisticTransaction。TryLock 之后就会更新到 WBWI 之中。
接下来主要看一下 PessimisticTransaction 的 TryLock 是如何实现key 独占 以及 冲突检测的。
如果用户配置了 TransactionOptions::skip_concurrency_control=true 的话,这里后面的key 独占以及冲突检测都会直接跳过。
前提是:
- 需要应用自己保证 不会有key冲突
- 需要应用保证recovery 的时候所有的回滚和commit 操作 都会新的事务启动之前就完成。
这种情况下的性能肯定是最好的, 不过一致性就得自己保证了(应用有自己的事务体系,只用到了Rocksdb的部分事务能力)。
对输入的key 的独占逻辑如下:
PessimisticTransaction::TryLockPessimisticTransactionDB::TryLockPointLockManager::TryLock
比较老的版本 ,最后key 的加锁过程入口是 TransactionLockMgr::TryLock,这里重构成了 PointLockManager::TryLock,主体逻辑都比较接近,主要是通过LockMgr 来实现,这里后面会详细介绍,先关注主体实现。
到这里当前事务的 当前key 的就加锁成功了,会独占这个key,直到这个事务 Commit 之前其他的事务都是无法修改这个key,而其他的事务在这个事务独占成功 但未 提交之前也会进入 上面的TryLock 逻辑之中,会尝试等待这个 key的锁释放,直到超时。
回到 PessimisticTransaction::TryLock 逻辑中,前面的加锁是为了标识这个key 后续不允许其他事务的修改。但是如果我们在事务的一开始就设置了 txn->SetSnapshot,则当前事务后续所有的更新操作都会默认独占。可能有这样的情况,就是在 SetSnapshot 之后 Put之前 外部事务可能对这个key 进行了修改并commit,这样就不满足Snapshot的语义了(一个事务设置snapshot之后 不允许其他事务的更新),这里当前事务后续的提交需要失败才行,PessimisticTransaction::TryLock 后面的逻辑就是为了做一些冲突检测。
一个简略的时序图场景如下:
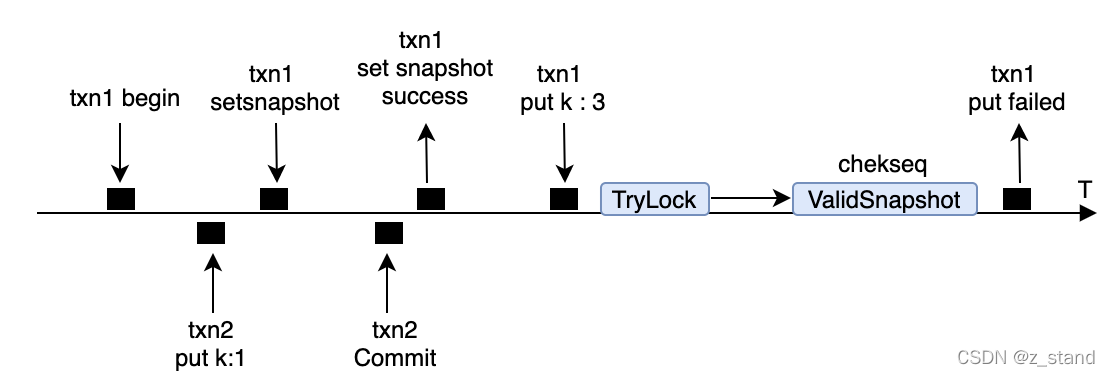
因为 SetSnapshot 操作需要创建Snapshot 并将这个snapshot 插入到全局的双向链表之中,所以会存在一种可能性就是txn1完成snapshot 之前 txn2 写入并提交了一个新的更新。这个时候,txn1 继续 Put的话需要语义上失败。具体过程就是通过 ValidSnapshot 函数 check txn1 开始时 拿到的最新的 seq 和 现在db 中已经提交的最新的seq ,如果小的话txn1 就应该失败。
具体检查的过程就是 从version 系统中 取一个local_version ,直接暴力遍历这个version 中的 mem/imm,imm-list/sst ,拿到当前冲突key 一个最新的seq即可。
逻辑如下:
PessimisticTransaction::ValidateSnapshotTransactionUtil::CheckKeyForConflictsTransactionUtil::CheckKeyDBImpl::GetLatestSequenceForKeysv->mem->Getsv->imm->Getsv->imm->GetFromHistorysv->current->Get
其中哪一步成功了,就直接返回,不需要后续的读了,越靠近上层的key-seq 越新。
做完 ValidateSnapshot ,如果当前事务冲突检测通过了,则继续后续的 WBWI 的更新即可。
到此,整个 PessimisticTransaction 大体 更新逻辑就是这样的了。
至于 Get 接口,则是直接从 WBWI 中读取就好了,调用 WriteBatchWithIndex::GetFromBatchAndDB 就好了;
还有 GetForUpdate 和 更新的逻辑差不多,也是需要先做完 TryLock 和 ValidateSnapshot 的检测才继续后续的读取。
需要注意的是 我们在txn->SetSnapshot 之后 外部事务更新 且 后续的 txn->Get 是没有问题的,但是 如果读取使用的是 GetForUpdate ,则会检测 read-write confict ,GetForUpdate 会失败;它要求的一致性语义 和 write-write confict 要求的是一样的。
2.3 LockManager 以及 DeadLock detect 实现
2.3.1 LockManager 加锁实现
在 PessimisticTransaction 的 TryLock 底层,我们会发现当前事务想要给 key加锁(保证 commit 之前对key 的独占语义 )是通过 LockManager 实现的,接下来仔细看一下这个组件的实现原理,以及其如何进行死锁检测的。
后文描述的 OptimisticTransaction 事务 因为 TryLock 过程不需要检测锁冲突,所以不需要用到LockManager.
LockManager 组件结构大概如下:
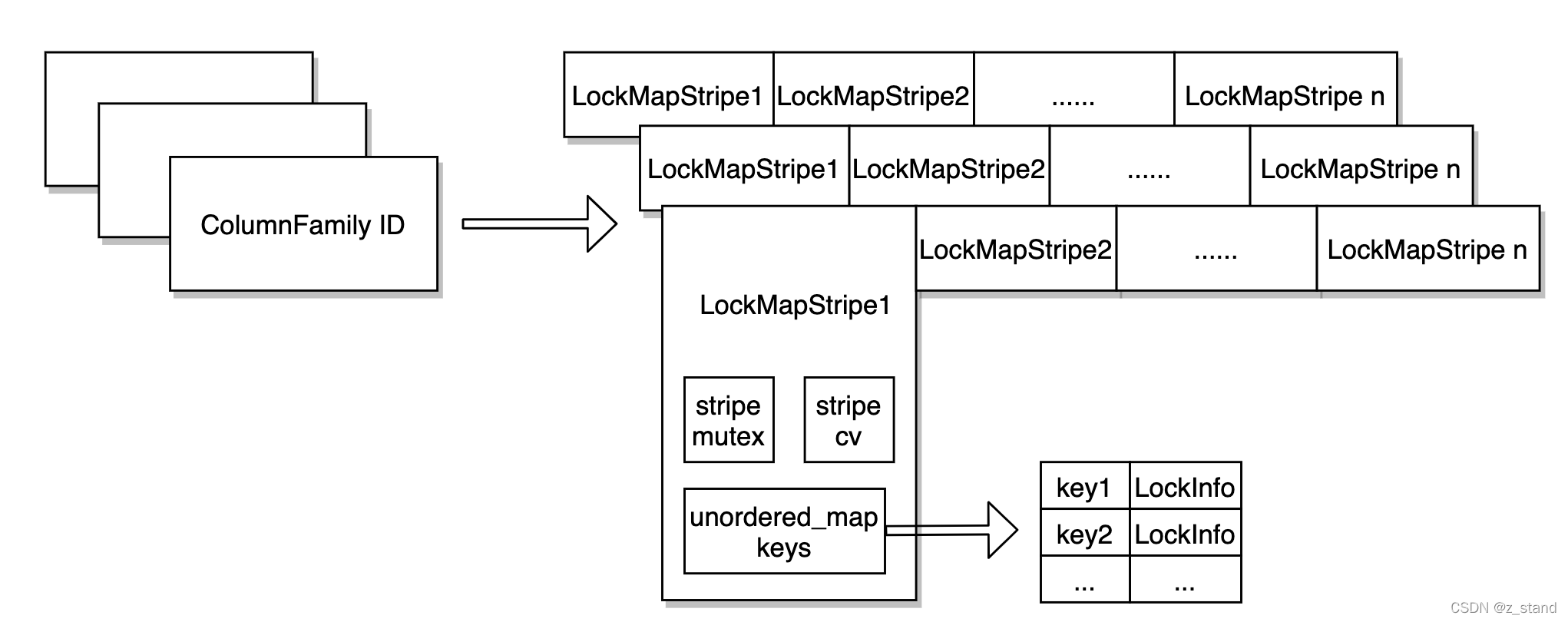
在整个DB 内部维护了一个大的 LockMaps,它是一个 column family id 到 LockMap的一个 unodered_map。这个DB内部的每一个 cf 都有一个自己的LockMap。
// Map of ColumnFamilyId to locked key info
using LockMaps = std::unordered_map<uint32_t, std::shared_ptr<LockMap>>;
LockMaps lock_maps_;
LockMap 内部 默认会有16个(可以通过 TransactionDBOptions::num_stripes进行配置) LockMapStripe,根据要加锁的Key 的hash值,会映射到对应的LockMapStripe,这里的目的应该将输入的key 打散到不同的stripe中,防止一个stripe 膨胀过大。
每一个 Stripe 内部有三个数据结构,stripe粒度的 mutex 和 conditionvariable,还有一个最重要的 unordered_map,用来保存 不同的key的 LockInfo,lock_info 中会用数组存储 操作当前key的 transactionId 以及 transaction experation_time,用来进行加锁相关的判断。
struct LockInfo {bool exclusive;autovector<TransactionID> txn_ids;// Transaction locks are not valid after this time in usuint64_t expiration_time;...
};
针对一个输入的key,具体的加锁过程如下:
拿到当前线程缓存的
lock_maps_cache_,它是一个ThreadLocalPtr(线程性能加速),从中 根据ColumnFamily ID 找到对应的LockMap; 如果lock_maps_cache_没有, 则从全局的LockMaps查找,找到则添加到lock_maps_cache_。
关于ThreadLocalPtr的介绍可以查看 rocksdb 读写链路上的极致优化。根据 输入Key 的Hash,从上一步中拿到的LockMap 中取出 key 被映射到的 LockMapStripe,并对该 Stripe 加锁(后续的处理中可能涉及对 stripe 内部 unordered_map keys 的更新)同时用
txn->GetID(), txn->GetExpirationTime()构造一个LockInfo。带着这个LockInfo 先判断这个key 所在的 LockMapStripe 的 keys 中是否有这个key,有则说明之前已经加过锁,取出这个 key 在 keys 中 的lockinfo :如果用户只允许一个key 加锁 ,即key 的LockInfo 是独占锁,且已有的lockinfo已经超时,这里 则替换成 传入的 LockInfo;如果用户允许多个事务 抢占当前key 的锁,会将这个事务ID 添加到 wait-ids 数组,等待加锁;
如果 LockMapStripe 的 keys 中没有这个key,则将当前key 以及 传入的LockInfo 添加到keys 对应的 unordered_map 之中。
需要注意的是这里有一个 stripe 允许的最大 加锁key 的数量判断(构造 LockManager 的时候 通过TransactionDBOptions::max_num_locks 控制,默认是不进行限制的),超过这个限制同样加锁失败。
如果第三步 还是加锁失败, 到第四步 会进入一个 大的超时循环中,在这个循环中会等待加锁,等待的超时时间是逐 key 对应的LockInfo 中的超时时间,如果等待的时间过了超时时间,当前事务就会加锁失败返回,每一个 txn 都会进入到这个 循环中进行。
2.3.2 DeadLock 检测实现
在上面的第四步中,因为每一个尝试加锁的 txn 在第一次没有获取到锁的时候 都会进入到 大循环中等待获得锁,这里并发事务场景下可能会出现死锁问题,所有会有死锁检测机制,实现逻辑是在 PointLockManager::IncrementWaiters 之中。
这里涉及到 死锁检测的几个参数如下:
TransactionOptions::deadlock_detect是否开启死锁检测,开启则会进行TransactionOptions::deadlock_detect_depth因为维护的是一个 txn 图,这里会有死锁检测的深度设置,越深肯定消耗的CPU计算越多
死锁检测的核心是想要在一个 有向无环图 中检测 有没有 wait-circle,即类似如下图:
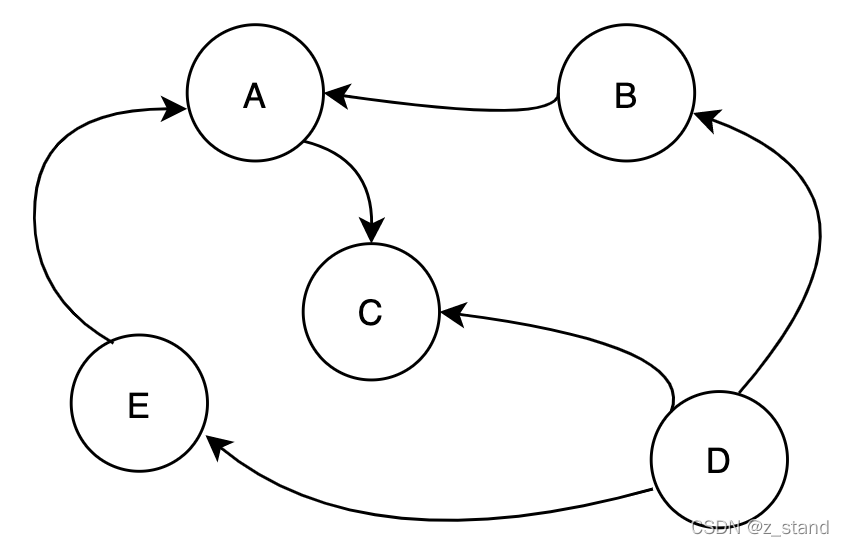
上图中通过尖头标识依赖,A–>C,txn A想要获得锁必须等到 txn C 释放才能获得。
显然这个 wait-circle 是不会死锁的, 只要 txn C 能够释放,那么其他的事务就能继续推进,但是调整一下C的依赖可能就会死锁了。
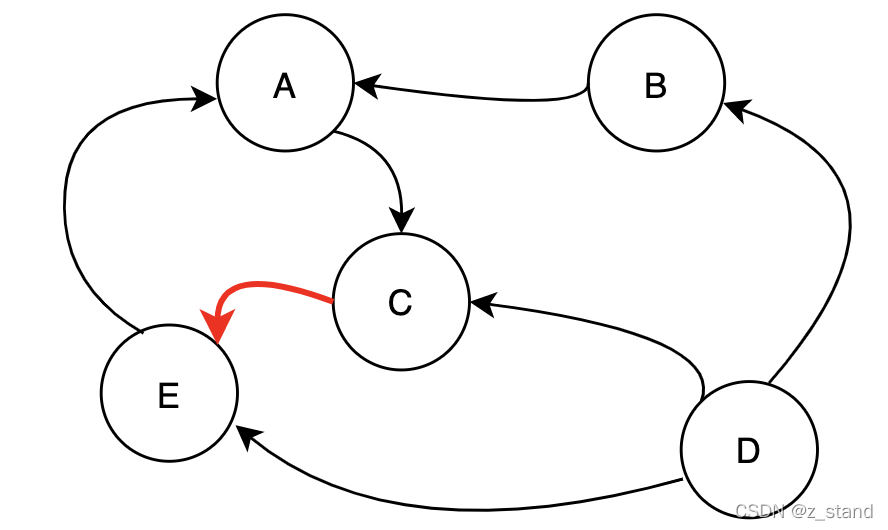
这样的依赖图 中出现了环,E–>A, A–>C, C–>E ,那就会死锁了。
所以,我们的死锁检测就是拿着当前事务前面尝试获取锁时 得到的一个 wait-ids 数组 和已有的wait-circle 来构建一个 有向无环图,在这个 有向无环图中 按照 前面用户配置的 depth 进行 wait-circle 的检测。
知道了核心目的,这里的代码逻辑就很简单了:
死锁检测入口是在PointLockManager::IncrementWaiters里面,通过前面对当前 txn 构造好的 wait-ids 数组构造 wait_txn_map_ 和 rev_wait_txn_map_ 两个 HashMap。
rev_wait_txn_map_用来保存 活跃事务 和 该事务在 有向无环图中的节点个数(也可以理解为权重)wait_txn_map_用来保存整个活跃事务视图,用于 广度优先遍历。保存的内容是 当前事务 和 该事务有关联的事务信息TrackedTrxInfo
接下来就是经典的广度优先遍历的实现了,通过提前resize 好的两个vector queue_values 和 queue_parents ,resize的大小是 前面说的 deadlock_detect_depth。 queue_values 保存层序,即每一层的所有节点;queue_parents 用来记录当前层的父节点的下标,方便后面在发现死锁环之后 进行死锁路径的回溯。
详细的算法实现这里就不细讲了,广度优先算法而已。
结束条件是:
- 在
deadlock_detect_depth这个检测深度下如果没有发现 当前事务id 和 已有活跃事务依赖图 中不会有相等的情况,则认为不会死锁,返回未发现死锁。 - 如果发现有相等的,也就是在依赖图 下找到了环的存在,则通过 queue_parents 数组来回溯当前事务在依赖图中的依赖路径,保存到
dlock_buffer_中,同时将该事务信息 从 事务依赖图中 踢出DecrementWaitersImpl,也就是将 当前txn 的 wait-ids 逆着走一遍初始化的过程,返回发现死锁。
因为死锁检测到的准确度与 deadlock_detect_depth 配置有关系,如果上层的事务并发很大,想要有效避免死锁问题,就需要合理得配置这个选项了,当然也需要和性能做一个trade-off,依赖图很大,深度又很深的话,那一次 Trylock 操作的开销可就不可忽视了。
这里实现上有一个细节,存储 事务的依赖图 rocksdb 并没有选择 std 的 unordered_map,而是自己利用 std::arrya 和 autovector(rocksdb 自己的用于小数据存储的vector, 减少扩容 以及 添加元素时 产生的内存分配的开销,开始时直接resize了一个大小) 实现了一个简易的 HashMap。
原因是 std::unordered_map 在 每一次 插入 或者 删除元素的时候 由于需要维护 iterator 的有效性(红黑树需要调整父子节点的指针链接关系),需要进行内存的分配和释放,这在 TryLock 中 尤其是高并发下,会造成不必要的开销。
所以,这里还是选择用 array + autovector,array 作为hash-bucket,autovector 存储每一个bucket内部的元素即可。
2.4 OptimisticTransaction
接下来看一下 OptimisticTransaction 的实现,相对来说就简单很多了, 相比于 PessimisticTransaction 的主要差异就是 冲突检测的时机 是在 Commit 阶段才进行。
它在 TryLock 的时候 会将当前 要更新的 key的信息添加到 LockTracker 中:
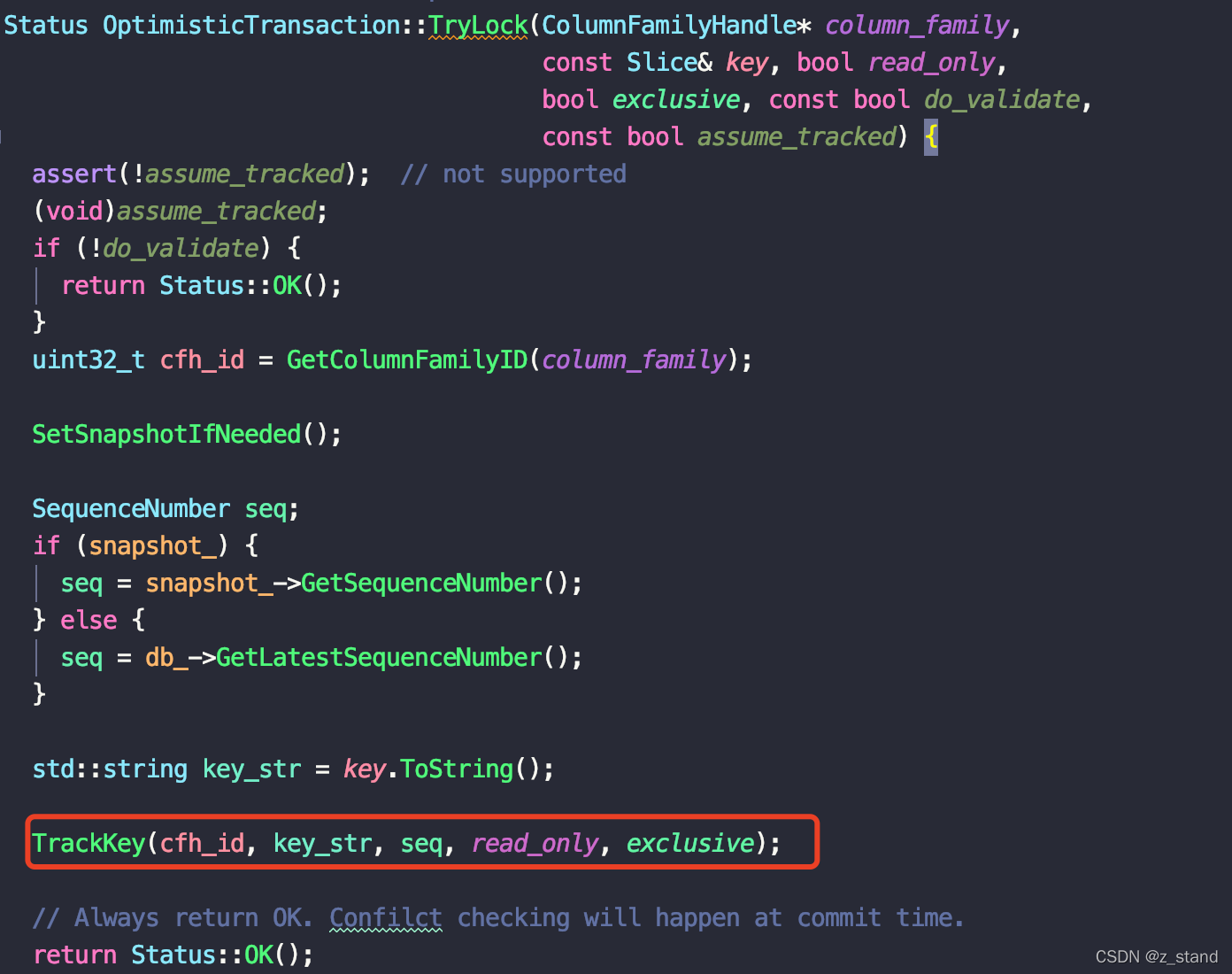
要追踪的信息主要包括当前key的 cf, seq, 是否只读,是否是独占的;其中 seq 是取用户设置的snapshot(如果设置了的话)的 seq,如果没有设置,则直接从basedb 中取最新的。
这里 LockTracker 结构大概是这样的:
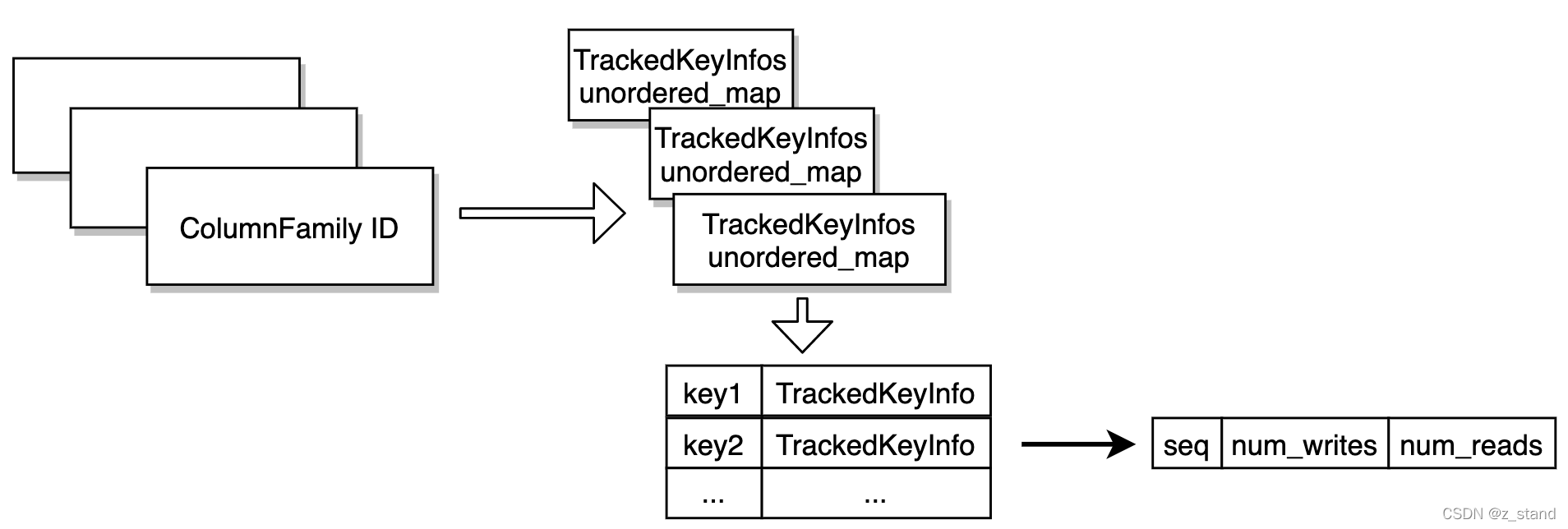
为每一个cf 维护一个 TrackedKeyInfos 的unordered_map,其中保存这个cf 追踪的key 以及 其 TrackedKeyInfo信息。
接下来 看看 Commit 的时候 乐观事务DB 怎么做冲突检测,按照经验,看上面记录的信息,肯定是 seq 是冲突检测的核心了。
Commit 的代码中提供了两种 Occ (optimistic concurrent control)策略: kValidateParallel 和 kValidateSerial ,在2020.6 月份及以前的版本 应该是只有一种 occ 策略,也就是 kValidateSerial 的实现。
先来分别看一下两种实现的具体差异,再想想为什么分别会有这两种策略,希望能为我们在分布式事务的设计中提供一些借鉴思路。
2.4.1 kValidateSerial occ
实现入口是在 OptimisticTransaction::CommitWithSerialValidate 中
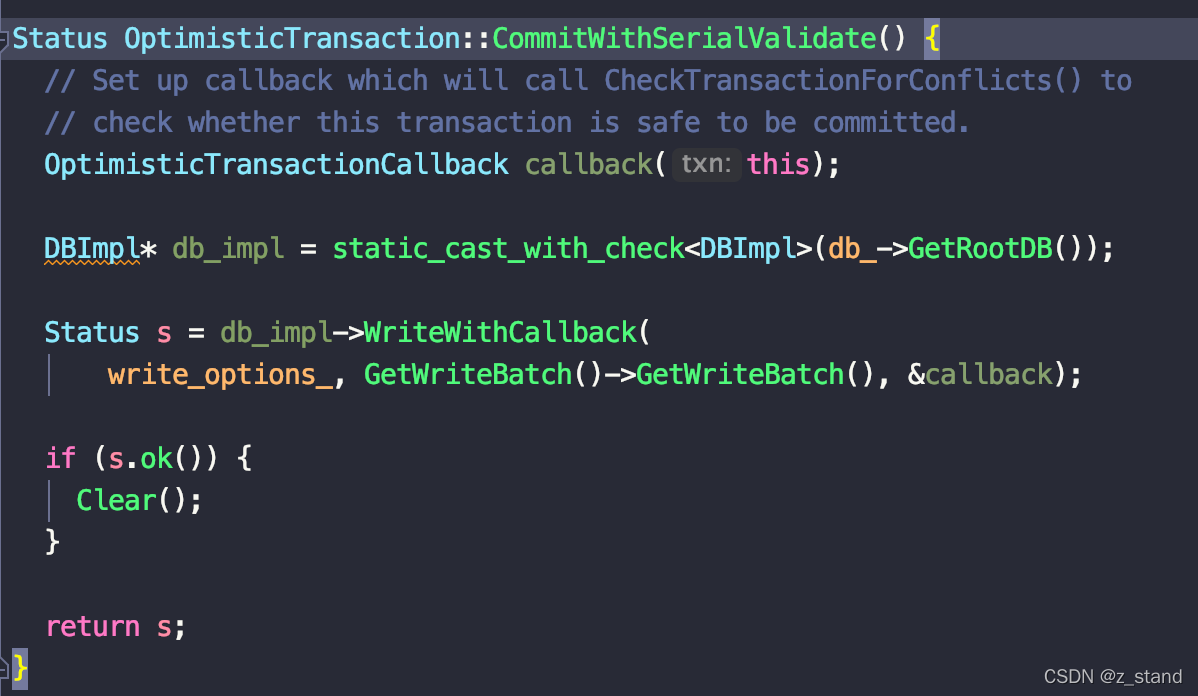
直接拿到 basedb,调用 WriteWithCallback 函数,其中 callback 的实现是 OptimisticTransactionCallback::Callback,也就是 OptimisticTransaction::CheckTransactionForConflicts。
在WriteWithCallback 会在每次写入之前对所有要写入的请求执行 callback,WriteImpl 中 writer->CheckCallback(this),检测是否满足写入的要求。
在 CheckTransactionForConflicts 中做的事情,就是拿着 前面 TryLock 过程中获取到的 LockTracker 信息 进行seq num的比较,和 PessimisticTransaction 事务中的 ValidSnapshot 做的事情一样,检测 tracker 中要提交的key 的 seq 是否比当前db 中最新的 已经commit 的 seq小,用来确定这个事务执行 中间是否有外部事务 对当前key 的更新(完成 commit的操作)。
TransactionUtil::CheckKeyForConflictsTransactionUtil::CheckKeyDBImpl::GetLatestSequenceForKeysv->mem->Getsv->imm->Getsv->imm->GetFromHistorysv->current->Get
如果做完冲突检测,这一批事务的 tracker key都没有问题,则可以提交,继续后续的写入(写WAL),否则会返回失败。
occ 策略中的 另一个策略在冲突检测这里都是差不多的。
2.4.2 kValidateParallel occ
这个策略的入口是 OptimisticTransaction::CommitWithParallelValidate。
关于冲突检测的内部实现就不过多介绍了,都是一样的,主要是这个策略如何调度 冲突检测的。
在写入之前 会先对所有的 tracked_locks_ 中的多事务的 key 按照顺序进行加锁,然后统一进行 多事务的冲突检测,冲突检测通过之后直接调度写入。
这里有一个 issue 来简单描述了 推出 kValidateParallel occ 策略的原因: kValidateSerial 太慢了。
虽然 optimisticTransaction 是建议 事务冲突概率较小的场景下才用,但是正常的多cf 写入的时候有人发现它比 baseDb和 permisticDB 慢了 5倍,看起来像是很多CPU 没有被利用起来的样子。
原因是因为 旧版本的实现 也就是 kValidateSerial 策略中:
OptimisticTransactionCallback::AllowWriteBatching返回是false,也就是在 不会调度 rocksdb 的写模型中 的 leader writer 批量写其他 writer的请求,这样的话大量的并发就没有什么用了, 都是顺序写wal。- OptimisticTransaction 本身就是在 commit 阶段进行冲突检测,所以 写入之前会有一些额外的CPU消耗(拿冲突key 的最新seq的过程 需要从上到下扫LSM-tree,直到拿到当前key在basedb 最新提交的seq)
这一些过程导致 在 旧版本的实现中 性能最差(即使是正常的请求处理),主要影响还是在 利用 Callback 去做冲突检测的过程为了保证冲突检测的有效性而关闭 group commit 功能。
所以,新的版本 主要就是解决这个问题,将callback 去掉,挪到了 write之前,毕竟冲突检测不论什么时候都得做,而挪到写链路之前做 并不会影响group-commit 的逻辑,冲突检测通过之后还是正常的 写逻辑。
相关的issue和pr 可以参考:
https://github.com/facebook/rocksdb/issues/4402
https://github.com/facebook/rocksdb/pull/6240
occ 策略希望能用一种乐观的方式处理并发事务场景,虽然在高并发的低冲突事务处理下优势明显,但是在正常的事务处理逻辑中不应该有更多的性能损耗, 可能是因为使用场景较少的原因,这个性能问题才在18年提出 20年才修复。
3. 总结
限于篇幅原因,本来还想继续展开 为myrocks 提供的 2PC 和 为 PessimisticTransactionDB 所做的长事务内存优化的 WritePreparedTxnDB 以及 WriteUnPreparedTxnDB ,先暂时推后吧。
总的来说,通过Rocksdb 的完整 事务实现过程 我们能够大体了解到 基本隔离级别的实现 以及 事务并发场景时 read-write confict 和 write-write conflict 的有效解决方案。因为 Rocksdb 是引擎底座,这一些实现方案 以及 底层的代码细节都是经过工业界长期验证的,值得学习参考。
不出意外应该是今年的最后一篇博客了,后面几天会写一写年末总结,为这 “多灾多难” 的一年画一个句号了。
相关文章:

关于学习编程的一些看法
1、看书,书上的代码一串一串的对吧?是不是很不好记?是不是觉得如果自己把这些代码都敲一遍很浪费时间?其实对于一些完全没有任何基础的人来说,全部敲一遍不失为一种简单的入门方法。对于有一点基础的人来说,…

Java项目:日历万年历(java+swing)
源码获取:博客首页 "资源" 里下载! 功能简介: 万年历 启动类: public class CalendarMainClass { public static void main(String args[]) { try { UIManager.setLookAndFeel("com.sun.java.swing.pl…

求大神给解释一下H3C ospf 双塔奇兵
转载于:https://blog.51cto.com/2807200/1364566
活着是为了什么?
活着是为了死亡,死亡才是完美,才是永恒。 死亡时将一无所有,所以活着不是为了能带走什么,而应该是能留下什么,这才是人活着的意义,多少人能想明白呢? 胡建龙转载于:https://www.cnblogs.com/hjl…
XFS 文件系统 (一) :设计概览
文章目录0 前言1 设计背景2. 需要解决的问题2.1 异常恢复太慢2.2 不支持大文件系统2.3 不支持大型稀疏文件2.4 不支持大型连续文件2.5 不支持大目录2.6 不支持过多文件个数3 XFS 架构4 痛点解决4.1 Allocation Groups4.2 Manging Free Space4.3 大文件的支持5 总结0 前言 虽然…

WebApi2官网学习记录---异常处理
HttpResponseException 当WebAPI的控制器抛出一个未捕获的异常时,默认情况下,大多数异常被转为status code为500的http response即服务端错误。 HttpResonseException是一个特别的情况,这个异常可以返回任意指定的http status code࿰…
Java项目:资源下载工具(java+swing)
源码获取:博客首页 "资源" 里下载! 功能简介: 下载地址、保存位置、下载设置、下载进度 文件仓库控制器: /*** ClassName: FileStoreController* Description: 文件仓库控制器**/ Controller public class FileStoreC…

江南Style之---西湖
西湖古称“钱塘湖”,又名“西子湖”,古代诗人苏轼就对它评价道:“欲把西湖比西子,淡妆浓抹总相宜。西湖,是一首诗,一幅天然图画,一个美丽动人的故事,不论是多年居住在这里的人还是匆…

mimikatz
下载后,在目标机直接运行 常用命令: 提升权限:privilege::debug 获取用户登录明文账号密码:sekurlsa::logonPasswords 获取用户密码hash值:lsadump::sam 转载于:https://www.cnblogs.com/xiaoqiyue/p/10824169.html
通过 RDTSC 指令从 CPU 寄存器中直接获取系统时钟
很多时候我们使用函数 gettimeofday 以及 clock_gettime 作为我们获取 wall lock的时钟函数。 因为这两种函数是 glibc 提供的用户封装,简单易用,而且能够精确到 ns,对于大多数的时钟需求场景都已经够用了。 但是如果 我们的应用 调用时钟频…

Java项目:星际争霸游戏(java+swing+awt界面编程+IO输入输出流+socket+udp网络通信)
源码获取:博客首页 "资源" 里下载! 功能简介: 星际争霸游戏项目,该项目实现了单人模式和多人合作模式,可记录游戏进度,新建游戏,载入历史记录等功能,多人模式下可以创建一…
GTONE清理维护建议方案
1、日志清理/home/gtone/AppGov/analyzer/log//home/gtone/AppGov/analyzer/SRC/temp//home/gtone/AppGov/WAS/logs/ 2、扩容现有磁盘空间至200GB转载于:https://www.cnblogs.com/arcer/p/4461018.html

[C#]委托和事件(讲解的非常不错)
引言 委托 和 事件在 .Net Framework中的应用非常广泛,然而,较好地理解委托和事件对很多接触C#时间不长的人来说并不容易。它们就像是一道槛儿,过了这个槛的人,觉得真是太容易了,而没有过去的人每次见到委托和事件就觉…
BZOJ1460: Pku2114 Boatherds
题目链接:点这里 题目描述:给你一棵n个点的带权有根树,有p个询问,每次询问树中是否存在一条长度为Len的路径,如果是,输出Yes否输出No. 数据范围:\(n\le1e5\,,p\le100\,,长度\le1e5\) Solution: …
centos 自定义内核模块 编译运行
简单记录一下 centos 自定义内核模块的一些编译运行记录,代码如下: 主要功能是通过rdtsc 指令直接从 CPU MSR 寄存器中获取时钟,尝试获取两次,两次之间会做一些赋值操作什么的,并记录一下时差。 #include <linux/…
os.system() 和 os.popen()
1.os.popen(command[, mode[, bufsize]]) os.system(command)2.os.popen() 功能强于os.system() , os.popen() 可以返回回显的内容,以文件描述符返回。eg:t_f os.popen ("ping 192.168.1.1")print t_f.read()或者:for line in os.popen("dir"…

Java项目:医院管理系统(java+Springboot+Maven+Mybatis+Vue+Mysql)
源码获取:博客首页 "资源" 里下载! 一、项目简述本系统功能包括:医院挂号,退号,缴费,退费,检查申请单开立,科室管理,医生开单,挂号级别,…
任意阶幻方..
1 /*coder Gxjun*/2 #include<stdio.h>3 #include<string.h>4 #include<stdlib.h>5 #define maxn 1006 int map[maxn][maxn] ;7 void creat_magic(int n,int x,int y ,int sn) //奇阶幻方构造8 {9 int i,j,k;10 i0;11 jn/2;12 for(kn;k<…
UML与软件建模 第三次作业
1.单元测试的任务有哪些? 单元测试是对软件基本组成单元进行的测试,而且软件单元是与程序的其他部分相隔离的情况下进行独立的测试. 任务主要包括对单元功能、逻辑控制、数据和安全性等各方面进行必要的测试。具体地说,包括单元中所有独立执行路径、数据…

Pliops XDP(Extreme Data Processor)数据库存储设计的新型加速硬件
文章目录0 前言1 核心问题1.1 引擎的各方面性能受限于数据结构的选择1.2 压缩功能 导致的CPU瓶颈1.3 Crash-safe 崩溃异常的无奈选择1.4 当前主流 加速硬件 较难满足存储性能提升的要求2 XDP 设计原则2.1 数据结构上的优化2.2 解决 压缩引入的CPU消耗2.3 异常恢复的设计2.4 易于…

Java项目:潜艇大战项目(java+swing)
源码获取:博客首页 "资源" 里下载! 功能简介: Java swing实现的一款小游戏潜艇大战的项目源码 游戏界面: SuppressWarnings({ "unused", "serial" }) public class GameGUI extends JPanel {//卡…

可以发张图片做链接用吗
转载于:https://www.cnblogs.com/wasss/p/4466492.html

更改显示器的分辨率
1.桌面右击,如图1-1所示。2.点击屏幕分辩率,选择分辨率调大小,确定,如图1-2所示。转载于:https://blog.51cto.com/qikai/1367734

Java 处理0x00特殊字符
Java 处理0x00特殊字符 一、0x00字符 1,0x00是ascii码的0值:NUL 2,0x00在windows系统中显示: 3,0x00在Linux中显示: ctrlV ctrl可以打出此字符 二、Java解决0x00字符 str.replaceAll("\\u0000",&…
关于 并查集(union find) 算法基本原理 以及 其 在分布式图场景的应用
二月的最后一篇水文…想写一些有意思的东西。 文章目录环检测在图数据结构中的应用深度/广度优先 检测环并查集数据结构 (Union-Find)基本概念初始化合并 union查找祖先优化1: 合并过程 利用 rank 优化路径优化2: 路径压缩(Path Compression)并查集 解决图中检测环问题环检测在…

Java项目:智能制造生产管理平台(java+SSM+mysql+Maven+Easyui+JSP)
源码获取:博客首页 "资源" 里下载! 运行环境:jdk1.8、tomcat7.0/8.5、Mysql5.7/5.1、Maven3.6/3.5、 eclipse/STS 功能简介:计划进度、设备管理、工艺监控、物料监控、质量监控、人员监控等 访问注册控制层:…
JAVA-Eclipse快捷键
Ctrl1:快速修复。CtrlD:快速删除行。ShiftEnter:快速调到下一行。CtrlF11:快速运行。Alt上下方向键:快速移动。CtrlM:光标所在视图最大化。Alt/:智能补全。Ctrl/:快速注释代码。 转载于:https://www.cnblogs.com/bluewhy/p/44669…
Android RelativeLayout属性
// 相对于给定ID控件android:layout_above 将该控件的底部置于给定ID的控件之上;android:layout_below 将该控件的底部置于给定ID的控件之下;android:layout_toLeftOf 将该控件的右边缘与给定ID的控件左边缘对齐;android:layout_toRightOf 将该控件的左边缘与给定ID的控件右边缘…
详解Azure的权限控制
注意:本文档仅限于Azure国际版,国内版略有不同Azure中的角色分配相对来说是比较复杂的的,对于任何云组织来说,云的资源访问管理权限都是一项非常重要的功能,azure中的授权系统叫做基于角色的访问控制(RBAC&…
SNMP introduction
简单网络管理协议(SNMP)首先是由Internet工程任务组织(Internet Engineering Task Force)(IETF)的研究小组为了解决Internet上的路由器管理问题而提出的。许多人认为 SNMP在IP上运行的原因是Internet运行的是TCP/IP协议,然而事实并不是这样。 SNMP被设计成与协议无…