极小连通子图和极大连通子图_强连通分量与拓扑排序
前言
由于GacUI里面开始多处用上拓扑排序,我决定把之前瞎JB搞出来的算法换掉,换成个正式的。之前我自己弄了个写起来很简单的算法,然后每一处需要用到的地方我就重新做一遍。当然这样肯定也是不行的,我觉得也差不多积累到重构的临界点,于是重构一把。
我的需求是要在做拓扑排序的同时,识别出图的强连通分量。于是在经过短暂的考察之后,我选择了 Kosaraju's algorithm 。这个算法设计的很精妙,虽然很简单,但是令我回味无穷。该算法claim说自己是线性的,虽然也没错,但是实际上为了构造出这个数据结构,本身花费的时间已经超过线性了,所以整个算下来并不是线性的。
GacUI需要用到拓扑排序的地方很多,包括但不限于:
CodePack.exe
一个把一堆C++代码打包成几个成对的h和cpp代码的工具。这里就需要拓扑排序。因为在配置文件里(譬如说这个),我只定义了哪一些文件需要合并。而最后文件与文件的#include关系,是自动算出来的。拓扑排序在这里起到的作用,就是如果排序不成功,那我就要输出错误信息。
现在我输出错误信息只是告诉说你错了,并不能告诉你是谁跟谁搞在一起导致出错的。强连通分量在这里就起到了很好的效果,他识别出了循环引用的最小的集合,那么我就可以把这个集合输出到错误信息里,这样你就知道配置文件里面哪里写的不对。
Workflow 编译器
Workflow脚本语言支持C#那样子的class和struct。class可以继承,struct可以在成员里面引用别的struct。如果我们把class a继承自class b,和struct a用了struct b,都看成a依赖b的话,那么所有的class或者所有的struct就构成了一个图。这个图必须是偏序结构的,否则就意味着,要么你循环继承class,要么你虚幻嵌套struct,这都是错误的。
那强连通分量是什么作用呢?其实仍然是为了输出错误信息。如果你有一个很大的Workflow程序,我告诉你某个class循环继承了自己,看起来其实不是很友好。如果我可以告诉你到底是哪几个class互相继承,你改起代码来自然就方便多了。每一个强连通分量都代表了一个错误信息,很方便。
Workflow C++代码生成器
Workflow生成C++代码还有一些额外的要求。譬如说你在GacUI里面,指明了一个窗口的ref.CodeBehind属性为true,那么GacUI就会为你这个窗口单独生成一对C++文件,否则就全部加进大文件里。这样可以有效减少文件数量。你需要单独生成文件的理由,自然是你需要把自己的C++代码合并进这个窗口生成的C++代码里,就像流行的GUI库编辑器做的那样。典型的有事件处理函数,或者是你自己用C++添加的成员等等。
这就带来了两个问题。第一个问题是,如果你有三个窗口,a继承出b,而b继承出c。本来abc都是生成到同一个文件里面的,但是后来你给b加上了ref.CodeBehind=true,这会导致c也必须生成到一个独立的文件。因为如果ac在一个文件,b在另一个文件的话,你就没法正确#include。
显然,你ref.CodeBehind=true的一些窗口,使得ref.CodeBehind=false的一些窗口不一定可以全部放到一个头文件里。在这里识别出强连通分量就可以很好地减少分裂的头文件数量。当然并不是每一个强连通分量就是一个文件,这样也是很多余的。具体的办法我还没开始想,不过肯定是水到渠成的问题,因为明显只要对每一个强连通分量按照一定的规则染色,就搞定了。
第二个问题是,Workflow的类可以有嵌套类,嵌套类也会影响生成文件的安排,但是就算你只有一个文件,还会带来另一个问题。譬如说我有这样的C++代码:
class Fuck : public Bitch::Dung
{
public: class Shit{};
};class Bitch : public Fuck::Shit
{
public: class Dung{};
};
你会发现,不管你怎么调整顺序,不管你怎么向前声明,你都没办法让他编译通过。当然C#是不会有这个问题的,以C#和COM作为模板的Workflow自然也不会有这个问题。但是你真的这么写了,我就没办法替你生成C++代码。
那么自然,Workflow的C++代码生成器必须在这个时候报错。这里我们仍然要进行拓扑排序,但是图的每一个节点,其实就是每一个top level class和所有内部类的集合。在这里自然就是{Fuck, Fuck::Shit}以及{Bitch, Bitch::Dung}。在检查继承关系之后,我们发现这两个节点是循环引用的,因此会被分配到同一个强连通分量里。如果排序的结果,有一个强连通分量有超过一个节点的话,那么就意味着这种代码没办法生成C++代码,因此就可以抱错了。报错的时候,我又可以生成好看的错误信息了。
实现
其他的我就不说了,还有很多。如果你们好好看了上面的维基百科的链接,就知道Kosaraju算法是表达为递归的。在敲代码之前,我也考虑过到底要不要把递归化为循环,让爆栈不那么容易发生。后来想想算了,因为这里的递归的层数,跟你C++代码#include的层数,和类继承的层数是一致的。如果你的Workflow类一共继承了1000层,那你也不要怪我GacGen.exe崩溃,我不管的(逃。因此我毅然选择了递归。
Vlpp里面一共有三个文件:PartialOrdering.h、PartialOrdering.cpp和TestPartialOrdering.cpp。大家有兴趣的话就去看,里面有实现以及测试用例。
经过我的估算,这个类的三个主要函数的worst case复杂度分别是:
- InitWithGroup:O(ElgV)
- InitWithFunc:O(V² + ElgV)
- Sort:O(V+E)
总的来说,整个东西的复杂度还是会被控制在O(nlgn)或者O(n²),还行。
之前瞎JB搞得算法的worst case是O(n³lgn),看起来很吓人,不过因为我处理的图都是稀疏图,所以平均下来也不会这么难看。既然已经把靠谱的算法做进GacUI了,那么接下来就是把每一处用到垃圾拓扑排序的地方删掉,用新写的算法替换上。
尾声
写代码真是开心啊,每天都可以找到缺陷可以改进,每天都有代码可以写。希望有我同样热情的人,好好学习,不要被一些投机倒把的CS学生,把你们的大学学籍给挤掉,每一个喜欢编程的同学最终都能读上CS专业。
相关文章:

INTERVAL数据类型-007学习笔记
http://baggio785.itpub.net/post/31233/286119 INTERVAL数据类型用来存储两个时间戳之间的时间间隔。 可以指定years and months,或者days,hours,minuts,seconds之间的间隔。本文为oracle的学习笔记,结合实例介绍INTERVAL数据类型。 INTERVAL数据类型用…

scrapy模拟用户登录
scrapy框架编写模拟用户登录的三种方式: 方式一:携带cookie登录,携带cookie一般请求的url为登录后的页面,获取cookie信息应在登录后的页面获取,cookie参数应转成字典形式 # -*- coding: utf-8 -*- import re import sc…
linux 系统调用 open函数使用
函数介绍 本文仅仅将open系统调用的使用简单总结一下,关于其实现原理大批的大佬分享可以自行学习。open系统调用主要用于打开或者创建一个文件,并返回文件描述符。 头文件 #include <fcntl.h>函数名称 a. int open(const char *pathname, int fl…
配置zendframework开始工作(加入环境变量)
首先需要把把两个路径加入到环境变量中 1、我用的php环境是xampp,安装在di盘,我要把d:/xampp/php/这个路径加入到环境变量 2、下载zendframework(我用的版本是1.),把安装包中的bin目录加入到环境变量 3、关于设置php/php.ini中设置…
mysql计算两gps坐标的距离_mysql 计算两坐标间的距离
mysql 5.6.1 加入了空间数据支持功能,新增了st_*相关函数,可以非常方便的计算两个地理坐标点的距离了。如下例子:按我的坐标计算周边坐标的距离并由近到远排序select name,st_distance(point(113.327955,23.129717),point)*111195 as distanc…
(转)mxArray数据类型
1 、数据类型mxArray的操作 在上节的Matlab引擎函数中,所有与变量有关的数据类型都是mxArray类型。数据结构mxArray以及大量的mx开头的函数,广泛用于Matlab 引擎程序和Matlab C数学库中。mxArray是一种很复杂的数据结构,与Matlab中的array相对…

Bootstrap笔记(记录不会的知识)
head: <link rel"stylesheet" href"bootstrap.min.css" /> 引入bootstrap.min.css文件 <meta name"viewport" content"widthdevice-width,initial-scale1" /> content"widthdevice-width:设为…
linux 系统调用 read,write和lseek 使用
read系统调用 头文件 #include <unistd.h>函数使用 ssize_t read(int fd, void *buf, size_t count) read 函数会从文件描述符fd中读取指定的count长度的内容,并且将读到的结果放入到buf缓冲区中返回值 count 读取成功,则会返回读到的字节数 小于…

简单有趣的matlab小程序_超实用有趣的五个小程序推荐
大家好,我是小胖。废话不多说,进入正题。1.一周CP共读有趣的灵魂总会相遇。一个极简的社交小程序。通过选择自己喜欢的一本书,匹配到那个跟自己有着一样有趣灵魂的TA。选择好要阅读哪本书之后,填写下资料,就能在看一本…
一些linux下的性能监测工具
1.gprof http://blog.csdn.net/stanjiang2010/article/details/5655143 2.系统性能调优 http://www.ibm.com/developerworks/cn/linux/l-time/part2/index.html?cadrs perf http://www.ibm.com/developerworks/cn/linux/l-cn-perf1/ oprofile http://www.ibm.com/developerwor…
uva 10183 How many Fibs?
数学题: 给你一个区间[a,b]在该区间内有多少个费波那列数(包括a,b),数据规模达到10^100。 这题的原理很简单,基本没什么算法,其实更偏重于编程能力,需要用到高精度。另外找区间的地方…
2018/11/29 一个64位操作系统的设计与实现 02 (安装nasm)
操作系统: Centos7 在nasm官网上的到通过yum安装nasm的方法 首先在/etc/yum.repos.d/目录下 新建一个名为nasm.repo的文件, 在这么文件中写入内容如下 : [nasm] nameThe Netwide Assembler baseurlhttp://www.nasm.us/pub/nasm/stable/linux/ enabled1 gpgcheck0[nasm-testing]…
a-awk 计算数值最大,最小,平均值并保留指定位数
awk 计算最大值 echo -e "1\n2\n3\n10\n9\n5\n11\n"|awk BEGIN {max 0} {if ($1>max) max$1 } END {print "Max", max} 输出为:Max 11 或者可以使用sort命令更为便捷: cho -e "1\n2\n3\n10\n9\n5\n11\n"|sort -n |tai…
第18章:MYSQL分区
第18章:分区 目录 18.1. MySQL中的分区概述18.2. 分区类型18.2.1. RANGE分区18.2.2. LIST分区18.2.3. HASH分区18.2.4. KEY分区18.2.5. 子分区18.2.6. MySQL分区处理NULL值的方式18.3. 分区管理18.3.1. RANGE和LIST分区的管理18.3.2. HASH和KEY分区的管理18.3.3. 分…

mysql属性配置提高查询_MYSQL性能优化-安装时优化参数配置提高服务性能
MYSQL性能优化一直是个头痛的问题,目前大多都是直接把页面html静态页面或直接使用了缓存技术,下面我就mysql本身的性能优化来分享一下。安装时优化参数配置提高服务性能在Linux下安装Mysql采用默认配置安装的Mysql却未必是工作在最佳性能状态的ÿ…

c++引用的自我见解
2019独角兽企业重金招聘Python工程师标准>>> 刚开始学习c 学完指针后,其细节比较好明白,但学到引用了以后,只知其表却不知其底层的实现机制,虽然知道引用是别名、声明必须同时初始化等等,但这只是概念性的东…

c# yield关键字原理
https://www.cnblogs.com/blueberryzzz/p/8678700.html c# yield关键字原理详解 1.yield实现的功能yield return:先看下面的代码,通过yield return实现了类似用foreach遍历数组的功能,说明yield return也是用来实现迭代器的功能的。 using st…
linux进程间通信:命名管道FIFO
文章目录FIFO 通信特点系统调用接口应用拥有亲缘关系之间的进程通信非亲缘关系进程之间的通信总结FIFO 通信特点 FIFO文件有文件名 可以像普通文件一样存储在文件系统之中可以像普通文件一样使用open/write读写和pipe文件一样属于流式文件,不…
mysql 账户管理_如何用MySQL 命令来实现账户管理
今天我们要学习的是如何用MySQL 命令的方式来对账号进行管理,我们大家都知道在实际应用中MySQL 命令可以完成多种任务,以下的文章主要是对用MySQL 命令的方式来对账号进行管理的具体内容介绍。手册上说 “GRANT语句允许系统管理员创建MySQL用户账户&…
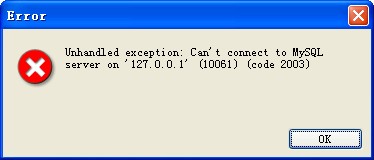
Can't connect to MySQL server on '127.0.0.1' (10061) (code 2003)解决方法
先验证一下MySQL的服务是否开启,到计算机->管理->服务和应用程序->服务 如果服务已开启,就检查一下C:\WINDOWS\system32\drivers\etc目录下的hosts文件, 是否存在这一下,不存在添加。 最后在mysql的配置文件my.ini中[mys…
学习MongoDB (1) :配置安装
为什么80%的码农都做不了架构师?>>> MongoDB是一种强大、灵活、可扩展的数据存储方式。它扩展了关系型数据库的众多有用的功能,如辅助索引、范围查询、排序。 最近开始在Windows 32位平台下研究MongoDB的使用,为了方便ÿ…

跨域策略文件crossdomain.xml文件
使用crossdomain.xml让Flash可以跨域传输数据 一、crossdomain.xml文件的作用 跨域,顾名思义就是需要的资源不在自己的域服务器上,需要访问其他域服务器。跨域策略文件是一个xml文档文件,主要是为web客户端(如Adobe Flash Player等)设置跨…

linux进程间通信:FIFO应用 /var/log/ 系统日志的模拟实现
在类unix操作系统下存在这样一个目录/var/log/,主要是记录操作系统相关的系统各个进程服务的日志信息 该日志系统的特性如下: 支持多进程并发写入同一文件不同进程日志信息可以写入不同文件支持使用head/tail/grep/cat/vi 等命令进行日志操作 我们可以…
context.xml mysql_在tomcat下context.xml中配置各种数据库连接池(示例代码)
Tomcat6的服务器配置文件放在 ${tomcat6}/conf 目录底下。我们可以在这里找到 server.xml 和 context.xml。当然,还有其他一些资源文件。但是在在本文中我们只用得上这两个,其他的就不介绍了。1,首先,需要为数据源配置一个JNDI资源。我们的数…

Planetary.js:帮助你构建超炫的互动球体效果
Planetary.js 是一个 JavaScript 库,用于构建互动球体效果。它使用 D3 和 TopoJSON 解析和渲染地理数据。Planetary.js 采用了基于插件的架构,即使是默认的功能是作为插件实现的,这使得 Planetary.js 非常灵活。Planetary.js 是完全可定制&am…
JAVA条件表达式的陷阱
Map<String, Integer> map new HashMap<String, Integer>(); map.put("count", null); Integer it map null ? 0 : map.get("count"); 注意:在第三行,会抛出java.lang.NullPointerException信息。因为分析&…
腾讯Bugly异常崩溃SDK接入
首先登入Bugly,创建应用,记录下AppId ①下载SDK,通过Cocoapods集成 pod Bugly #腾讯异常崩溃日志服务 ②导入头文件,并初始化 /** 腾讯Bugly */#import <…
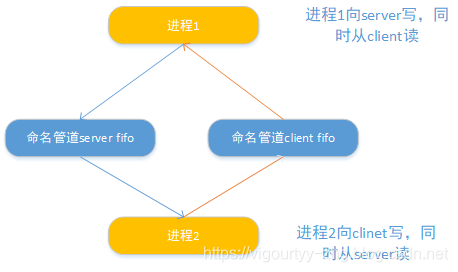
linux进程间通信:FIFO实现进程间的双向通信
fifo的双向通信的方式如下图: 两个进程间的通信需要两个命名管道,分别处理一个进程的读和写 导致这种通信方式出现的根因还是由于fifo的阻塞读和阻塞写,所以这里需要使用两个管道对读写进行分别处理。 同时因为管道传输的数据为流式数据&…
load python txt文件_详解Python中numpy.loadtxt()读取txt文件
为了方便使用和记忆,有时候我们会把 numpy.loadtxt() 缩写成np.loadtxt() ,本篇文章主要讲解用它来读取txt文件。读取txt文件我们通常使用 numpy 中的 loadtxt()函数numpy.loadtxt(fname, dtype, comments#, delimiterNone, convertersNone, skiprows0, usecolsNone…
线程之线程标识
就像每个进程有一个进程ID一样,每个线程也有一个线程ID。进程ID在整个系统中是唯一的,但线程ID不同,线程ID只在它所属的进程环境中有效。 进程ID,用pid_t数据类型来表示,是一个非负整数。线程ID则用pthread_t数据类型来…