10个常用python自动化脚本
大家好,Python凭借其简单和通用性,能够为解决每天重复同样的工作提供最佳方案。本文将探索10个Python脚本,这些脚本可以帮助自动化完成任务,提高工作效率。无论是开发者、数据分析师还是仅仅想简化工作流程的普通用户,这些脚本都能提供帮助。
1. 自动化文件管理
1.1 排序目录中的文件
# Python脚本,用于根据文件扩展名对目录中的文件进行排序
import os
from shutil import move
def sort_files(directory_path):
for filename in os.listdir(directory_path):
if os.path.isfile(os.path.join(directory_path, filename)):
file_extension = filename.split('.')[-1]
destination_directory = os.path.join(directory_path, file_extension)
if not os.path.exists(destination_directory):
os.makedirs(destination_directory)
move(os.path.join(directory_path, filename), os.path.join(destination_directory, filename))
根据文件扩展名将文件分类到子目录中,来组织目录中的文件。它识别文件扩展名并将文件移动到适当的子目录中,这对于整理下载文件夹或组织特定项目的文件非常有用。
1.2 删除空文件夹
# Python脚本,用于删除目录中的空文件夹
import os
def remove_empty_folders(directory_path):
for root, dirs, files in os.walk(directory_path, topdown=False):
for folder in dirs:
folder_path = os.path.join(root, folder)
if not os.listdir(folder_path):
os.rmdir(folder_path)
脚本用于在指定目录中搜索和删除空文件夹,维护干净整洁的文件夹结构,特别是在处理大量数据集时。
1.3 批量重命名文件
# Python脚本,用于批量重命名目录中的文件
import os
def rename_files(directory_path, old_name, new_name):
for filename in os.listdir(directory_path):
if old_name in filename:
new_filename = filename.replace(old_name, new_name)
os.rename(os.path.join(directory_path, filename), os.path.join(directory_path, new_filename))
脚本允许同时批量重命名目录中的多个文件。它以旧名称和新名称作为输入,并将所有匹配的文件中的旧名称替换为新名称。
2. 使用Python进行网页抓取
2.1 从网站中提取数据
# 使用Python进行网页抓取的脚本,以从网站中提取数据
import requests
from bs4 import BeautifulSoup
def scrape_data(url):
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# 在此处编写代码,从网站中提取相关数据
脚本利用requests和BeautifulSoup库来抓取网站的数据。它获取网页内容并使用BeautifulSoup解析HTML,可以自定义该脚本以提取诸如标题、产品信息或价格等特定数据。
2.2 批量下载图片
# Python脚本,用于从网站批量下载图片
import requests
def download_images(url, save_directory):
response = requests.get(url)
if response.status_code == 200:
images = response.json() # 假设API返回图片URL的JSON数组
for index, image_url in enumerate(images):
image_response = requests.get(image_url)
if image_response.status_code == 200:
with open(f"{save_directory}/image_{index}.jpg", "wb") as f:
f.write(image_response.content)
脚本旨在从网站批量下载图片,它假设该网站提供一个返回图片URL数组的JSON API。该脚本然后遍历这些URL并下载图片,将其保存到指定的目录中。
2.3 自动提交表单
# Python脚本,用于自动在网站上提交表单
import requests
def submit_form(url, form_data):
response = requests.post(url, data=form_data)
if response.status_code == 200:
# 在此处编写代码以处理表单提交后的响应
脚本使用POST请求以表单数据自动在网站上提交表单,可以通过提供URL和要提交的表单数据来自定义该脚本。
3. 文本处理和操作
3.1 统计文本文件中的单词数
# Python脚本,用于统计文本文件中的单词数
def count_words(file_path):
with open(file_path, 'r') as f:
text = f.read()
word_count = len(text.split())
return word_count
脚本读取文本文件并统计其中包含的单词数,可以用于快速分析文本文档的内容,或跟踪写作项目中的字数。
3.2 查找和替换文本
# Python脚本,用于在文件中查找和替换文本
def find_replace(file_path, search_text, replace_text):
with open(file_path, 'r') as f:
text = f.read()
modified_text = text.replace(search_text, replace_text)
with open(file_path, 'w') as f:
f.write(modified_text)
脚本在文件中搜索特定文本并将其替换为所需文本,它对批量替换大型文本文件中的某些短语或更正错误非常有用。
3.3 生成随机文本
# Python脚本,用于生成随机文本
import random
import string
def generate_random_text(length):
letters = string.ascii_letters + string.digits + string.punctuation
random_text = ''.join(random.choice(letters) for i in range(length))
return random_text
脚本生成指定长度的随机文本,可用于测试和模拟目的,甚至作为创作的随机内容源。
4. 自动发送电子邮件
4.1 发送个性化电子邮件
# Python脚本,用于向收件人列表发送个性化电子邮件
import smtplib
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
def send_personalized_email(sender_email, sender_password, recipients, subject, body):
server = smtplib.SMTP('smtp.gmail.com', 587)
server.starttls()
server.login(sender_email, sender_password)
for recipient_email in recipients:
message = MIMEMultipart()
message['From'] = sender_email
message['To'] = recipient_email
message['Subject'] = subject
message.attach(MIMEText(body, 'plain'))
server.sendmail(sender_email, recipient_email, message.as_string())
server.quit()
脚本能够向收件人列表发送个性化电子邮件,可以自定义发件人的电子邮件、密码、主题、正文以及收件人列表。请注意,出于安全考虑,使用Gmail时应使用应用专用密码。
4.2 发送带附件的电子邮件
# Python脚本,用于发送带有附件的电子邮件
import smtplib
from email.mime.multipart import MIMEMultipart
from email.mime.base import MIMEBase
from email import encoders
def send_email_with_attachment(sender_email, sender_password, recipient_email, subject, body, file_path):
server = smtplib.SMTP('smtp.gmail.com', 587)
server.starttls()
server.login(sender_email, sender_password)
message = MIMEMultipart()
message['From'] = sender_email
message['To'] = recipient_email
message['Subject'] = subject
message.attach(MIMEText(body, 'plain'))
with open(file_path, "rb") as attachment:
part = MIMEBase('application', 'octet-stream')
part.set_payload(attachment.read())
encoders.encode_base64(part)
part.add_header('Content-Disposition', f"attachment; filename= {file_path}")
message.attach(part)
server.sendmail(sender_email, recipient_email, message.as_string())
server.quit()
脚本允许发送带有附件的电子邮件,只需提供发件人的电子邮件、密码、收件人的电子邮件、主题、正文以及要附加的文件的路径即可。
4.3 自动电子邮件提醒
# Python脚本,用于发送自动电子邮件提醒
import smtplib
from email.mime.text import MIMEText
from datetime import datetime, timedelta
def send_reminder_email(sender_email, sender_password, recipient_email, subject, body, reminder_date):
server = smtplib.SMTP('smtp.gmail.com', 587)
server.starttls()
server.login(sender_email, sender_password)
now = datetime.now()
reminder_date = datetime.strptime(reminder_date, '%Y-%m-%d')
if now.date() == reminder_date.date():
message = MIMEText(body, 'plain')
message['From'] = sender_email
message['To'] = recipient_email
message['Subject'] = subject
server.sendmail(sender_email, recipient_email, message.as_string())
server.quit()
脚本基于指定日期发送自动电子邮件提醒,对设置重要任务或事件的提醒非常有用,确保不会错过最后期限。
5. 自动化Excel电子表格
5.1 读写Excel
# Python脚本,用于读写Excel电子表格中的数据
import pandas as pd
def read_excel(file_path):
df = pd.read_excel(file_path)
return df
def write_to_excel(data, file_path):
df = pd.DataFrame(data)
df.to_excel(file_path, index=False)
脚本使用pandas库从Excel电子表格中读取数据并将数据写入新的Excel文件。它允许以编程方式处理Excel文件,从而提高数据操作和分析的效率。
5.2 数据分析和可视化
# 使用pandas和matplotlib进行数据分析和可视化的Python脚本
import pandas as pd
import matplotlib.pyplot as plt
def analyze_and_visualize_data(data):
# 在此处编写数据分析和可视化的代码
pass
脚本使用pandas和matplotlib库执行数据分析和可视化,能够探索数据集、洞察数据以及创建数据的可视化表示。
5.3 合并多个表格
# Python脚本,用于将多个Excel表合并为一个表
import pandas as pd
def merge_sheets(file_path, output_file_path):
xls = pd.ExcelFile(file_path)
df = pd.DataFrame()
for sheet_name in xls.sheet_names:
sheet_df = pd.read_excel(xls, sheet_name)
df = df.append(sheet_df)
df.to_excel(output_file_path, index=False)
脚本合并Excel文件中多个表的数据到一个表中,当数据分布在不同的表中,但想进行汇总以进行进一步分析时,会很方便。
6. 与数据库交互
6.1 连接数据库
# Python脚本,用于连接数据库并执行查询
import sqlite3
def connect_to_database(database_path):
connection = sqlite3.connect(database_path)
return connection
def execute_query(connection, query):
cursor = connection.cursor()
cursor.execute(query)
result = cursor.fetchall()
return result
脚本允许连接SQLite数据库并执行查询,使用适当的Python数据库驱动程序,可以将其修改为使用其他数据库管理系统(如MySQL或PostgreSQL)。
6.2 执行SQL查询
# Python脚本,用于在数据库上执行SQL查询
import sqlite3
def execute_query(connection, query):
cursor = connection.cursor()
cursor.execute(query)
result = cursor.fetchall()
return result
脚本是一个通用函数,用于在数据库上执行SQL查询。可以将查询作为参数传递给该函数以及数据库连接对象,它将返回查询的结果。
6.3 数据备份和恢复
import shutil
def backup_database(database_path, backup_directory):
shutil.copy(database_path, backup_directory)
def restore_database(backup_path, database_directory):
shutil.copy(backup_path, database_directory)
脚本允许创建数据库的备份并在需要时进行恢复,是防止宝贵数据意外丢失的预防措施。
7. 自动化系统任务
7.1 管理系统进程
# Python脚本,用于管理系统进程
import psutil
def get_running_processes():
return [p.info for p in psutil.process_iter(['pid', 'name', 'username'])]
def kill_process_by_name(process_name):
for p in psutil.process_iter(['pid', 'name', 'username']):
if p.info['name'] == process_name:
p.kill()
脚本使用psutil库来管理系统进程,允许检索运行进程的列表并通过名称终止指定的进程。
7.2 使用Cron安排任务
# Python脚本,用于使用cron语法安排任务
from crontab import CronTab
def schedule_task(command, schedule):
cron = CronTab(user=True)
job = cron.new(command=command)
job.setall(schedule)
cron.write()
脚本利用crontab库使用cron语法来调度任务,支持以正则间隔或特定时间自动执行特定命令。
7.3 监控磁盘空间
# Python脚本,用于监控磁盘空间并在空间不足时发送警告
import psutil
def check_disk_space(minimum_threshold_gb):
disk = psutil.disk_usage('/')
free_space_gb = disk.free / (2**30) # 将字节转换为GB
if free_space_gb < minimum_threshold_gb:
# 在此处编写代码以发送警告(电子邮件、通知等)
pass
脚本监视系统上的可用磁盘空间,如果低于指定阈值则发送警告,这对于磁盘空间的积极管理和避免因磁盘空间不足导致的数据丢失非常有用。
8. 网络自动化
8.1 检查网站状态
# Python脚本,用于检查网站状态
import requests
def check_website_status(url):
response = requests.get(url)
if response.status_code == 200:
# 在此处编写代码以处理成功的响应
else:
# 在此处编写代码以处理不成功的响应
脚本通过向提供的URL发送HTTP GET请求来检查网站的状态,有助于监控网站的可用性及其响应代码。
8.2 自动化FTP传输
# Python脚本,用于自动化FTP文件传输
from ftplib import FTP
def ftp_file_transfer(host, username, password, local_file_path, remote_file_path):
with FTP(host) as ftp:
ftp.login(user=username, passwd=password)
with open(local_file_path, 'rb') as f:
ftp.storbinary(f'STOR {remote_file_path}', f)
脚本使用FTP协议自动化文件传输,连接到FTP服务器,使用提供的凭据登录,并将本地文件上传到指定的远程位置。
8.3 网络设备配置
# Python脚本,用于自动化网络设备配置
from netmiko import ConnectHandler
def configure_network_device(host, username, password, configuration_commands):
device = {
'device_type': 'cisco_ios',
'host': host,
'username': username,
'password': password,
}
with ConnectHandler(device) as net_connect:
net_connect.send_config_set(configuration_commands)
脚本使用netmiko库自动配置网络设备,如思科路由器和交换机,可以提供一系列配置命令,脚本将在目标设备上执行它们。
9. 数据清理和转换
9.1 从数据中删除重复项
# Python脚本,用于从数据中删除重复项
import pandas as pd
def remove_duplicates(data_frame):
cleaned_data = data_frame.drop_duplicates()
return cleaned_data
脚本使用pandas从数据集中删除重复行,这是确保数据完整性和提高数据分析的简单有效的方法。
9.2 数据规范化
# 数据规范化的Python脚本
import pandas as pd
def normalize_data(data_frame):
normalized_data = (data_frame - data_frame.min()) / (data_frame.max() - data_frame.min())
return normalized_data
脚本使用最小-最大规范化技术对数据进行规范化,将数据集中的值缩放到0到1范围内,使比较不同特征更容易。
9.3 处理缺失值
# Python脚本,用于处理数据中的缺失值
import pandas as pd
def handle_missing_values(data_frame):
filled_data = data_frame.fillna(method='ffill')
return filled_data
脚本使用pandas处理数据集中的缺失值,使用向前填充方法用前一个非缺失值填充缺失值。
10. 自动化PDF操作
10.1 从PDF中提取文本
# Python脚本,用于从PDF中提取文本
import PyPDF2
def extract_text_from_pdf(file_path):
with open(file_path, 'rb') as f:
pdf_reader = PyPDF2.PdfFileReader(f)
text = ''
for page_num in range(pdf_reader.numPages):
page = pdf_reader.getPage(page_num)
text += page.extractText()
return text
脚本使用PyPDF2库从PDF文件中提取文本,读取PDF的每一页并将提取的文本编译成一个字符串。
10.2 合并多个PDF
# Python脚本,用于将多个PDF合并为一个PDF
import PyPDF2
def merge_pdfs(input_paths, output_path):
pdf_merger = PyPDF2.PdfMerger()
for path in input_paths:
with open(path, 'rb') as f:
pdf_merger.append(f)
with open(output_path, 'wb') as f:
pdf_merger.write(f)
脚本将多个PDF文件合并为一个PDF文档,这对于合并独立的PDF报告、演示文稿或其他文档到一个连贯的文件很有用。
10.3 添加密码保护
# Python脚本,用于为PDF添加密码保护
import PyPDF2
def add_password_protection(input_path, output_path, password):
with open(input_path, 'rb') as f:
pdf_reader = PyPDF2.PdfFileReader(f)
pdf_writer = PyPDF2.PdfFileWriter()
for page_num in range(pdf_reader.numPages):
page = pdf_reader.getPage(page_num)
pdf_writer.addPage(page)
pdf_writer.encrypt(password)
with open(output_path, 'wb') as output_file:
pdf_writer.write(output_file)
脚本为PDF文件添加密码保护,使用密码加密PDF,确保只有那些知道正确密码的人才能访问内容。
综上所述,本文探索了不同领域的10个Python脚本,这些脚本可以完成自动化过程。从网页抓取和网络自动化到机器学习和物联网设备控制,Python的通用性允许高效地自动化广泛的过程。
自动化不仅可以节省时间和精力,还可以减少错误的风险,提高整体效率。通过自定义和扩展这些脚本,可以创建定制的自动化解决方案以满足特定需求。
相关文章:

【Linux之升华篇】Linux内核锁、用户模式与内核模式、用户进程通讯方式
alloc_pages(gfp_mask, order),_ _get_free_pages(gfp_mask, order)等。字符设备描述符 struct cdev,cdev_alloc()用于动态的分配 cdev 描述符,cdev_add()用于注。外,还支持语义符合 Posix.1 标准的信号函数 sigaction(实际上,该函数是基于 BSD 的,BSD。从最初的原子操作,到后来的信号量,从。(2)命名管道(named pipe):命名管道克服了管道没有名字的限制,因此,除具有管道所具有的。
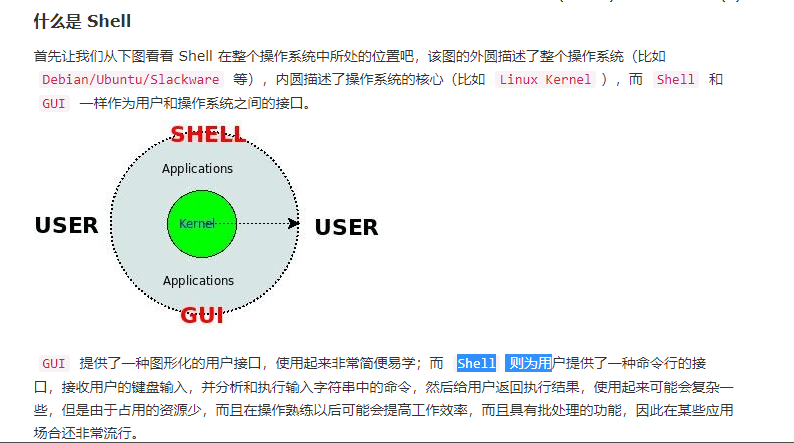
shell编程
简单来说“Shell 编程就是对一堆 Linux 命令的逻辑化处理”。

Ubuntu下安装和配置Redis
找到 /ect/redis/redis.conf 文件修改如下:注释掉 127.0.0.1 ,如果不需要远程连接redis则不需要这个操作。使用客户端向 Redis 服务器发送一个 PING ,如果服务器运作正常的话,会返回一个 PONG。默认情况下,Redis服务器不允许远程访问,只允许本机访问,所以我们需要设置打开远程访问的功能。执行sudo apt-get install redis-server 安装命令。查看 redis 是否启动,重新打开一个窗口。停止/启动/重启redis。
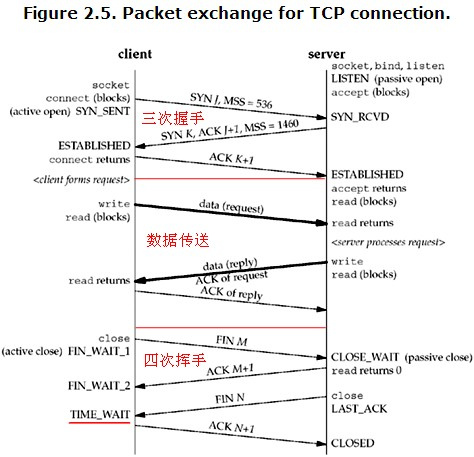
Linux下netstat命令详解&&netstat -anp | grep 讲解
Netstat是控制台命令,是一个监控TCP/IP网络的非常有用的工具,它可以显示路由表、实际的网络连接以及每一个网络接口设备的状态信息。Netstat用于显示与IP、TCP、UDP和ICMP协议相关的统计数据,一般用于检验本机各端口的网络连接情况。
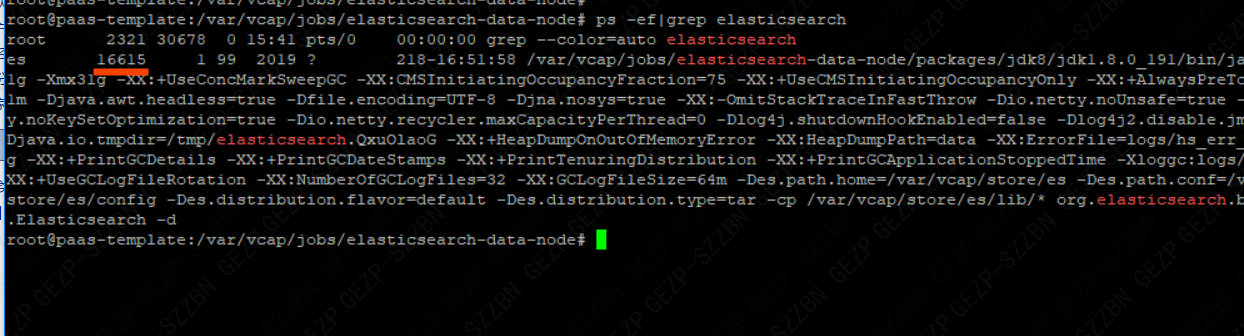
Linux命令——根据端口号查进程
查出的数据第二列(16615)是elasticsearch的进程号。通常我们会根据端口号查进程号,或者通过进程号查端口号。linux环境下,我们常常会查询进程号pid。最常用ps -ef |grep xx。根据端口port查进程。根据端口port查进程。根据进程pid查端口。根据进程pid查端口。

第三方消息推送回调Java app消息推送第三方选择
由于最先集成的是极光,因此根据官方给的推送设备区分方式中,选择了使用标签tag来进行区分管理方式,其接口提供了设置和清理标签, 每次设置会覆盖上次的结果,当然这个需要和极光后台进行交互,是异步返回的。5、由于其接口没有使用免费和付费区分,对于接口的访问没有限制,从使用的情况来看,经常会出现不准的情况,并且设置标签的效果其实是添加,导致业务需要改变标签时,需要先清除在设置,然而接口又经常出问题,导致这部分也是一塌糊涂了;如果想使用不受免费版本限制特性的推送服务,可以联系平台提供的商务对接,购买付费版本。
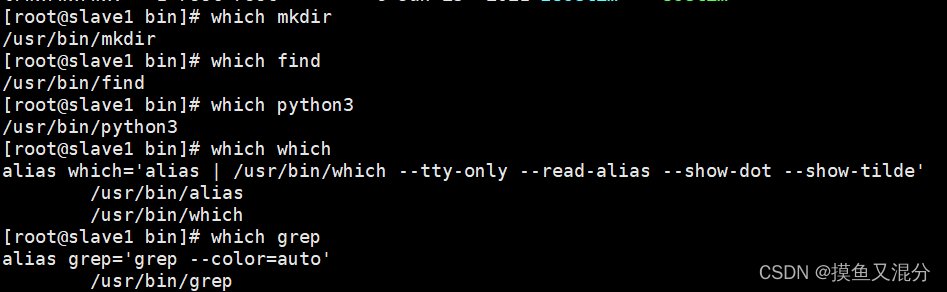
Linux搜索文件&搜索文件名&替换文件内容
locate是Linux系统提供的一种快速检索全局文件的系统命令,它并不是真的去检索所以系统目录,而是检索一个数据库文件locatedb(Ubuntu系置/var/cache/locate/locatedb),该数据库文件包含了系统所有文件的路径索引信息,所以查找速度很快。time结尾的选项,其单位为天,min结尾的选项其单位为分钟,这些选项的值都为一个正负整数, 如+7,表示,7天以前被访问过的文件,-7表示7天以内被访问过的文件,7表示恰好7天前被访问的文件。:快速返回某个指定命令的位置信息。
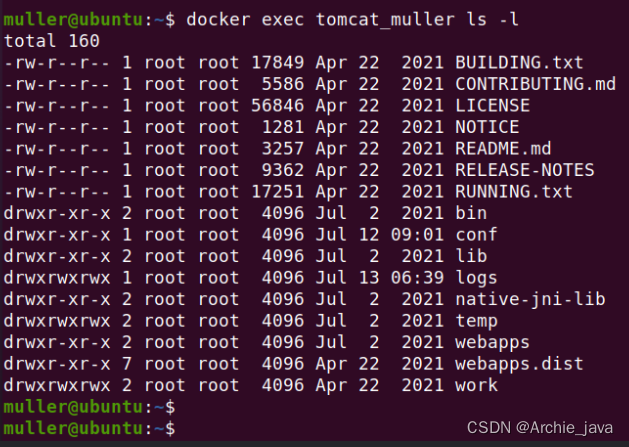
Docker exec命令详细使用指南
Docker exec命令是Docker提供的一个强大工具,用于在正在运行的容器中执行命令。本文将详细介绍Docker exec命令的用法和示例,帮助大家更好地理解和使用这个命令。Docker是一种流行的容器化平台,允许我们在容器中运行应用程序。有时候,在容器内执行命令可以帮助我们调试、排查问题或进行其他操作。这就是Docker exec命令发挥作用的时候。本文详细介绍了Docker exec命令的用法和示例。
给服务器开通telnet的流程
但一些特殊场景下,比如要升级ssh,ssh不能用时,需要使用telnet,用过要关闭此服务。需要首先安装,如果telnet-server服务在xinetd之前安装了,要先删除telnet-server,再安装xinetd。安装顺序:xinetd--》telnet--》telnet-server。安装顺序:xinetd--》telnet--》telnet-server。2、卸载rpm包(如果已经安装了,又不清楚顺序,可以都卸载后统一安装)注意:telnet-server服务启动依赖xinetd服务,
如何在Nginx中配置防盗链?
防盗链是一种防止网站资源被非法下载的技术。当用户尝试直接访问一个受保护的资源时,服务器会返回一个403 Forbidden错误,提示用户该资源受到保护,不能直接访问。这样可以避免用户通过搜索引擎或其他方式获取到未经授权的资源。通过以上步骤,我们可以在Linux系统中的Nginx Web服务器中使用Shell脚本实现防盗链的配置。这种方法可以有效地保护网站资源不被非法下载,提高用户体验,同时防止恶意攻击。在实际项目中,我们可以根据实际需求灵活配置受保护资源的URL和处理方式。
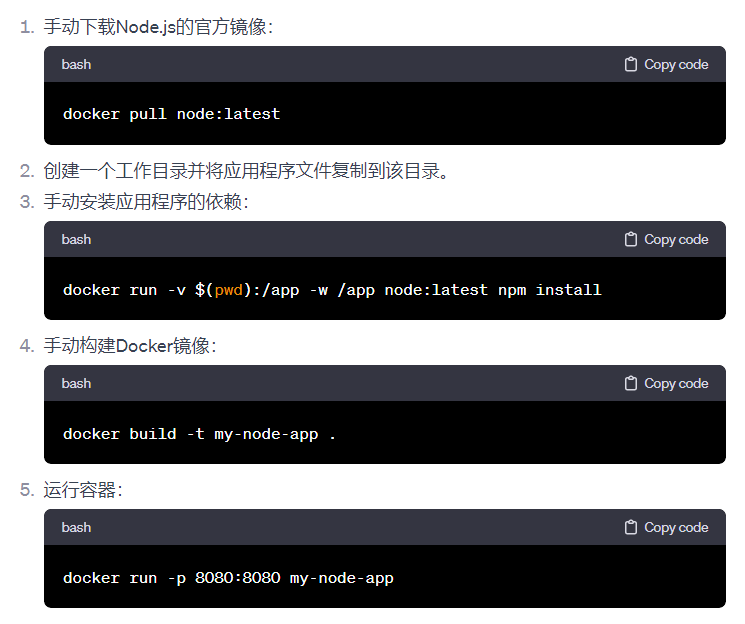
使用DockerFile构建镜像与镜像上传
首先Dockerfile 是一个文本格式的配置文件, 用户可以使用 Dockerfile 来快速创建自定义的镜像。

Python自动化实战之接口请求的实现
作为一位过来人也是希望大家少走一些弯路,如果你不想再体验一次学习时找不到资料,没人解答问题,坚持几天便放弃的感受的话,在这里我给大家分享一些自动化测试的学习资源,希望能给你前进的路上带来帮助。

轻松管理Linux磁盘空间命令:df
通过使用--output选项,可以自定义df命令的输出格式,选择显示的列以及它们的顺序。这对于筛选特定信息以便进一步处理非常有用。本文我们介绍了Linux系统上的df命令,包括基本用法、进阶用法、实际案例和场景应用,以及一些实用技巧和注意事项。df命令是系统管理中的一个重要工具,能够帮助用户有效管理磁盘空间,预防和解决潜在问题。在实际使用中,请根据具体情况选择合适的df命令选项和参数,并结合其他命令,以获取更全面的系统信息。
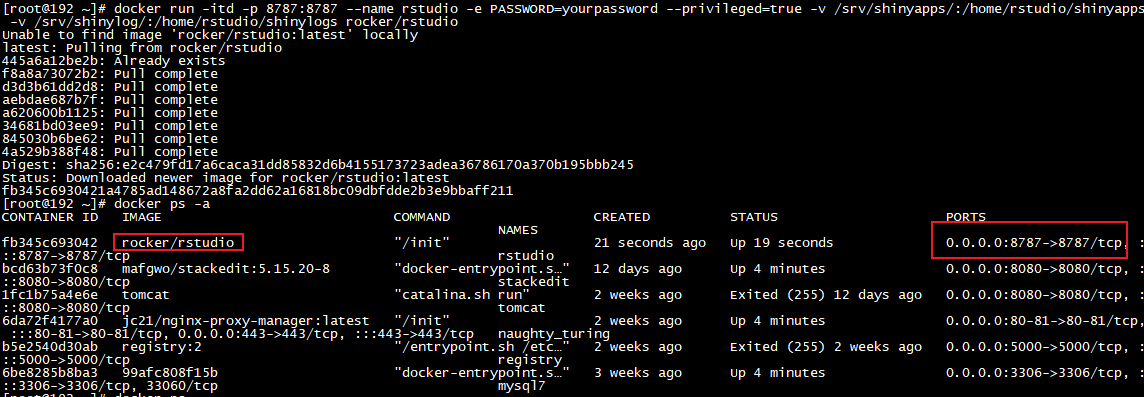
使用docker部署RStudio容器并结合内网穿透实现公网访问
RStudio Server 使你能够在 Linux 服务器上运行你所熟悉和喜爱的 RStudio IDE,并通过 Web 浏览器进行访问,从而将 RStudio IDE 的强大功能和工作效率带到基于服务器的集中式环境中。下面介绍在Linux docker中安装RStudio Server并结合cpolar内网穿透工具,实现远程访问,docker方式安装可以避免很多问题,一键安装,如设备没有安装docker,需提前安装docker。

Docker网络配置&网络模式
网络相关概念,子网掩码、网关、规则的介绍及网络模式bridge、host详解,Dockers自定义网络配置
Linux grep命令教程:强大的文本搜索工具(附案例详解和注意事项)
grep(Global Regular Expression Print)命令用来在文件中查找包含或者不包含某个字符串的行,它是强大的文本搜索工具,并可以使用正则表达式进行搜索。当你需要在文件或者多个文件中搜寻特定信息时,grep就显得无比重要啦。
保持Python程序在Linux上持续运行的几种方法
主要是用来定时执行任务的,但你也可以利用它来监控你的Python脚本是否正在运行,并在需要时重新启动它。是一个非常实用的命令,它可以让你的Python脚本在你退出shell后继续运行。总结起来,根据你的具体需求和环境,你可以选择以上任何一种方法来保持Python程序在Linux上的持续运行。使用这些工具,你可以随时断开SSH连接,而不用担心脚本会停止运行。通过这种方式,你可以安全地关闭终端,而脚本会继续在后台执行。这样,你的Python脚本就会作为系统服务运行,并且会在系统启动时自动启动。

linux环境中一次启动多个jar包,并且设置脚本开机自启
我们在通过jar启动项目时,有时候会比较多,启动会比较麻烦,需要编写shell脚本启动,将启动脚本存放在需要启动的jar包路径下。(文档存放在 /home/process_parent )PORTS 端口号,多个用空格隔开MODULES 模块,多个用空格隔开MODULE_NAMES 模块名称,多个用空格隔开。

开发版ubuntu系统上如何进行开机自启(四种方法一览)
如果省略该字段,则 systemd 将默认将当前服务的启动顺序设置为与其他服务无关,即在启动过程中没有任何依赖性关系,服务的启动顺序由系统自行决定。【ExecStart】 关键字段,服务启动命令,指定服务启动时需要执行的命令或脚本【WantedBy】用于指定服务的自动启动级别,在 Linux 系统中,多用户模式是指允许多个用户同时登录并使用系统资源的模式,与之相对的是单用户模式,只有一个用户可以登录并使用系统资源。保存文件的方法根据所使用的编辑器而有所不同,通常是按下特定的键组合,然后选择保存并退出。
你了解计算机网络的发展历史吗?
计算机网络是指将一群具有独立功能的计算机通过被互联起来的,在通信软件的支持下,实现的系统。计算机网络是计算机技术与通信技术紧密结合的产物,两者的迅速发展渗透形成了计算机网络技术。简而言之呢,计算机网络就是实现两台计算机相互沟通的介质。

Docker的介绍及安装&基本操作命令
在讲到Docker之前,我们先了解虚拟机与容器之间的区别VM(VMware)在宿主机器、宿主机器操作系统的基础上创建虚拟层、虚拟化的操作系统、虚拟化的仓库,然后再安装应用;容器,在宿主机器、宿主机器操作系统上创建Docker引擎,在引擎的基础上再安装应用。特性容器虚拟机启动秒级分钟级硬盘使用一般为MB一般为GB性能接近原生弱于系统支持量单机支持上千个容器一般几十个。
Linux安装MongoDB教程
将解压后的 mongodb-linux-x86_64-rhel70-4.2.23 中的所有文件全部移动到 /usr/local/mongodb 中 :注意/*是所有子文件。也可以不用设置环境变量进行启动,但是不设置环境变量启动的话要每次启动写很多启动参数,比较麻烦,所以做好配置环境变量。在 mongodb 下创建 data 和 logs 目录,以及日志文件mongodb.log。在 /usr/local 目录中创建 mongodb 文件夹。启动 MongoDB(-conf 使用配置文件方式启动)
Linux之后台执行命令:nohup和&的使用
如果不将 nohup 命令的输出重定向,输出将附加到当前目录的 nohup.out 文件中。command>out.file是将command的输出重定向到out.file文件,即输出内容不打印到屏幕上,而是输出到out.file文件中。2>&1是将标准错误(2)重定向到标准输出(&1),标准输出(&1)再被重定向输入到out.file文件中。作业在后台运行的时候,可以把输出重定向到某个文件中,相当于一个日志文件,记录运行过程中的输出。将sh test.sh任务放到后台,但是依然可以使用标准输入,

Linux系统中Java new Date()的时间和系统时间不一致
出现问题:new Date(),的时间和当前时间不一样,发现差了8小时,看到8小时就应该明白了,时区的问题。
linux中&和&&,|和||及分号(;)的用法
在linux中,我们经常会用到&和&&,|和||及分号,但是好多人对其会混淆,不明白其中的意思,今天为大家讲解一下&和&&,|和||及分号(;)各自的说明和用法。
docker-宿主机与容器的命令执行方法
宿主机命令容器执行程序、容器命令宿主机执行程序的方法。

Nginx实战 | 高性能HTTP和反向代理神器Nginx前世今生,以及它的“繁花之境”
Nginx 的历史可以追溯到 1990 年代末期,当时互联网开始迅速发展,传统的 HTTP 服务器如 Apache 开始显得力不从心,无法满足日益增长的访问量和并发请求。Nginx 的设计理念是追求极高的性能和稳定性,同时还具有较低的内存消耗和资源占用,这使得它能够处理大量并发请求,非常适合于需要处理高负载的服务器环境。通过这些测试和优化方法,你可以了解 Nginx 的性能瓶颈,并采取相应的措施来提高其性能。Nginx 的测试和优化可以通过多种方式进行,包括负载测试、性能测试、配置优化和代码级优化。
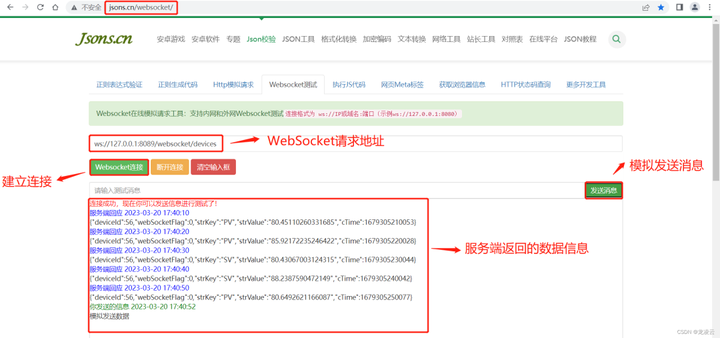
什么?Postman也能测WebSocket接口了?
作为一位过来人也是希望大家少走一些弯路,如果你不想再体验一次学习时找不到资料,没人解答问题,坚持几天便放弃的感受的话,在这里我给大家分享一些自动化测试的学习资源,希望能给你前进的路上带来帮助。
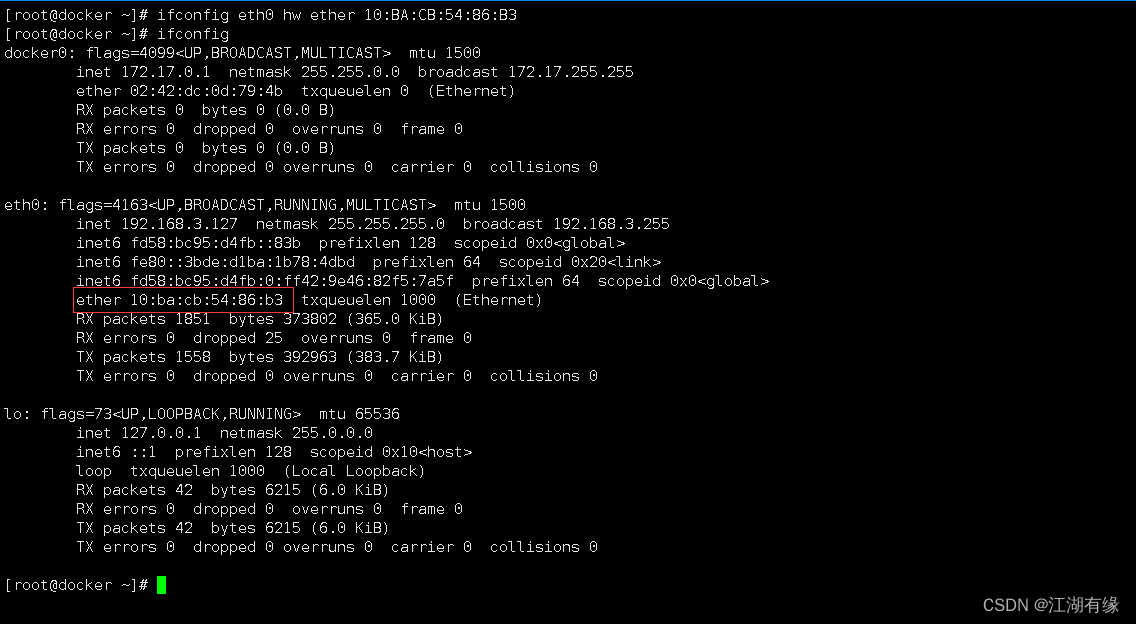
Linux系统之ifconfig命令的基本使用
ifconfig是Linux中常用的网络配置工具之一,用于配置和显示网络接口的具体状况。
一篇文章带你了解Harbor镜像是什么?
Harbor 是一个开源的企业级容器镜像仓库,它提供了安全、可靠且高效的镜像管理解决方案。它简化了镜像管理的复杂性,提高了开发人员的效率,并增强了镜像的安全性。此外,Harbor 还支持镜像的标签管理、版本控制和漏洞扫描,帮助用户确保镜像的安全性和可靠性。容器技术的快速发展推动了应用的现代化进程。开发人员可以将他们的镜像推送到 Harbor,然后其他团队成员可以从 Harbor 拉取这些镜像并在他们的环境中进行测试和部署。此外,Harbor 还提供了镜像签名和扫描功能,以确保镜像的完整性和安全性。