C++ 从双重检查锁定问题 到 内存屏障的一些思考
文章目录
- 1. 问题描述
- 2. DCLP 的问题 和 指令执行顺序
- 2.1 Volatile 关键字
- 2.2 C++11 的内存模型
- 3. C++11内存模型 解决DCLP问题
- 3.1 内存屏障和获得、释放语义
- 3.2 atomic 的完整介绍
- 3.2.1 原子操作的三种类型
- 3.2.2 atomic 内存序
- 3.2.3 atomic 成员函数
- 4. 总结
1. 问题描述
单例模式 是我们日常编码过程中比较常用的一种设计模式,用来对一个抽象进行限定,表示该类在当前程序生命周期内仅能创建一次,被整个进程空间共享。
比如 FPGA处理单元在我们实际的处理过程中仅能拥有一个实例来完成Compaction操作,那么便可以将FPGA的处理过程抽象为一个单例模式,在整个进程启动之后有且仅有一个FPGA实例完成整个rocksdb的compaction 过程。
查看如下单例代码
#include <iostream>
// header file
class Singleton{
private:static Singleton *instance;Singleton(){}
public:static Singleton *get_instance();
};// implemetation file
Singleton *Singleton::instance = NULL;Singleton *Singleton::get_instance() {if(Singleton::instance == NULL) {Singleton::instance = new Singleton(); }return instance;
}int main() {Singleton *test = Singleton::get_instance();..... // do somethingreturn 0;
}
以上代码是经典懒汉模式(延迟加载)下实现的单例模式,主要通过get_instance函数创建单例;
这种实现在单线程下是完全满足要求的,对于还未创建的单例,通过判断静态数据成员的单例实例Singleton::instance是否为空来确定之前是否创建过单例实例,如果没有,则创建。后续的单例创建 则会直接返回之前创建的单例实例地址,并不会创建新的单例实例。
但是在多线程模式下这样的实现并不可靠,每个线程拥有各自的函数栈空间,虽然指令层级是串型执行,但在进/线程层级看起来是并行执行的。
比如线程A进入了get_instance函数,判断Singleton::intance实例为空,并准备创建新的单例实例 但还味创建。此时线程B 也进入到了get_instance函数,因为A还没有创建Singleton::intance实例,则线程B也判断其为空,此时就会出现两个线程各自创建了自己的单例实例。这样的结果显然违背了单例模式实现的初衷。
那么对于以上多线程下单例的实现问题, 很容易便可以通过加锁来解决,如下代码:
std::mutex g_lock;
class Singleton{
private:static Singleton *instance;Singleton(){}
public:static Singleton *get_instance();
};Singleton *Singleton::instance = NULL;Singleton *Singleton::get_instance() {std::lock_guard<std::mutex> lock(g_lock); // 一进入函数即加锁,来独占接下来的逻辑操作if(instance == NULL) {instance = new Singleton(); }return instance;
}
这样确实能够保证多线程下的单例创建的可靠性,一进入get_instance函数通过锁来独占后续的CPU。
显然这样的实现在多线程模型下非常昂贵,对于每一个执行get_instance函数的线程都需要独占整个CPU ,而我们实际仅仅需要在该函数内部执行真正创建instance实例的时候才需要加锁,所以直接粗暴的加锁方法并不是最好的实现。
这个时候DCLP(Double-Check Locking Pattern) 双重检查锁定 通过观察instance实例是否为空来判断是否需要进行加锁,这样便能够避免每一个进入get_instance函数的线程独占CPU的情况。
如下代码:
std::mutex g_lock;
class Singleton{
private:static Singleton *instance;Singleton(){}
public:static Singleton *get_instance();
};Singleton *Singleton::instance = NULL;// DCLP implementation
Singleton *Singleton::get_instance() {if(instance == NULL) { // 第一重检查std::lock_guard<std::mutex> lock(g_lock);if(instance == NULL) { // 第二重检查instance = new Singleton(); }}return instance;
}
现在来看这样的实现既能够保证多线程下的可靠性 又能满足我们想要的性能。
那么文章到此就结束了吗? 这样的思考并不够深入,以上的实现能够安全的在单处理器的设备上稳定运行,但是在我们如今以多处理器为主的设备上还是不够安全,接下来就需要讨论一下多处理器下的指令顺序问题。
2. DCLP 的问题 和 指令执行顺序
继续看我们节中实现的**双重检查锁定(DCLP)**的代码,其中在加锁的逻辑中通过检查instance成员是否为空来决定是否实例话还成员。
具体实例化的代码如下:
instance = new Singleton();
这一行代码在C++的语义中又可以被进一步拆分为如下几步:
- 为先为
Singleton对象分配内存 - 初始化
Singleton类,将该类的数据成员填充到分配好的内存之中 - 创建一个
instance指针,指向已经分配好的内存
这里有非常关键的一点是 编译器并不会严格按照上述的三个步骤执行实例化instance成员的逻辑。在某一些场景下,编译器能够支持第二步和第三步交换执行。关于编译器为什么会这样做,接下来会详细提到。先将讨论重心放在第二步和第三步如果发生了交换之后所产生的后果之上。
如下代码展示了实例化过程中 第二步(初始化 Singleton)和 第三步(赋值Singleton地址) 交换的逻辑(实际代码我们并不会这样写,这里仅仅为了展示):
Singleton *Singleton::get_instance() {if(instance == NULL) {std::lock_guard<std::mutex> lock(g_lock);if(instance == NULL) {instance = // 第三步operator new(sizeof(Singleton)); // 第一步new (instance)Singleton; // 第二步}}return instance;
}
通常情况下,以上代码并不是对于DCLP实现的完整解释,单例模式的构造器在 调用到第二步的时候会抛异常;且大部分的场景编译器并不会将 第三步 的执行顺序放在第二步之前,但是以上的情况是存在的,最简单的一种情况是编译器可以保证Singleton构造函数不会抛出异常(例如通过内联化后的流分析(post-inlining flow analysis),当然这不是唯一情况。
针对以上拆分实例化过程 可能出现的问题 举例如下:
- 线程A进入到
get_instance函数,进行第一次instance判空的检查通过。获取到全局锁,进入到第二次判空逻辑。并执行由第三步和第一步组成的语句。接下来简单暂停一下,执行到这里instance 成员因为已经分配了内存地址,并不为空。但此时instance指向的内存中并未填充Singleton类中的成员数据。 - 此时线程B进入到
get_instance函数中,进行第一次的instance成员判空的检查,发现并不为空,则直接返回instance成员的地址,认为instance成员已经实例化完成,并且释放该函数内 instance 指针指向的地址,然而这样的返回值并没有完成真正意义的单例对象创建。
所以双重检查锁定(DCLP) 当且仅当 第一步和第二步 在第三步之前执行时才能够保证多线程,多处理器下的可靠性。但是这在C/C++语言中 并不能真正意义上保证这种逻辑下的执行执行顺序,也就是说多线程这样的概念在C/C++语言中并不存在。
看看如下非常简单的代码:
void foo() {int x = 0, y = 0; // 语句1x = 5; // 语句2y = 10; // 语句3printf("x=%d, y=%d\n", x, y); // 语句4
}
通过设置编译器的优化选项 能够看到具体语句1-4并不一定按照函数设置的语句逻辑来执行。
如下,从上到下依次是为开启编译器的优化选项,开启-O1优化选项,开启-O2优化选项的结果
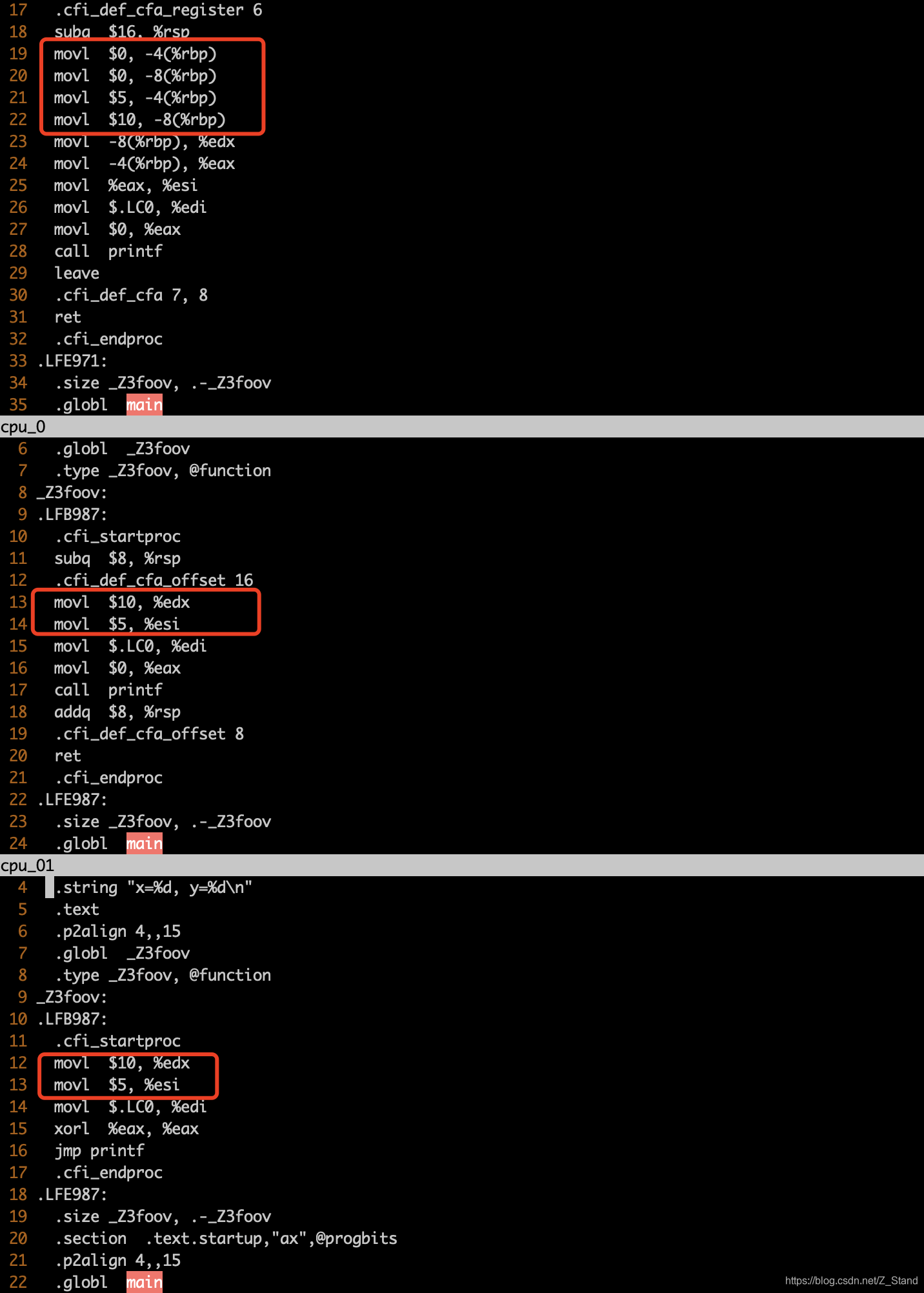
那么C/C++程序员如何 写出正常工作的多线程程序呢?也就是我们经常使用的线程库(Posix的pthreads线程库)。多线程程序的编译和链接需要依赖这一些线程库,这一些线程库的实现也已经经过严格的规范来约束关键指令的执行顺序(核心实现通过汇编语言来完成),保证不会受到编译器的优化干扰产生指令的重新排序。
然而针对DLCP这样的代码我们想要跳出编译器对执行指令的约束,使用一种语言(C++实现)是无法达到跳出约束的目的,那么作为程序员,我们想要摆脱编译器对我们的代码的优化,针对DLCP 这样的代,尝试这样的逻辑。
在instance未完成初始化之前,不对instance做出任何修改:
Singleton *Singleton::get_instance() {if(instance == NULL) {std::lock_guard<std::mutex> lock(g_lock);if(instance == NULL) {Singleton *tmp = new Singleton();instance = tmp;}}return instance;
}
这样的代码 在那一些老奸巨猾的编译器优化程序员的眼中可是无用代码的,使用了优化选项之后 tmp的初始化显然并不会被真正执行到,正如foo代码之中的O1以上的优化选项,对于代码开头x=0,y=0这样的代码是直接跳过的。
如果我们想用一种语言和那一些专注于编译器优化几十年的老程序员比拼实力,显然没有人家在行,分分钟钟将你不想被编译器优化的代码给优化掉。。。。
同时 ,在多处理器环境下,每个处理器都有各自的高速缓存,但所有处理器共享内存空间。这种架构需要设计者精确定义一个处理器该如何向共享内存执行写操作,又何时执行读操作,并使这个过程对其他处理器可见。我们很容易想象这样的场景:当某一个处理器在自己的高速缓存中更新的某个共享变量的值,但它并没有将该值更新至共享主存中,更不用说将该值更新到其他处理器的缓存中了。这种缓存间共享变量值不一致的情况被称为缓存一致性问题(cache coherency problem)。
假设处理器A改变了共享变量x的值,之后又改变了共享变量y的值,那么这些新值必须更新至内存中,这样其他处理器才能看到这些改变。然而,由于按地址顺序递增刷新缓存更高效,所以如果y的地址小于x的地址,那么y很有可能先于x更新至主存中。这样就导致其他处理器认为y值的改变是先于x值的。
对DCLP而言,这种可能性将是一个严重的问题。正确的Singleton初始化要求先初始化Singleton对象,再初始化 Instance。如果在处理器A上运行的线程是按正确顺序执行,但处理器B上的线程却将两个步骤调换顺序,那么处理器B上的线程又会导致pInstance被赋值为未完成初始化的Singleton对象。

那么问题来了,怎么能够让我们的C++代码指令顺序 在多处理器上 按照我们自己的想法来执行呢?
2.1 Volatile 关键字
在某一些编译器中使用volatile 关键字可以达到内存同步的效果。但是我们必须记住,这不是volatitle的设计意图,也不能通用地达到内存同步的效果。volatitle的语义只是防止编译器“优化”掉对内存的读写而已。它的合适用法,目前主要是用来读写映射到内存地址上的IO操作。
由于volatile 不能在多处理器的环境下确保多个线程看到同样顺序的数据变化,在今天的通用程序中,不应该再看到volatitle的出现。
2.2 C++11 的内存模型
为了从根本上解决上述问题,C++11 引入了更适合多线程的内存模型。
跟我们实际开发过程密切相关的是:原子对象(atomic),使用原子对象的获得(acquire)、释放(release)语义,可以真正精确地控制内存访问的顺序性,保证我们需要的内存序。
3. C++11内存模型 解决DCLP问题
3.1 内存屏障和获得、释放语义
现在有两个全局变量:
int x = 0;
int y = 0;
在一个线程内执行:
x = 1;
y = 2;
在另一个线程执行:
if (y ==2) {x = 3;y = 4;
}
这样的代码按我们正常立即的程序逻辑来看,x和y的结果有两种可能:1,2 和 3,4
但是之前已经对编译器的优化选项导致的指令序列不同 以及 多处理器场景下内存访问问题 可能还会出现x和y的结果是1,4的情景(编译器优化后的执行序 y先于x赋值 或者 多处理器场景下y在内存中的地址低于x 也可能出现y先于x赋值)。
我们想要满足程序员心中的完全存储序,就需要在x=1和y=2两个语句之间加入内存屏障,从而禁止这两个语句交换顺序。这种情况下最常用的两个概念是“获得”和 “释放”:
- 获得 是对一个内存的 读 操作,当前线程后续的任何读写操作都不允许重排到这个操作之前
- 释放 是对一个内存的 写 操作,当前线程的任何前面读写操作都不允许重排到这个操作之后
比如上面的代码段,我们需要将y 声明成 atomic<int>。然后在线程1中需要使用释放语义:
x = 1;
y.store(2, memory_order_release);
在线程2 我们需要对y 的读取使用获得语义,但存储只需要松散的内存序即可:
if (y.load(memory_order_acquire) == 2) {x = 3;y.store(4, memory_order_relaxed);
}
如下图,两边的代码重排之后不允许越过虚线,如果y上的释放早于y上的获取,释放前 对内存的修改都在另一个线程的获取操作后可见。

实际编码过程中,我们把y直接改成atomic<int>之后,两个线程的代码不做任何的变更执行结果都会是符合我们预期的,因为atomic 变量的写操作默认是释放语义,读操作默认是获得语义。
y = 2相当于y.store(2, memory_order_release)y==2相当于y.load(memory_order_acquire) == 2
那为什么要说显式得使用内存屏障的获得释放语义呢,因为缺省行为对性能不利:我们不需要在任何情况下都要保证操作的顺序性。
另外,我们应当注意 acquire和release 通常都是配对出现的,目的是保证如果对同一个原子对象的release 发生在acquire 之前,release之前发生的内存修改都能够被acquire之后的内存读取全部看到。
比如 第一个线程y=2是在第二个线程y==2之前完成的,那么y=2之前针对x代表的内存的修改 是能够被y==2之后的语句看到。
3.2 atomic 的完整介绍
C++11 在<atomic> 头文件中引入了 atomic 模版,对原子对象进行封装,让我们能够应用到任何类型之上。当然这个过程对于不同类型的效果是不同的,对于整型量和指针等简单类型,通常结果是无锁的原子对象;而对于另外一些类型,比如64位机器上 大小不是1,2,4,8 的类型,编译器会自动为这一些原子对象的操作加上锁。同时,编译器也提供了原子对象的成员函数is_lock_free 能够检查这个原子对象上的操作是否是无锁操作。
3.2.1 原子操作的三种类型
- 读 : 读取的过程中,读取位置的内容不会发生任何变动
- 写 : 在写入的过程中,其他执行线程不会看到部分写入的结果(比如多处理器场景:写入先写到CPU cache,再写入到内存中,这两个操作都完成才算当前写入完成)
- 读-修改-写: 读取内存,修改数值,写回内存。整个操作的过程中间不会有其他写入操作插入,同时其他线程也不会看到中间结果。
3.2.2 atomic 内存序
memory_order_relaxed松散内存序,只用来保证对原子对象的操作是原子的memory_order_consume消费语义,和acquire类似,只是在部分平台的效果更好。更加详细的介绍可以参考memory_order_consumememory_order_acquire获得操作,在读取某原子对象时,当前线程的任何后面的读写操作都不允许重排到这个操作的前面,并且其他线程在对同一个原子对象释放之前的所有内存写入操作在当前线程都是可见的。memory_order_release释放操作,在写入某原子对象时,当前线程的任何前面的读写操作都不允许重排到这个操作的后面,并且当前线程的所有内存写入都在对同一个原子对象进行获取的其他线程可见。memory_order_acq_rel获得释放操作,一个读-修改-写操作 同时具有获得语义和释放语义,即它前后的任何读写操作都不允许重排,并且其他线程在对同一个原子对象释放之前的所有内存写入都在当前线程可见,当前线程的所有内存写入都在对同一个原子对象进行获取的其他线程可见。memory_order_seq_cst顺序一致性语义,对于读操作相当于获取,对于写操作相当于释放,对于读-修改-写 操作相当于获得释放,是所有原子操作的默认内存序。
3.2.3 atomic 成员函数
- 默认构造函数(只支持初始化零)
- 拷贝构造函数被删除
- 使用内置对象类型的构造函数(不是原子操作)
- 可以从内置对象类型赋值到原子对象(相当于store)
- 可以从原子对象隐式转换成内置对象(相当于load)
- store, 写入数据到原子对象,第二个可选参数是内存序类型
- load,从原子对象读取内置对象,有一个可选参数是内存序类型
- is_lock_free, 判断原子对象的操作是否无锁(是否可以用处理器指令直接完成原子操作)
- exchange , 交换操作,第二个可选参数是内存序类型(读-修改-写 操作)
- compare_exchange_weak 和 compare_exchange_strong,两个比较加交换(CAS)版本,可以分别制定成功和失败时的内存序,也可以只制定一个,或者使用默认的最安全的内存序--
memory_order_seq_cst顺序一致性语义。 (同样是 读-修改-写 操作) - fetch_add 和 fetch_sub ,仅对整数和指针 内置对象生效。对目标原子对象执行加 或 减操作,返回其原始数值,第二个可选参数是内存序类型。(同样是 读-修改-写 操作)
- ++ 和 – (前置和后置) ,仅对整数和指针 内置对象生效。对目标原子对象执行加一 或 减一操作,使用顺序一致性语义,返回的并不是原子对象的引用。(读–修改–写 操作)
- += 和 -= ,仅对整数和指针内置对象有效,对目标原子对象执行 加 或减操作, 返回操作后的数值。操作使用顺序一致性语义,且返回的并不少原子对象的引用(读-修改-写 操作)
有了对atomic 内存模型的理解之后 我们在一些全局共享变量的原子性维护上 就可以使用std::atomic_int count_;这样的形式了。
这样的声明 在后续的 原子对象的自增自减 过程中 使用的是默认内存序类型(顺序一致性),其实整体的代价还是有有点大,因为顺序一致性是需要完整执行 获取加释放语义。
那么自增的实现可以通过如下定义完成:
void add_count() noexcept
{count_.fetch_add(1,std::memory_order_relaxed);
}
仅需增加内存的松散内存序,保证自增操作的原子性即可。
4. 总结
我们讨论了 从单例模式 在并发场景出现的问题,到使用锁来解决问题,到为了更可靠 和更高效 而提出DCLP,又因为编译器的指令重排和多处理器的内存一致性问题 而提出对DCLP的质疑,感觉一个线程安全的实现是如此之艰难,和CPU缓存/内存 几十年的编译器优化程序员博弈 中 被人家吊打。
最后终于在C++11 的实现中看到了曙光,简单 清晰得内存屏障。乌干达儿童终于 从编译器的指令重排 和 内存一致性问题 的苦难中 走了出来。
相关文章:

android系统的iphone,iPhone上安装Android系统详细步骤。
该楼层疑似违规已被系统折叠 隐藏此楼查看此楼在iphone安装android系统的详细步骤首先,准备好iphone的多点触屏和wlan固件。因为法律的缘故,我们不能分享这些文件,你可以去ipsw文件里提取或去marvell网站下载。1、在linux的home目录下创建一个…
Linux下GCC和Makefile实例(从GCC的编译到Makefile的引入) 转
http://www.crazyant.net/2011/10/29/linux%E4%B8%8Bgcc%E5%92%8Cmakefile%E5%AE%9E%E4%BE%8B%EF%BC%88%E4%BB%8Egcc%E7%9A%84%E7%BC%96%E8%AF%91%E5%88%B0makefile%E7%9A%84%E5%BC%95%E5%85%A5%EF%BC%89/ 很给力的说,回头去搞搞!
服务端如何识别是selenium在访问以及解决方案参考二
有不少朋友在开发爬虫的过程中喜欢使用Selenium Chromedriver,以为这样就能做到不被网站的反爬虫机制发现。 先不说淘宝这种基于用户行为的反爬虫策略,仅仅是一个普通的小网站,使用一行Javascript代码,就能轻轻松松识别你是否使用…
LSM 优化系列(二)-- dCompaction: Speeding up Compaction of the LSM-Tree via Delayed Compaction
文章目录背景描述dCompaction设计触发条件 VCT触发VT 合并的条件 VSMT测试数据优化的重心集中在减少写放大上,同时将读性能维持在和rocksdb 原生读性能接近,优化思想是中国科学院的2位博士 提出的。论文原地址:dCompaction: Speeding up Comp…
Android应用系列:完美运行GIF格式的ImageView(附源码)
前言 我们都知道ImageView是不能完美加载Gif格式的图片,如果我们在ImageView中src指定的资源是gif格式的话,我们将会惊喜的发觉画面永远停留在第一帧,也就是不会有动画效果。当然,经过略加改造,我们是可以让gif在Image…
wordpress怎么修改html,WordPress后台编辑器HTML模式界面中添加修改删除按钮
在WordPress编辑器HTML模式界面中添加按钮一文中,我大致介绍了怎么在后台添加一些自定义的按钮,本文则更为详细全面的对wordpress后台编辑器HTML模式下的按钮自定义进行详解,以让开发者肆意的修改按钮及其布局。自定义按钮起效的两种途径 ↑首…
OCA读书笔记(9) - 管理数据同步
9.Managing Data Concurrency 描述锁机制以及oracle如何管理数据一致性监控和解决锁冲突 管理数据的并发--管理锁数据的不一致:脏读更改丢失幻影读 脏读:数据是指事务T2修改某一数据,并将其写回磁盘,事务T1读取同一数据后,T2由于某…
Java EE学习笔记(四)
Spring的数据库开发 1、Spring JDBC 1)、Spring JDBC模块的作用:Spring的JDBC模块负责数据库资源管理和错误处理,大大简化了开发人员对数据库的操作,使得开发人员可以从繁琐的数据库操作中解脱出来,从而将更多的精力投入到编写业务…

SpringBoot 中实现订单30分钟自动取消的策略
在电商和其他涉及到在线支付的应用中,通常需要实现一个功能:如果用户在生成订单后的一定时间内未完成支付,系统将自动取消该订单。本文将详细介绍基于Spring Boot框架实现订单30分钟内未支付自动取消的几种方案,并提供实例代码。
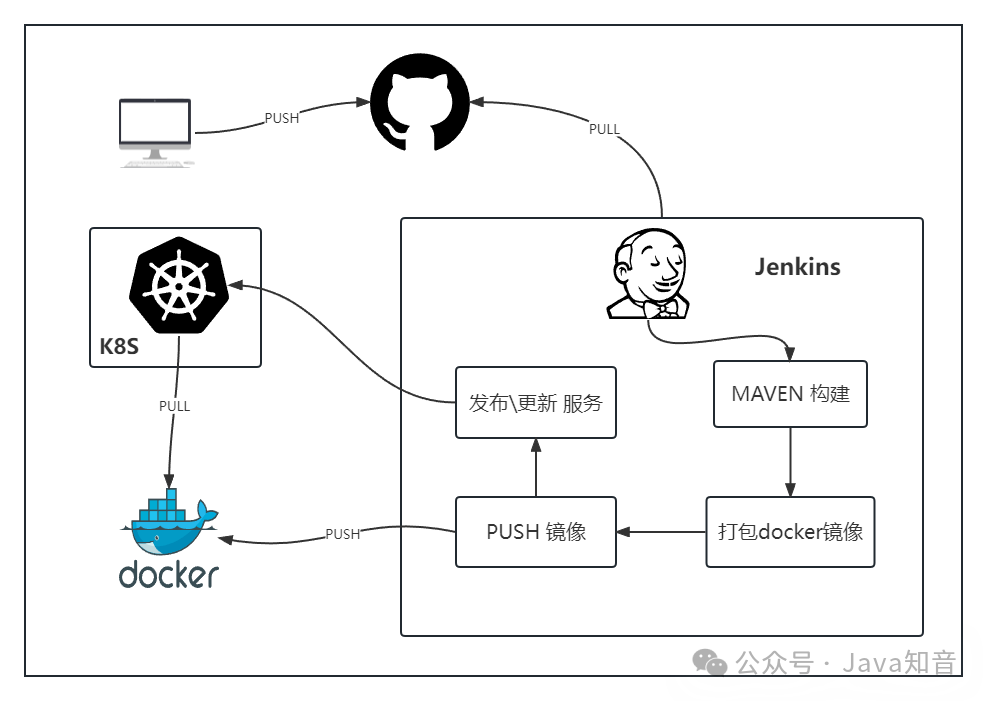
一键部署 SpringCloud 微服务,这套流程值得学习一波儿!
一键部署 springcloud 微服务,需要用到 Jenkins K8S Docker等工具。本文使用jenkins部署,流程如下图开发者将代码push到git运维人员通过jenkins部署,自动到git上pull代码通过maven构建代码将maven构建后的jar打包成docker镜像 并 push docker镜像到docker registry通过k8s发起 发布/更新 服务 操作其中 2~5步骤都会在jenkins中进行操作。
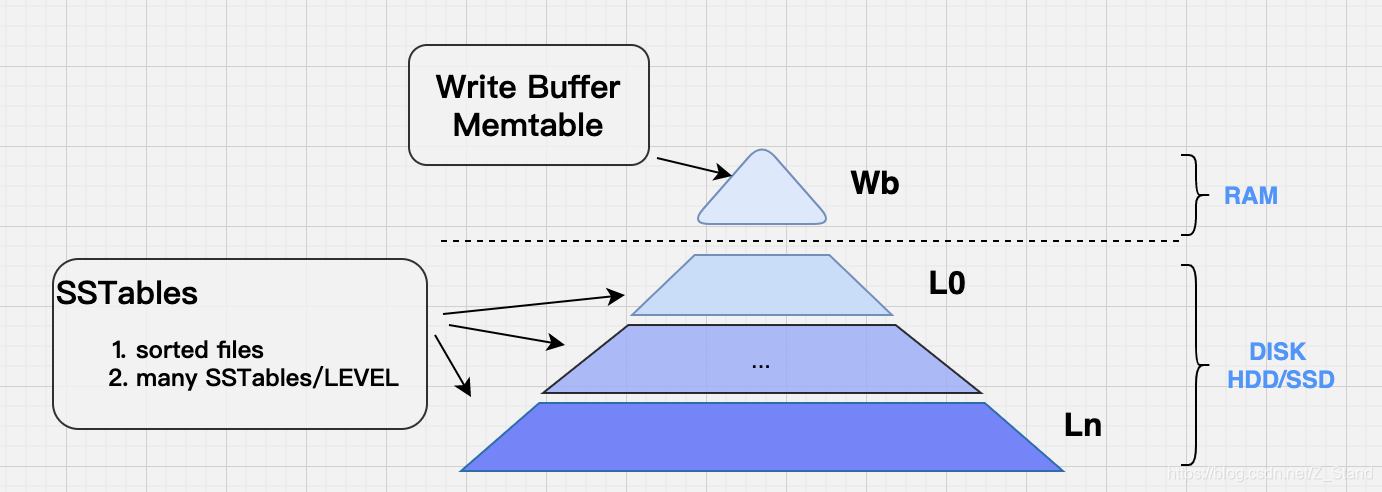
Rocksdb 的 rate_limiter实现 -- compaction限速
文章目录前言1. Compaction为什么会影响Client qps1.1 基本LSM介绍1.2 LSM internal ops1.3 长尾延时的原因2. Rate limiter 基本限速接口3. Rate Limiter 限速原理实现3.1 Rate Limiter的传入3.2 Rate Limiter 控制 sync datablock的速率3.3 Rate Limiter控制写入速率4. rocks…
Oracle --获取绑定变量的值.
SELECT * FROM DBA_HIST_SQLBIND WHERE SNAP_ID>67073 AND SNAP_ID<67079 AND SQL_ID3DR3410F086P4;SELECT * FROM v$sql_bind_capture where sql_id http://blog.itpub.net/22034023/viewspace-689802/ 通过v$sql_bind_capture视图,可以查看绑定变量…

计算机网络TCP/IP协议-从双绞线到TCP
消息响应也是同理,这种带端口的消息发送方式,其实就是UDP协议,UDP简单粗暴,但是UDP存在很多问题,所以我们需要设计一个稳定可靠的协议,TCP协议,首先,网络是不稳定的,我们发送的消息很有可能会在中途丢失,所以需要设置重试机制,当消息发送失败时重新发送,为了判断是否成功,还需要要求接收方收到消息后,必须发送确认消息,这样就可以保证消息必达,另外大段的内容发送,很容易造成部分丢失,导致全部内容都要重新发送,于是我们可以将数据分包,分成多个包发送。到这,也行你会发现了,演示中的IP地址是怎么设置的呢?

使用HTML CSS完成初步的页面,任务九:使用HTML/CSS实现一个复杂页面(示例代码)
任务目的通过实现一个较为复杂的页面,加深对于HTML,CSS的实战能力实践代码的复用、优化任务描述整个页面内容宽度固定,但头部的蓝色导航和浏览器宽度保持一致任务注意事项只需要完成HTML,CSS代码编写,不需要写JavaScri…
Yii-yiic使用
原文在:http://blog.sina.com.cn/s/blog_862b12fb0101n00v.htmlyii提供了强大的命令行工具来快速的创建相关组件和应用。下面就来讲解用yiic工具快速创建yii应用我的web目录在d:\ EasyPHP-DevServer\data\localweb下;yiiframework在D:\EasyPHP-DevServer…
nginx语法
一、 1. 配置文件由指令与指令块构成; 2. 每条指令以;分号结尾,指令与参数间以空格符号分隔; 3. 指令块以{} 大括号将多条指令组在一起; 4. include语句允许组合多个配置文件以提升可维护性; 5. 使用#符号添…

如何对 Rocksdb以及类似存储引擎社区 提出 有效的性能问题?
性能 是rocksdb的优点,活跃的社区十分欢迎大家对各自使用rocksdb 过程中性能相关的疑惑点进行提问。提问的时候如果能够提供更多,更详细的信息 是可以增加快速得到恢复回复的概率。当然,性能是一个非常广泛且有巨量影响因素的话题,…
我已经喜欢上了Python
早就听说了Python语言,今天试了试,挺喜欢她了。 Python 3.4.2 (v3.4.2:ab2c023a9432, Oct 6 2014, 22:15:05) [MSC v.1600 32 bit (Intel)] on win32Type "copyright", "credits" or "license()" for more information.&g…

layui跳转html如何带参数,Layui跳转页面代码(可携带复杂参数)
今天用了Layui的“数据表格 - 数据操作”示例代码,结果发现点击“编辑”按钮出出来一个弹出消息框,效果如下:虽然说也可以用“弹出层”做编辑页面,但是,由于我编辑的东西很多,用“弹出层”不太理想。我就想…
java获取日期
/* * 获取昨天日期 方法一,这个方法好像有点慢 */Date dt new Date(); Calendar cal Calendar.getInstance();cal.add(Calendar.DATE, -1);time new SimpleDateFormat( "yyyy-MM-dd").format(cal.getTime()); /* * 获取昨天日期 方法二 */Date as ne…
DRF (Django REST framework) 中的视图类
视图说明 1. 两个基类 1)APIView rest_framework.views.APIView APIView是REST framework提供的所有视图的基类,继承自Django的View父类。 APIView与View的不同之处在于: 传入到视图方法中的是REST framework的Request对象,而不是…

Go:分布式学习利器(1) -- 开发环境搭建 + 运行第一个go程序
文章目录为什么要学习 go开发环境搭建 -- MAC运行第一个go程序go 函数的返回值设置go 函数的命令行参数为什么要学习 go 在如下几个应用场景的需求下产生了go: 超大规模分布式计算集群多核硬件的架构web模式下的大规模开发和频繁的进度更新 所以go 语言有如下几个特点&#…
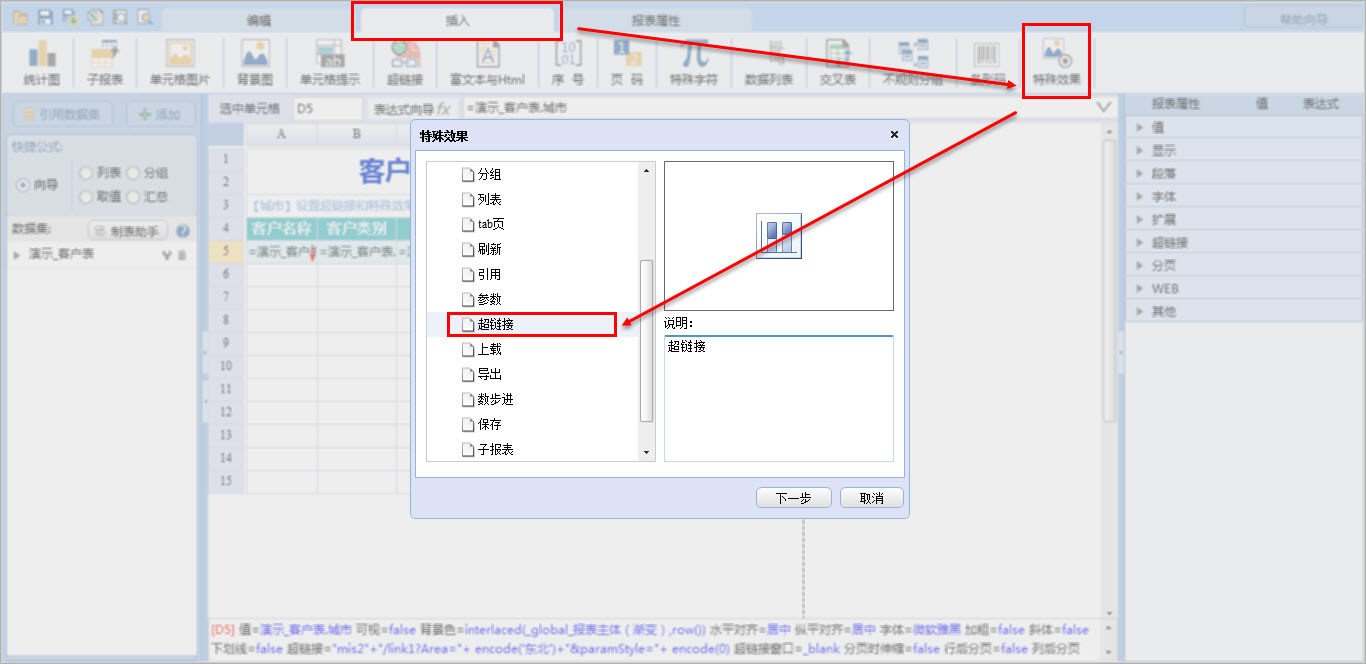
html生成的超级链接预览功能,超链接特效
功能说明超链接特效功能是基于报表特殊效果功能的一种扩展实现。报表特殊效果功能的作用是为单元格添加一些特殊的显示效果。超链接特效可以给超链接添加特殊显示效果,实现超链接功能的扩展增强。当产品默认生成的超链接显示效果不能满足用户的个性化需求时…
ROOT android 原理。 基于(zergRush)
出自: http://bbs.gfan.com/android-2996211-1-1.html 须要ROOT的同学请去上面的地址下载。 a.控制手机创建个暂时目录,然后把zergRush脚本写入此目录,并改动此文件权限使之能够运行(这一步无需ROOT权限); adb shell rm -r /data/local/tmpadb shell mkdir /data/lo…
Oracle数据库日常维护知识总结
DBA要定时对数据库的连接情况进行检查,看与数据库建立的会话数目是不是正常,如果建立了过多的连接,会消耗数据库的资源。同时,对一些“挂死”的连接,可能会需要DBA手工进行清理。首先要说的是,不同版本数据…

JAVA 第五周学习总结
20175304 2018-2019-2 《Java程序设计》第五周学习总结 教材学习内容总结 Java为什么要定义接口:接口的作用是实现多重继承,因为一个子类只能继承一个父类,但是可以实现一个或多个接口。使用关键字interface来定义一个接口,定义方…
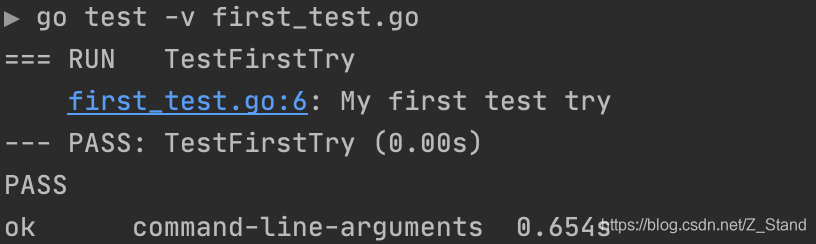
Go: 分布式学习利器(2)-- Go中的变量,常量 以及与其他语言变量之间的差异
文章目录1. Go 语言编写测试代码2. Go 的变量3. Go 常量定义1. Go 语言编写测试代码 源码文件以 _test结尾: xxx_test.go测试方法名需以Test开头: func TESTXXX(t *testing.T) {..} ,且参数列表直接用go 默认的test参数即可 如下first_test…
Scala:Functions and Closures
1 object Functions {2 def main(args: Array[String]) {3 // 本地函数4 def localFun(msg: String) println(msg)5 localFun("Hi")6 7 // 函数对象8 var list List(1, 2, 3)9 list.foreach((x: Int) > println(x)) 10 list.fore…
云计算机机房怎么样,如何知道云电脑配置多少?怎么选择云电脑机房?
一般在玩一款游戏时,需要考虑玩游戏的配置,云电脑帮助我们实现配置的需求,那如何才能知道云电脑配置是多少,该怎么选择云电脑机房。在使用云电脑时,我们不用考虑自己的手机、平板和电脑的硬件,只要设备能正…
eclipse中新建android项目,不自动生成R.java
http://huyuantai000.iteye.com/blog/1681582转载于:https://www.cnblogs.com/wmm3416/p/3386698.html