Python自动化处理Excel数据
需求描述:数据格式如下所示,需要分离出2023年7月1号之后的数据明细

数据核对与处理:从Excel文件中提取特定日期后的签收数据
1. 引言
在实际数据处理和分析过程中,经常会遇到需要从大量数据中提取出特定日期范围内的信息的需求。本文将介绍如何使用Python的pandas库来处理Excel文件,并提取出2023年7月1日之后的签收数据。
2. 准备工作
首先,我们需要导入所需的库。在本文中,我们将使用pandas库来处理Excel文件。
import pandas as pd3. 设置显示选项
为了能够正确显示所有列和行,我们可以设置pandas的显示选项。
pd.set_option('display.max_columns', None) pd.set_option('display.max_rows', None)
4. 读取Excel数据文件
接下来,我们使用pd.read_excel()函数来读取Excel文件中的数据,并指定nrows参数来限制读取的行数。
data = pd.read_excel('C:\\Users\\Admin\\Desktop\\数据核对\\工作簿2.xlsx', nrows=600)
5. 数据处理
为了方便后续操作,我们将DataFrame的索引设置为“货件单号”和“SKU”。
data = data.set_index(['货件单号', 'SKU'])
然后,我们将“签收明细”这一列进行拆分,并将拆分后的每个数据项排成多行。
data = data['签收明细'].str.split('\n', expand=True).stack().reset_index(level=2, drop=True) data.name = '签收明细'
接着,我们从拆分后的数据中提取出“日期”和“数量”两列,并将其转换为正确的数据类型。
data = data.str.split(' \| ', expand=True) data.columns = ['日期', '数量'] data['日期'] = pd.to_datetime(data['日期']) data['数量'] = pd.to_numeric(data['数量'])
6. 筛选数据并保存结果
现在,我们可以筛选出2023年7月1日之后的数据,并将结果保存到Excel文件中。
result = data[data['日期'] >= '2023-07-01'].reset_index() result.to_excel('2023年7月1号之后签收数据.xlsx', index=True)
7. 结果展示
最后,我们输出提示信息,显示结果已经保存到文件中。
print(f"结果已经保存到文件中:2023年7月1号之后签收数据.xlsx")
8. 总结
本文介绍了如何使用Python的pandas库处理Excel文件,并提取出特定日期范围内的签收数据。通过设置显示选项、读取Excel文件、进行数据处理、筛选数据并保存结果,我们能够高效地处理大量数据,并得到我们需要的信息
完整代码:
import pandas as pd # 设置最大列数为 None,以显示所有列 pd.set_option('display.max_columns', None) # 设置最大行数为 None,以显示所有行 pd.set_option('display.max_rows', None) # 读取Excel数据文件 data = pd.read_excel('C:\\Users\\Admin\\Desktop\\数据核对\\工作簿2.xlsx', nrows=600) # 输出全部数据(显示所有行和列) print(data) # 将DataFrame的索引设置为“货件单号”和“SKU”,以便后续操作 data = data.set_index(['货件单号', 'SKU']) # 将“签收明细”这一列进行拆分,并将拆分后的每个数据项排成多行 data = data['签收明细'].str.split('\n', expand=True).stack().reset_index(level=2, drop=True) data.name = '签收明细' # 从拆分后的数据中提取“日期”和“数量”两列 data = data.str.split(' \| ', expand=True) data.columns = ['日期', '数量'] data['日期'] = pd.to_datetime(data['日期']) data['数量'] = pd.to_numeric(data['数量']) # 筛选出 2023 年 7 月 1 日之后的数据,并将结果保存到 Excel 文件中 result = data[data['日期'] >= '2023-07-01'].reset_index() # 筛选符合条件的行,并重置索引 result.to_excel('2023年7月1号之后签收数据.xlsx', index=True) # 将结果保存到 Excel 文件中 # 输出提示信息 print(f"结果已经保存到文件中:2023年7月1号之后签收数据.xlsx")
相关文章:

ModuleNotFoundError: No module named ‘qcloud_cos‘
是腾讯云提供的一个Python SDK,用于与腾讯云对象存储(COS)服务进行交互。使用pip安装qcloud_cos报以下错误。这个错误表示Python无法找到名为。

python安装成功的图标_ubuntu下:安装anaconda、环境配置、软件图标的创建、成功启动anaconda图形界面...
Ubuntu安装anaconda常见的四大问题:目录1、介绍2、安装anaconda3、环境配置4、软件图标的创建5、成功启动anaconda图形界面1、介绍先介绍一下anaconda和python的关系:初学者所安装的python2/3只是python的环境,没有python的工具包&a…
Java中的方法重载和方法重写有什么区别?
Java中的方法重载(Overloading)和方法重写(Overriding)都是面向对象编程中的重要概念,但它们之间有一些区别。方法重载是指在同一个类中,可以定义多个具有相同名称但参数列表不同的方法。这些方法具有不同的参数类型、参数个数或参数顺序。在调用重载方法时,Java编译器会根据传递给方法的参数类型和数量来选择要调用的正确方法。方法重载主要用于解决方法的命名冲突和提高代码的可读性和可维护性。
python基础使用之变量,表达式,语句
PYTHON基础知识系列之变量、表达式、语句

python基础小知识:引用和赋值的区别
通过引用,就可以在程序范围内任何地方传递大型对象而不必在途中进行开销巨大的赋值操作。不过需要注意的是,这种赋值仅能做到顶层赋值,如果出现嵌套的情况下仍不能进行深层赋值。赋值与引用不同,复制后会产生一个新的对象,原对象修改后不会影响到新的对象。如果在原位置修改这个可变对象时,可能会影响程序其他位置对这个对象的引用

Python自动化实战之接口请求的实现
作为一位过来人也是希望大家少走一些弯路,如果你不想再体验一次学习时找不到资料,没人解答问题,坚持几天便放弃的感受的话,在这里我给大家分享一些自动化测试的学习资源,希望能给你前进的路上带来帮助。
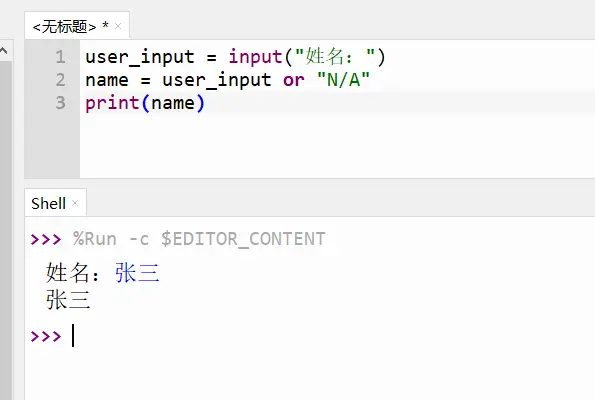
Python中如何简化if...else...语句
我们通常在Python中采用if...else..语句对结果进行判断,根据条件来返回不同的结果,如下面的例子。这段代码是一个简单的Python代码片段,让用户输入姓名并将其赋值给变量user_input。我们能不能把这几行代码进行简化,优化代码的执行效率呢?以下是对各行代码的解读。这里使用了or这个逻辑运算符,当user_input不为空时,user_input为真,name就被赋于user_input的值。采用这种方法可以轻松实现if...else语句的简化。我们可以使用一行简短的代码来实现上面的任务。
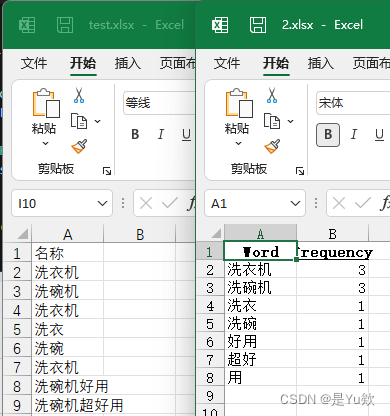
一键式Excel分词统计工具:如何轻松打包Python脚本为EXE
最近,表姐遇到了一个挑战:需要从Excel文件中统计出经过分词处理的重复字段,但由于数据隐私问题,这些Excel文件不能外传。这种情况下,直接使用Excel内置功能好像是行不通的,需要借助Python脚本来实现。为了解决这个问题,我写了一个简单的数据分析和自动化办公脚本,以方便使用。想象一下,即使电脑上没有安装Python,也能通过一个简单的EXE文件轻松完成工作,这是多么方便!因此,我决定不仅要写出这个脚本,还要学会如何将其打包成一个独立的EXE文件。这样,无需Python环境的电脑也能直接运行它
深入三目运算符:JavaScript、C++ 和 Python 比较
三目运算符是编程中常用的条件表达式,它允许我们根据条件选择不同的值。我们将通过具体的例子分别介绍 JavaScript、C++ 和 Python 中的三目运算符,以便更好地理解它们的用法和特性。JavaScript 示例// 例子: 根据条件选择不同的值var x = 10;var y = 20;"x 大于 y" : "x 不大于 y";在这个例子中,如果x大于y,则result的值为 “x 大于 y”,否则为 “x 不大于 y”。C++ 示例// 例子: 根据条件选择不同的值。

python实现网络爬虫代码_python如何实现网络爬虫
2、【find()】和【find_all()】方法可以遍历这个html文件,提取指定信息。return soup.find_all(string=re.compile( '百度' )) #结合正则表达式,实现字符串片段匹配。print(res) #打印输出[root@localhost demo]# python3 demo1.py。[root@localhost demo]# vim demo.py#web爬虫学习 -- 分析。r.raise_for_status() #如果状态码不是200,产生异常。
详细讲解Python中的aioschedule定时任务操作
aioschedule 是一个基于 asyncio 的 Python 库,用于在异步应用程序中进行任务调度。它提供了一种方便的方式来安排和执行异步任务,类似于传统的 schedule 库,但适用于异步编程。
Jetson AGX Orin安装archiconda、Pytorch
Jetson AGX Orin安装archiconda、Pytorch

pandas进行数据计算时如何处理空值的问题?
我们在处理数据时经常会遇到空值的问题,比如有个学生某科弃考但是其他科有成绩的话,计算总分时便需要解决空值计算的问题
如何用pthon连接mysql和mongodb数据库【极简版】
发现宝藏 前言 1. 连接mysql 1.1 安装 PyMySQL 1.2 导入 PyMySQL 1.3 建立连接 1.4 创建游标对象 1.5 执行查询 1.6 关闭连接 1.7 完整示例 2. 连接mongodb 2.1 安装 PyMongo 2.2 导入 PyMongo 2.3 建立连接 2.4
用python实现实现手势音量控制
要实现手势音量控制,您可以使用Python中的PyAutoGUI和pynput库。PyAutoGUI可以模拟鼠标和键盘操作,而pynput可以检测用户的输入事件。,用于检测键盘事件。如果用户按下ESC键,则停止监听鼠标和键盘事件并退出程序。最后,我们创建了鼠标和键盘监听器对象,并调用它们的。,用于模拟按下音量增加和音量减少键的操作。然后,我们定义了一个鼠标手势检测函数。,用于检测鼠标左键的点击事件。在程序的主循环中,我们使用。在这个示例代码中,我们定义了两个函数。函数等待用户按下ESC键退出程序。
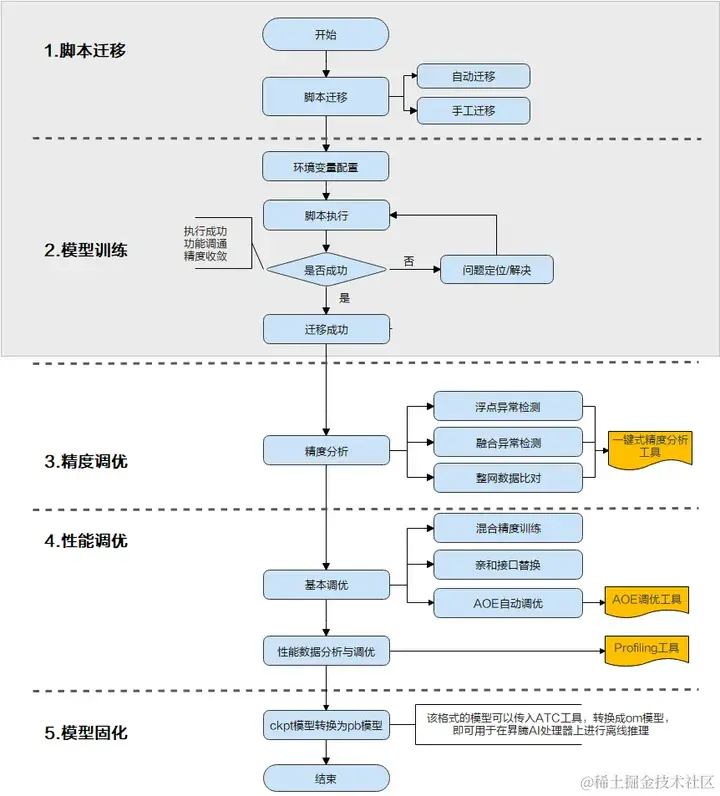
一文详解TensorFlow模型迁移及模型训练实操步骤
当前业界很多训练脚本是基于TensorFlow的Python API进行开发的,默认运行在CPU/GPU/TPU上,为了使这些脚本能够利用昇腾AI处理器的强大算力执行训练,需要对TensorFlow的训练脚本进行迁移。

websocket介绍并模拟股票数据推流
Websockt是一种网络通信协议,允许客户端和服务器双向通信。最大的特点就是允许服务器主动推送数据给客户端,比如股票数据在客户端实时更新,就能利用websocket。

Python实现PDF—>Excel的自动批量转换(附完整代码)
tkinter适用于简单的 GUI 应用,对于入门级开发者和小型项目而言是一个良好的选择。PyQt、PySide、Kivy 和 wxPython 适用于需要更丰富功能、更现代外观或跨平台移动应用的项目,但可能需要更多学习和配置。选择 GUI 库的最佳方法取决于项目的需求、开发者的经验水平以及对不同库的个人偏好。

Python 教程 01:Python 简介及发展历史
Python 是一门大小写敏感的、动态类型的、解释型的编程语言。
PyTorch中nn.Module的继承类中方法foward是自动执行的么?
在 PyTorch的 nn.Module中,forward方法并不是自动执行的,但它是在模型进行前向传播时必须调用的一个方法。当你实例化一个继承自torch.nn.Module的自定义类并传入输入数据时,需要通过调用该实例来实现前向传播计算,这实际上会隐式地调用forward方法。

Python 面向对象之继承和组合
可以看到这两个类之间有太多重复的内容了,所以使用在创建双发射手的时候使用继承可以直接继承他们的属性(名字和攻击力),继承方法(扭动身体的方法),重写方法(攻击)python支撑多继承,新建的类可以继承一个或者多个父类多继承的例子,我们来简单的写以下豌豆僵尸豌豆僵尸继承了豌豆射手类和僵尸类【3】经典类和新式类经典类:没有继承类的所有子类新式类:继承了类的子类在中如果不写继承关系那么就将默认继承object类,所以**里面都是新式类**【二】实例属性查找顺序【1】不存在隐藏属性

如何通过Python将各种数据写入到Excel工作表
本文中将介绍如何使用Python写入数据到Excel表格,包括文本、数组(List)、XML和CSV数据,提供更高效和准确的Excel表格数据写入方案,从而简化数据处理流程并节省宝贵的时间和精力。
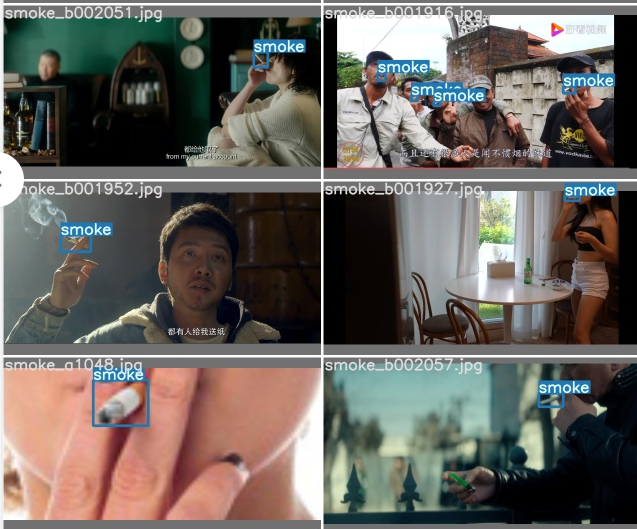
大创项目推荐 深度学习YOLO抽烟行为检测 - python opencv
🔥 优质竞赛项目系列,今天要分享的是🚩基于深度学习YOLO抽烟行为检测该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!🥇学长这里给一个题目综合评分(每项满分5分)难度系数:3分工作量:3分创新点:4分🧿YOLO系列是基于深度学习的回归方法。该系列陆续诞生出YOLOv1、YOLOv2、YOLOv3、YOLOv4、YOLOv5。YOLOv5算法,它是一种单阶段目标检测的算法,该算法可以根据落地要求灵活地通过chaneel和layer的控制因子来配置和调节模型,所以在比赛和落地中应用比较多。
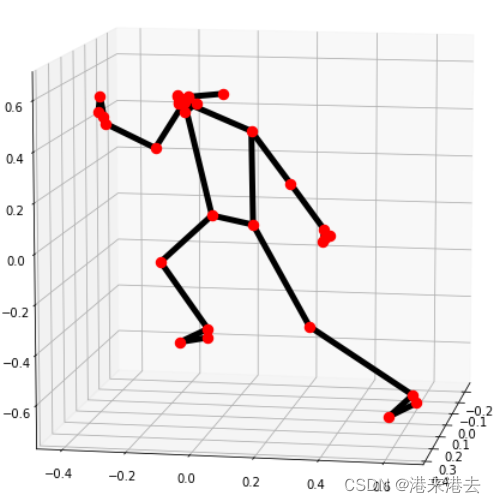
Mediapipe绘制实时3d铰接骨架图——Mediapipe实时姿态估计
使用Mediapipe绘制实时3d骨架铰接图;使用Mediapipe、matplotlib进行3d姿态估计、绘制实时3d坐标

使用 Django 的异步特性提升 I/O 类操作的性能
通过使用 Django 的异步特性,可以显著提高 I/O 类操作的性能。通过使用异步 ORM、异步中间件和异步视图等特性,以及协程和缓存等手段,可以帮助开发人员构建高性能的 Web 应用程序。在使用异步特性时,需要注意代码的可读性和可维护性,以及正确处理并发和异常情况。同时,也需要了解目标硬件和网络环境的限制和瓶颈,以便更好地优化应用程序的性能。
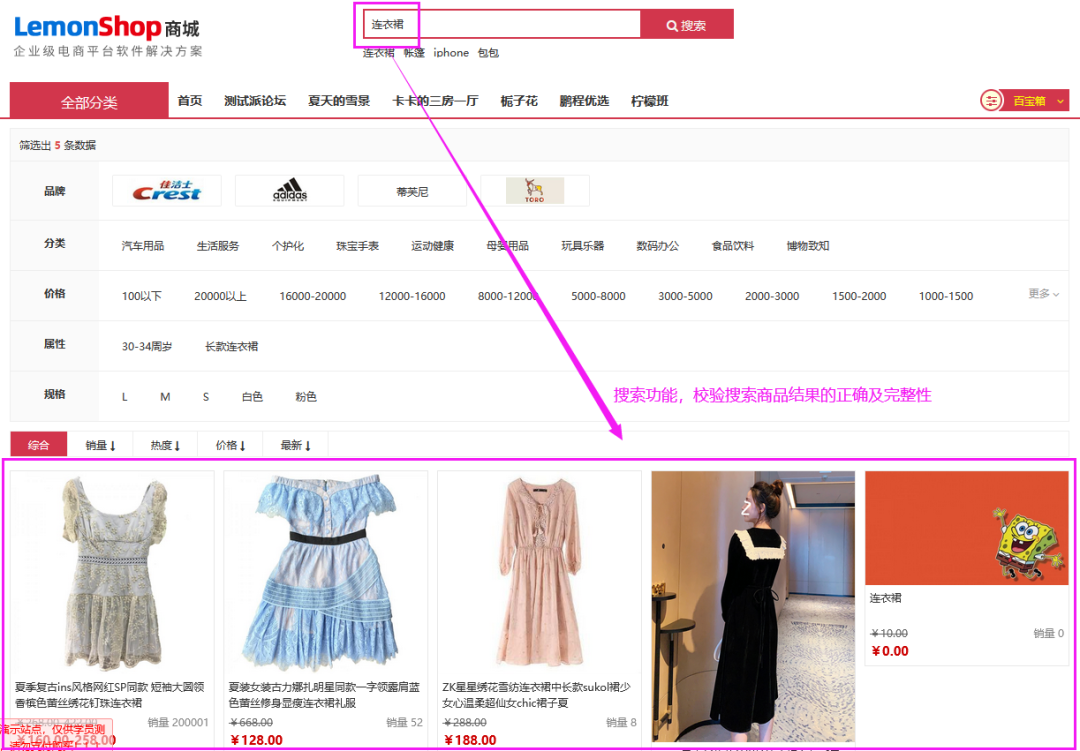
Jmeter、postman、python 三大主流技术如何操作数据库?
只要是做测试工作的,必然会接触到数据库,数据库在工作中的主要应用场景包括但不限于以下:功能测试中,涉及数据展示功能,需查库校验数据正确及完整性;例如商品搜索功能自动化测试或性能测试中,某些接口要跑通,需要关联到数据库操作;例如注册接口中短信验证码获取自动化测试中断言处理,除了响应结果的断言,还包括到数据库断言自动化测试或性能测试中,某些场景需批量造数据,可能需要用到数据库造数据测试中,发现bug,需定位bug,可能需要查询到数据库进行定位当我们利用Jmeter。

python爬虫之selenium模拟浏览器
之前在异步加载(AJAX)网页爬虫的时候提到过,爬取这种ajax技术的网页有两种办法:一种就是通过浏览器审查元素找到包含所需信息网页的真实地址,另一种就是通过selenium模拟浏览器的方法[1]。当时爬的是豆瓣,比较容易分析出所需信息的真实地址,不过一般大点的网站像淘宝这种是不好分析的,所以利用selenium模拟浏览器的行为来爬取数据是一个比较可行的办法。
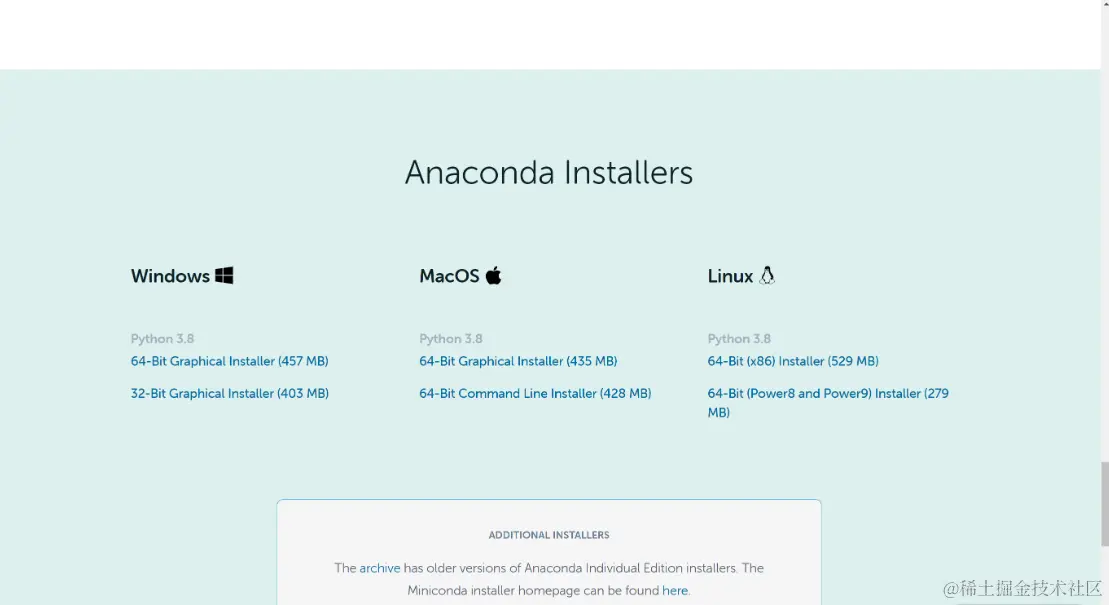
如何搭建一个高效的Python开发环境
不用更改,直接点击 Install,等待 2~3 分钟之后,即可完成安装。安装完毕之后,可以从程序中找到 Anaconda Navigator,点击打开就可以看到整套 Anaconda3 的所有工具(如下图所示):其中 Notebook 是数据分析应用范围最广泛的工具,但它却不是一款足够有效率的工具,因为它缺乏智能的代码输入联想、自动完成和错误提示。而有效率的分析师是不会容忍自己用“记事本”写代码的。
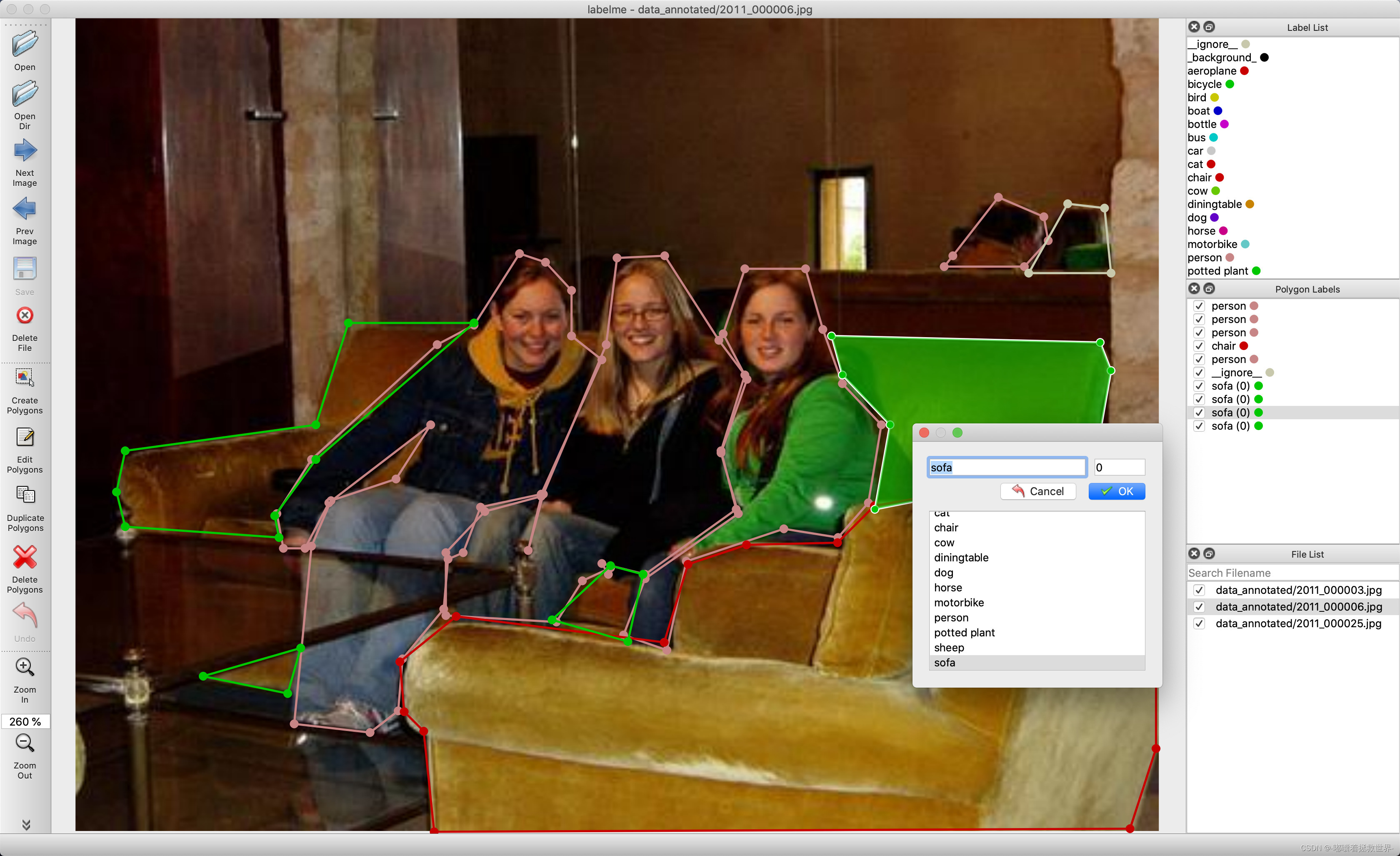
labelme安装与使用教程(内附一键运行包和转格式代码)
Labelme是一个开源的图像标注工具,由麻省理工学院的计算机科学和人工智能实验室(CSAIL)开发。它主要用于创建计算机视觉和机器学习应用所需的标记数据集。LabelMe让用户可以在图片上标注对象和区域,为机器学习模型提供训练数据。它支持多种标注类型,如矩形框、多边形和线条等。它是用 Python 编写的,并使用 Qt 作为其图形界面。
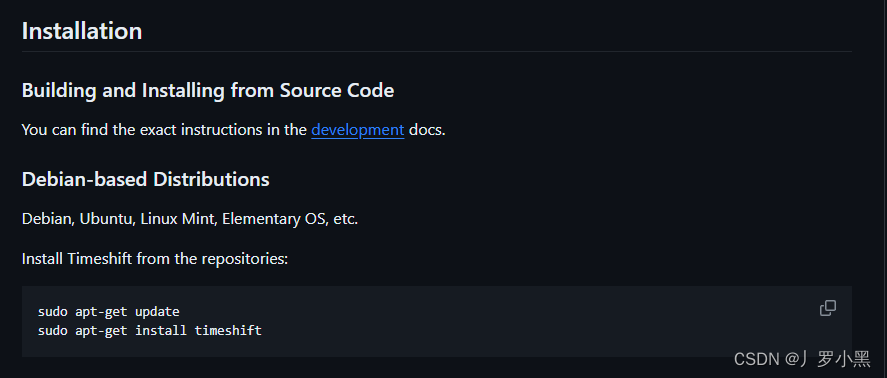
ubuntu20.04安装timeshift最新方法
发现,该软件已移交linuxmint维护。后查阅timeshift的。2. 现在可以使用如下代码安装。