C++ STL: 超详细 容器 deque 以及 适配器queue 和 stack 源码分析
文章目录
- 前言
- deque 实现
- deque类
- _Deque_iterator 类
- deque 的元素插入 insert函数
- deque如何模拟空间连续
- queue 实现
- stack 的实现
前言
C++容器中 deque是一个非常有趣的容器结构,我们知道deque本身是一个支持双向扩容的结构,对外表现出连续的存储方式。
本节将从它的内部实现抽丝剥茧,看看STL 团队的deque以及通过deque实现的queue和stack适配器的有趣实现。
关于deque 支持的基本接口如下:
- push_back()
- push_front()
- pop_back()
- pop_front()
- front()
- back()
- size()
- max_size()
关于接口的使用这里就不多说了,非常简单明了。
接下来就看一下deque的实现。
本节涉及的源代码是基于:gcc 2.95 版本的libstdc++ 标准库进行分析的。不同版本的代码实现方式可能有一些差异,但是核心思想应该是一样的。
gcc-2.95 源码下载
deque 实现
话不多说,先上图
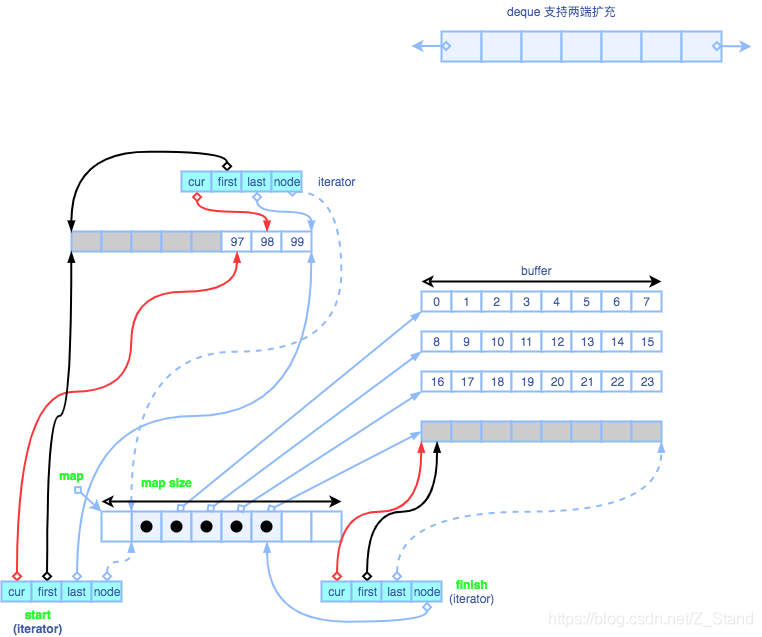
这个图是 deque 在内存中的存储结构,map这个指针指向的是deque的结构。
deque 中存储了多个指针,分别指向不同的buffer,而实际存储数据的就是buffer中的一个数据区域。 也就是deque实际的存储结构是分段连续的,并不是整个数据存储区域都是连续的,其中灰色的区域表示还没有进行数据存储的区域。deque的双向push和pop功能则是通过两端的迭代器: start 和 finish
同时维护了一个用来访问实际数据的迭代器,也就是我们通过deque<string>::iterator it;这样的方式声明的可以在整个deque存储结构中访问数据的迭代器。接下来看一下iterator的结构:
- cur 指针 ,表示当前iterator指向的 buffer的数据区域
- first 指针,表示指向当前buffer的头部区域
- last 指针,表示指向当前buffer的 尾部区域
- node 指针 则是和map指针相关联,指向map中的一个地址
deque中的buffer区域增加和删除 都是通过start 和 finish iterator 的指针变动来进行维护的,这里的两个iterator 是非常重要的。
deque 实现的类图如下(代码在 stl_deque.cc):

从上面的类图中我们可以看出deque的数据成员主要来自_Deque_base 和 _Deque_alloc_base两个类,其中_Deque_base 类提供了我们的start和finish两个迭代器,这两个迭代器的用途我们在上面的一张deque结构图下已经讲过了,分别维护deque两端的buffer区域的扩张。
关于迭代器内部的数据成员,我们上面的类图也已经给出了,右侧的类图中描述了迭代器内部的数据成员,分别是四个指针,用来访问buffer内部的数据成员。
其次就是类 _Deque_alloc_base,包含map主节点的成员变量,包括map指针以及map_size的大小。
综上,我们可以知道一个deque的对象的大小为(64位机器下):sizeof(T*) * 8 + 8 + 4 = 72
ps:
以上大小是在gcc 2.95这个版本的stl中的元素的大小,可能新版本C++中的大小会有细微的差异
deque类
接下来我们仔细看一下deque这个类,声明如下:
template <class _Tp, class _Alloc = __STL_DEFAULT_ALLOCATOR(_Tp), size_t __bufsiz = 0>
class deque : protected _Deque_base<_Tp, _Alloc, __bufsiz> {typedef _Deque_base<_Tp, _Alloc, __bufsiz> _Base;
public: // Basic typestypedef _Tp value_type;typedef value_type* pointer;typedef const value_type* const_pointer;typedef value_type& reference;typedef const value_type& const_reference......
模版类传入除了正常的数据类型的参数_Tp之外还包括 _Alloc,和一个size_t类型的__buffsiz,这里的buffsiz指的是每个buffer 可容纳的元素总大小。
这里表明我们可以自己指定buffer 的大小,即我们通过声明deque<int, allocator<int>, 100>的方式来自己指定buffer的大小。
如果说我们自己没有指定,则STL默认会将buffsiz设置为0,此时分配buffsiz空间大小的函数则会由_Deque_alloc_base 类的_M_allocate_node函数进行空间分配,最终调用__deque_buf_size计算需要分配的大小。
_Tp* _M_allocate_node(){ return _Node_alloc_type::allocate(__deque_buf_size(__bufsiz, sizeof(_Tp))); }inline size_t
__deque_buf_size(size_t __n, size_t __size)
{return __n != 0 ? __n : (__size < 512 ? size_t(512 / __size) : size_t(1));
}
分配的大小根据传入的buffsiz的个数来判断:
如果n不为0,传回n,表示buffer的大小由使用者自己定
如果n 为0,表示buffer大小使用默认设定的,那么仍需确认:
- 如果(sizeof(value_type))小于512B,传回512 / sizeof(value_type)
- 如果(sizeof(value_type))大于512B,则返回1
_Deque_iterator 类
deque的迭代器是一个非常重要的实现,因为我们在使用deque的时候需要遍历迭代器的元素,需要对迭代器进行自加,或者+= n 的操作。即,用户认为deque是连续的存储方式,但是本身deque的存储方式是分段连续,所以这里需要迭代器来实现deque的分段连续特性,要能够将遍历元素无缝从上一个buffer切换到下一个buffer,且支持+= n的一次跨越多个元素更主要的是跨越多个buffer的操作。
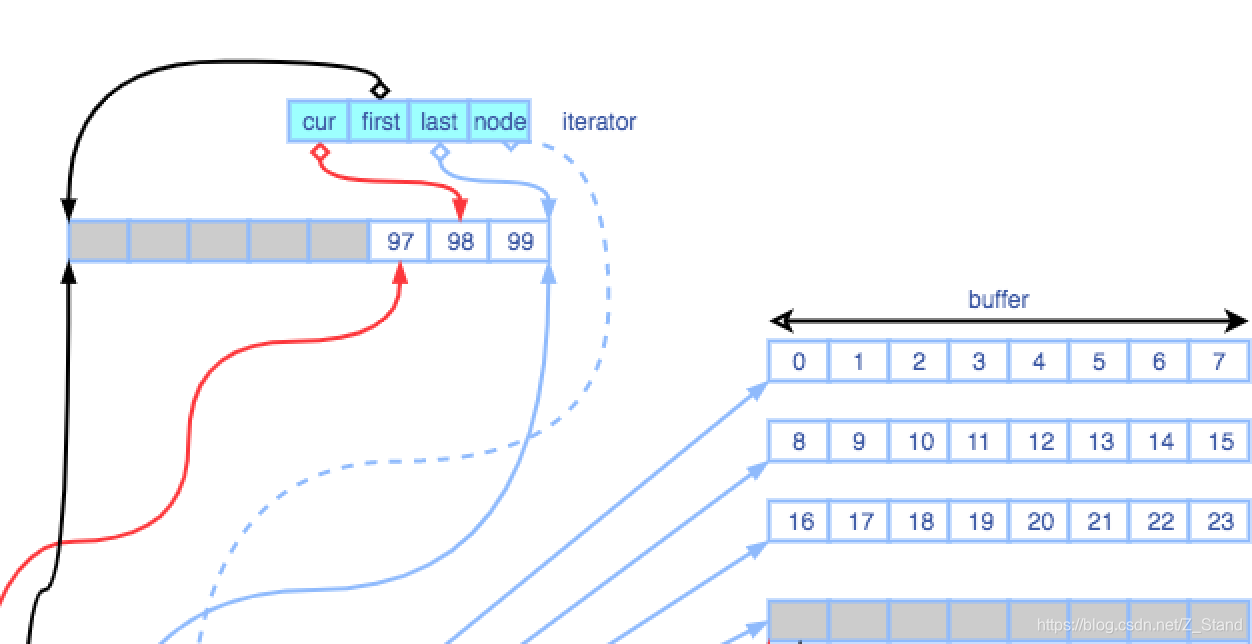
接下来看一下迭代器类如何实现上述的操作,迭代器类的实现如下:
#ifndef __STL_NON_TYPE_TMPL_PARAM_BUG
template <class _Tp, class _Ref, class _Ptr, size_t __bufsiz>
struct _Deque_iterator {typedef _Deque_iterator<_Tp,_Tp&,_Tp*,__bufsiz> iterator;typedef _Deque_iterator<_Tp,const _Tp&,const _Tp*,__bufsiz> const_iterator;static size_t _S_buffer_size() { return __deque_buf_size(__bufsiz, sizeof(_Tp)); }......typedef random_access_iterator_tag iterator_category;typedef _Tp value_type;typedef _Ptr pointer;typedef _Ref reference;typedef size_t size_type;typedef ptrdiff_t difference_type;typedef _Tp** _Map_pointer;typedef _Deque_iterator _Self;//这是几个迭代器内部的重要指针_Tp* _M_cur;_Tp* _M_first;_Tp* _M_last;_Map_pointer _M_node;......
deque 的元素插入 insert函数
分段连续的实现,我们这里来看一个有趣的函数insert
//在position的位置插入一个value_type的元素
iterator insert(iterator position, const value_type& __x) {if (position._M_cur == _M_start._M_cur) {//如果安插点是deque的最前端push_front(__x); //则交给push_front处理return _M_start;}else if (position._M_cur == _M_finish._M_cur) { //如果安插点是deque的最末端push_back(__x); //则交给push_back处理iterator __tmp = _M_finish;--__tmp;return __tmp;}else {return _M_insert_aux(position, __x); //不在头部,则不在尾部,则单独处理,需要在分段的buffer之间跳跃}
}
可以看到insert在确认了整个deque的两端都没法插入之后会调用一个_M_insert_aux函数来执行中间部分的插入。依据deque的分段连续的实现,这个函数任务重大,它就是实现分段连续的关键。因为中间部分就是分段的,这个函数需要实现分段之间的连续跳跃以及跨段跳跃,并提供给使用者可以连续操作的接口(++,–,+=,-=)
_M_insert_aux函数实现如下:
template <class _Tp, class _Alloc, size_t __bufsize>
void
deque<_Tp,_Alloc,__bufsize>::_M_insert_aux(iterator __pos,const value_type* __first,const value_type* __last,size_type __n)
{const difference_type __elemsbefore = __pos - _M_start;//获取安插点之前的元素个数size_type __length = size();if (__elemsbefore < __length / 2) {// 如果安插点之前的元素较少,则靠近头端插入iterator __new_start = _M_reserve_elements_at_front(__n);//调整新的start位置,预留下来足够存储元素n的空间iterator __old_start = _M_start;__pos = _M_start + __elemsbefore;__STL_TRY {if (__elemsbefore >= difference_type(__n)) { //确认从原来的start 到pos之间的距离是否足够存储元素niterator __start_n = _M_start + difference_type(__n); //可以的话则保留元素n加入之后的位置uninitialized_copy(_M_start, __start_n, __new_start); //将m_start到start_n之间的元素都移动到new_start位置_M_start = __new_start;copy(__start_n, __pos, __old_start);//不同buffer之间的元素拷贝copy(__first, __last, __pos - difference_type(__n)); // 调整first和last指针,移动buffer内部的元素}else {const value_type* __mid = __first + (difference_type(__n) - __elemsbefore);__uninitialized_copy_copy(_M_start, __pos, __first, __mid,__new_start);_M_start = __new_start;copy(__mid, __last, __old_start);}}__STL_UNWIND(_M_destroy_nodes(__new_start._M_node, _M_start._M_node));}else {// 如果安插点之前的元素较多(多于整个deque元素一半),则靠近尾端插入iterator // __new_finish = _M_reserve_elements_at_back(__n);iterator __old_finish = _M_finish;const difference_type __elemsafter = difference_type(__length) - __elemsbefore;__pos = _M_finish - __elemsafter;__STL_TRY {if (__elemsafter > difference_type(__n)) {iterator __finish_n = _M_finish - difference_type(__n);uninitialized_copy(__finish_n, _M_finish, _M_finish);_M_finish = __new_finish;copy_backward(__pos, __finish_n, __old_finish);copy(__first, __last, __pos);}else {const value_type* __mid = __first + __elemsafter;__uninitialized_copy_copy(__mid, __last, __pos, _M_finish, _M_finish);_M_finish = __new_finish;copy(__first, __mid, __pos);}}__STL_UNWIND(_M_destroy_nodes(_M_finish._M_node + 1, __new_finish._M_node + 1));}
}
以上的代码大体分为几步:
- 确认插入的元素在整个deque所处的位置,如果靠近deque的头部
则插入头部,插入的过程是:
将从deque头部到插入位置的元素向前拷贝sizeof(x)的位置(过程中可能有buffer之间的移动,以及新buffer空间的分配),再将新的元素插入当前位置。 - 如果在整个deque靠近尾部(小于deque.size / 2)的位置,则按照以上的方式进行元素的移动,只不过是方向向后移动。
deque如何模拟空间连续
介绍deque模拟连续空间的实现之前,我们先看如下几个函数的实现:
- front()函数
//front函数返回整个deque的最开始位置,也就是_M_start所指向的位置 reference front() { return *_M_start; } - back()函数
// 因为_M_finish是deque尾部的迭代器,且它的last指向最后一个元素的下一个元素 // 所以需要取它的前一个指向,从而能够访问到deque的最后一个元素 reference back() {iterator __tmp = _M_finish;--__tmp;return *__tmp; } - size() 函数
整个deque的大小就是从start 到 finish迭代器之间的距离size_type size() const { return _M_finish - _M_start;; }
到这里 我们总结一下deque模拟连续空间的功能在以上三个函数中都用到了,像操作符 *, --,- 都是经过重载的。比如我们想要获取deque 的大小,上面的实现中size仅仅是做了迭代器之间的 - 操作,但是迭代器内部的指针计算 从 start 到 到end之间的距离(如下图从start iterator访问到finish iterator),这个过程内是怎么移动的,涉及到可能跨越多个buffer的大小计算,所以这里还需要详细看看对应的运算符的重载实现。

模拟连续空间的实现,迭代器功不可没。
接下来看一下_Deque_iterator对几个运算符重载功能的实现。
operator *
返回了当前迭代器中的cur指针,指向该迭代器所处buffer的元素,返回该元素的值。reference operator*() const { return *_M_cur; }operator ->
返回迭代器的指针,也就是->符号访问的还是一个迭代器pointer operator->() const { return _M_cur; }operator -
两个迭代器之间的距离相当于:
(1) 两个iterator之间的buffer总长度 +
(2) itr至其buffer末尾的长度 +
(3) x 至其buffer起始的长度difference_type operator-(const _Self& __x) const {/*difference_type(_S_buffer_size()) 每个缓冲区的大小(_M_node - __x._M_node - 1) 表示完成的缓冲区的个数(_M_cur - _M_first) 末尾迭代器itr到其buffer末尾的长度(__x._M_last - __x._M_cur) x 到其buffer开头的长度*/return difference_type(_S_buffer_size()) * (_M_node - __x._M_node - 1) +(_M_cur - _M_first) + (__x._M_last - __x._M_cur); }operator ++
这里使用的是前++实现的后++运算符_Self& operator++() {++_M_cur; //切换至下一个元素if (_M_cur == _M_last) { // 如果发现元素达到了buffer的边界,由当前迭代器的_M_last表示_M_set_node(_M_node + 1); // 就跳至下一个node点,_M_set_node实现在下面_M_cur = _M_first; // 将当前的cur指向下一个node点的first节点}return *this; }_Self operator++(int) {_Self __tmp = *this;++*this; // 调用上面的 ++运算符,即使用后++ 运算符调用前 ++return __tmp; } // 重置当前迭代器的几个指针。 void _M_set_node(_Map_pointer __new_node) {_M_node = __new_node;_M_first = *__new_node;_M_last = _M_first + difference_type(_S_buffer_size()); }operator --
同样使用的是前–实现后–运算符_Self& operator--() {if (_M_cur == _M_first) {// 减之前如果发现当前节点已经达到buffer首部边界_M_set_node(_M_node - 1); //重置node,到node - 1(前一个buffer)_M_cur = _M_last; // 将cur指向 上一个buffer的last}--_M_cur;return *this; } _Self operator--(int) {_Self __tmp = *this;--*this;return __tmp; }operator +=
+= 运算符表示支持迭代器cur指针可以跨越多个元素,这个过程难免要处理针对buffer的跨越处理_Self& operator+=(difference_type __n) {difference_type __offset = __n + (_M_cur - _M_first);if (__offset >= 0 && __offset < difference_type(_S_buffer_size()))// 目标位置在同一buffer内,没有跨越缓冲区边界_M_cur += __n;else {// 目标位置在不同buffer内,计算需要跨越多少个buffer// __offset / difference_type(_S_buffer_size()) difference_type __node_offset =__offset > 0 ? __offset / difference_type(_S_buffer_size()): -difference_type((-__offset - 1) / _S_buffer_size()) - 1;// 切换到了正确的buffer _M_set_node(_M_node + __node_offset);// 切换到正确的元素,使用__offset 减去跨越的缓冲区的距离,剩下的就是在新的缓冲区中的距离_M_cur = _M_first + (__offset - __node_offset * difference_type(_S_buffer_size()));}return *this; }//同时 + 运算符也是借用+= 执行的 _Self operator+(difference_type __n) const {_Self __tmp = *this;return __tmp += __n; }operatro -=
-= 运算符的重载的实现更加便捷// 直接使用 += 一个-__n元素来进行跳转 _Self& operator-=(difference_type __n) { return *this += -__n; }_Self operator-(difference_type __n) const {_Self __tmp = *this;return __tmp -= __n; }operator []
因为deque对外体现的是连续的空间,所以需要提供能够随机访问(下标访问)的能力
这里是使用的+ 运算符,即也就是+= 运算符实现reference operator[](difference_type __n) const { return *(*this + __n); }
queue 实现
如下为基本的queue和stack操作,stack是先入先出

如上为queue和 stack的基本操作示意图,queue是两端开口,先入先出的形态。
默认使用deque作为底层容器,并封装了一些deque的细节,所以queue和stack也被成为适配器,并不是标准的容器。
实现代码如下:
#ifndef __STL_LIMITED_DEFAULT_TEMPLATES
template <class _Tp, class _Sequence = deque<_Tp> > //deque实现底层容器
#else
template <class _Tp, class _Sequence>
#endif
class queue {friend bool operator== __STL_NULL_TMPL_ARGS (const queue&, const queue&);friend bool operator< __STL_NULL_TMPL_ARGS (const queue&, const queue&);
public:typedef typename _Sequence::value_type value_type;typedef typename _Sequence::size_type size_type;typedef _Sequence container_type;typedef typename _Sequence::reference reference;typedef typename _Sequence::const_reference const_reference;
protected:_Sequence c; // 底层容器 deque
public:queue() : c() {}explicit queue(const _Sequence& __c) : c(__c) {}/*queue 的功能都交给deque,调用对应的deque接口实现*/bool empty() const { return c.empty(); }size_type size() const { return c.size(); }reference front() { return c.front(); }const_reference front() const { return c.front(); }reference back() { return c.back(); }const_reference back() const { return c.back(); }void push(const value_type& __x) { c.push_back(__x); }void pop() { c.pop_front(); }
};
这里 说一下为什么 queue和 stack都默认使用deque作为底层容器?
可以看到queue的接口也就是上面中的那一些,也即只要有其他的容器能够提供类似于上面的几个接口,也能作为queue和stack的底层容器。这里有list也能够作为底层的容器,但是STL团队选择deque肯定是有原因的,唯一的差异就是性能了,验证代码如下:
#include <iostream>
#include <deque>
#include <list>
#include <queue>
#include <ctime>using namespace std;int main()
{clock_t time_start = clock(); queue<int, list<int> > q;for (int i = 0 ;i < 1000000; i++) {q.push(i);}cout << "list as container of queue, push time is " << clock() - time_start << endl;time_start = clock();queue<int> Q;for (int i = 0 ;i < 1000000; i++) {Q.push(i);}cout << "deque as container of queue, push time is " << clock() - time_start << endl;return 0;
}
输出如下:
list as container of queue, push time is 153782 # 微秒
deque as container of queue, push time is 45401 # 微秒
可以看到push 100万个元素分别到不同容器实现的queue中,deque的实现性能要优于queue接近四倍。
stack 的实现
同样内含deque,作为底层容器
#ifndef __STL_LIMITED_DEFAULT_TEMPLATES
template <class _Tp, class _Sequence = deque<_Tp> > // 同样使用 deque作为底层容器
#else
template <class _Tp, class _Sequence>
#endif
class stack {friend bool operator== __STL_NULL_TMPL_ARGS (const stack&, const stack&);friend bool operator< __STL_NULL_TMPL_ARGS (const stack&, const stack&);
public:typedef typename _Sequence::value_type value_type;typedef typename _Sequence::size_type size_type;typedef _Sequence container_type;typedef typename _Sequence::reference reference;typedef typename _Sequence::const_reference const_reference;
protected:_Sequence _M_c;
public:stack() : _M_c() {}explicit stack(const _Sequence& __s) : _M_c(__s) {}bool empty() const { return _M_c.empty(); }size_type size() const { return _M_c.size(); }reference top() { return _M_c.back(); }const_reference top() const { return _M_c.back(); }void push(const value_type& __x) { _M_c.push_back(__x); }void pop() { _M_c.pop_back(); }
};
这里说一个注意事项:
我们知道所有的标准容器,list,vector,deque,set,map 是都允许使用迭代器进行元素的遍历,但是stack和queue 不允许。因为如果允许迭代器进行遍历,也就意味着迭代器可以对元素进行任意的插入和删除,那么也就破坏了stack和queue本身想要组织的数据形态
所以这样的代码
queue<string>::iterator ite; 会编译出错
no template named 'iterator' in'std::__1::queue<std::__1::basic_string<char>,std::__1::deque<std::__1::basic_string<char>,std::__1::allocator<std::__1::basic_string<char> > > >'; did you meansimply 'iterator'?
我们在queue中说了,只要支持queue和stack的底层操作,底层容器的选择可以有其他的实现。那vector是否可以作为以上两者的容器呢?
测试代码:
#include <iostream>
#include <deque>
#include <list>
#include <queue>
#include <ctime>
#include <stack>
using namespace std;int main()
{clock_t time_start = clock(); queue<int, vector<int> > q;for (int i = 0; i < 10; ++i) {q.push(i);}q.front();q.back();q.empty();q.size();q.pop();stack<int, vector<int>> s;for (int i = 0; i < 10; ++i) {s.push(i);}s.top();s.empty();s.size();s.pop();return 0;
}
编译以上代码,发现出错,发现是queue使用vector时,底层容器vector并没有pop_front的成员函数,而stack可以使用vector作为底层容器。
error: no member named 'pop_front' in 'std::__1::vector<int,std::__1::allocator<int> >'void pop() {c.pop_front();}~ ^
STL_deque.cc:22:4: note: in instantiation of member function'std::__1::queue<int, std::__1::vector<int, std::__1::allocator<int> >>::pop' requested hereq.pop();
有趣的结构,有趣的实现。
相关文章:
php好的mvc中index方法,创建一个mvc应用目录架构并创建入口文件index.php
摘要:<?php require vendor/autoload.php;require pig/Base.php;define(ROOT_PATH,__DIR__./);$configrequire pig/config.php;$queryStr$_S<?php require vendor/autoload.php;require pig/Base.php;define(ROOT_PATH,__DIR__./);$configrequire pig/confi…

C语言对mysql数据库的操作
C语言对mysql数据库的操作 原文:C语言对mysql数据库的操作这已经是一相当老的话题。不过今天我才首次使用,把今天的一些体会写下来,也许能给一些新手带来一定的帮助,更重要的是供自己今后忘记的怎么使用而进行查阅的! 我们言归正传…
[转]MCC(移动国家码)和 MNC(移动网络码)
From : http://blog.chinaunix.net/uid-20484604-id-1941290.html 国际移动用户识别码(IMSI) international mobile subscriber identity 国际上为唯一识别一个移动用户所分配的号码。 从技术上讲,IMSI可以彻底解决国际漫游问题。但是由于…
虚拟机cenos 重置密码
许久不用虚拟机,临时想登录看下,结果想不起来密码了,尝试各种可能的密码都登录失败。然后百度查验各种方法,看到一篇文章然后根据上面说的成功解决了问题,贴出链接:https://blog.csdn.net/dannistang/artic…
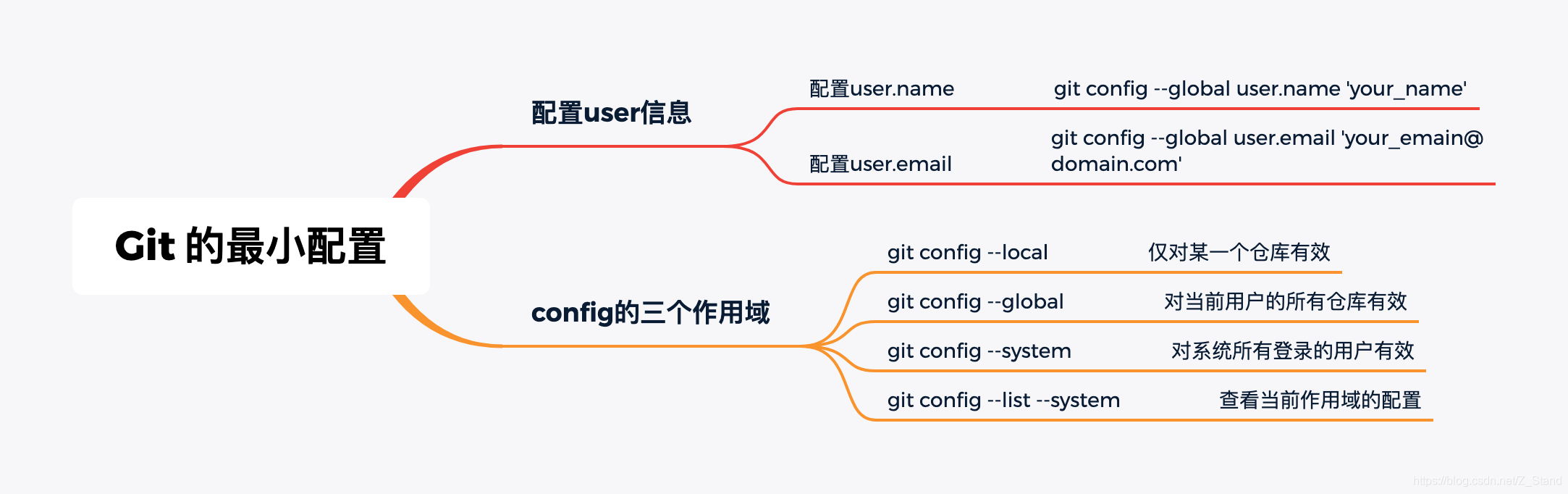
g-git 相关命令 及其 基本原理探索 (一)
文章目录git 最小配置作用域git 创建本地仓库git log 查看版本演进.git 目录refs目录objectsgit 三种对象类型详解 (commit ,tree,blob)因为工作需求,接下来将从git的使用到其内部工作原理,来避免代码提交或者review或者版本管理上的一些尴尬,…
php表单退出怎么写,PHP提交表单失败后如何保留填写的信息
[导读]本文章来给各位同学介绍PHP提交表单失败后如何保留填写的信息一些方法总结,最常用的就是使用缓存方式了,这种方法如果网速慢是可能出问题的,最好的办法就是使用ajax了。1.使用header头设置缓存控制头Cache-c本文章来给各位同…
lists,tuples and sets of Python
(python2.7.x) Lists 列表 列表是一个有序序列(集合),可变的(可以修改),可以理解为其他语言中的数组类型,但是列表更灵活更强大。 列表由方括号[]来定义的,它的元素可以是任意类型或对象,一个列…
Javascript中使用WScript.Shell对象执行.bat文件和cmd命令
WScript.Shell(Windows Script Host Runtime Library)是一个对象,对应的文件是C:/WINDOWS/system32/wshom.ocx,Wscript.shell是服务器系统会用到的一种组件。shell 就是“壳”的意思,这个对象可以执行操作系统外壳常用…
控件绘制的方法
1处理WM_PAINT 最极端的选择是执行一个 WM_PAINT 处理程序,并且自己完成所有的绘制。这意味着,您的代码将需要进行一些与呈现控件相关的琐事 — 创建适当的设备上下文(一个或多个),决定控件的大小和位置,绘…
google gflags的参数解析,便捷实用
命令行参数解析,一直是我们后段开发人员需要经常使用的一个功能,用来从终端解析接口的输入 ,并做出对应的处理。这里为使用C/python的开发人员推荐一个便捷的命令行解析接口集 gflags。 我们之前使用C的getopt/getopt_long 函数需要自己使用…
linux进程下的线程数,Linux下查看进程线程数的方法
0x01:ps -ef只打印进程,而ps -eLf会打印所有的线程[rootcentos6 ~]# ps -ef | grep rsyslogdroot 1470 1 0 2011 ? 00:01:13 /sbin/rsyslogd -c 4root 29865 28596 0 22:45 pts/5 00:00:00 grep rsyslogd[rootcentos6 ~]# ps…

OpenCV学习(20) grabcut分割算法
在OpenCV中,实现了grabcut分割算法,该算法可以方便的分割出前景图像,操作简单,而且分割的效果很好。算法的原理参见papaer:“GrabCut” — Interactive Foreground Extraction using Iterated Graph Cuts 比如下面的一…
VMware workstation中rhel安装VMware tools失败
切换登录用户为root即可转载于:https://www.cnblogs.com/dazzleC/p/10555809.html
g-git 相关命令 及其 基本原理探索(二):git 在工作中的常用命令操作 ,超级实用!!!
上一篇git 基本原理对git的使用以及文件分布已经有了一个整体的了解。 本篇将对工作中常用的一些git 操作命令的操作进行总结归纳,方便今后查阅。 文章目录1. 分离头指针2. 通过HEAD 来进行不同提交的差异对比3. 删除不需要的分支4. 对当前分支最近一次提交的messag…
Linux中的文件寻址,Linux文件寻址算法:逻辑地址到物理地址的转换
题目描述:编写一个函数实现Linux文件寻址的算法,即读取文件当前位置到物理存储位置的转换函数,需要给出运行的测试数据,可以假设和模拟需要的数据和结构。即编写一个函数unsigned long ltop(unsigned long logblkNum). 计算逻辑块…
datatable和dataset的区别
DataSet 是离线的数据源 DataTable 是数据源中的表.当然也可以自己建一张虚表。插入数据库中 DataSet是DataTable的容器DataSet可以比作一个内存中的数据库,DataTable是一个内存中的数据表,DataSet里可以存储多个DataTabledatatable是dataset中的一个表另…
如何避免重构带来的危险
http://blog.jobbole.com/30049/ 重构代码很危险,它会给测试工作增加巨大的负担。除非你的程序需要重构,一定不要轻易重构代码。我这里所说的并不是把一个for循环改成while循环,或把一个StringBuffer改成StringBuilder,我说的是大…
ip通信(第二周)
计算机网络分为局域网(LAN)、城域网(MAN)和广域网(WAN)。拓扑结构分为星型网,树形网,分布式网络,总线型网络,环型网络和复合型网络。认识了几个常见的国际标准…
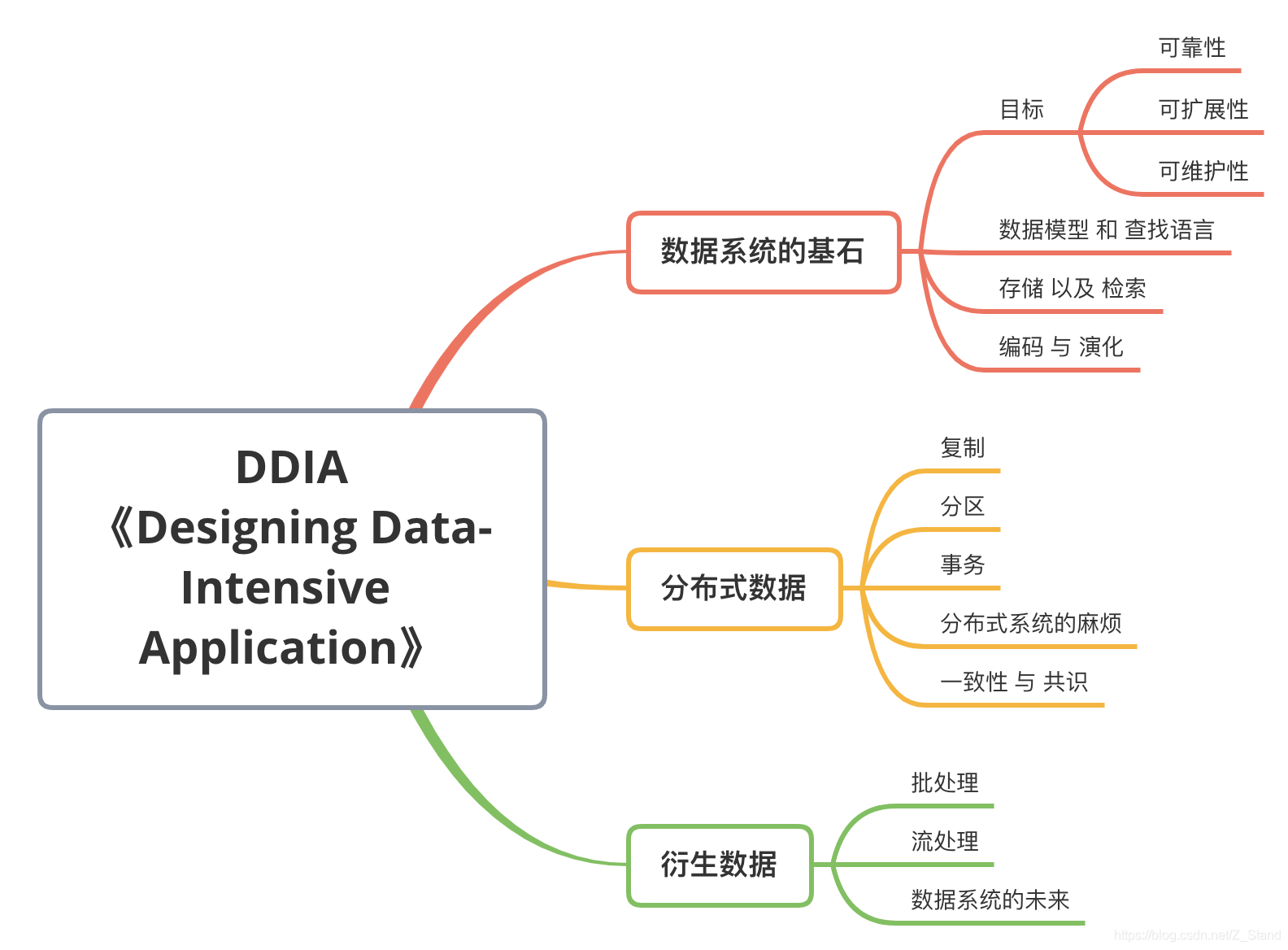
《DDIA》读书笔记
数据存储系统的经典书籍: 从数据系统的特性开始,先讲单机存储引擎 再到 分布式存储系统,最后到一些数据流的处理方式,作者深入浅出,译者更是精雕细琢,本书需要细品。 将持续阅读整理,先从理论走…
linux网卡设置adsl上网,Linux下设置ADSL自动拨号上网
前段时间下载了红帽的linux,版本为redhat 9.0,整整刻了三张CD。最初是为了体验一下linux下QQ聊天软件的功能,最后因内核太低(官方推荐内核在2.6以上,我下载的版本是2.4)而告终。最大的收获是了解了linux下文件系统及linux下软件与…
安卓天天酷跑脚本刷高分图文教程
http://news.gamedog.cn/a/20130923/241742.html

SpringBoot 中 JPA 的使用
前言 第一次使用 Spring JPA 的时候,感觉这东西简直就是神器,几乎不需要写什么关于数据库访问的代码一个基本的 CURD 的功能就出来了。下面我们就用一个例子来讲述以下 JPA 使用的基本操作。 新建项目,增加依赖 在 Intellij IDEA 里面新建一个…

《DDIA》读书笔记(一):可靠性、可扩展性、可维护性
这一节描述了密集型应用的基本思考方式。 可靠性。意味着系统发生故障,也能保持正常的运行。故障会集中在三个方面,硬件故障(通常是随机和不相关的)、软件故障(通常是系统性的bug,较难发现,较难处理),人为故障(不可避免得时不时出…
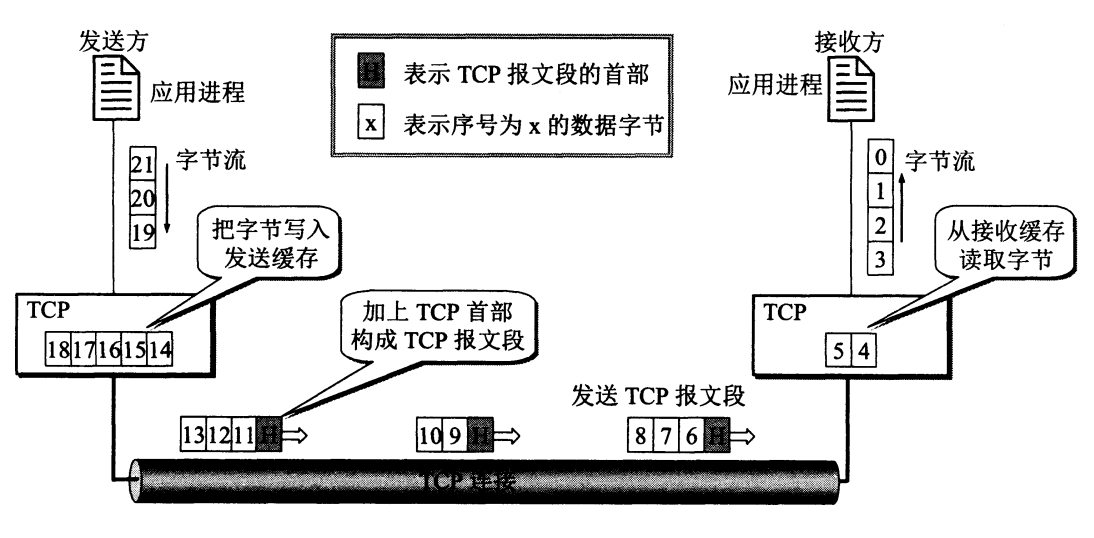
TCP协议-TCP连接管理
TCP协议是 TCP/IP 协议族中一个非常重要的协议。它是一种面向连接、提供可靠服务、面向字节流的传输层通信协议。TCP(Transmission Control Protocol,传输控制协议)。

[Unity WWW] 跨域访问解决方法
什么是跨域访问 域(Domain)是Windows网络中独立运行的单位,域之间相互访问则需要建立信任关系(即Trust Relation)。信任关系是连接在域与域之间的桥梁。当一个域与其他域建立了信任关系后,2个域之间不但可以按需要相互进行管理,还可以跨网分配…
linux环境安全测评实验报告,linux第一次实验报告
iframe载入页面过程显示动画效果http://www.xfeixiang.com/Bug/Detail/A2FD7EFFA8CA72F1加密算法使用(三):用用BASE64采用Base64编码具有不可读性,即所编码的数据不会被人用肉眼所直接看到 package testEncrypt; import java.security.Key; import java.secu ...jav…
2019-03-20 Python爬取需要登录的有验证码的网站
当你向验证码发起请求的时候,就有session了,记录下这次session因为每当你请求一次验证码 或者 请求一次登录首页,验证码都在变动验证码的链接可能不是固定的,可能需要GET/POST请求,获取那部分变动的信息 session requests.sessio…

Mac上 如何快速玩起rocksdb
想要自己随时随地写一写rocksdb的代码,并且快速测试,但是公司的物理机登陆过于麻烦,想要验证功能的话其实在自己的电脑就完全可以了。 安装 brew install rocksdb,默认二进制文件安装在/usr/local/bin在~/.bashrc或者自己正在使用…
OC学习篇之---对象的拷贝
在前一篇文章中我们说到了如何解决对象的循环引用问题:http://blog.csdn.net/jiangwei0910410003/article/details/41926369,这一篇文章我们就来介绍一下OC中的对象拷贝概念,这个对于面向对象语言中都会有这种的问题,只是不同的语…

linux脚本自定义赋值,JMeter——运用BeanShell给自定义的变量动态赋值
这个计划中定义了以下组件:用户自定义变量:里面定义了2个变量,一个是us(注意,未对它初始化),一个变量名是:test ,值为:123456一个BeanShell Sampler:${test}表示传入BeanShell Sampl…